في هذه المقالة سوف أصف تجربتنا في الترحيل Preply إلى Kubernetes ، وكيف ولماذا فعلنا ذلك ، وما الصعوبات التي واجهناها والمزايا التي اكتسبناها.

Kubernetes ل Kubernetes؟ لا ، متطلبات العمل!
حول Kubernetes هناك الكثير من الضجيج ولسبب وجيه. يقول الكثير من الناس أن هذا سوف يحل جميع المشكلات ، والبعض الآخر يقول أنك على الأرجح لن تحتاج إلى Kubernetes . الحقيقة بالطبع في مكان ما بين.

ومع ذلك ، فإن كل هذه المناقشات حول أين ومتى يلزم Kubernetes تستحق مقالة منفصلة. الآن سأتحدث قليلاً عن متطلبات أعمالنا وكيف عملت Preply قبل الترحيل إلى Kubernetes:
- عندما استخدمنا تدفق Skullcandy ، كان لدينا الكثير من الفروع ، كلها مدمجة في فرع مشترك يسمى
stage-rc ، تم نشره على المسرح. قام فريق ضمان الجودة باختبار هذه البيئة ، بعد اختبار أن الفرع كان مرحًا في المعلم والسيد تم نشره في المنتج. استغرق الإجراء بأكمله حوالي 3-4 ساعات وتمكنا من نشر 0-2 مرات في اليوم - عندما نشرنا الكود المكسور على المنتج ، اضطررنا إلى إعادة جميع التغييرات المضمنة في الإصدار الأخير. كان من الصعب أيضًا العثور على التغيير الذي كسر منتجنا
- استخدمنا AWS Elastic Beanstalk لاستضافة طلبنا. استغرق كل عملية نشر لشجرة الفاصولياء في حالتنا 45 دقيقة (خط الأنابيب بأكمله مع الاختبارات التي تمت في 90 دقيقة ). التراجع إلى الإصدار السابق من التطبيق استغرق 45 دقيقة
لتحسين منتجاتنا وعملياتنا في الشركة ، أردنا:
- كسر متراصة في microservices
- نشر أسرع وأكثر في كثير من الأحيان
- التراجع بشكل أسرع
- غير عملية التطوير الخاصة بنا لأننا اعتقدنا أنها لم تعد فعالة
احتياجاتنا
نحن نغير عملية التطوير
لتنفيذ ابتكاراتنا مع تدفق Skullcandy ، نحتاج إلى إنشاء بيئة ديناميكية لكل فرع. في منهجنا مع تكوين التطبيق في Elastic Beanstalk ، كان من الصعب والمكلف القيام به. أردنا إنشاء بيئات من شأنها أن:
- يتم النشر بسرعة وسهولة (يفضل حاويات)
- عملت على الحالات الفورية
- كانوا مثل تشبه همز
قررنا الانتقال إلى التنمية القائمة على الجذع. بكل مساعدة ، كل ميزة لها فرع منفصل ، والتي ، بشكل مستقل عن البقية ، يمكن دمجها في برنامج رئيسي. يمكن نشر فرع رئيسي في أي وقت.
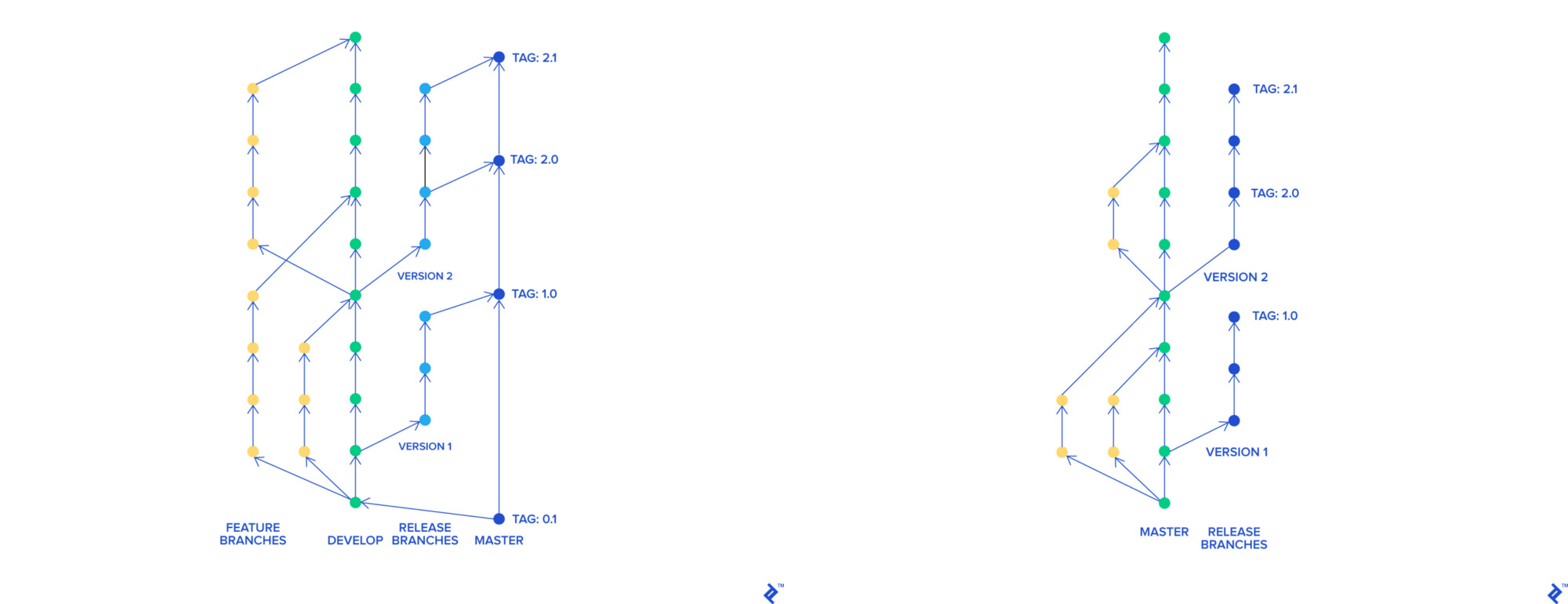
