
في
مقال سابق
، أخبرت بتاريخًا موجزًا عن تطور المنتجات الداخلية والخارجية لـ DublGIS. اليوم ننتقل إلى تفاصيل تطوير أحد المنتجات ، وهي تصدير البيانات. سأتحدث عن بنية المشروع والحلول التقنية الفردية التي سمحت لنا بالتطوير التدريجي للمشروع وتكييفه مع المتطلبات المتغيرة مع مرور الوقت.
ملخص موجز للمادة الأخيرة
هناك العديد من المنتجات الداخلية التي تجمع كميات كبيرة من بيانات الخريطة ، ودليلًا للمؤسسات ، والإعلانات ، وتعليقات المستخدمين ، والتعليقات ، والصور ، وتحليلات متنوعة. تتواصل هذه المنتجات مع بعضها البعض عبر ناقل البيانات أو عبر Rest Api. وهناك عملية تصدير منفصلة تقوم بجمع كل هذه البيانات في كومة ، وتقوم بمعالجتها وتحليلها بالتنسيق المطلوب ، وتعبئ وتشكل "حزمة" جاهزة للتسليم إلى منتجاتها النهائية. يتم التسليم إما من خلال خادم التحديث للكمبيوتر وإصدارات الأجهزة المحمولة ، أو في الواجهة الخلفية عبر الإنترنت ، في الواقع ، الإصدار عبر الإنترنت من 2GIS.
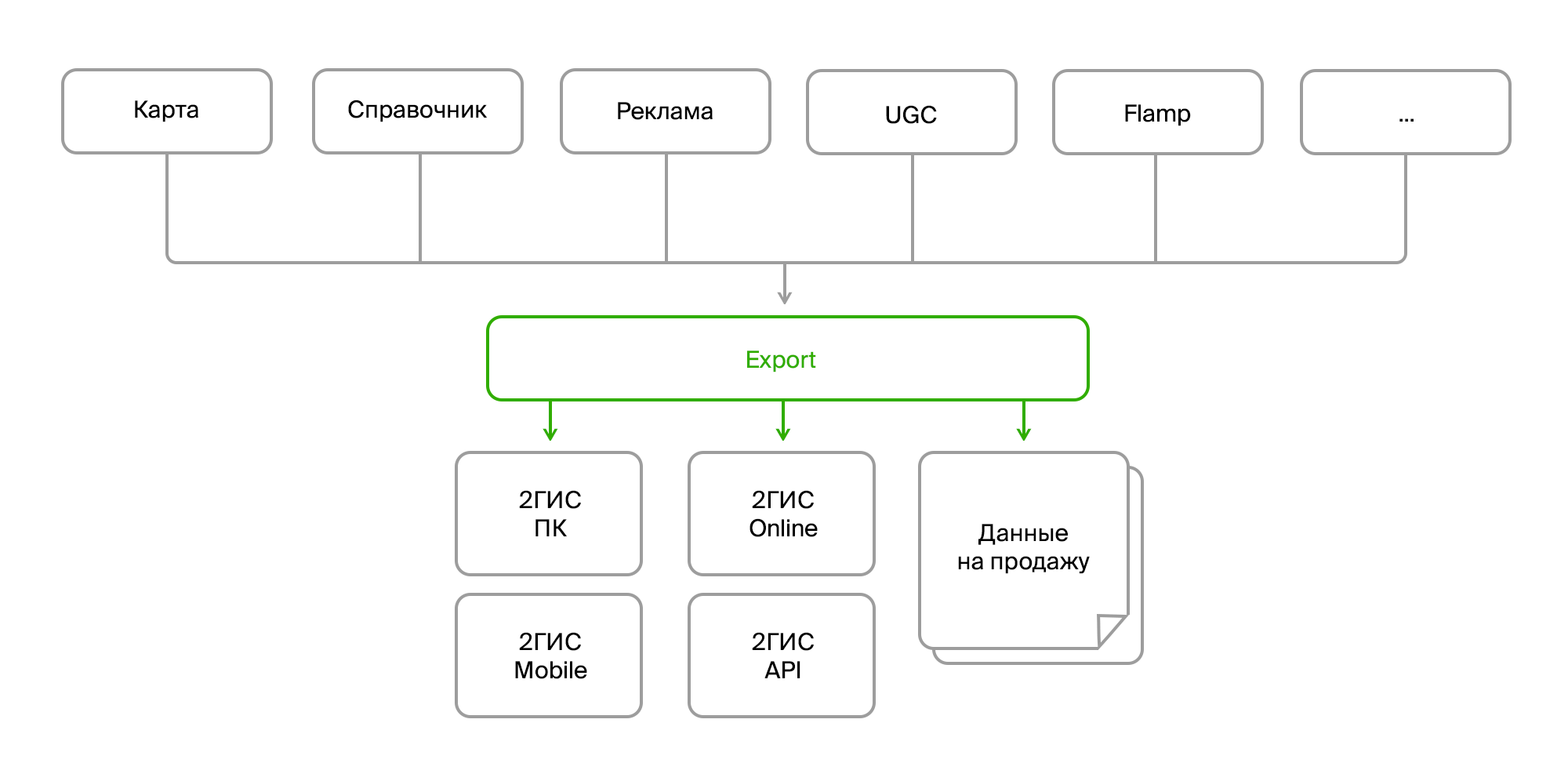
مصدر البيانات
عند المدخل لدينا:
- عدة مصادر لنفس البيانات ؛
- طرق تسليم مختلفة (Firebird ، bus ، FTP ، RestAPI) ؛
- بنية مختلفة من نفس الأشياء ؛
- تغييرات ثابتة في بنية البيانات ؛
- تنسيقات مختلفة (بيانات أولية في قاعدة البيانات ، XML ، JSON).
من وجهة نظر المستهلك:
- مرة أخرى ، تنسيقات مختلفة (تنسيقات البيانات الخاصة بها لإصدارات مختلفة من المنتج ، تنسيقات منفصلة للبيع) ؛
- تغييرات شكل ثابت.
