توضح هذه المقالة عملية تحليل جملة اللغة الروسية باستخدام قواعد اللغة الخالية من السياق وخوارزمية تحليل LR.
معالجة اللغة الطبيعية هي الاتجاه العام للذكاء الاصطناعي واللغويات الرياضية. يدرس مشاكل تحليل الكمبيوتر وتوليف اللغات الطبيعية.
بشكل عام ، عملية تحليل جمل اللغة الطبيعية هي كما يلي: (1) تقسيم الجمل إلى وحدات نحوية - الكلمات والعبارات ؛ (2) تحديد المعلمات النحوية لكل وحدة ؛ (3) تعريف العلاقة النحوية بين الوحدات. الإخراج هو شجرة تحليل مجردة.
1. تقسيم الجمل إلى وحدات نحوية
جملة اللغة الطبيعية تتكون من أشكال الكلمات والعبارات القوية. ويطلق على عدد من أشكال الكلمة من كلمة معينة نموذجا.
على سبيل المثال
"": [, , , , , ]
لا تتغير العبارات - الاقتران المركب أو المسند أو التعبيرات المستقرة - ولا يمكن تقسيمها إلى وحدات أصغر دون فقدان المعنى. علاوة على ذلك ، نعني بكلمة أي وحدة نحوية - شكل كلمة أو عبارة.
يتم تحديد كل كلمة في الجملة بثلاث مرات:
- شكل كلمة / سلسلة كلمة ("كتب")
- الشكل العادي للكلمة ("الكتابة")
- مجموعة من المعلمات النحوية (['VERB' ، 'sing' ، 'musc' ، 'tran' ، 'past'])
وبالتالي ، فإن انهيار الجملة "من
الواضح أنه لن يحضر الاجتماع " سيكون بالشكل التالي:
[' ', '', '', '', '', ''] ' ' - ,
2. تعريف المعلمات النحوية (القواعد)
الجرام عنصر من عناصر الفئة النحوية. قواعد مختلفة من نفس الفئة هي حصرية بشكل متبادل ولا يمكن التعبير عنها معا. لكل شكل كلمة ، نحدد مجموعة من سبعة قواعد:
[ , , , , , , ]
كمصدر ، سوف نستخدم قاموس
OpenCorpora وواجهته ،
pymorphy2 . للبحث عن قاعدة في القواعد النحوية لمجموعة معينة من الغرامات ، سنقدمها بشكل عام:
'' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None] '?' ,
3. تعريف العلاقة النحوية بين الكلمات
لتحديد العلاقة النحوية بين الكلمات ، سوف نستخدم التحليل النحوي والسياق الخالي من السياق.
تحليل قواعد اللغة والقواعد اللغوية
قواعد اللغة الرسمية هي وسيلة لوصف لغة في شكل ما يسمى بالإنتاج. على سبيل المثال:
a -> ab | ac
تعني القاعدة "أ" تفرخ "ab" أو "ac".
Nonterminals هي كائنات تدل على أي جوهر للغة (الجملة ، الصيغة ، وما إلى ذلك).
المحطات الطرفية - الكائنات الموجودة مباشرة في اللغة المطابقة للقواعد النحوية والتي لها معنى محدد لا يتغير (حروف ، كلمات ، صيغ ، إلخ). القواعد النحوية الخالية من السياق هي قواعد نحوية يكون فيها الجانب الأيسر من جميع المنتجات عبارة عن وحدات طرفية غير مفردة.
لوصف اللغة الروسية ، سوف نستخدم نظرية القواعد النحوية للمكونات (
قواعد بنية العبارة ) ، والتي تدعي أن أي وحدة نحوية معقدة تتكون من وحدتين أبسط وليس متقاطعتين ، تسمى مكوناتها المباشرة. المكونات التالية تتميز:
(1) المجموعة الاسمية (NP) NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
بمعنى ، عبارة اسمية اسمية عبارة عن اسم في الحالة الاسمية أو صفة في الحالة الاسمية + عبارة اسمية اسمية أو أخرى.
(2) المجموعة اللفظية (VP) VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
بمعنى آخر ، مجموعة الفعل متعدية هي فعل متعدية + مجموعة اسمية أو مجموعة صفة قصيرة + مجموعة فعلية أو أخرى.
(3) المجموعة الجر (PP) PP -> PREP NP[case='datv'] | ...
مجموعة حروف الجر هي حروف جر + مجموعة اسمية اسمية او اخرى.
