
في هذه المقالة ، أود أن أقترح بديلاً عن أسلوب تصميم الاختبار التقليدي باستخدام مفاهيم البرمجة الوظيفية في Scala. استلهم هذا النهج من عدة أشهر من الألم من الحفاظ على عشرات الاختبارات الفاشلة والرغبة الشديدة لجعلها أكثر وضوحا وأكثر قابلية للفهم.
على الرغم من أن الكود موجود في Scala ، إلا أن الأفكار المقترحة مناسبة للمطورين ومهندسي ضمان الجودة الذين يستخدمون لغات تدعم البرمجة الوظيفية. يمكنك العثور على رابط Github مع الحل الكامل ومثال في نهاية المقالة.
المشكلة
إذا كان عليك التعامل مع الاختبارات في أي وقت (لا يهم الاختبارات: اختبارات الوحدات ، التكاملية أو الوظيفية) ، فمن المحتمل أن تكون مكتوبة كمجموعة من التعليمات المتسلسلة. على سبيل المثال:
في تجربتي ، يفضل معظم المطورين هذه الطريقة في كتابة الاختبارات. يشتمل مشروعنا على حوالي ألف اختبار على مستويات مختلفة من العزلة ، وقد تمت كتابتها جميعًا بهذه الطريقة حتى وقت قريب. مع نمو المشروع ، بدأنا نلاحظ وجود مشاكل حادة وتباطؤ في الحفاظ على مثل هذه الاختبارات: إصلاحها سيستغرق ما لا يقل عن نفس الوقت الذي تستغرقه كتابة رمز الإنتاج.
عند كتابة اختبارات جديدة ، كان علينا دائمًا التوصل إلى طرق لإعداد البيانات من البداية ، وذلك عادةً عن طريق نسخ ولصق الخطوات من الاختبارات المجاورة. نتيجة لذلك ، عندما يتغير نموذج بيانات التطبيق ، فإن منزل البطاقات سينهار ، وسيتعين علينا إصلاح كل اختبار فاشل: في سيناريو أسوأ الحالات - من خلال الغوص بعمق في كل اختبار وإعادة كتابته.
عندما يفشل الاختبار "بأمانة" - أي بسبب خلل فعلي في منطق العمل - كان فهم الخطأ الذي حدث دون تصحيح الأخطاء مستحيلاً. نظرًا لأن الاختبارات كانت صعبة للغاية ، لم يكن لدى أي شخص المعرفة الكاملة دائمًا بكيفية تصرف النظام.
كل هذا الألم ، في رأيي ، هو أحد أعراض أعمق مشكلتين في تصميم الاختبار:
- لا يوجد هيكل واضح وعملي للاختبارات. كل اختبار هو ندفة الثلج فريدة من نوعها. عدم وجود هيكل يؤدي إلى الفعل ، الذي يستهلك الكثير من الوقت ويثبط من فعالية. التفاصيل غير المهمة تصرف الانتباه عن الأهم - الشرط الذي يؤكده الاختبار. النسخ واللصق تصبح النهج الأساسي لكتابة حالات اختبار جديدة.
- الاختبارات لا تساعد المطورين في توطين العيوب. أنها تشير فقط إلى وجود مشكلة من نوع ما. لفهم الحالة التي يتم فيها تشغيل الاختبار ، يجب عليك رسمه في رأسك أو استخدام مصحح أخطاء.
تصميم
هل يمكننا أن نفعل ما هو أفضل؟ (تنبيه المفسد: يمكننا.) دعنا نفكر في نوع الهيكل الذي قد يكون لهذا الاختبار.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
كقاعدة عامة ، تتوقع التعليمة البرمجية قيد الاختبار بعض المعلمات الصريحة (معرفات ، أحجام ، كميات ، عوامل تصفية ، على سبيل المثال لا الحصر) ، وكذلك بعض البيانات الخارجية (من قاعدة بيانات أو قائمة انتظار أو خدمة أخرى في العالم الحقيقي). لكي يعمل اختبارنا بشكل موثوق ، يحتاج إلى تثبيت - حالة لوضع النظام أو مزودي البيانات أو كليهما.
باستخدام هذه المباراة ، نقوم بإعداد تبعية لتهيئة الكود تحت الاختبار - ملء قاعدة بيانات ، وإنشاء قائمة انتظار من نوع معين ، إلخ.