بوابة التدفق والتنمية القائمة على الجذع
نشر أسرع وأكثر في كثير من الأحيان
سمحت لنا العملية الجديدة القائمة على الجذع بتوصيل الابتكارات إلى الفرع الرئيسي بشكل أسرع واحدًا تلو الآخر. وقد ساعدنا ذلك كثيرًا في عملية العثور على رمز مكسور في المنتج وإعادته. ومع ذلك ، كان وقت النشر لا يزال 90 دقيقة ، وكان وقت التراجع 45 دقيقة ، ولهذا السبب لم نتمكن من نشر أكثر من 4-5 مرات في اليوم.
واجهنا أيضًا صعوبات في استخدام بنية الخدمة على Elastic Beanstalk. كان الحل الأكثر وضوحا هو استخدام الحاويات والأدوات لتنظيمها. بالإضافة إلى ذلك ، لدينا بالفعل خبرة في استخدام Docker و docker-compose للتنمية المحلية.
كانت خطوتنا التالية هي البحث عن أوركسترا الحاويات الرائعين:
- AWS ECS
- سرب
- اباتشي ميسوس
- بدوي
- Kubernetes
قررنا البقاء في Kubernetes ، وهذا هو السبب. من بين الأوركسترا المعنيين ، كان لدى الجميع بعض العيوب المهمة: ECS هو حل معتمد على البائع ، وفقد Swarm بالفعل أمجاد Kubernetes ، بدا Apache Mesos وكأنه سفينة فضاء لنا مع Zookeepers. بدت Nomad مثيرة للاهتمام ، لكنها كشفت عن نفسها تمامًا فقط في التكامل مع منتجات Hashicorp الأخرى ، كما شعرنا بخيبة أمل لأن مساحات الأسماء في Nomad قد تم دفعها.
على الرغم من عتبة الدخول العالية ، فإن Kubernetes هي المعيار الفعلي في تزامن الحاويات. Kubernetes كخدمة متاحة في معظم مزودي الخدمات السحابية الرئيسية. الأوركسترا قيد التطوير النشط ، وتضم مجموعة كبيرة من المستخدمين والمطورين ، وتوثيق جيد.
كنا نتوقع أن ننتقل بشكل كامل من منصتنا إلى Kubernetes في سنة واحدة. شارك اثنان من مهندسي المنصات بدون خبرة Kubernetes في عملية الترحيل الجزئي.
باستخدام Kubernetes
لقد بدأنا بإثبات المفهوم ، وأنشأنا مجموعة اختبار ، ووثقنا كل ما فعلناه بالتفصيل. قررنا استخدام kops ، لأنه في منطقتنا في ذلك الوقت ، كانت EKS لا تزال غير متوفرة (في أيرلندا تم الإعلان عنها في سبتمبر 2018 ).
أثناء العمل مع المجموعة ، اختبرنا نظام autoscaler ، و cert-manager ، و Prometheus ، والتكامل مع Hashicorp Vault و Jenkins والمزيد. لقد "لعبنا" مع استراتيجيات التحديث المستمر ، وواجهنا العديد من مشاكل الشبكة ، وخاصة مع DNS ، وعززنا معرفتنا في تجميع المجموعات.
