في عالم التشفير ، هناك العديد من الطرق السهلة لتشفير الرسالة. كل واحد منهم جيد بطريقته الخاصة. سيتم مناقشة واحد منهم.
يلشو شتشكو
أو تُرجم من "شفرة قيصر" إلى اللغة الروسية - شفرة قيصر .

- ما هو جوهرها؟
- يقوم بتشفير الرسالة ، مع تبديل كل حرف بـ N نقطة. يقوم تشفير قيصر الكلاسيكي بتحريك الحروف ثلاث خطوات للأمام. بكلمات بسيطة - لقد كان "abv" ، أصبح "حيث".
"لكن ماذا عن الحروف في نهاية الأبجدية؟" ماذا عن المساحات؟
انهم جميعا على ما يرام. في حالة تغيير الحرف ، يتجاوز التشفير نطاق الأبجدية - يبدأ العد من جديد. وهذا يعني أن الحروف "Eyuya" تتحول إلى "abv". وتبقى المساحات مسافات.
- هل يجب أن تساوي N بالضرورة ثلاثة؟
لا على الإطلاق. N قد تختلف عن ثلاثة. يُسمح بأي N بين [1: M-1] ، حيث M هو عدد الأحرف في الأبجدية.
من السهل فك تشفير مثل هذه الشفرة إذا كنت تعرف بوجودها. ولكن لم تكن "موثوقيته" هي التي جذبتني ، ولكن شيئًا آخر.
التعادل
في أحد أيام الصيف أردت أن أعرف:
- ولكن ماذا لو قمت بتشفير كلمة باستخدام قيصر ، وحصلت على كلمة موجودة في الإخراج؟
- كم من هذه الكلمات هي "المغيرون"؟
- وسوف يكون هناك نمط إذا تم تغيير N؟
بدأت أبحث عن إجابات لهذه الأسئلة في الدقائق نفسها.
المهمة: البحث عن كل الكلمات
التراجع. من حفلات ميخائيل زادورنوف والتجربة الشخصية ، فهمت شيئين:
- الأمريكيون لا يشعرون بالإهانة بسبب خطاب الكوميديين الروس.
- اللغة الروسية قوية وقوية. وهناك الكثير من الكلمات في ذلك.
لذلك ، قررت أن تأخذ اللغة الإنجليزية كأساس لي. بالإضافة إلى ذلك ، ذات مرة كان هناك INFA أن اللاعبين الناطقين باللغة الإنجليزية تمكنوا من وضع قاموس كامل للكلمات الإنجليزية. ما الذي دفعني إلى إيجاد مجموعة البيانات هذه.
السطر الأول من googling البطيء نقلني إلى هذا المستودع . وعد المؤلف 479K الكلمات الإنجليزية في أشكال مريحة. أعجبني ملف json ، الذي وضعت فيه جميع الكلمات في شكل مناسب للتحميل في قاموس Python.
بعد تشريح الجثة الأولى ، تبين أنه كان هناك عدد أقل من الكلمات - 370 101 قطعة. "لكن هذا لا يهم ، لأنه على سبيل المثال الجيد سيكون كافيا" ، اعتقدت.
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
تحتاج أولا إلى إنشاء الأبجدية. قررت أن تجعلها قائمة بأنسب الطرق بالنسبة لي. كان من الضروري أيضًا تذكر عدد الحروف في الأبجدية:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
في البداية كان من المثير للاهتمام جعل وظيفة ترجمة الكلمة إلى كلمة مشفرة. إليك ما حدث:
قررت أن أقوم بدورة كبيرة بكل الكلمات وأن أبدأ بترجمتها واحدة تلو الأخرى. ولكن واجه مشكلة. اتضح أن بعض الكلمات تحتوي على علامة "-" ، والتي كانت مفاجئة وطبيعية في نفس الوقت.
دون التفكير مرتين ، أحسب عدد هذه الكلمات واتضح أن هناك كلمتين فقط. بعد ذلك قام بحذف كليهما ، لأنه لن يؤثر على النتيجة. لمساعدتي ، ولدت هذه الوظيفة:
بدا القاموس مثل:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
لذلك ، قررت ألا أكون ذكياً واستبدل الكلمات بالكلمات المشفرة. للقيام بذلك ، كتب وظيفة:
وبطبيعة الحال ، كنا بحاجة إلى دورة كبيرة ستستعرض كل الكلمات ، ونجد مبدلات الكلمات وحفظ النتيجة. ومن هنا:
ربما لاحظت أنه في معلمات الوظيفة هي "min_len = 0". سوف تكون هناك حاجة في المستقبل. لخصوصية مجموعة البيانات هذه كانت مجموعة "غريبة" من الكلمات. مثل: "aa" ، "aah" ومجموعات مماثلة. هم الذين أعطوا النتيجة الأولى - 660 مغير كلمات.