- البيانات المجمعة (تحتاج إلى دمج كائنات مختلفة في واحد ، وجمع البيانات على الشركة من جميع الفروع ، وتكميلها بروابط إلى الصور ، والمراجعات ، وأقرب توقف ، وما إلى ذلك) ؛
- معالجة ما قبل وما بعد المعالجة المعقدة (تحديث بعض البيانات على أساس بيانات أخرى ، وتحويل البيانات ، وإنشاء بيانات مفقودة ، على سبيل المثال ، ترتيب الشعارات المصغرة للإعلان على المباني ، وحذف أو تصحيح البيانات الخاطئة) ؛
- متطلبات تناسق البيانات وصلاحيتها ؛
- جميع البيانات مطلوبة.
هنا يجدر التركيز على الفقرة الأخيرة. كما تعلمون ، فإن الميزة الرئيسية لـ 2GIS هي العمل دون اتصال بالإنترنت. أي أن معظم البيانات التي تراها في أجهزة الكمبيوتر والإصدارات المحمولة الخاصة بنا تقع على جهازك. ولكن هذه مجموعة ضخمة: مئات الآلاف من الكائنات الجغرافية (البحار والغابات والأنهار والطرق والمباني والمداخل والشرفات والتوقيعات وخطط الأرضية والنماذج ثلاثية الأبعاد) وعشرات ومئات الآلاف من الشركات وفروعها مع جهات الاتصال وساعات العمل والسمات الإضافية مثل متوسط الفاتورة وتوافر خدمة الواي فاي. وبالطبع النصوص والإعلانات.
وكل شيء يتغير باستمرار ، وأضاف ، حذف.
وحتى لا نغرق في هذا التدفق الذي لا ينتهي من التغييرات ، عند تطوير بنية التصدير ، كان علينا التركيز على العديد من المجالات الرئيسية:
- مصادر البيانات
- طرق التسليم ؛
- خوارزميات المعالجة ؛
- تنسيقات بيانات المستهلك.
نحن مجردة من مصادر مختلفة وتنسيقات البيانات
تعرض المصادر المختلفة الصعوبات التالية:
- أنها تعطي نفس البيانات في أشكال مختلفة ؛
- لديهم مجموعة مختلفة من الكيانات أو السمات التي تحتاج إلى الحد إلى كائن مجال واحد.