واستخدموا الحالات الفورية لتحسين تكاليف البنية التحتية. لتلقي إشعارات حول المشكلات الموضعية ، استخدموا معالج إشعارات kube-spot-termination ، ويمكن لـ Spot Instance Advisor مساعدتك في اختيار نوع مثيل الموضع.
لقد بدأنا الانتقال من تدفق Skullcandy إلى التطوير المستند إلى Trunk ، حيث أطلقنا مرحلة ديناميكية لكل طلب ، وهذا يسمح لنا بتقليل وقت التسليم للميزات الجديدة من 4-6 إلى 1-2 ساعات .
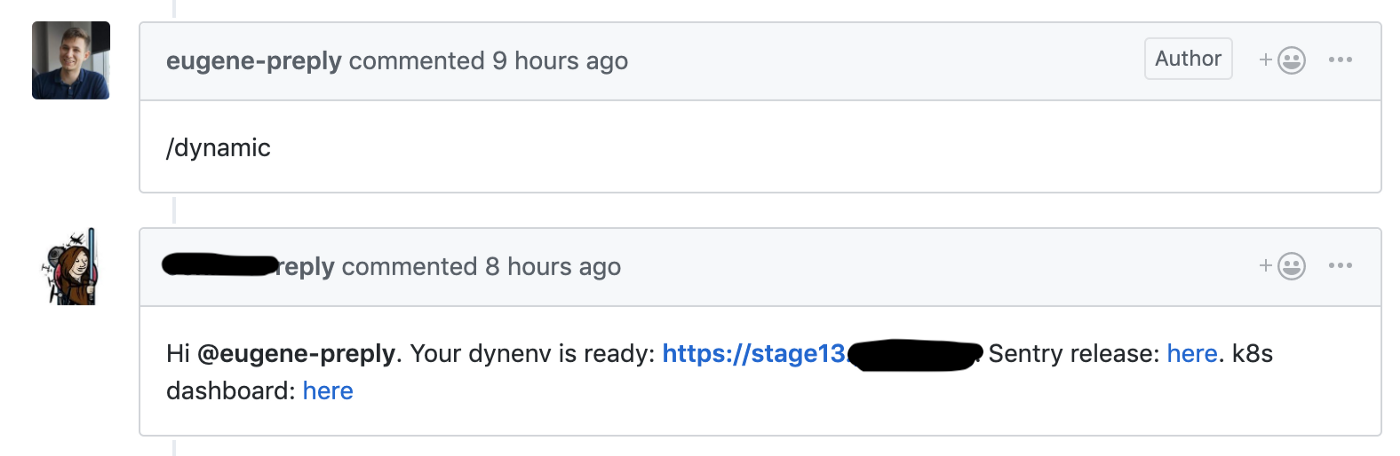
هوك جيثب تطلق خلق بيئة ديناميكية لطلب السحب
استخدمنا مجموعة اختبار لهذه البيئات الديناميكية ، وكانت كل بيئة في مساحة اسم منفصلة. تمكن المطورون من الوصول إلى لوحة معلومات Kubernetes لتصحيح التعليمات البرمجية الخاصة بهم.
يسعدنا أننا بدأنا الاستفادة من Kubernetes بعد 1-2 أشهر فقط من بداية استخدامه.
مجموعات المرحلة وبيع
إعداداتنا لمجموعات المرحلة والمنتج:
- kops و Kubernetes 1.11 (أحدث إصدار في وقت إنشاء الكتلة)
- ثلاث نقاط رئيسية في مناطق وصول مختلفة
- طوبولوجيا شبكة خاصة مع حصن مخصص ، Calico CNI
- يتم نشر بروميثيوس لجمع المقاييس في نفس المجموعة باستخدام PVC (تجدر الإشارة إلى أننا لا نقوم بتخزين المقاييس لفترة طويلة)
- وكيل Datadog ل APM
- Dex + dex-k8s-Authenticator لتوفير الوصول إلى الكتلة للمطورين
- عقد لكتلة المرحلة العمل على الحالات الموضعية
أثناء العمل مع المجموعات ، واجهنا العديد من المشاكل. على سبيل المثال ، اختلفت إصدارات وكيل Nginx Ingress و Datadog على المجموعات ، فيما يتعلق بهذا الأمر ، عملت بعض الأشياء على مجموعة المسرح ، لكنها لم تعمل على المنتج. لذلك ، قررنا الالتزام التام بإصدارات البرامج على الكتل لتجنب مثل هذه الحالات.
