بشكل عام ، فإن التعرف على الوجوه وتحديد هويتهم وفقًا لنتائجهم يبدو وكأنه جنس مراهق لكبار السن - الجميع يتحدثون عنه كثيرًا ، لكن القليل من الممارسة. من الواضح أننا لم نندهش بعد أنه بعد تنزيل الصور من التجمعات الودية ، يقترح Facebook / VK وضع علامات على الأشخاص الموجودين في الصورة ، لكننا نعلم هنا بشكل حدسي أن الشبكات الاجتماعية لديها مساعدة جيدة في شكل رسم بياني لشخص ما. وإذا لم يكن هناك مثل هذا الرسم البياني؟ ومع ذلك ، لنبدأ بالترتيب.

في البداية ، نشأ التعرف على الوجوه وتحديد هوية "الصديق / العدو" معنا من الاحتياجات المحلية الحصرية - دخل مدمنو المخدرات في مدخل زميل لهم ، ويقومون باستمرار بمراقبة الصورة من كاميرا الفيديو المثبتة ، وحتى تفكيك مكان الجيران وحيث لا يرغب أي شخص غريب لا.
لذلك ، في غضون أسبوع واحد فقط ، تم تجميع نموذج أولي على الركبة ، يتكون من كاميرا IP وجهاز أحادي اللوحة ومستشعر للحركة ومكتبة التعرف على الوجوه Python. نظرًا لأن مكتبة الثعبان كانت على لوحة واحدة ، وأجهزة قوية إلى حد ما ... دعنا نقولها بعناية ، وليس بسرعة كبيرة ، قررنا بناء عملية المعالجة على النحو التالي:
- يحدد مستشعر الحركة ما إذا كانت هناك حركة في مساحة الفضاء الموكلة إليه ويشير إلى وجودها ؛
- تقوم خدمة مكتوبة تعتمد على gstreamer ، والتي تتلقى باستمرار دفقًا من كاميرا IP ، بقطع 5 ثوانٍ قبل 10 ثوانٍ من الكشف وتغذيتها إلى مكتبة التعرّف لتحليلها ؛
- إنها ، بدورها ، تشاهد الفيديو ، وتجد الوجوه هناك ، وتقارنها بالعينات المعروفة ، وإذا تم العثور عليها غير معروفة ، فإنها ترسل الفيديو إلى قناة Telegram ، في وقت لاحق كان من المفترض أن يتم التحكم فيه في نفس المكان ليقطع على الفور إيجابيات كاذبة - على سبيل المثال ، عندما يقوم أحد الجيران تحولت إلى الكاميرا على الجانب الخطأ في العينات.
تم إرفاق العملية برمتها من قبل حبيبنا إرلانج ، وأثناء اختباره على زملائه أثبت قدرته الدنيا على العمل.
ومع ذلك ، فإن النموذج المُجمَّع لم يجد تطبيقًا في الحياة الواقعية - ليس بسبب النقص الفني الذي كان بلا شك - كما تظهر التجربة - تم جمعها على الركبة في ظروف مكتب الدفيئة لديه ميل سيء للغاية للكسر في هذا المجال ، وفي وقت العرض التوضيحي للعميل ، وبسبب تلك التنظيمية ، رفض سكان الدرج من قبل الأغلبية أي مراقبة بالفيديو.
استمر المشروع على الرف ودس بعصا للمظاهرات أثناء المبيعات والرغبة في تجسيد الأسرة الشخصية.
لقد تغير كل شيء منذ اللحظة التي كان لدينا فيها مشروع أكثر تحديدا وتجاريا حول نفس الموضوع. نظرًا لأنه لن يكون من الممكن قطع الزوايا فيه باستخدام مستشعر للحركة مباشرةً من بيان المشكلة ، كان علي أن أعمق في الفروق الدقيقة للبحث عن الوجوه والتعرف عليها في ثلاثة رؤوس (حسنًا ، اثنان ونصف ، إذا عدتني) مباشرة على الدفق. ثم حدث الوحي.
