يعد التقسيم ("التقسيم") في SQL Server ، مع البساطة الظاهرة ("ما هو موجود - يمكنك نشر الجدول والفهارس حسب مجموعات الملفات ، والحصول على ربح في الإدارة والأداء") موضوعًا موسعًا إلى حد ما. سأحاول أدناه وصف كيفية إنشاء وتطبيق نظام وظيفة وقسم وما هي المشاكل التي قد تواجهها. لن أتحدث عن الفوائد ، باستثناء شيء واحد - تبديل المقاطع ، عند إزالة مجموعة بيانات ضخمة على الفور من جدول ، أو العكس - على الفور تحميل مجموعة لا تقل ضخامة في الجدول.
كما تنص
msdn : "يتم تقسيم بيانات الجداول والفهارس المقسمة إلى كتل يمكن توزيعها عبر عدة مجموعات ملفات في قاعدة البيانات. يتم تقسيم البيانات أفقياً ، بحيث يتم تعيين مجموعات الصفوف إلى أقسام فردية. يجب أن تكون جميع أقسام نفس الفهرس أو الجدول في نفس قاعدة البيانات. يعتبر الجدول أو الفهرس كيانًا منطقيًا منفردًا عند تنفيذ الاستعلامات أو التحديثات على البيانات. "
يتم سرد المزايا الرئيسية أيضا هناك:
- نقل مجموعات فرعية من البيانات والوصول إليها بسرعة وكفاءة مع الحفاظ على سلامة مجموعة البيانات
- يمكن إجراء عمليات الصيانة بشكل أسرع باستخدام قسم أو أكثر ؛
- يمكنك زيادة سرعة تنفيذ الاستعلام ، وفقًا للاستعلامات التي يتم تنفيذها غالبًا في تكوين الجهاز.
بمعنى آخر ، يتم استخدام التقسيم للتحجيم الأفقي. يتم توزيع "الجدول / الفهارس" بواسطة مجموعات ملفات مختلفة ، والتي يمكن أن تكون موجودة على أقراص فعلية مختلفة ، مما يزيد بشكل كبير من راحة الإدارة ويسمح لك ، من الناحية النظرية ، بتحسين أداء استعلامات هذه البيانات - يمكنك إما قراءة القسم المطلوب فقط (بيانات أقل) ، أو قراءة كل شيء بالتوازي (أجهزة مختلفة ، وقراءة بسرعة). في الممارسة العملية ، يكون كل شيء أكثر تعقيدًا إلى حد ما ويمكن أن تؤدي زيادة أداء الاستعلامات إلى الجداول المقسمة إلى العمل فقط إذا كانت الاستعلامات تستخدم التحديد حسب الحقل الذي قسمته. إذا لم تكن لديك بالفعل تجربة مع الجداول المقسمة ، فقط ضع في اعتبارك أن أداء استفساراتك قد لا يتغير ، ولكنه قد يتدهور بعد تقسيم الجدول.
دعنا نتحدث عن الميزة المطلقة التي تحصل عليها بالتأكيد مع التقسيم (ولكن عليك أيضًا أن تكون قادرًا على استخدامها) - هذه زيادة مضمونة في راحة إدارة قاعدة البيانات الخاصة بك. على سبيل المثال ، لديك جدول به مليار سجل ، 900 مليون منها من الفترات القديمة ("المغلقة") وهي للقراءة فقط. بمساعدة القسم ، يمكنك نقل هذه البيانات القديمة إلى مجموعة منفصلة من الملفات للقراءة فقط ، وعمل نسخة احتياطية منها وعدم سحبها في جميع نسخك الاحتياطية اليومية - ستزداد سرعة إنشاء نسخة احتياطية وسيقل الحجم. يمكنك إعادة إنشاء الفهرس ليس على الجدول بأكمله ، ولكن عبر الأقسام المحددة. بالإضافة إلى ذلك ، يزداد توفر قاعدة البيانات الخاصة بك - إذا فشل أحد الأجهزة التي تحتوي على مجموعة الملفات مع القسم ، فستظل الأجهزة الأخرى متوفرة.
لتحقيق الفوائد المتبقية (التبديل الفوري للأقسام ؛ زيادة الإنتاجية) - تحتاج إلى تصميم بنية البيانات وكتابة الاستعلامات على وجه التحديد.
أفترض أنني قد أحرجت القارئ بالفعل بشكل كافٍ والآن يمكنني المضي قدمًا في التدريب.
أولاً ، قم بإنشاء قاعدة بيانات تحتوي على 4 مجموعات ملفات سنقوم بإجراء تجارب عليها:
create database [PartitionTest] on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB) log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB); go alter database [PartitionTest] set recovery simple; go use partitionTest;
إنشاء جدول أننا سوف عذاب.
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
وملء البيانات لمدة عام واحد:
;with nums as ( select 0 n union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9 ) insert into ptest(dt, dummy_int, dummy_char) select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar) from ( select row_number() over(order by (select (null))) rn from nums n1, nums n2, nums n3, nums n4 )t where rn < 8761
يحتوي جدول pTest الآن على سجل واحد لكل ساعة من 2018.
أنت الآن بحاجة إلى إنشاء وظيفة قسم تصف شروط الحدود لتقسيم البيانات إلى أقسام. يدعم SQL Server فقط تقسيم النطاق.
سنقوم بتقسيم جدولنا على العمود dt (وقت / تاريخ) بحيث يحتوي كل قسم على بيانات لمدة 4 أشهر (هنا أنا ثمل - في الواقع ، سوف يحتوي القسم الأول على بيانات لمدة 3 ، والثاني لمدة 4 ، والثالث لمدة 5 أشهر ، ولكن لأغراض العرض - هذه ليست مشكلة)
create partition function pfTest (datetime) as range for values ('20180401', '20180801')
يبدو أن كل شيء طبيعي ، لكنني ارتكبت عمداً "خطأً" واحدًا. إذا نظرت إلى بناء الجملة في
msdn ، فسترى أنه أثناء الإنشاء يمكنك تحديد القسم الذي ستنتمي إليه الحدود المحددة - إلى اليسار أو إلى اليمين. افتراضيًا ، لسبب غير معروف ، يشير الحد المحدد إلى القسم "الأيسر" ، لذلك سيكون من الصحيح في حالتي إنشاء وظيفة قسم كما يلي:
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
بينما أعدم بالفعل:
create partition function pfTest (datetime) as range left for values ('20180401', '20180801')
لكننا سنعود إلى هذا لاحقًا ونعيد إنشاء وظيفة التقسيم الخاصة بنا. في غضون ذلك ، نواصل ما حدث من أجل فهم ما حدث ولماذا لم يكن جيدًا بالنسبة لنا.
بعد إنشاء وظيفة القسم ، ستحتاج إلى إنشاء مخطط قسم. إنه يربط الأقسام بمجموعات الملفات بوضوح:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
كما ترون ، ستكون أقسامنا الثلاثة في مجموعات ملفات مختلفة. الآن حان الوقت لتقسيم طاولتنا. للقيام بذلك ، نحتاج إلى إنشاء فهرس متفاوت المسافات ، وبدلاً من تحديد مجموعة الملفات التي يجب أن تكون موجودة فيها ، حدد نظام التقسيم:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
وهنا أيضًا ، ارتكبت "خطأ" في المخطط الحالي - كان بإمكاني إنشاء فهرس متفاوت المسافات فريد في هذا العمود ، ومع ذلك ، عند إنشاء فهرس فريد ، يجب تضمين العمود المستخدم في القسم في الفهرس. وأريد أن أظهر ما يمكنك مواجهته مع هذا التكوين.
الآن دعونا نرى ما حصلنا عليه في التكوين الحالي (
يتم أخذ الطلب من هنا ):
SELECT sc.name + N'.' + so.name as [Schema.Table], si.index_id as [Index ID], si.type_desc as [Structure], si.name as [Index], stat.row_count AS [Rows], stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB], stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB], p.partition_number AS [Partition