هذه مشكلة قياسية إلى حد ما ، ويتم حلها بشكل قياسي. نحتاج فقط إلى إنشاء واجهة لتلقي البيانات ، وهناك تطبيق محدد يسير بالفعل حيث تكون هناك حاجة إليه وسوف نحصل على البيانات بالشكل الذي نحتاج إليه.

مثال على الواجهة:
public interface ISource : IDisposable { ISourceReader GetDeletedRows(); ISourceReader GetInsertedOrUpdatedRows(); byte[] GetDataVersion(); } public interface ISourceReader : IDisposable { bool Read(); object this[string columnName] { get; } }
مثال على تنفيذ الشركات الحائزة:
internal class FirmSetSource : ISource { public ISourceReader GetDeletedRows() { if(_lastDataVersion == null) return null; var query = DataContext.ExecuteObject<EsbFirmDeleted>(_lastDataVersion); return new DeletedIdsSourceReader<long>( query.Select(x => x.Id).GetEnumerator()); } public ISourceReader GetInsertedOrUpdatedRows() { return new EnumeratorSourceReader(typeof(FirmSet), GetNewOrChangedRows().GetEnumerator()); } public virtual byte[] GetDataVersion() { return DataContext.ExecuteObject<EsbFirm>().Max(x => x.RowVersion); } }
هذا التجريد يسمح لنا جزئيًا بحل المشكلة من خلال الاختلافات في نموذج المجال ، ولكن ليس تمامًا. يتمثل أحد القيود المهمة في الحاجة إلى تلقي البيانات بشكل تدريجي ، أي لتلقي التحديثات الخاصة بهم فقط ، وليس لامتصاص كل شيء في كل مرة. في هذه الحالة ، من غير المريح تتبع العلاقة بين البيانات من أجل جمع بعض المجاميع. ومن الصعب نسبيًا القيام بكل شيء دون أخطاء. لذلك ، قررنا في هذه المرحلة أن نستخلص البيانات من المصادر من واحد إلى واحد ، وسنحل المشكلة مع نموذج المجال على مستوى مختلف.
نموذج المجال
من أجل عدم الاعتماد على التغييرات في مجموعة البيانات وهيكلها في مصادر البيانات ، تم إنشاء قاعدة بيانات التصدير بقائمة الجداول المستقرة نسبيًا ، والتي سقطت في النهاية على نطاقنا. إذا لم يكن للمصدر 1 أي سمات للكيان A (كائن البيانات في الصورة التالية) ، فسيحصلون إما على قيمة افتراضية أو كانوا اختياريين. وإذا كان الكيان B عبارة عن نوع من تجميع بيانات المصدر أو حتى مصادر مختلفة ، فيمكن الحصول على كل جزء على حدة ثم تجميعه ككل في المرحلة التالية.

نحن مجردة من طريقة تسليم البيانات
في الواقع ، وجود قاعدة البيانات الخاصة بك في التصدير وظهور واجهة
ISourceReader بالفعل حل هذه المشكلة. ولكن هناك نقطة واحدة لم يتم حلها: نماذج مختلفة قليلاً للحصول على البيانات. في إحدى الحالات ، نقوم بالسحب والحصول على لقطة في اللحظة الحالية ، وفي الحالة الأخرى - دلتا التغييرات على الحافلة ، في الحالة الثالثة - أيضًا الحالة الحالية في وقت الطلب ، ولكن مع معلومات حول الكائنات المحذوفة من لحظة الطلب السابق.
لتحقيق التوحيد في حديقة الحيوان هذه ، سنضيف قاعدة بيانات أخرى ندمج فيها جميع البيانات من جميع المصادر.
تحصل على مثل هذه الصورة.