المشكلة هي أن معظم النتائج التي توصلت إليها حول هذه المسألة هي عبارة عن رسومات أكاديمية بحتة حول موضوع "اضطررت إلى كتابة مقال في مجلة حول موضوع عصري والحصول على علامة للنشر." لا ينتقص من مزايا العلماء - من بين الأوراق التي وجدتها كان هناك الكثير من المفيد والمثير للاهتمام ، ولكن ، للأسف ، يجب أن أعترف أن استنساخ عمل الكود الخاص بهم المنشور على جيثب يترك الكثير مما هو مرغوب فيه أو يبدو وكأنه مهمة مشكوك فيها مع مضيعة للوقت في النهاية.
غالبًا ما كان من الصعب رفع الأطر العديدة للشبكات العصبية والتعلم الآلي - كانت التعرف على الوجوه مهمة ضيقة منفصلة بالنسبة لها ، حيث كانت غير مهتمة بمجموعة واسعة من المشكلات التي تم حلها. بمعنى آخر ، لنأخذ مثالًا جاهزًا وتشغيله على الجهاز الهدف لمجرد التحقق من كيفية عمله وما إذا كان يعمل أم لا. لم يكن ذلك مثالًا ، ثم اقترحت الحاجة إلى الحصول عليه السعي الحامض من تجميع مكتبات معينة لإصدارات معينة لنظام التشغيل المحدد بدقة. أي لاتخاذ والطيران على هذه الخطوة - حرفيا الفتات مثل face_recognition المذكورة سابقا ، والتي استخدمناها في الحرف السابقة.
الشركات الكبرى ، كما هو الحال دائما ، أنقذنا. لطالما شعرت كل من Intel و Nvidia بالزخم المتنامي والجاذبية التجارية لهذه الفئة من المهام ، ولكن كموردين للمعدات في المقام الأول ، يوزعون أطر عملهم لحل مشكلات التطبيقات المحددة مجانًا.
كان مشروعنا على الأرجح أكثر من بحث ، ولكن كان ذا طبيعة تجريبية ، لذلك لم نحلل ونقارن حلول البائعين الفرديين ، لكن ببساطة أخذنا أولًا بهدف جمع نموذج أولي جاهز واختباره في المعركة ، مع تلقي أسرع استجابة ممكنة. لذلك ، وقع الاختيار بسرعة كبيرة على
Intel OpenVINO - مكتبة للتطبيق العملي للتعلم الآلي في المهام التطبيقية.
بادئ ذي بدء ، قمنا بتجميع موقف ، وهو تقليديًا مجموعة من فرقة Nettop مع معالج Intel Core i3 وكاميرات IP من البائعين الصينيين في السوق. تم توصيل الكاميرا مباشرة بـ nettop وزودتها بدفق RTSP مع FPS ليس كبيرًا جدًا ، استنادًا إلى الافتراض بأن الناس ما زالوا لن يعملوا أمامه كما هو الحال في المسابقات. تقلبت سرعة معالجة إطار واحد (البحث عن الوجوه والتعرف عليها) في المنطقة من عشرات إلى مئات الميلي ثانية ، وهو ما يكفي لتضمين آلية البحث للأشخاص الذين يستخدمون العينات الموجودة. بالإضافة إلى ذلك ، كان لدينا أيضًا خطة احتياطية - لدى Intel معالجًا خاصًا لتسريع العمليات الحسابية للشبكات العصبية
Neural Compute Stick 2 ، والتي يمكننا استخدامها إذا لم يكن لدينا معالج للأغراض العامة. ولكن - حتى الآن لم يحدث شيء.
بعد الانتهاء من التجميع والتحقق من وظائف الأمثلة الأساسية - كانت الميزة المميزة لـ Intel SDK في دليل مثال مفصل خطوة بخطوة - بدأنا في إنشاء البرنامج.