وبالتالي ، حصلنا على ثلاثة أقسام غير ناجحة للغاية - أول بيانات عن المتاجر من بداية الوقت حتى 04/01/2018 00:00:00 شاملة ، والثانية - من 01/01/2018 00:00:01 إلى 08/01/2018 00:00:00 شاملة ، الثالث من 08/01/2018 00:00:01 إلى نهاية العالم (فاتني عمدا جزء من الثانية ، لأنني لا أتذكر مع ما تدرج SQL Server يكتب هذه الكسور ، ولكن المعنى ينتقل بشكل صحيح).
قم الآن بإنشاء فهرس غير عنقودي في حقل dummy_int ، "محاذاة" وفقًا لنظام التقسيم نفسه.
لماذا نحتاج إلى فهرس موحد؟نحتاج إلى فهرس محاذاة حتى نتمكن من إجراء عملية تبديل قسم (رمز التبديل) - وهذه واحدة من تلك العمليات التي ، في كثير من الأحيان ، تتكلف عن التقسيم. إذا كان هناك فهرس غير محاذٍ واحد على الأقل في الجدول ، فلا يمكنك تبديل هذا القسم
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
ودعونا نرى لماذا قلت أن استفساراتك قد تصبح أبطأ بعد تنفيذ التقسيم. قم بتشغيل الطلب:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 SET STATISTICS TIME, IO OFF;
ودعونا نرى إحصائيات التنفيذ:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
وخطة التنفيذ:

نظرًا لأن الفهرس الخاص بنا "محاذاة" حسب الأقسام ، فإن كل قسم له فهرسه الخاص ، وهو "غير متصل" مع فهارس في أقسام أخرى. لم نفرض شروطًا على الحقل الذي يتم به تقسيم الفهرس ، لذلك يضطر SQL Server إلى تنفيذ Index Seek في كل قسم ، في الواقع ، 3 Search Seek بدلاً من واحد.
دعنا نحاول استبعاد قسم واحد:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 and dt < '20180801' SET STATISTICS TIME, IO OFF;
ودعونا نرى إحصائيات التنفيذ:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
نعم ، تم استبعاد قسم واحد وتم إجراء البحث عن القيمة المطلوبة في قسمين فقط.
هذا شيء يجب تذكره عند اتخاذ قرار بشأن التقسيم. إذا كانت لديك استعلامات لا تستخدم قيودًا على الحقل الذي يتم به تقسيم الجدول ، فقد تواجهك مشكلة.
لم نعد نحتاج إلى فهرس غير عنقودي ، لذا أحذفه
drop index nix_pTest_dummyINT on pTest;
ولماذا كان هناك حاجة إلى فهرس غير عنقودي؟بشكل عام ، لم أكن في حاجة إليها ، يمكنني إظهار الشيء نفسه مع فهرس الكتلة ، لا أعرف لماذا قمت بإنشائه ، لكن منذ أن صنعته وأعدت لقطات شاشة - لا أفقد الخير
الآن ، ضع في اعتبارك السيناريو التالي: نقوم بأرشفة البيانات من هذا الجدول كل 4 أشهر - نزيل البيانات القديمة ونضيف قسمًا للأشهر الأربعة القادمة (يتم وصف تنظيم "النافذة المنزلقة" في msdn وكومة المدونات).
نقسم المهمة إلى مهام فرعية صغيرة ومفهومة:
- إضافة قسم للبيانات من 01/01/2019 إلى 04/01/2019
- إنشاء جدول مرحلة فارغ
- بدّل قسم البيانات حتى 04/01/2018 في جدول المرحلة
- تخلص من القسم الفارغ
دعنا نذهب:
1. نعلن أنه سيتم إنشاء القسم الجديد في مجموعة ملفات FG1 ، لأنه سيتم تحريره قريبًا منا:
alter partition scheme psTest next used [FG1];
وتغيير وظيفة التقسيم عن طريق إضافة حد جديد:
SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
نحن ننظر إلى الإحصاءات:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
هناك 8809 صفحة في الجدول (فهرس الكتلة) ، وبالتالي فإن عدد القراءات ، بالطبع ، يتجاوز الخير والشر. دعونا نرى ما لدينا الآن في أقسام.