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
بعد تشغيل الشفرة قيد الاختبار على بعض معلمات الإدخال ، نتلقى مخرجات - كلاهما صريح (يتم إرجاعهما بواسطة الكود قيد الاختبار) والضمني (التغييرات في الحالة).
result shouldBe 90
أخيرًا ، نتحقق من أن الإخراج كما هو متوقع ، مع الانتهاء من الاختبار بتأكيد واحد أو أكثر.
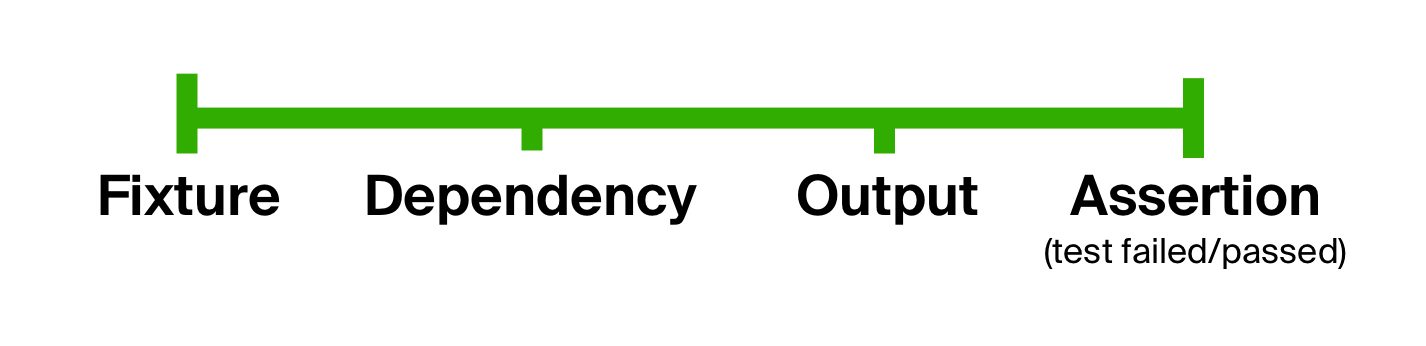
يمكن للمرء أن يستنتج أن الاختبارات تتكون عمومًا من نفس المراحل: إعداد الإدخال ، تنفيذ التعليمات البرمجية ، وتأكيد النتائج. يمكننا استخدام هذه الحقيقة للتخلص من المشكلة الأولى في اختباراتنا ، أي الشكل الليبرالي المفرط ، من خلال تقسيم جسم الاختبار بشكل صريح إلى مراحل. هذه الفكرة ليست جديدة ، حيث يمكن رؤيتها في اختبارات نمط التنمية BDD ( التطوير القائم على السلوك ).
ماذا عن التمدد؟ قد تحتوي أي خطوة من عملية الاختبار ، بدورها ، على أي مقدار من الخطوات الوسيطة. على سبيل المثال ، يمكننا اتخاذ خطوة كبيرة ومعقدة ، مثل بناء تجهيزات ، وتقسيمها إلى عدة ، بالسلاسل واحدة تلو الأخرى. وبهذه الطريقة ، يمكن أن تكون عملية الاختبار قابلة للتمديد إلى ما لا نهاية ، ولكن في النهاية تتكون دائمًا من نفس الخطوات العامة القليلة.

تشغيل الاختبارات
دعونا نحاول تنفيذ فكرة تقسيم الاختبار إلى مراحل ، ولكن أولاً ، يجب أن نحدد نوع النتيجة التي نود أن نراها.
بشكل عام ، نود كتابة الاختبارات والحفاظ عليها لتصبح أقل كثافة في العمل وأكثر متعة. كلما قل عدد الإرشادات غير الفريدة الصريحة في الاختبار ، سيتعين إجراء تغييرات أقل عليه بعد تغيير العقود أو إعادة التجهيز ، وتقليل الوقت اللازم لقراءة الاختبار. يجب أن يشجع تصميم الاختبار على إعادة استخدام مقتطفات الكود الشائعة ويثبط النسخ واللصق اللاذعان. سيكون من الجميل أيضًا أن يكون للاختبارات شكل موحد. القدرة على التنبؤ تعمل على تحسين قابلية القراءة وتوفير الوقت. على سبيل المثال ، تخيل مقدار الوقت الذي سيستغرقه العلماء الطموحين لتعلم كل الصيغ إذا كانت الكتب المدرسية ستجعلهم يكتبون بحرية بلغة مشتركة بدلاً من الرياضيات.