كانت المهمة الرئيسية التي تواجهنا هي البحث عن شخص في مجال رؤية الكاميرا وتحديد هويتها وإشعارها بوجودها في الوقت المناسب. وفقًا لذلك ، بالإضافة إلى التعرف على الوجوه ومقارنتها بالأنماط (كيفية القيام بذلك ، في ذلك الوقت ، طرحت أسئلة لا تقل عن أي شيء آخر) ، نحتاج إلى توفير أشياء ثانوية لخطة الواجهة. وهي ، يجب أن نتلقى إطارات مع وجوه الأشخاص الضروريين من نفس الكاميرا لتحديد هويتهم لاحقًا. لماذا ، من الكاميرا نفسها ، أعتقد أنها واضحة تمامًا - نقطة تثبيت الكاميرا على الكائن وبصريات العدسات تقدم تشوهات معينة ، والتي من المفترض أنها يمكن أن تؤثر على جودة الاعتراف ، نستخدم مصدرًا مختلفًا لبيانات المصدر بدلاً من أداة التتبع.
أي بالإضافة إلى معالج الدفق نفسه ، نحتاج على الأقل إلى أرشيف فيديو ومحلل ملفات فيديو من شأنه عزل جميع الوجوه المكتشفة عن التسجيل وحفظ الوجوه الأكثر ملائمة كوجهات مرجعية.
كما هو الحال دائمًا ، اتخذنا Erlang و PostgreSQL المألوفين كغراء بين ffmpeg والتطبيقات على OpenVINO و Telegram Bot API للتنبيهات. بالإضافة إلى ذلك ، كنا بحاجة إلى واجهة مستخدم على الويب لتوفير الحد الأدنى من مجموعة الإجراءات لإدارة المجمع ، والتي حمّلها زميلنا في الواجهة إلى VueJS.
كان منطق العمل على النحو التالي:
- تحت السيطرة على طائرة التحكم (في Erlang) ، يكتب ffmpeg دفقًا من الكاميرا إلى الفيديو في شرائح مدتها خمس دقائق ، وتضمن عملية منفصلة تخزين السجلات في وحدة تخزين محددة بدقة وتنظيف الأقدم عند الوصول إلى هذا الحد ؛
- من خلال واجهة المستخدم على الويب ، يمكنك مشاهدة أي سجل ، وهي مرتبة ترتيبًا زمنيًا ، والتي ، على الرغم من أن ذلك ليس بدون صعوبة ، يسمح لك بعزل الجزء المطلوب وإرساله للمعالجة ؛
- تتكون المعالجة من تحليل الفيديو واستخراج الإطارات ذات الوجوه المكتشفة ، إنها تقوم فقط بالبرمجيات المستندة إلى OpenVINO (يجب أن أقول ، لقد تمكنا هنا من قطع الزاوية قليلاً - برنامج تحليل الدفق وتحليل الملفات متطابق تقريبًا ، وهذا هو السبب في أن معظمه انتقل إلى مكتبة مشتركة ، والأدوات المساعدة نفسها تختلف فقط في سلسلة المعالجة و gstreamer la وحدات). تتم المعالجة على الفيديو ، حيث يتم عزل الوجوه التي تم العثور عليها باستخدام شبكة عصبية مدربة بشكل خاص. تقع الأجزاء الناتجة من الإطار الذي يحتوي على الوجوه في شبكة عصبية أخرى ، والتي تشكل متجهًا مكونًا من 256 عنصرًا ، وهو في الواقع إحداثيات النقاط المرجعية لوجه الشخص. يتم تخزين هذا المتجه والإطار المكتشف وإحداثيات مستطيل الوجه الموجود في قاعدة البيانات ؛
- علاوة على ذلك ، بعد اكتمال المعالجة ، يفتح المشغل مجموعة متنوعة من الإطارات المرسومة ، ويخشى من عددهم ويواصل البحث عن الأشخاص المستهدفين. يمكن إضافة عينات محددة إلى شخص موجود أو إنشاء واحدة جديدة. بعد اكتمال معالجة المهمة ، يتم حذف نتائج التحليل ، باستثناء المتجهات المخزنة التي تم تعيينها لسجلات الملاحظات ؛
- وفقًا لذلك ، يمكننا أن ننظر إلى كل من الإطارات ونواقل الكشف في أي وقت ونقوم بتحريرها ، ونحذف العينات غير الناجحة ؛
- بالتوازي مع دورة الكشف في الخلفية ، تعمل خدمة تحليل الدفق دائمًا ، والتي تعمل نفس الشيء ، ولكن مع الدفق من الكاميرا. يقوم بتحديد الوجوه في التدفق المرصود ومقارنتها بعينات من قاعدة البيانات ، والتي تستند إلى افتراض بسيط بأن متجهات شخص واحد ستكون أقرب إلى بعضها البعض من جميع النواقل الأخرى. يحدث حساب زوجي للمسافة بين المتجهات ، عندما يتم الوصول إلى العتبة ، يتم وضع سجل للكشف والإطار في قاعدة البيانات. بالإضافة إلى ذلك ، تتم إضافة شخص إلى قائمة التوقف في المستقبل القريب ، مما يتجنب إخطارات متعددة عن الشخص نفسه ؛
- تقوم طائرة التحكم بالتحقق من سجل الكشف بشكل دوري ، وفي حالة وجود إدخالات جديدة ، يتم إخطارها برسالة تحتوي على الصورة المرفقة وإبراز الوجه من خلال الروبوت لأولئك المسموح لهم وفقًا للإعدادات.