لذلك ، كان علي أن أضع حدًا لا يقل عن خمسة أحرف على الأقل ، بحيث تكون الكلمات جذابة للعين وتشبه تلك الموجودة.
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
نعم ، تم العثور على عشر كلمات قلب بفضل الخوارزمية. مزيج بلدي المفضل:
بريميرو [الأول] → الكبريت [الكبريت]. معظم الأزواج الأخرى جوجل مترجم لا يتعرف.
في هذه المرحلة ، أطفأت تعطش المعرفة. لكن أمامك كانت الأسئلة مثل: "ماذا عن N الأخرى؟"
وباستخدام هذه الوظيفة ، وجدت الإجابة:
انتهت الدورة في 10-15 ثانية. يبقى فقط لرؤية النتائج. لكن ، كما أعتقد ، سيكون الأمر أكثر إثارة عندما يكون هناك جدول زمني. وهنا هي الوظيفة النهائية ، والتي سوف تظهر لنا النتيجة:
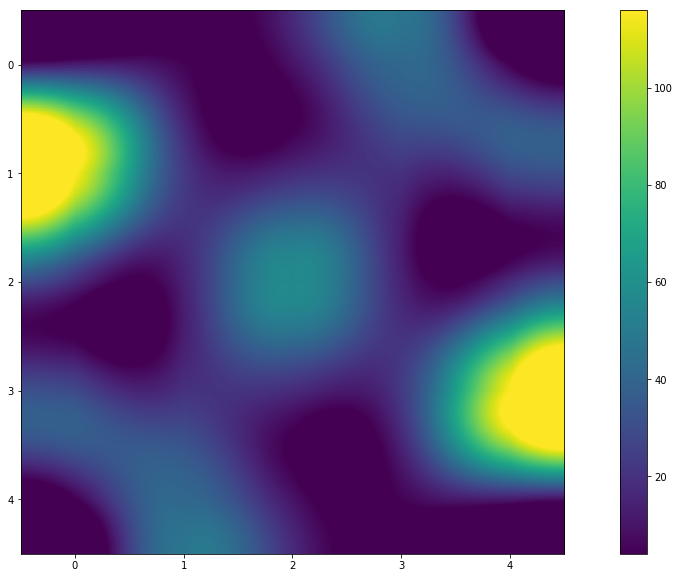
يؤدي
إجابات على الأسئلة في البداية
"ماذا لو قمت بتشفير كلمة باستخدام قيصر ، وحصلت على كلمة موجودة في الإخراج؟"
- هذا ممكن ، حتى جدا. بعض N يعطي كلمات أكثر بكثير من غيرها.
- كم عدد هذه الكلمات "المغيرون" هناك؟
- يعتمد على N ، الحد الأدنى للطول ، وبالطبع على مجموعة البيانات. في حالتي ، مع N = 3 ، يكون الحد الأدنى لطول كلمة 0 و 5 هو عدد الكلمات: 660 و 10 ، على التوالي.
- وسوف يكون هناك نمط إذا قمت بتغيير N؟
- على ما يبدو ، نعم! من الرسم البياني (أو خريطة الحرارة) يمكنك أن ترى أن الألوان متناظرة. والقيم في مصفوفة النتائج تشير إلى هذا. والإجابة على السؤال "لماذا هذا؟" سأتركه للقارئ.
سلبيات هذا العمل
- ليس صحيحا تماما مجموعة البيانات. العديد من الكلمات ليست واضحة. على الرغم من أنه قد يكون كذلك. هذه هي الكلمات " الكل " في اللغة الإنجليزية.
- قانون
دائما يمكن تحسينها. - "رمز قيصر" هو حالة خاصة من "رمز أثينا" ، حيث الصيغة:

بالنسبة لـ "قيصر التشفير" A = 1. بالمناسبة ، لديه المزيد من الفروق الدقيقة ، مما يعني المزيد من الاهتمام.
يكمن ملف العمل الخاص بي الذي يحتوي على النتيجة وقائمة بالكلمات المعاكسة في هذا المستودع
efzp zzhgl!