وبالتالي ، فإن هدفنا هو إخفاء أي شيء يشتت انتباهك ولا لزوم له ، مع ترك ما هو مهم للغاية لفهم: ما الذي يتم اختباره ، وما هي المدخلات والمخرجات المتوقعة.
دعنا نعود إلى نموذجنا لبنية الاختبار.
من الناحية الفنية ، يمكن تمثيل كل خطوة منه بنوع بيانات ، وكل عملية انتقال - بواسطة دالة. يمكن الانتقال من نوع البيانات الأولي إلى النوع الأخير من خلال تطبيق كل وظيفة على نتيجة النوع السابق. بمعنى آخر ، باستخدام تكوين وظيفة إعداد البيانات (دعنا نسميها prepare ) ، تنفيذ التعليمات البرمجية ( execute ) والتحقق من النتيجة المتوقعة ( check ). ستكون مدخلات هذا التكوين هي الخطوة الأولى - المباراة. دعنا ندعو وظيفة الترتيب الأعلى الناتجة إلى وظيفة دورة حياة الاختبار .
اختبار وظيفة دورة الحياة def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
يطرح سؤال ، من أين تأتي هذه الوظائف المعينة؟ حسنًا ، فيما يتعلق بإعداد البيانات ، لا يوجد سوى عدد محدود من الطرق للقيام بذلك - ملء قاعدة بيانات ، وسخرية ، وما إلى ذلك. وبالتالي ، من السهل كتابة متغيرات متخصصة من وظيفة prepare المشتركة عبر جميع الاختبارات. نتيجة لذلك ، سيكون من الأسهل إجراء وظائف دورة حياة اختبار متخصصة لكل حالة ، والتي من شأنها إخفاء تطبيقات ملموسة لإعداد البيانات. نظرًا لأن تنفيذ التعليمات البرمجية والتأكيدات فريدة إلى حد ما بالنسبة لكل اختبار (أو مجموعة من الاختبارات) ، يجب كتابة execute check منه في كل مرة بشكل صريح.
اختبار وظيفة دورة الحياة تكييفها لاختبار intergration على قاعدة بيانات من خلال تفويض جميع الفروق الدقيقة في وظيفة دورة حياة الاختبار ، نحصل على القدرة على تمديد عملية الاختبار دون لمس أي اختبار معين. باستخدام تكوين الوظيفة ، يمكننا التدخل في أي خطوة من العملية واستخراج أو إضافة بيانات.
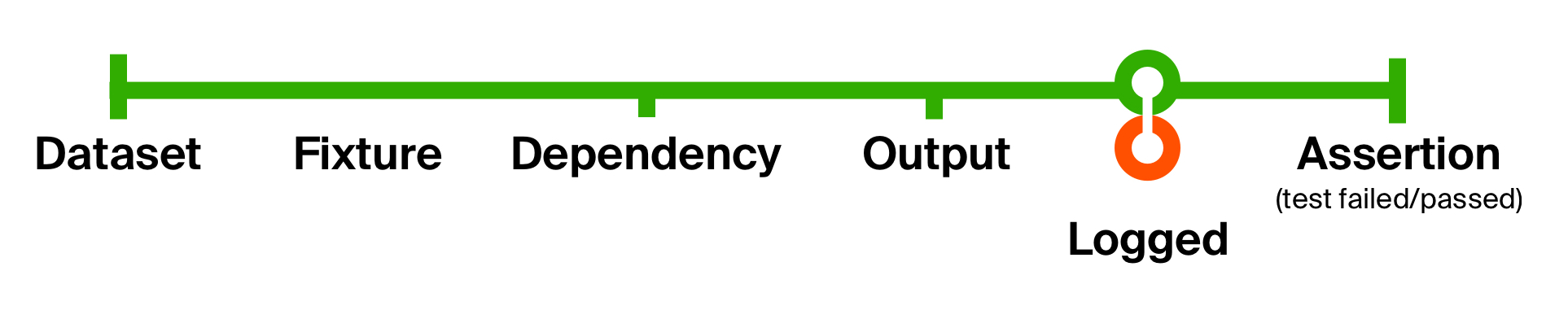
لتوضيح إمكانات مثل هذا النهج بشكل أفضل ، دعنا نحل المشكلة الثانية المتمثلة في اختبارنا الأولي - عدم وجود معلومات تكميلية لحل المشكلات المحددة. دعنا نضيف تسجيل أيا كان تنفيذ التعليمات البرمجية عاد. لن يغير تسجيلنا نوع البيانات ؛ لا ينتج عنه سوى تأثير جانبي - إخراج رسالة إلى وحدة التحكم. بعد الآثار الجانبية ، نعيدها كما هي.
