تلميحات البحث رائعة. كم عدد المرات التي نكتب فيها عنوان الموقع بالكامل في شريط العناوين؟ واسم المنتج في متجر على الانترنت؟ بالنسبة إلى هذه الاستعلامات القصيرة ، عادةً ما تكون كتابة بعض الأحرف كافية إذا كانت تلميحات البحث جيدة. وإذا لم يكن لديك عشرين إصبعًا أو سرعة طباعة مذهلة ، فستستخدمها بالتأكيد.
في هذه المقالة ، سنتحدث عن خدمة تلميح hh.ru الجديدة للبحث ، والتي قمنا بها في العدد السابق من
مدرسة المبرمجين .
واجهت الخدمة القديمة عددًا من المشكلات:
- كان يعمل على استفسارات المستخدم الشعبية المختارة باليد ؛
- لا يمكن التكيف مع تغيير تفضيلات المستخدم ؛
- تعذر ترتيب الاستعلامات التي لم يتم تضمينها في الجزء العلوي ؛
- لم تصحيح الأخطاء المطبعية.
في الخدمة الجديدة ، قمنا بتصحيح أوجه القصور هذه (أثناء إضافة أوجه قصور جديدة).
قاموس من الاستفسارات الشعبية
عند عدم وجود تلميحات على الإطلاق ، يمكنك تحديد استعلامات المستخدمين من أعلى إلى N يدويًا وإنشاء تلميحات من هذه الاستعلامات باستخدام التكرار الدقيق للكلمات (بترتيب أو بدون ترتيب). هذا خيار جيد - إنه سهل التنفيذ ، ويوفر دقة جيدة للمطالبات ولا يواجه مشاكل في الأداء. لفترة طويلة ، عملت sugest لدينا من هذا القبيل ، ولكن العيب الكبير في هذا النهج هو عدم اكتمال الإصدار الكافي.
على سبيل المثال ، لم يقع طلب "مطور جافا سكريبت" في مثل هذه القائمة ، لذلك عندما ندخل "أوقات جافا سكريبت" ، لا يوجد لدينا شيء نعرضه. إذا قمنا باستكمال الطلب ، مع الأخذ في الاعتبار الكلمة الأخيرة فقط ، فسنرى "javascript handyman" في المقام الأول. للسبب نفسه ، لن يكون من الممكن تطبيق تصحيح الأخطاء أكثر صعوبة من النهج القياسي في إيجاد أقرب الكلمات عن طريق مسافة Damerau-Levenshtein.
نموذج اللغة
هناك طريقة أخرى تتمثل في تعلم تقييم احتمالات الاستعلامات وإنشاء الاستمرارات الأكثر احتمالًا لاستعلام المستخدم. للقيام بذلك ، استخدم نماذج اللغة - توزيع الاحتمالات على مجموعة من تسلسل الكلمات.
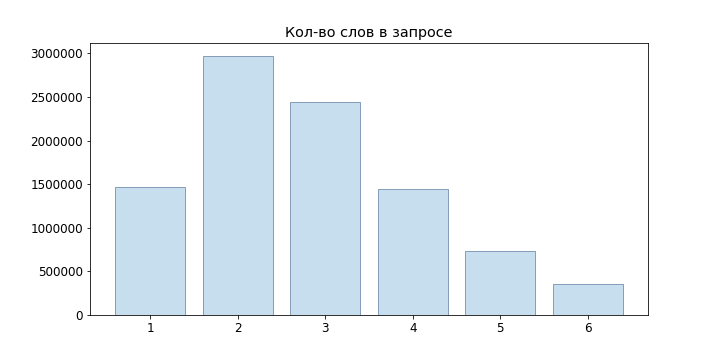
نظرًا لأن طلبات المستخدمين قصيرة في الغالب ، لم نحاول حتى نماذج لغة الشبكة العصبية ، لكننا قصرنا على n-gram:
كأبسط نموذج ، يمكننا أن نأخذ التعريف الإحصائي للاحتمال ، إذن
ومع ذلك ، فإن هذا النموذج ليس مناسبًا لتقييم الاستعلامات التي لم تكن موجودة في العينة الخاصة بنا: إذا لم نلاحظ "java developer java" ، فسيظهر بعد ذلك أن
لحل هذه المشكلة ، يمكنك استخدام نماذج مختلفة من التنعيم والاستيفاء. استخدمنا Backoff:
حيث P هو الاحتمال الملساء
(استخدمنا تجانس لابلاس):
حيث الخامس هو قاموسنا.