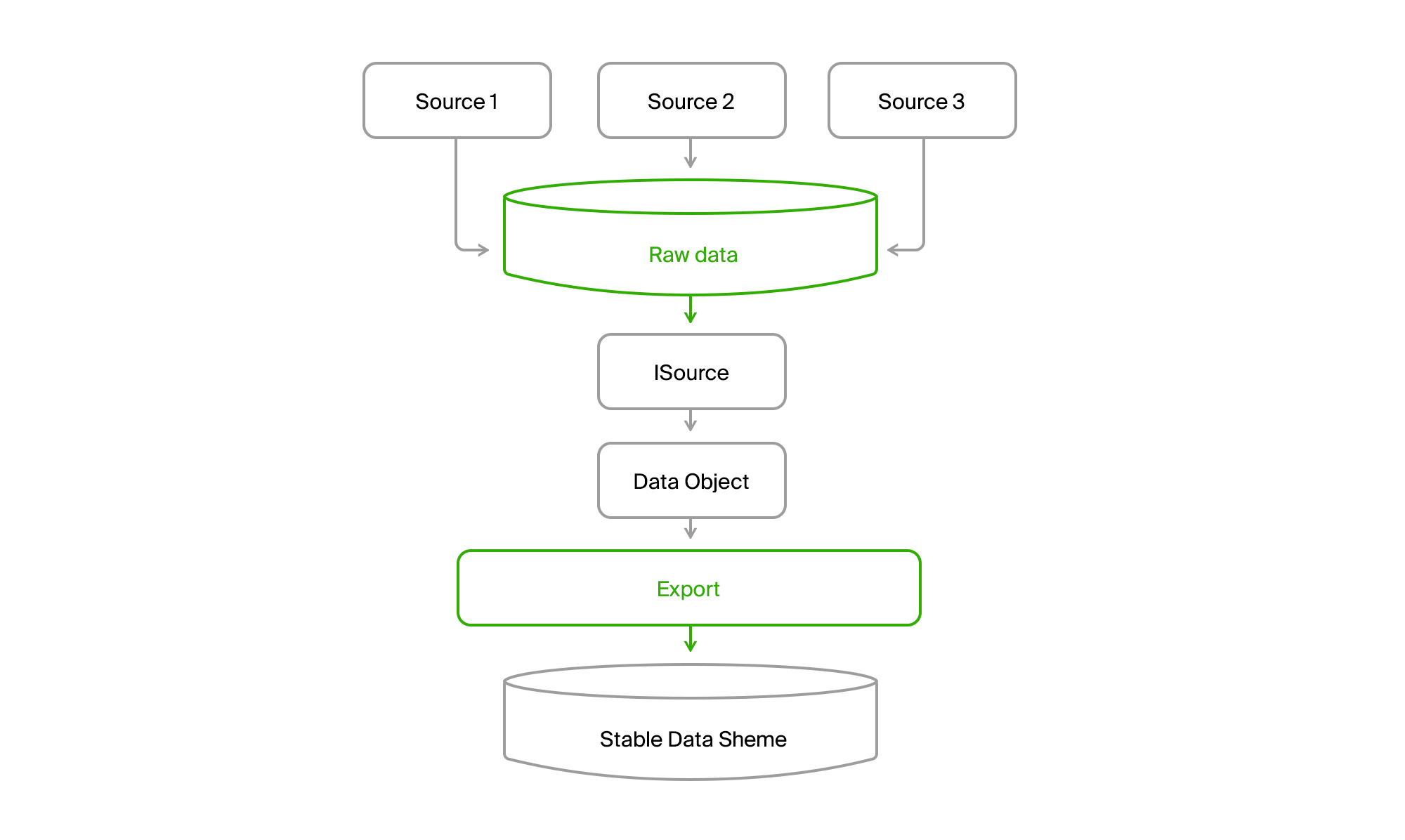
نتيجة لذلك ، نقرأ جميع البيانات من أي قناة في جميع المدن إلى قاعدة البيانات المركزية. دائمًا ما يتم التسليم بشكل تدريجي ، أي أن التغييرات تأتي فقط. و DGPP القديم ، على قيد الحياة ، لا يزال مصدرا بديلا. كان قادرا على ضخ البيانات من DBMS إلى آخر لم يكن أي.
علاوة على ذلك ، قام التصدير عبر ISource بسحب بيانات المدينة من DGPP أو EMDB إلى قاعدة بيانات المزامنة المستقرة وتحويلها إلى نموذج المجال الخاص بها.
ثم يبقى فقط لمعالجتها وتحميلها في تنسيقات المستهلك.