اختبار وظيفة دورة الحياة مع تسجيل def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
مع هذا التغيير البسيط ، أضفنا تسجيل إخراج الشفرة المنفذة في كل اختبار . تتمثل ميزة هذه الوظائف الصغيرة في سهولة فهمها وتأليفها والتخلص منها عند الحاجة.

نتيجة لذلك ، يبدو اختبارنا الآن كالتالي:
val fixture: SomeMagicalFixture = ???
أصبح هيكل الاختبار موجزا ، ويمكن إعادة استخدام المباراة والشيكات في اختبارات أخرى ، ونحن لا نعد قاعدة البيانات يدويا في أي مكان بعد الآن. لا تزال هناك مشكلة واحدة صغيرة ...
إعداد المباراة
في الكود أعلاه ، كنا نعمل وفقًا لافتراض أنه سيتم تقديم المباراة لنا من مكان ما. نظرًا لأن البيانات هي المكون الأساسي للاختبارات القابلة للصيانة والمباشرة ، يتعين علينا أن نتطرق إلى كيفية جعلها سهلة.
لنفترض أن متجرنا قيد الاختبار يحتوي على قاعدة بيانات علائقية نموذجية متوسطة الحجم (من أجل البساطة ، في هذا المثال ، يحتوي على 4 طاولات فقط ، ولكن في الواقع ، يمكن أن يحتوي على المئات). تحتوي بعض الجداول على بيانات مرجعية ، وبعضها - بيانات تجارية ، ويمكن تجميع كل ذلك بشكل منطقي في كيان واحد أو أكثر. ترتبط العلاقات مع مفاتيح خارجية لإنشاء Bonus ، Package مطلوبة ، والتي بدورها تحتاج إلى User ، وهلم جرا.

تؤدي الحلول البديلة والاختراقات فقط إلى عدم تناسق البيانات ، ونتيجة لذلك ، إلى ساعات على ساعات من تصحيح الأخطاء. لهذا السبب ، نحن لا نجري تغييرات على المخطط بأي شكل من الأشكال.
يمكننا استخدام بعض طرق الإنتاج لملئها ، ولكن حتى تحت الفحص الضحل ، فإن هذا يثير الكثير من الأسئلة الصعبة. ما الذي سيعد البيانات في الاختبارات لرمز الإنتاج؟ هل سيتعين علينا إعادة كتابة الاختبارات في حالة تغيير عقد هذا الرمز؟ ماذا لو جاءت البيانات من مكان آخر تمامًا ، ولا توجد طرق لاستخدامها؟ كم عدد الطلبات التي يتطلبها إنشاء كيان يعتمد على العديد من الطلبات الأخرى؟
ملء قاعدة البيانات في الاختبار الأولي insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
أساليب المساعدة المتناثرة ، مثل تلك الموجودة في مثالنا الأول ، هي نفس المشكلة تحت ستار مختلف. يضعون مسؤولية إدارة التبعيات على أنفسنا والتي نحاول تجنبها.
من الناحية المثالية ، نود بعض بنية البيانات التي من شأنها تقديم حالة النظام بالكامل في لمحة واحدة. سيكون المرشح الصحيح عبارة عن جدول (أو مجموعة بيانات ، كما هو الحال في PHP أو Python) والتي لن تتضمن شيئًا سوى الحقول المهمة لمنطق العمل. إذا تغيرت ، فسيكون من السهل الحفاظ على الاختبارات: سنقوم فقط بتغيير الحقول الموجودة في مجموعة البيانات. على سبيل المثال:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
من طاولتنا ، نقوم بإنشاء مفاتيح - روابط الكيان حسب المعرف. إذا كان الكيان يعتمد على كيان آخر ، فسيتم أيضًا إنشاء مفتاح لذلك الكيان الآخر. قد يحدث أن ينشئ كيانان مختلفان تبعية بنفس المعرف ، مما قد يؤدي إلى انتهاك المفتاح الأساسي . ومع ذلك ، في هذه المرحلة يكون إلغاء تنشيط المفاتيح المكررة رخيصًا بشكل لا يصدق - نظرًا لأن كل ما تحتويه عبارة عن معرفات ، يمكننا وضعها في مجموعة تقوم بإلغاء البيانات المكررة بالنسبة لنا ، على سبيل المثال ، Set . إذا تبين أن هذا غير كافٍ ، فيمكننا دائمًا تنفيذ إلغاء البيانات المكررة بشكل أكثر ذكاءً كوظيفة منفصلة وننشئها في وظيفة دورة حياة الاختبار.