الجيل الخيار
لذلك ، نحن قادرون على تقييم احتمال طلب معين ، ولكن كيف نولد هذه الطلبات نفسها؟ من الحكمة القيام بما يلي: اسمح للمستخدم بإدخال استعلام
، ثم يمكن العثور على الاستفسارات المناسبة لنا من الحالة
بالطبع ، الفرز من خلال
لا يمكن تحديد أفضل الخيارات لكل طلب وارد ، لذلك سنستخدم
Beam Search . بالنسبة إلى نموذج اللغة n-gram الخاص بنا ، يتعلق الأمر بالخوارزمية التالية:
def beam(initial, vocabulary): variants = [initial] for i in range(P): candidates = [] for variant in variants: candidates.extends(generate_candidates(variant, vocabulary)) variants = sorted(candidates)[:N] return candidates def generate_candidates(variant, vocabulary): top_terms = []

هنا العقد المميزة باللون الأخضر هي الخيارات المحددة النهائية ، الرقم أمام العقدة
- الاحتمال
، بعد العقدة -
.
لقد أصبح أفضل بكثير ، ولكن في توليد_مرشحين ، تحتاج إلى الحصول بسرعة على N أفضل المصطلحات لسياق معين. في حالة تخزين احتمالات n-gram فقط ، نحتاج إلى استعراض القاموس بالكامل وحساب احتمالات جميع العبارات الممكنة ، ثم فرزها. من الواضح أن هذا لن ينطلق للاستعلامات عبر الإنترنت.
البورون للاحتمالات
للحصول بسرعة على N في المتغيرات الاحتمالية الشرطية لاستمرار العبارة ، استخدمنا البورون في المصطلحات. في العقدة
معامل المخزنة
القيمة
وفرزها حسب الاحتمال الشرطي
قائمة المصطلحات
جنبا إلى جنب مع
. يشير المصطلح
eos الخاص إلى نهاية العبارة.
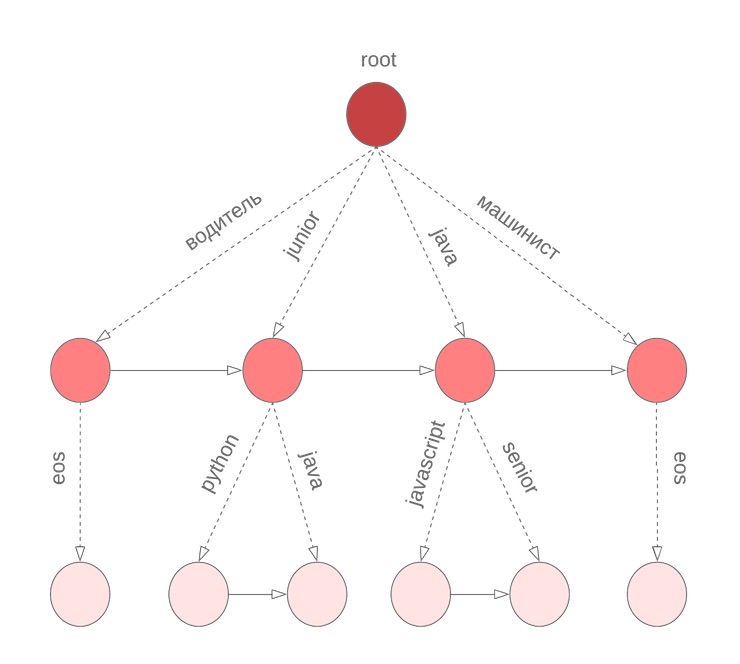
ولكن هناك فارق بسيط
في الخوارزمية الموضحة أعلاه ، نفترض أن جميع الكلمات في الاستعلام قد اكتملت. ومع ذلك ، هذا ليس صحيحًا بالنسبة للكلمة الأخيرة التي أدخلها المستخدم الآن. نحتاج مرة أخرى إلى الانتقال إلى القاموس بأكمله لمتابعة الكلمة الحالية التي يتم إدخالها. لحل هذه المشكلة ، نستخدم البورون الرمزي ، في العقد التي نقوم بتخزين مصطلحات M مرتبة حسب احتمال unigram. على سبيل المثال ، سيبدو هذا مثل bor بالنسبة إلى java أو junior أو jupyter أو javascript مع M = 3:

بعد ذلك ، قبل البدء في Beam Search ، نجد أفضل المرشحين M لمتابعة الكلمة الحالية
وحدد N أفضل المرشحين ل
.
أخطاء مطبعية
حسنًا ، لقد أنشأنا خدمة تتيح لك تقديم تلميحات جيدة لطلب المستخدم. نحن مستعدون حتى للكلمات الجديدة. وكل شيء سيكون على ما يرام ...