بشكل عام ، كل شيء كما هو متوقع - ظهر قسم جديد ذو حدود عليا (تذكر أن شروط الحدود بالنسبة لنا تنتمي إلى القسم الأيسر) 01/01/2019 وقسم فارغ سيكون فيه بيانات أخرى ذات تاريخ أطول.
يبدو أن كل شيء على ما يرام ، ولكن لماذا توجد العديد من القراءات؟ ننظر بعناية في الشكل أعلاه ، ونرى أن البيانات من القسم الثالث التي كانت في FG3 انتهى بها المطاف في FG1 ، ولكن القسم التالي ، فارغ ، في FG3.
2. إنشاء جدول المرحلة.
للتبديل (التبديل) إلى قسم إلى جدول والعكس ، نحتاج إلى جدول فارغ يتم فيه إنشاء جميع القيود والفهارس نفسها كما في جدولنا المقسم. يجب أن يكون الجدول في نفس مجموعة الملفات مثل القسم الذي نريد "التبديل" فيه. يقع القسم الأول (المحفوظ) في FG1 ، لذلك نقوم بإنشاء جدول وفهرس كتلة في نفس المكان:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id) on [FG1];
لا تحتاج إلى تقسيم هذا الجدول.
3. الآن نحن مستعدون للتبديل:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
وهنا ما حصلنا عليه:
4947, 16, 1, 59 ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
مضحك ، دعونا نرى ما لدينا في المؤشرات:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column from sys.indexes i join sys.objects o on i.object_id = o.object_id join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id where o.name in ('pTest', 'stageTest')
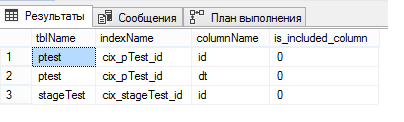
تذكر ، لقد كتبت أنه من الضروري عمل فهرس متفاوت المسافات فريد على جدول مقسم؟ هذا هو بالضبط السبب في أنه كان ضروريا. عند إنشاء فهرس متفاوت المسافات فريدًا ، سيطلب SQL Server تضمين العمود الذي نقسم به الجدول في الفهرس بشكل صريح ، لذا أضافه بنفسه ونسى أن يقول ذلك. وأنا حقا لا أفهم السبب.
لكن ، بشكل عام ، المشكلة مفهومة ، نقوم بإعادة إنشاء فهرس الكتلة على طاولة المرحلة.
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
والآن ، مرة أخرى ، نحاول تبديل القسم:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
سد تا! تم تبديل القسم ، راجع ما كلفنا:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
لكن لا شيء. إن تحويل قسم إلى جدول فارغ والعكس صحيح (جدول كامل إلى قسم فارغ) هو عملية فقط على البيانات الوصفية وهذا هو بالضبط السبب في أن التقسيم شيء رائع للغاية.
دعونا نرى ما هو مع أقسامنا:

وكل شيء رائع معهم. في القسم الأول ، لا توجد سجلات يسار ، وتركوا بأمان لجدول stageTest. يمكننا المضي قدما
4. كل ما تبقى بالنسبة لنا هو حذف القسم الأول الفارغ. دعونا نفعل ذلك ونرى ما سيحدث:
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
وهذه أيضًا عملية فقط على البيانات الوصفية ، في حالتنا. نحن ننظر إلى الأقسام:

لدينا ، كما كان ، 3 أقسام فقط ، كل في مجموعة الملفات الخاصة به. المهمة أنجزت. ما يمكن تحسينه هنا؟ حسنًا ، أولاً ، أود أن تشير قيم الحدود إلى الأقسام "الصحيحة" ، بحيث تحتوي الأقسام على جميع البيانات لمدة 4 أشهر. وأود أن أرى إنشاء قسم جديد أقل تكلفة. قراءة البيانات عشر مرات أكثر من الجدول نفسه - تمثال نصفي.
لا يمكننا فعل أي شيء مع الأول الآن ، ولكن مع الثاني سنحاول. لنقم بإنشاء قسم جديد يحتوي على بيانات من 01/01/2019 إلى 04/01/2019 ، وليس حتى نهاية الوقت:
alter partition scheme psTest next used [FG2]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190401'); SET STATISTICS TIME, IO OFF;
ونحن نرى:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
ها! حتى الآن هذه العملية هي فقط على البيانات الوصفية؟ نعم ، إذا "قسمت" قسمًا فارغًا - فهذه عملية فقط على البيانات الوصفية ، لذلك سيكون القرار الصحيح هو الاحتفاظ بكل من القسمين الفارغين الأيسر والأيسر المضمونين ، وإذا لزم الأمر ، حدد قسمًا جديدًا - "قصهما" من هناك.
الآن ، لنرى ما يحدث إذا أردت إرجاع البيانات من جدول المرحلة إلى الجدول المقسم. للقيام بذلك ، سأحتاج إلى:
- إنشاء قسم جديد على اليسار للبيانات
- بدّل الجدول إلى هذا القسم
نحن نحاول (وتذكر أن stageTest في FG1):
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20180401'); SET STATISTICS TIME, IO OFF;
نحن نرى:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
حسنًا ، ليس سيئًا ، أي قراءة فقط القسم الأيسر (الذي نقسمه) وهذا كل شيء. حسنا. لتبديل جدول غير فارغ غير مقسم إلى قسم جدول مقسم ، يجب أن يكون للجدول المصدر قيود حتى يعرف SQL Server أن كل شيء سيكون على ما يرام ويمكن التبديل كعملية على البيانات الأولية (بدلاً من قراءة كل شيء على التوالي والتحقق مما إذا كان القسم يطابق الشروط أم لا ):
alter table stageTest add constraint check_dt check (dt <= '20180401')
محاولة التبديل:
SET STATISTICS TIME, IO ON; alter table stageTest switch to pTest partition 1 SET STATISTICS TIME, IO OFF;
إحصائيات:
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 39 ms.
مرة أخرى ، العملية هي فقط على البيانات الوصفية. نحن ننظر إلى ما هو مع أقسامنا:

حسنا. يبدو فرزها. والآن سنحاول إعادة إنشاء مخطط الوظيفة والتقسيم (لقد حذفت مخطط التقسيم ووظيفته ، وأعدت إعادة ملء الجدول وأعدت إنشاء فهرس نظام المجموعة باستخدام نظام التقسيم الجديد):
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
لنرى ما الأقسام التي لدينا الآن:

حسنًا ، لدينا الآن ثلاثة أقسام "منطقية" - من بداية الوقت حتى 04/01/2018 00:00:00 (غير شاملة) ، من 04/01/2018 00:00:00 (ضمناً) إلى 08/01/2018 00:00:00 ( ليست شاملة) والثالثة ، كل ما هو أكبر من أو يساوي 01/01/2018 00:00:00.
الآن ، دعونا نحاول أداء نفس مهمة أرشفة البيانات التي أجريناها باستخدام وظيفة القسم السابق.
1. أضف قسمًا جديدًا:
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
نحن ننظر إلى الإحصاءات:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
ليس سيئا ، على الأقل معقول - قراءة فقط القسم الأخير. نحن ننظر إلى ما لدينا في الأقسام:

لاحظ الآن أن القسم الثالث المكتمل قد بقي في مكانه في FG3 ، وأنشئ قسم فارغ جديد في FG1.
2. نقوم بإنشاء جدول مرحلة وفهرس مجموعة CORRECT عليه
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3. التبديل القسم
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
تقول الإحصاءات أن عملية البيانات الوصفية هي:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
الآن ، كل ذلك دون مفاجآت.
4. إزالة القسم غير الضروري
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
وهنا لدينا مفاجأة:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
نحن ننظر إلى ما لدينا مع الأقسام:

وهنا يصبح واضحًا: تم نقل القسم رقم 2 من مجموعة ملفات fg2 إلى مجموعة ملفات fg1. الطبقة. هل يمكننا فعل شيء حيال ذلك؟
ربما نحتاج فقط إلى امتلاك قسم فارغ و "تدمير" الحد الفاصل بين القسم الأيسر "الفارغ دائمًا" والقسم الذي "حولناه" إلى جدول آخر.
في الختام:- استخدم بناء الجملة الكامل لإنشاء وظيفة التقسيم ، ولا تعتمد على القيم الافتراضية - فقد لا تحصل على ما تريد.
- حافظ على اليسار واليمين في القسم الفارغ - سيكونان مفيدان للغاية لك عند تنظيم "نافذة منزلقة".
- قم بتقسيم مقاطع غير فارغة ودمجها - يؤلمك دائمًا ، وتجنب ذلك إن أمكن.
- تحقق من استفساراتك - إذا لم تستخدم عامل التصفية حسب العمود الذي تنوي به تقسيم الجدول وتحتاج إلى القدرة على تبديل المقاطع - يمكن أن يقل أداءها بشكل ملحوظ.
- إذا كنت ترغب في القيام بشيء ما ، فاختبر أولاً عدم الإنتاج.
نأمل أن المواد كانت مفيدة. ربما اتضح أنه تم تفتيتها ، إذا كنت تعتقد أن شيئًا ما لم يتم الإفصاح عنه ، اكتب ، سأحاول الانتهاء منه. شكرا لاهتمامكم