(4) العرض الكامل (S) S -> NP[case='nomn'] VP[tran]
توجد جملة كاملة إذا كانت مجموعات الاسم والفعل متطابقة في العدد والشخص والجنس.
def agreement(self, node_left, node_right): ... if (numb1 and numb2): if (numb1 != numb2): return False; if (per1 and per2): if (per1 != per2): return False; if (gend1 and gend2): if (gend1 != gend2): return False; return True;
الجملة غير المكتملة هي جملة حيث يتم حذف الجزء الاسمي. كقاعدة عامة ، في مثل هذه الجمل يتم التعبير عن مجموعة الفعل بواسطة فعل غير شخصي. على سبيل المثال ، "
أريد أن أمشي " ، "لقد أصبح
الضوء ". الجملة الإهليلجية هي جملة حيث يتم حذف جزء الفعل ، ويتم استبداله بشرطة. على سبيل المثال ، "
خلف الغابة توجد غابة. إلى اليمين واليسار توجد مستنقعات ."
لتحديد ما إذا كانت هذه الجملة تنتمي إلى لغة القواعد ، سنستخدم خوارزمية تحليل LR. تتضمن هذه الخوارزمية إنشاء شجرة تحليل من أسفل لأعلى (من الأوراق إلى الجذر). العنصر الرئيسي في الخوارزمية هو طريقة "تحويل الإلتواء" (
تقليل التحول في اللغة الإنجليزية):
(1) نقرأ أحرف خط الإدخال حتى توجد سلسلة تتطابق مع الجانب الأيمن من أي من القواعد ، ونضع السلسلة الموجودة في الحزمة (نقل) ؛
(2) استبدال السلسلة الموجودة بالقاعدة من القواعد (الالتفاف).
إذا تم التفاف كل سلاسل الأوتار ، فإن هذه الجملة تنتمي إلى اللغة النحوية ، وهناك شجرة تحليل واحدة على الأقل.
خشبلتمثيل الاتصال النحوي ، تستخدم الجملة شجرة ثنائية ، حيث يترك هي الكلمات (محطات) مع مجموعة من غرام ، والعقد هي قواعد (preterminals). والجذر هو الجملة (غير الطرفية).
يتم تعريف عقدة شجرة كما يلي:
class Node: def __init__(self, word=None, tag=None, grammemes=None, leaf=False): self.word = word;
يبدأ بناء شجرة بأوراق يتم تعيين سلسلة من الكلمات أو العبارات إليها ، وكذلك مجموعة من قواعدها.
def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)
بعد ذلك ، يتم إجراء تحليل LR. كل الالتواء يتوافق مع اتحاد العقدتين أو الأوراق تحت سلف مشترك. يتم تعيين علامة سلف سابقة للعنصر القديم تتوافق مع القواعد النحوية ، بالإضافة إلى ذلك ، يقبل الجد قواعد اللغة للعضو الرئيسي في المجموعة ، على سبيل المثال ، في مجموعة الفعل V [tran] PRCL (على سبيل المثال
"يود" ) ، سيتم أخذ العلامات من الفعل التعددي V [tran] ، ليس من الجسيمات من PRCL. وفي المجموعة الاسمية NP [case = 'nomn'] NP [case = 'gent'] (مثل
"والد الأطفال" ) سيتم أخذ العلامات من الاسم في الاسم الترويجي.
من المهم ملاحظة أن الالتواء يحدث بالترتيب المحدد:
def reduce(self): self.reduce_ADJ() # self.reduce_NP() # self.reduce_PP() # self.reduce_VP() # self.reduce_S() #
هذا الترتيب مهم لأنه يستبعد إمكانية "فقدان" بعض أعضاء الاقتراح. أولاً ، يتم تشكيل الصفات مع المعدلات (على سبيل المثال
جميلة بجنون ) ، ثم المجموعات الاسمية ، حرف الجر وأخيرا اللفظي. بعد ذلك ، يتم البحث عن جمل كاملة / غير كاملة ، وإذا لم تكن هناك أي جمل ، فإن الشجرة ليس لها جذر ، وبالتالي فإن الجملة لا تنتمي إلى لغة القواعد.