لكن المستخدمين يهتمون ولا تبديل لوحات المفاتيح hfcrkflre.كيفية حل هذا؟ أول ما يتبادر إلى الذهن هو البحث عن التصحيحات من خلال إيجاد أقرب الخيارات لمسافة Damerau-Levenshtein ، والتي يتم تعريفها على أنها الحد الأدنى لعدد الإدراج / الحذف / استبدال حرف أو تبديل لشخصين متجاورين ضروريين للحصول على آخر من سطر واحد. لسوء الحظ ، لا تأخذ هذه المسافة في الاعتبار احتمال استبدال معين. لذلك ، بالنسبة للكلمة "sapper" التي تم إدخالها ، نجد أن الخيارات "جامع" و "لحام" متكافئتان ، على الرغم من أنه يبدو من البديهي أنهما كانا في ذهنهما الكلمة الثانية.
المشكلة الثانية هي أننا لا نأخذ في الاعتبار السياق الذي حدث فيه الخطأ. على سبيل المثال ، في استعلام "ترتيب الأمر" ، لا يزال يتعين علينا أن نفضل الخيار "جامع" بدلاً من "لحام".
إذا اقتربت من مهمة تصحيح الأخطاء المطبعية من وجهة نظر احتمالية ، فمن الطبيعي جدًا الوصول إلى
نموذج لقناة مزعجة :
- مجموعة الأبجدية .
- مجموعة من جميع الخطوط زائدة فوقه
- العديد من الأسطر التي هي الكلمات الصحيحة .
- توزيعات معينة حيث .
ثم يتم تعيين مهمة التصحيح كإيجاد الكلمة الصحيحة w للإدخال s. اعتمادا على مصدر الخطأ ، وقياس
يمكن بناؤه بطرق مختلفة ، وفي حالتنا ، من الحكمة محاولة تقدير احتمال حدوث أخطاء مطبعية (دعنا نسميها بدائل أولية)
، حيث t ، r هي رمزية n-gram ، ومن ثم تقييمها
كاحتمال الحصول على s من w بواسطة بدائل أولية محتملة.
سمح

- تقسيم السلسلة x إلى سلاسل فرعية (ربما صفر). يتضمن نموذج Brill-Moore حساب الاحتمال
على النحو التالي:
P (s | w) \ approx \ max_ {R \ in Part_n (s)} T \ in Part_n (s)} \ prod_ {i = 1} ^ {n} P_e (T_i | R_i)
لكننا بحاجة إلى إيجاد
:
من خلال تعلم تقييم P (w | s) ، سنعمل أيضًا على حل مشكلة خيارات الترتيب بنفس مسافة Damerau-Levenshtein ويمكن أن نأخذ بعين الاعتبار السياق عند تصحيح الخطأ المطبعي.
حساب
لحساب احتمالات البدائل الأولية ، ستساعدنا استعلامات المستخدم مرة أخرى: سنقوم بتكوين أزواج من الكلمات (الكلمات ، ث) والتي
- قريب في داميراو ليفينشتاين ؛
- واحدة من الكلمات هي أكثر شيوعا من الأوقات N الأخرى.
لمثل هذه الأزواج ، نعتبر المحاذاة المثلى وفقًا لـ Levenshtein:
نحن نؤلف جميع الأقسام الممكنة من s و w (حددنا أنفسنا بالأطوال n = 2 ، 3): n → n ، pr → rn ، pro → rn ، ro → po ، m → `` ، mm → m ، إلخ. لكل ن غرام ، نجد
حساب
حساب
يأخذ مباشرة
: نحن بحاجة إلى فرز جميع الأقسام الممكنة من w مع جميع الأقسام المحتملة من s. ومع ذلك ، يمكن أن تعطي ديناميكيات البادئة إجابة
حيث n هو الحد الأقصى لطول البدائل الأولية:
d [i، j] = \ start {cases} d [0، j] = 0 & j> = k \\ d [i، 0] = 0 & i> = k \\ d [0، j] = P (s [0: j] \ space | \ space w [0]) & j <k \\ d [i، 0] = P (s [0] \ space | \ space w [0: i]) & i <k \\ d [i، j] = \ underset {k، l \ le n، k \ lt i، l \ lt j} {max} (P (s [jl: j] \ space | \ space w [ik: i]) \ cdot d [ik-1، jl-1]) \ end {cases}
هنا P هو احتمال الصف المقابل في نموذج k-gram. إذا نظرت عن كثب ، فهي تشبه إلى حد كبير خوارزمية فاغنر فيشر مع لقطة Ukkonen. في كل خطوة نحصل عليها
عن طريق تعداد جميع الإصلاحات
في
يخضع ل
واختيار الأكثر احتمالا.