يبدو شيء مثل هذا:
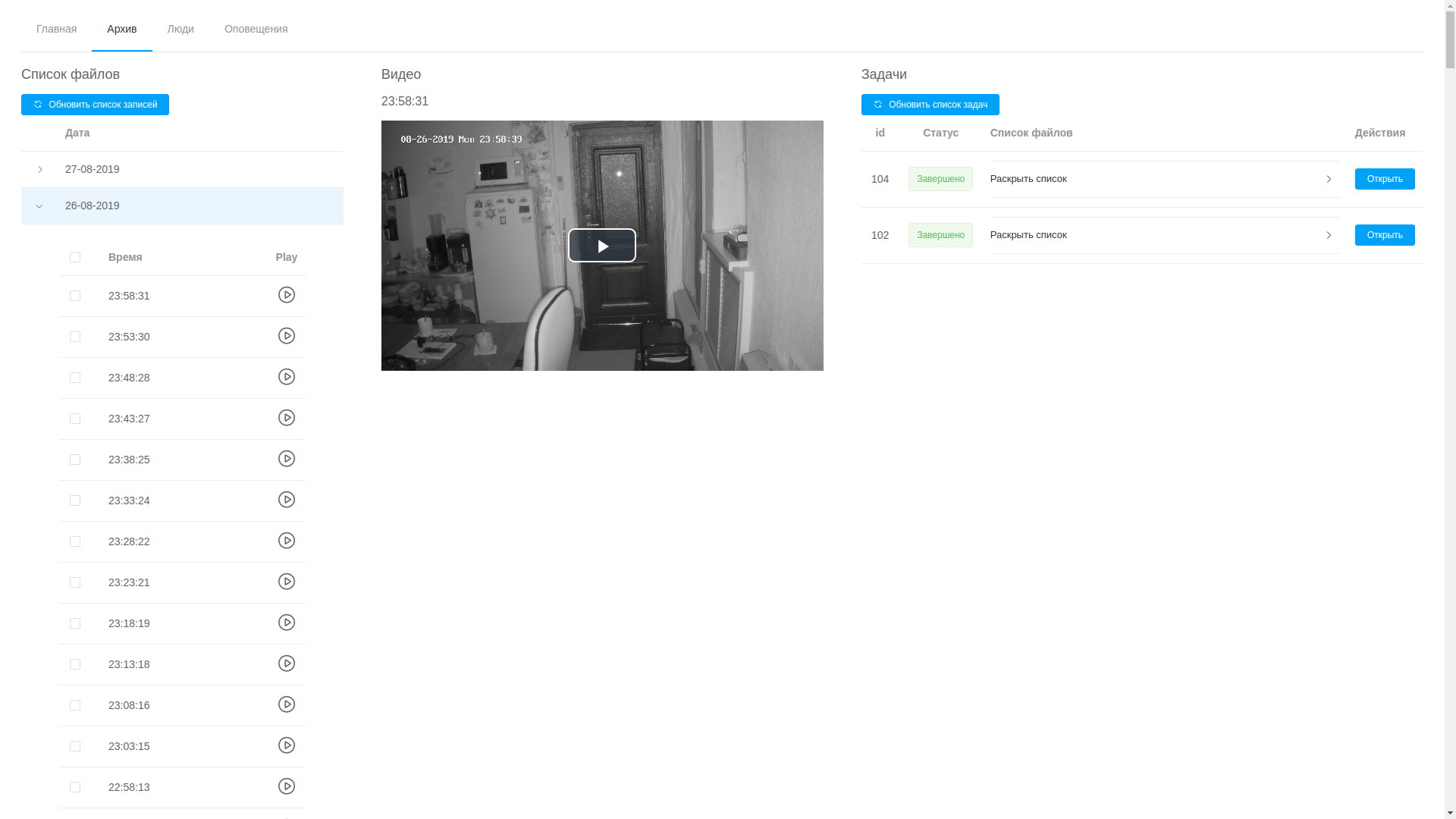 عرض الأرشيف
عرض الأرشيف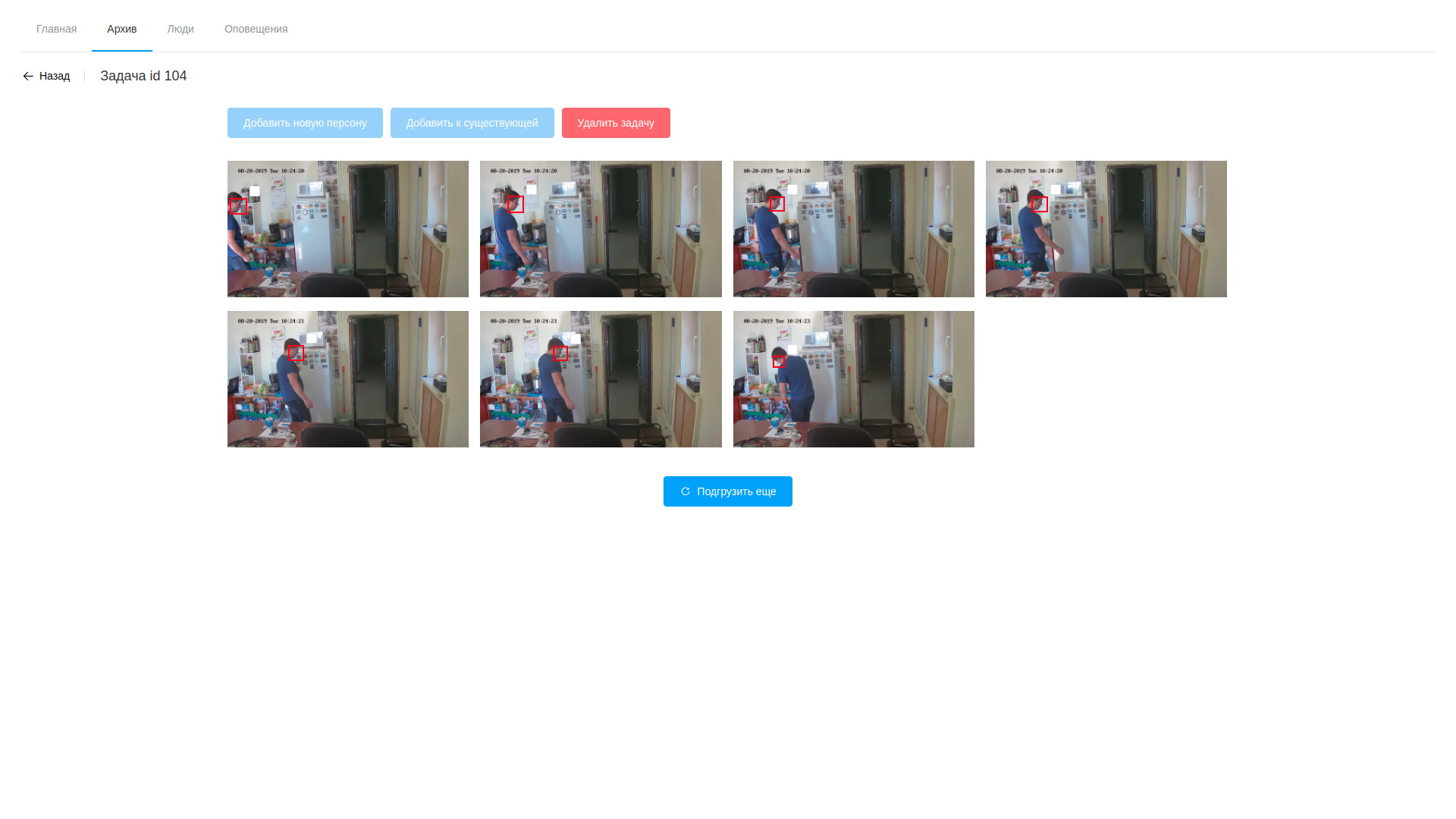 نتائج تحليل الفيديو
نتائج تحليل الفيديو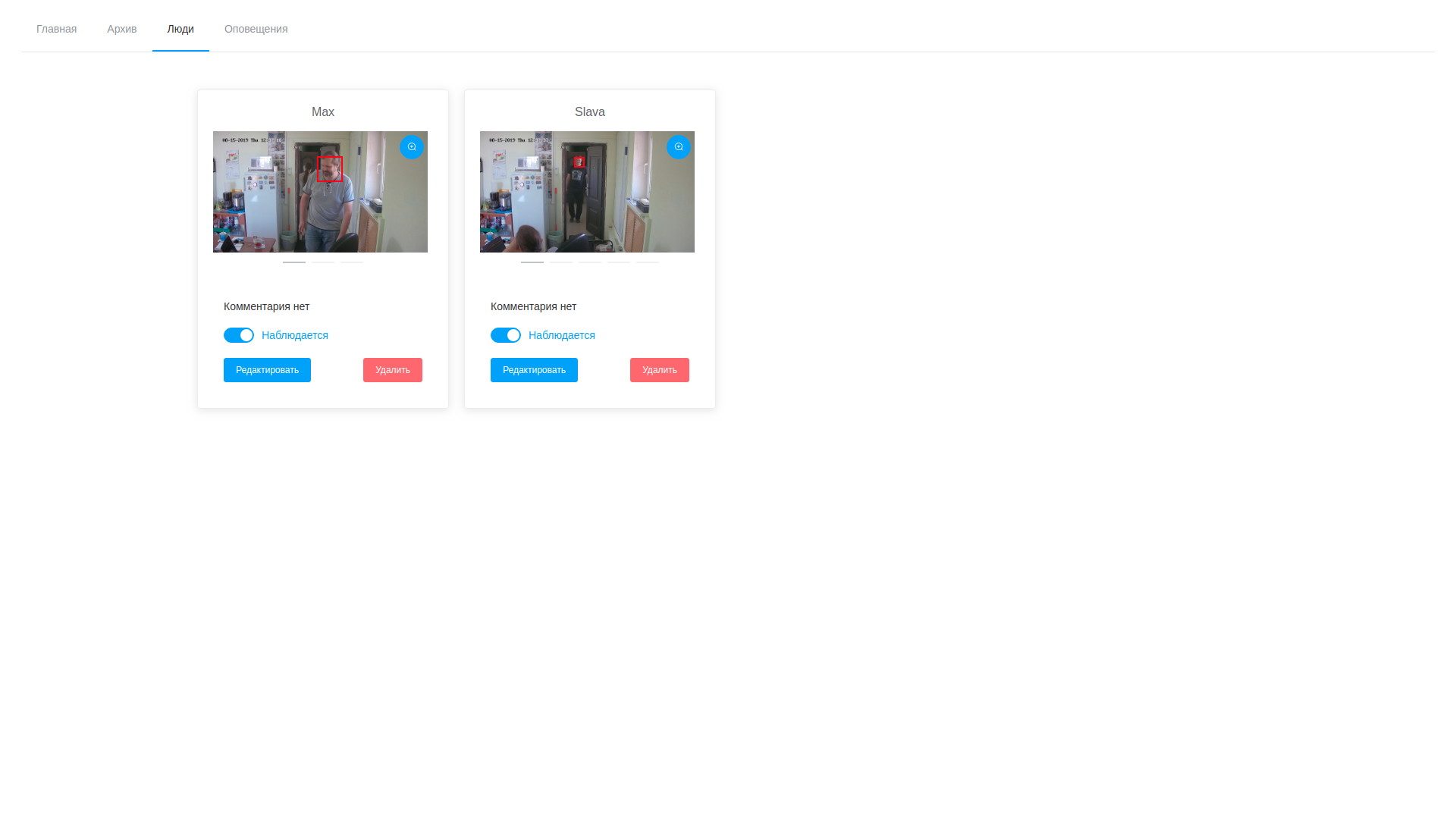 قائمة الشخصيات المرصودة
قائمة الشخصيات المرصودةيكون الحل الناتج في كثير من النواحي مثيرًا للجدل وأحيانًا لا يكون مثالياً سواء من حيث الإنتاجية أو من حيث تقليل وقت رد الفعل. لكن ، أكرر ، لم يكن لدينا هدف للحصول على نظام فعال على الفور ، ولكن ببساطة السير في هذا الطريق وملء أكبر عدد ممكن من المخاريط ، وتحديد المسارات الضيقة والمشاكل المحتملة غير الواضحة.