النظر في مثال مشروط لبناء شجرة:
sent = " " def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn'] NP[case='accs'] -> N[case='accs'] NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
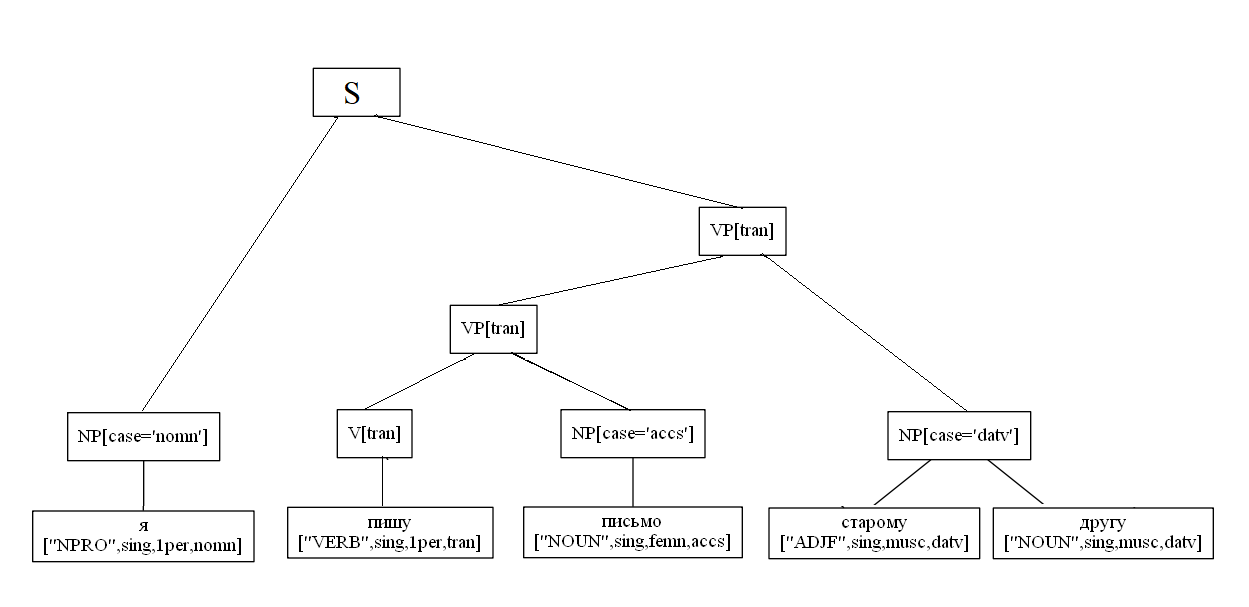
مثال محدد لتحليل جملة من جزأين:
import analyzer parser = analyzer.Parser() sent = " , ." t = parser.parse(sent) t[0].display() S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres'] NP[case='datv'] ['NOUN', 'sing', 'datv'] S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] PP PREP ['PREP'] NP[case='ablt'] ['NOUN', 'sing', 'femn', 'ablt'] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres']
المشاكل
اللغة الطبيعية غامضة ، يعتمد فهمها على عدد من العوامل - على ميزات البنية النحوية للغة ، والثقافة الوطنية ، والمتحدث ، إلخ. نحن قائمة المشاكل الرئيسية لمعالجة لغة الآلة.
- الكشف عن الجناس. الشخص الحي يفهم الجناس بناءً على الحس السليم والسياق ، لكن من الواضح أنه ليس من السهل بالنسبة للكمبيوتر دائمًا.
- Homonymy هي مصادفة في الصوت والإملاء للوحدات اللغوية التي لا ترتبط معانيها ببعضها البعض. حل واحد هو الأساليب الاحتمالية. في الجملة " أعرف ذلك جيدًا " ، فإن احتمال أن يكون " هذا " ضميرًا وليس جسيمًا سيكون أكبر. هذه الأساليب تتطلب العلبة كبيرة بما فيه الكفاية.
- يؤدي الترتيب الحر للكلمات إلى أن تفسير الجملة قد يكون غامضًا. على سبيل المثال ، " الوجود يحدد الوعي " - ما الذي يحدد ماذا؟ في اللغة الروسية ، يتم تعويض ترتيب الكلمات المجانية عن طريق المورفولوجيا المطورة ، وكلمات الخدمة وعلامات الترقيم ، ولكن في معظم الحالات بالنسبة لهذا الكمبيوتر ، يمثل هذا مشكلة إضافية.
- ليس كل الناس يكتبون بشكل صحيح. على الشبكة ، يميل الناس إلى استخدام الاختصارات ، والكلمات الجديدة ، والقطع ، وأشياء أخرى قد تتعارض مع القواعد الأدبية. لهذا السبب ، فإن استخدام قواعد اللغة والقواميس الخالية من السياق ليست ممكنة دائمًا.
استنتاج
المشروع
متاح للاستخدام والتحرير. أنه يحتوي على محلل نفسه ، شجرة التحليل ، وكذلك قواعد اللغة الروسية وقواعد اللغة الروسية وقاموس صغير من النقابات المركبة ويتوقع أن ليست في قاموس OpenCorpora. في الوقت الحالي ، يمكن أن يجد المحلل اللغوي في جمل طويلة معقدة 3 أشجار أو أكثر ، لحل هذه المشكلة ، يتم إجراء تغييرات على قواعد اللغة ، ومن المقرر أيضًا استخدام طرق احتمالية.