العودة إلى
لذلك ، يمكننا حساب
. الآن نحن بحاجة إلى تحديد العديد من الخيارات ث تعظيم
. بتعبير أدق ، للطلب الأصلي
يجب أن تختار
حيث
الحد الأقصى. لسوء الحظ ، لم يكن الخيار الصادق للخيارات يتناسب مع متطلبات وقت الاستجابة لدينا (وكان الموعد النهائي للمشروع يقترب من نهايته) ، لذلك قررنا التركيز على النهج التالي:
- من الاستعلام الأصلي ، حصلنا على عدة خيارات عن طريق تغيير الكلمات الأخيرة k:
- نقوم بتصحيح تخطيط لوحة المفاتيح إذا كان المصطلح الناتج لديه احتمال أعلى عدة مرات من المصطلح الأصلي ؛
- نجد كلمات لا تتجاوز مسافة Damerau-Levenshtein d ؛
- اختر من بينها خيارات أعلى N ل .
- إرسال BeamSearch إلى المدخلات جنبا إلى جنب مع الطلب الأصلي ؛
- عند تصنيف النتائج نقوم بخصم الخيارات التي تم الحصول عليها على .
بالنسبة للفقرة 1.2 ، استخدمنا خوارزمية FB-Trie (التعادل للأمام والخلف) ، استنادًا إلى البحث الغامض في أشجار البادئة الأمامية والخلفية. اتضح أن هذا أسرع من تقييم P (s | w) في جميع أنحاء القاموس.
إحصائيات الاستعلام
مع إنشاء نموذج اللغة ، كل شيء بسيط: نقوم بجمع إحصاءات عن استفسارات المستخدم (عدد المرات التي طلبنا فيها عبارة معينة ، وعدد المستخدمين ، وعدد المستخدمين المسجلين) ، ونقسم الطلبات إلى n-gram ، وبناء الأزيز. أكثر تعقيدًا مع نموذج الخطأ: كحد أدنى ، يلزم وجود قاموس للكلمات الصحيحة لإنشاءه. كما ذكر أعلاه ، لتحديد أزواج التدريب ، استخدمنا الافتراض بأن هذه الأزواج يجب أن تكون قريبة من مسافة Damerau-Levenshtein ، ويجب أن تحدث واحدة أكثر من غيرها عدة مرات.
لكن البيانات لا تزال صاخبة للغاية: محاولات حقن xss ، تخطيط غير صحيح ، نص عشوائي من الحافظة ، مستخدمين ذوي خبرة مع طلبات "programmer c not 1c" ،
طلبات من القط الذي مر عبر لوحة المفاتيح .
على سبيل المثال ، ماذا حاولت أن تجد بهذا الطلب؟ لذلك ، لمسح البيانات المصدر ، استبعدنا:
- شروط التردد المنخفض.
- تحتوي على عوامل تشغيل لغة الاستعلام
- المفردات الفاحشة.
قاموا أيضًا بتصحيح تخطيط لوحة المفاتيح والتحقق من الكلمات من نصوص الشواغر والقواميس المفتوحة. بالطبع ، لم يكن من الممكن إصلاح كل شيء ، ولكن عادة ما تكون هذه الخيارات مقطوعة تمامًا أو موجودة في أسفل القائمة.
في همز
مباشرة قبل حماية المشروع ، أطلقوا خدمة في الإنتاج للاختبار الداخلي ، وبعد يومين - عن 20 ٪ من المستخدمين. في hh.ru ، تمر جميع التغييرات المهمة للمستخدمين من خلال
نظام اختبارات AB ، والذي لا يسمح لنا فقط بالتأكد من أهمية وجودة التغييرات ، ولكن أيضًا
للعثور على الأخطاء .