المفاتيح (مثال) sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
يتم تفويض توليد بيانات وهمية للحقول (مثل الأسماء) إلى فصل منفصل. بعد ذلك ، باستخدام هذه الفئة وقواعد التحويل للمفاتيح ، نحصل على كائنات الصف المخصصة للإدراج في قاعدة البيانات.
الصفوف (مثال) object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
البيانات المزيفة عادة ما تكون غير كافية ، لذلك نحن بحاجة إلى وسيلة لتجاوز حقول محددة. لحسن الحظ ، العدسات هي فقط ما نحتاج إليه - يمكننا استخدامها للتكرار على جميع الصفوف التي تم إنشاؤها وتغيير الحقول التي نحتاجها فقط. نظرًا لأن العدسات وظائف تمويه ، يمكننا إعدادها كالمعتاد ، وهي أقوى نقطة فيها.
ينس (مثال) def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
بفضل التكوين ، يمكننا تطبيق تحسينات وتحسينات مختلفة داخل العملية: على سبيل المثال ، يمكننا تجميع الصفوف حسب الجدول لإدراجها مع INSERT واحد لتقليل وقت تنفيذ الاختبار أو تسجيل حالة قاعدة البيانات بأكملها.
وظيفة إعداد المباراة def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
وأخيرا ، فإن كل شيء يوفر لنا المباراة. في الاختبار نفسه ، لا يتم عرض أي شيء إضافي ، باستثناء مجموعة البيانات الأولية - يتم إخفاء جميع التفاصيل حسب تكوين الوظيفة.

تبدو مجموعة الاختبارات الآن كما يلي:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) "If the buyer's role is" - { "a customer" - { "And the total price of items" - { "< 250 after applying bonuses - no discount" - { "(case: no bonuses)" in calculatePriceFor(dataTable, 1) "(case: has bonuses)" in calculatePriceFor(dataTable, 3) } ">= 250 after applying bonuses" - { "If there are no bonuses - 10% off on the subtotal" in calculatePriceFor(dataTable, 2) "If there are bonuses - 10% off on the subtotal after applying bonuses" in calculatePriceFor(dataTable, 4) } } } "a vip - then they get a 20% off before applying bonuses and then all the other rules apply" in calculatePriceFor(dataTable, 5) }
ورمز المساعد:
تعد إضافة حالات اختبار جديدة إلى الجدول مهمة تافهة تسمح لنا بالتركيز على تغطية المزيد من الحالات الهامشية وليس على كتابة كود boilerplate.
إعادة استخدام لاعبا اساسيا في مشاريع مختلفة
حسنًا ، لذا فقد كتبنا مجموعة كبيرة من التعليمات البرمجية لإعداد تجهيزات في مشروع محدد واحد ، وقضاء بعض الوقت في هذه العملية. ماذا لو كان لدينا العديد من المشاريع؟ هل محكوم علينا إعادة اختراع كل شيء من الصفر في كل مرة؟
يمكننا أن نستخلص إعداد المباراة على نموذج مجال ملموس. في عالم البرمجة الوظيفية ، هناك مفهوم للرسومات . دون التعمق في التفاصيل ، فإنها لا تشبه الفصول في OOP ، ولكنها تشبه الواجهات من حيث أنها تحدد سلوكًا معينًا لمجموعة من الأنواع. الفرق الأساسي هو أنهم ليسوا موروثين ولكن متشابهين مثل المتغيرات. ومع ذلك ، على غرار الميراث ، يحدث حل مثيلات typeclass في وقت الترجمة . في هذا المعنى ، يمكن فهم أدوات الطباعة مثل أساليب التمديد من Kotlin و C # .
لتسجيل كائن ما ، لا نحتاج إلى معرفة ما بداخله ، ما هي الحقول والأساليب الموجودة به. كل ما يهمنا هو وجود log() سلوك log() مع توقيع معين. سيكون تمديد كل فصل Logged بواجهة Logged أمرًا شاقًا للغاية ، وحتى ذلك الحين غير ممكن في كثير من الحالات - على سبيل المثال ، بالنسبة للمكتبات أو الفصول القياسية. مع typeclasses ، وهذا أسهل بكثير. يمكننا إنشاء نسخة من typeclass تسمى Logged ، على سبيل المثال ، لاعبا اساسيا لتسجيله بتنسيق قابل للقراءة من قبل الإنسان. بالنسبة لكل شيء آخر لا يحتوي على مثيل لـ Logged يمكننا توفير نسخة احتياطية: مثيل للنوع Any يستخدم طريقة قياسية toString() لتسجيل كل كائن في تمثيله الداخلي مجانًا.