المستخلص من خوارزميات إعداد البيانات
وهنا تنشأ صعوبة أخرى. أولاً ، يريد المستهلكون المختلفون البيانات بتنسيقاتها. علاوة على ذلك ، يريدون مجموعات بيانات مختلفة. وفي التذييل ، يجب أن تكون البيانات غير المتصلة مضغوطة ومهيكلة قدر الإمكان حتى يمكن قراءتها بسرعة. نتيجة لذلك ، نحصل على تنسيقات ثنائية تم تطويرها بواسطة فرق المنتجات النهائية. وهؤلاء هم الرجال الذين يعملون على كومة تقنية مختلفة تماما. لدينا المألوف والمحبوب لتطوير الخلفية .NET وفي بعض الأحيان جافا ، لديهم أساسا C ++ وبيثون.
بشكل عام ، حديقة الحيوان للتكنولوجيا.
في فجر التطور السريع ، عندما كان لدينا فقط DGPP (راجع
المقال السابق) وإصدار PC 2GIS ، كان تنسيق البيانات النهائية هو binar ، الذي أعدته مكتبة خاصة مكتوبة في C ++ وملفوفة في كائن COM. يبدو من عدم تكامل كود غير متجانسة. نقوم بتوصيل المرجع ، يتم إنشاء واجهة .NET - وقيادتها. وأول مرة فعلنا.
لكن ، كالعادة ، ظهرت مشكلتان.
- بدأت بياناتنا تنمو بسرعة. ظهرت أنواع جديدة من البيانات ، مدن كبيرة جديدة مثل موسكو.
- بدأت أنظمة تشغيل X64 بت في الانتشار بنشاط.
- هناك حاجة إلى تصحيح المشكلات في COM بطريقة ما.
دعنا نذهب من خلال النقاط.
أدى نمو البيانات التي تحتاجها منتجاتنا بالكامل إلى حقيقة أن معالجتها بدأت تستهلك كمية كبيرة من ذاكرة الوصول العشوائي. وبعد توصيل مكتبة COM بعملية .NET الخاصة بنا x86 ، تلقينا تلقائيًا عملية x86 ، أي كحد أقصى من عملاء 3Gb مع زيادة مساحة العنوان. لم يكن لدى الفرق دعم مكتبة لموارد x64 ، لكن المكتبة نفسها لديها القدرة على استخدام القرص بدلاً من الذاكرة ، مما أدى إلى تخفيف المشكلة إلى حد ما.