تم اختبار النظام المجمع في ظروف مكتب الدفيئة لمدة أسبوع. خلال هذا الوقت ، تم ملاحظة الملاحظات التالية:
- هناك اعتماد واضح لجودة التعرف على جودة العينات الأصلية. إذا مر الشخص المرصود عبر منطقة المراقبة بسرعة كبيرة ، فلن يترك البيانات بدرجة كبيرة لاحتمال أخذ العينات ولن يتم التعرف عليها. ومع ذلك ، أعتقد أن هذه مسألة تحسين النظام ، بما في ذلك معلمات الإضاءة ودفق الفيديو ؛
- نظرًا لأن النظام يعمل بالتعرف على عناصر الوجوه (العيون والأنف والفم والحواجب وما إلى ذلك) ، فمن السهل الخداع بوضع عقبة بصرية بين الوجه والكاميرا (الشعر والنظارات الداكنة وارتداء غطاء محرك السيارة ، إلخ) - الوجه ، على الأرجح ، سيتم العثور عليها ، لكن المقارنة مع العينات لن تعمل بسبب التناقض الشديد بين متجهات الكشف والعينات ؛
- لا تؤثر النظارات العادية كثيرًا - كان لدينا أمثلة على الاستجابات الإيجابية لدى الأشخاص الذين يعانون من النظارات وإجابات سلبية خاطئة لدى الأشخاص الذين وضعوا النظارات للاختبار ؛
- إذا كانت اللحية على العينات الأصلية ، ثم اختفت ، فسيتم تقليل عدد العمليات (قام مؤلف هذه الخطوط بقص لحيته إلى 2 مم وتقلص عدد العمليات إلى النصف) ؛
- حدثت أيضًا إيجابيات كاذبة ، وهي مناسبة لمزيد من الانغماس في رياضيات المسألة ، وربما حل لمشكلة المراسلات الجزئية للمتجهات والأسلوب الأمثل لحساب المسافة بينهما. ومع ذلك ، يجب أن يكشف الاختبار الميداني عن المزيد من المشكلات في هذا الصدد.
ما هو قادم؟ فحص النظام في المعركة ، وتحسين دورة معالجة الكشف ، وتبسيط إجراءات البحث عن الأحداث في أرشيف الفيديو ، وإضافة المزيد من البيانات إلى التحليل (العمر ، والجنس ، والعواطف) وغيرها من المهام الصغرى التي لا تزال بحاجة إلى 100،500. لكن الخطوة الأولى في طريق ألف خطوة اتخذناها بالفعل. إذا شارك أي شخص تجربته في حل هذه المشكلات أو قدم روابط مهمة حول هذه المسألة - سأكون ممتنًا للغاية.