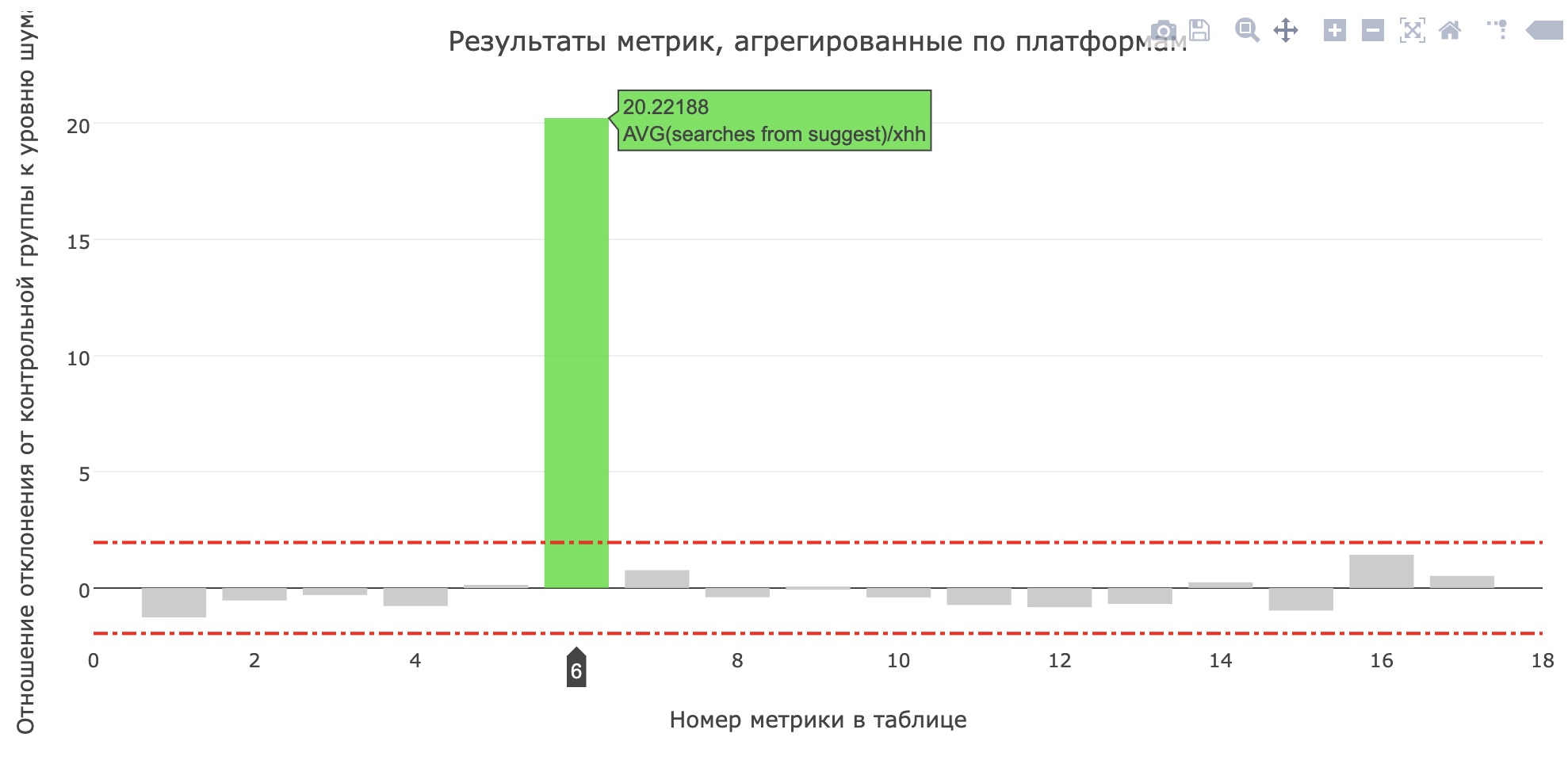
لقد زاد معدل قياس عدد عمليات البحث من sujest للمتقدمين (زاد من 0.959 إلى 1.1355) ، وزادت حصة عمليات البحث من sujest لجميع طلبات البحث من 12.78٪ إلى 15.04٪. لسوء الحظ ، لم تنمو مقاييس المنتج الرئيسية ، ولكن بالتأكيد بدأ المستخدمون في استخدام المزيد من النصائح.
في النهاية
لم يكن هناك مجال لقصة حول عمليات المدرسة ، والنماذج الأخرى التي تم اختبارها ، والأدوات التي كتبناها لمقارنات النماذج ، والاجتماعات حيث قررنا الميزات التي يجب تطويرها من أجل الحصول على عرض توضيحي متوسط. انظر إلى
سجلات المدرسة السابقة ، واترك طلبًا على
https://school.hh.ru ، واستكمل المهام الشيقة ، وتأتي للدراسة. بالمناسبة ، تم إجراء خدمة التحقق من المهام أيضًا بواسطة خريجي المجموعة السابقة.
ماذا تقرأ؟
- مقدمة لنموذج اللغة
- بريل مور النموذجي
- FB-حاكموا
- ماذا يحدث لاستعلام البحث الخاص بك