ولكن التصحيح لا يزال صعبا للغاية. كان من الضروري بدء التصدير ، والانتظار حتى يتم إعداد البيانات ، والبدء في إضافة هذه البيانات إلى المكتبة. وبعد ظهور الخطأ ، يجب أن تفهم من السجلات ما حدث من خطأ وأن تكرر العملية مرة أخرى. ليست جيدة ، سيئة للغاية.
الحل كالمعتاد على السطح. يكفي أن تأخذ كل الشفرة الأجنبية في عملية منفصلة ، وأن تنشئ اتصالاً من خلال ملفات وسيطة بتنسيق ثنائي أو نص بسيط.
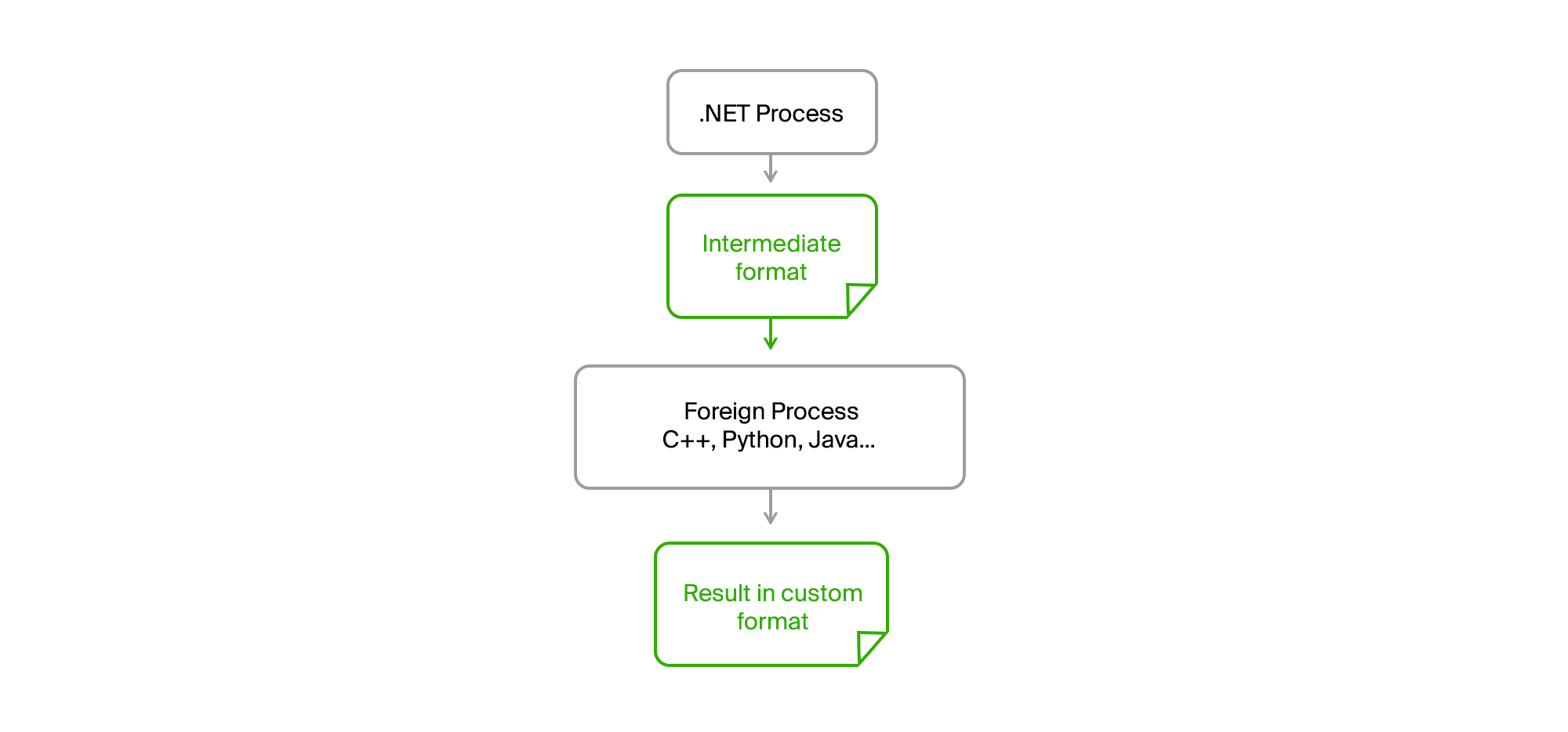
نتيجة لذلك ، أصبحت عملية .NET الأصلية لدينا تمامًا أي وحدة المعالجة المركزية. لم يعد هناك أي تسرب للذاكرة أو أخطاء فادحة في رمز الجهة الخارجية التي أثرت عليه. أعد التصدير البيانات ، وحملها على ملف وسيط ، وقام بتغذيتها إلى الأداة وتلقى النتيجة منها أيضًا في شكل ملف. كتب شباب الفرق الخارجية خوارزمياتهم بلغاتهم الخاصة (C ++ أو Python) ويمكنهم تصحيحها في بيانات حقيقية في حالة وجود أخطاء على أجهزتهم دون الحاجة إلى بدء التصدير.
كان علينا فقط تشكيل اتفاقات على واجهة الأداة المساعدة ، والتي تم توفيرها مع وقت التشغيل ، وكان لدينا قائمة متفق عليها من المعلمات المطلوبة ، وعرض رسائل المعلومات والأخطاء في stdout بالتنسيق المطلوب.
 مثال على تنسيق النص الوسيط
مثال على تنسيق النص الوسيطالنتائج
تحدثت في المقالة عن بعض الأساليب التي استخدمناها في مستويات مختلفة من التطبيق لعزل عملية إعداد البيانات:
- اختبأ تفاصيل الوصول إلى مصادر البيانات وراء واجهات ؛
- المستخرجة من قنوات توصيل البيانات باستخدام التخزين الوسيط ؛
- اجعل نطاقك مستقرًا وقم بتحويل البيانات الأصلية إليه ؛
- نفذت المراحل الفردية من معالجة البيانات في العمليات والرمز المستخدم بلغات أخرى.
شكرا للوصول الى النهاية. سأجيب على جميع الأسئلة في التعليقات ، تأكد من طرحها.