ترحيل Prod إلى Kubernetes
مجموعات المواد الغذائية والمرحلة جاهزة ، ونحن مستعدون لبدء الهجرة. نستخدم monorepa مع الهيكل التالي:
. ├── microservice1 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microservice2 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microserviceN │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── helm │ ├── microservice1 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microservice2 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microserviceN │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml └── Jenkinsfile
يحتوي الجذر Jenkinsfile على جدول مراسلات بين اسم الخدمة الصغيرة والدليل الذي يوجد به الكود. عندما يحتفظ المطور بطلب السحب للسيد ، يتم إنشاء علامة في GitHub ، يتم نشر هذه العلامة في المنتج باستخدام Jenkins وفقًا لـ Jenkinsfile.
يحتوي الدليل helm/ الدليل على مخططات HELM مع ملفين قيمين منفصلين للمرحلة والبيع. نستخدم Skaffold لنشر العديد من مخططات HELM على المسرح. لقد حاولنا استخدام المخطط المظلي ، ولكن واجهنا صعوبة في القياس.
وفقًا للتطبيق الاثني عشر ، تقوم كل خدمة ميكروية جديدة في prod بكتابة سجلات إلى stdout وقراءة أسرار Vault ولديها مجموعة أساسية من التنبيهات (التحقق من عدد مآثر العمل وخمسمائة أخطاء ومرابط عند الدخول).
بغض النظر عما إذا كنا نستورد ميزات جديدة في خدمات micros أم لا ، في حالتنا جميع الوظائف الرئيسية هي في متراصة Django وما زالت هذه المتراصة تعمل على تطبيق Beanstalk المرن.

تقسيم متراصة إلى microservices // فيجيلاند بارك في أوسلو
استخدمنا AWS Cloudfront كقاعدة بيانات (CDN) ومعنا استخدمنا نشر الكناري خلال عملية الترحيل لدينا. بدأنا في نقل المتراصة إلى Kubernetes واختبارها على بعض الإصدارات اللغوية وعلى الصفحات الداخلية للموقع (مثل لوحة المسؤول). سمحت لنا عملية هجرة مماثلة بقبض الأخطاء على عملية التلميع وصقل عمليات نشرنا في عدد قليل من التكرارات. على مدار أسبوعين ، قمنا بمراقبة حالة النظام الأساسي والتحميل والمراقبة ، وفي النهاية ، تم تحويل 100 ٪ من حركة المبيعات إلى Kubernetes.
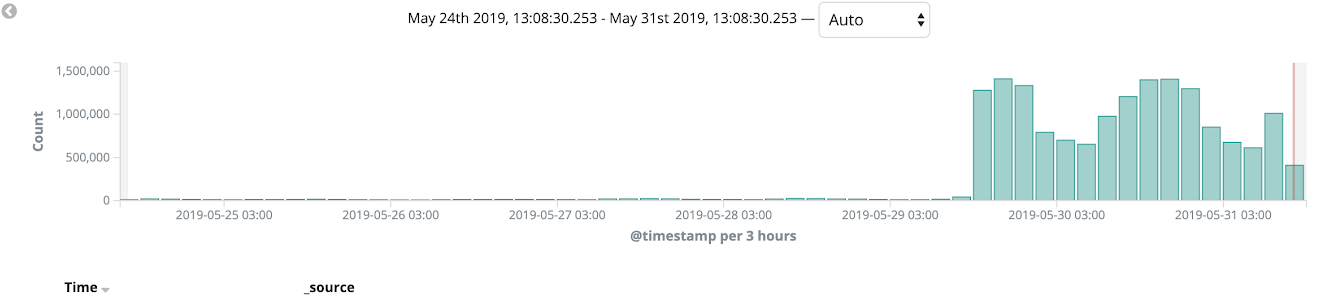
بعد ذلك ، تمكنا تمامًا من التخلي عن استخدام لعبة Beanstalk المرنة.
النتائج
استغرقت الهجرة الكاملة 11 شهرًا ، كما ذكرت أعلاه ، فقد خططنا للوفاء بالموعد النهائي وهو عام واحد.
في الواقع ، النتائج واضحة:
- انخفض وقت النشر من 90 دقيقة إلى 40 دقيقة
- زاد عدد عمليات النشر من 0-2 إلى 10-15 يوميًا (وما زال ينمو!)
- تراجع وقت الاستعادة من 45 إلى 1-2 دقائق
- يمكننا بسهولة تقديم خدمات ميكروية جديدة للمنتج
- قمنا بتنظيم عمليات المراقبة والتسجيل وإدارة الأسرار الخاصة بنا وركزناها ووصفناها على أنها كود
لقد كانت تجربة ترحيل رائعة جدًا وما زلنا نعمل على العديد من التحسينات على النظام الأساسي. تأكد من قراءة المقال الرائع حول تجربة Kubernetes من Jura ، وكان أحد مهندسي YAML الذين شاركوا في تنفيذ Kubernetes في Preply.