مثال على typeclass المسجلة ومثيلاتها trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
إلى جانب قطع الأشجار ، يمكننا استخدام هذا النهج طوال عملية صنع التركيبات بأكملها. يقترح حلنا طريقة مجردة لجعل تركيبات قاعدة البيانات ومجموعة من typeclasses للذهاب معها. إنه المشروع الذي يستخدم مسؤولية الحل في تنفيذ مثيلات هذه اللوحات من أجل أن يعمل كل شيء.
عند تصميم أداة تحضير هذه المباراة ، استخدمت مبادئ SOLID كبوصلة للتأكد من إمكانية صيانتها وقابليتها للتمديد:
- مبدأ المسؤولية الفردية : يصف كل نوع من أنواع الحروف سلوك واحد وواحد فقط من نوع ما.
- مبدأ الفتح / الإغلاق : لا نقوم بتعديل أي من فئات الإنتاج ؛ بدلا من ذلك ، نحن تمديدها مع مثيلات من typeclasses.
- لا ينطبق مبدأ تبديل Liskov هنا لأننا لا نستخدم الميراث.
- مبدأ الفصل بين الواجهات : نستخدم العديد من أنواع الحروف المتخصصة بدلاً من واحدة عالمية.
- مبدأ الانعكاس التبعية : لا تعتمد وظيفة إعداد لاعبا اساسيا على أنواع ملموسة ، ولكن على typeclasses مجردة.
بعد التأكد من استيفاء جميع المبادئ ، قد نفترض بأمان أن حلنا قابل للصيانة وقابل للتوسيع بدرجة كافية لاستخدامه في مشاريع مختلفة.
بعد كتابة وظيفة دورة حياة الاختبار والحل لإعداد تركيبات ، والتي هي أيضا مستقلة عن نموذج مجال ملموسة على أي تطبيق معين ، ونحن جميعا على استعداد لتحسين جميع الاختبارات المتبقية.
خلاصة القول
لقد تحولنا من أسلوب تصميم الاختبار التقليدي (خطوة بخطوة) إلى التصميم الوظيفي. يُعد أسلوب خطوة بخطوة مفيدًا في البداية وفي المشروعات الأصغر حجمًا ، لأنه لا يقيد المطورين ولا يتطلب أي معرفة متخصصة. ومع ذلك ، عندما تصبح كمية الاختبارات كبيرة جدًا ، يميل هذا النمط إلى السقوط. من المحتمل ألا تؤدي كتابة الاختبارات في الأسلوب الوظيفي إلى حل جميع مشكلات الاختبار الخاصة بك ، ولكنها قد تحسن بشكل كبير من القياس والإبقاء على الاختبارات في المشروعات ، حيث يوجد المئات أو الآلاف منها. تبين أن الاختبارات المكتوبة بأسلوب وظيفي أكثر إيجازًا وتركز على الأشياء الأساسية (مثل البيانات والرمز قيد الاختبار والنتيجة المتوقعة) ، وليس على الخطوات المتوسطة.
علاوة على ذلك ، لقد اكتشفنا مدى قوة وظيفة التكوين والرسومات في البرمجة الوظيفية. بفضل مساعدتهم ، من السهل جدًا تصميم الحلول مع التمديد وقابلية إعادة الاستخدام في الاعتبار.
منذ تبني الأسلوب منذ عدة أشهر ، كان على فريقنا قضاء بعض الجهد في التكيف ، لكن في النهاية استمتعنا بالنتيجة. تتم كتابة الاختبارات الجديدة بشكل أسرع ، كما أن السجلات تجعل الحياة أكثر راحة ، كما أن مجموعات البيانات في متناول اليد للتحقق من وجود أسئلة حول تعقيدات بعض المنطق. يهدف فريقنا إلى تبديل جميع الاختبارات إلى هذا الأسلوب الجديد بشكل تدريجي.
يمكن العثور على رابط للحل ومثال كامل هنا: Github . وقتا ممتعا مع الاختبار الخاص بك!