"استشاري +" - نظام مرجعي للمحامين والمحاسبين وغيرهم. إنه يعمل بثبات مثل الساعة. في هذا المنشور ، يُقترح أن تضبط هذه الساعة قليلاً على احتياجاتك فيما يتعلق بإخراج النص ، وهي: انظر كيف يمكنك معالجة المعلومات النصية التي يقدمها النظام بيثون. على طول الطريق ، العمل مع عناصر النص المعلنة في العنوان.
الظل على السياج
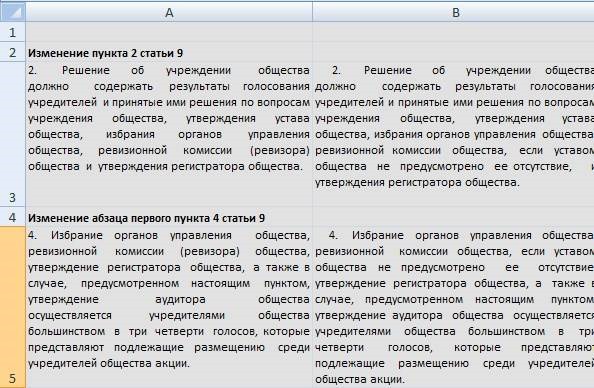
كمحامي ، الذي عمل لفترة طويلة مع برنامج المساعدة "Consultant +" ، كنت دائماً أفتقد وظيفة عادية في هذا النظام. وكانت هذه الوظيفة على النحو التالي. عندما تظهر أي تغييرات في القانون التنظيمي ، ينشر موظفو K + نظرة عامة على التغييرات في شكل عمودين من النص:

العمود الموجود على اليسار هو ما كان عليه من قبل ، والعمود الموجود على اليمين هو المعيار الساري الآن. الآن (منذ بضع سنوات) ، تم تحديث الوظيفة وإبراز التغييرات
بخط غامق ومرئي على الفور. هذا كل شيء مريح للغاية. ولكن هناك أشياء غير مريحة.
أولا ، لا يتم إعطاء بعض المعايير ، لأن حجمها كبير جدًا بالنسبة لموظفي K + وعليك الانتقال إلى روابط النظام ، وثانياً ، لا يمكنك فقط التقاط هذين العمودين ونسخهما عن طريق لصقهما في جدول إكسل أو كلمة عادي.
ربما تم ذلك عن قصد حتى يعمل المستخدمون بنشاط أكبر مع النظام ، بما في ذلك عدم نقل أي شيء من هناك.
حسنا يجب اصلاحها.
المهمة : نشر النص في عمودين ، حيثما كان ذلك ممكنًا وأين لا - قم فقط بإزالة القاعدة ووضع كل هذا في جدول بيانات Excel. في الوقت نفسه ، دعونا نرى كيف يمكنك تغيير الخط والمحاذاة وغيرها من تفاهات في النص باستخدام بيثون.
على سبيل المثال الذي يغذي برنامجنا المستقبلي ، نأخذ من K + التغييرات في قانون الشركات المساهمة العامة. غالبا ما يتم تغيير هذا القانون ، لذلك سيكون هناك عمل للقيام به.
احفظ التغييرات في ملف txt عادي (على سبيل المثال ، إصدار .txt). تحصل على شيء مثل التالي:

لذلك ، من الواضح أن كل تغيير يتم فصله عن الآخر بخط صلب ، والذي اتخذ بعد الحفظ شكل "؟؟؟". هناك أيضًا تغيير عنوان يجب حسابه. كل شيء يبدو بسيطا باستثناء بعض النقاط.
لذلك ، صادف التغييرات التي تحتوي على النموذج التالي:

بالإضافة إلى ذلك ، تتفاقم المسألة من خلال حقيقة أن التغييرات الفردية تختلف اختلافًا كبيرًا في الطول.
ننتقل إلى K +.
قم بإنشاء ملف consult.py جديد وأضف الأسطر الأولى إليه:
from __future__ import unicode_literals import codecs import openpyxl
الوحدة النمطية openpyxl مألوفة بالفعل ، فهي تتيح لك العمل مع Excel ، لكن الآخران جديدان. وتتمثل مهمتها في معالجة الأحرف الروسية بشكل صحيح ، والتي غالبًا ما تتم قراءتها بشكل غير صحيح بواسطة البرامج.
مقدما ، قم بإنشاء ملف excel فارغ جديد خارج البرنامج ، مع تسميته على سبيل المثال revision2.xlsx. سنفتح هذا الملف مع برنامجنا ونكتب البيانات هناك. سيكون هذا هو ملفنا النهائي.
لذلك ، يفتح البرنامج ملف excel ، ويدخله:
wb = openpyxl.load_workbook('2.xlsx') sheet=wb.get_active_sheet() x=1 y=0 test=[] test2=[] test3=[]
أعلاه أيضًا ، نقوم بإنشاء 3 قوائم فارغة حيث سنجمع البيانات: اختبار ، اختبار 2 ، اختبار 3.
بعد ذلك ، في المتغير "a" ، سنضع كل شيء قد يقع في شكل اسم التغيير. في ذ - سيكون هناك خط فاصل. هو نفسه في الطول:
a=('','','','','','','') y='?????????????????????????????????????????????????????????????????????????'
الآن الجزء الممتع.
with open ('.txt',encoding='cp1251') as f: lines = (line.strip() for line in f) for line in lines: if line.startswith(''): continue col1=line[:35] col2=line[39:] col3=line[35:39] if line.startswith(a): sheet.cell(row=x, column=1).value=line
لقد فتحنا ملف cp1251 المشفر. txt. تم مسح كل سطر من المسافات من النهاية والبداية بواسطة طريقة الشريط.
إذا كان السطر يبدأ بكلمة "old" ، فإننا نتخطاها. لماذا نحتاج إلى الحفاظ على "القديم" و "الجديد" ، وهذا واضح بالفعل. بعد ذلك ، نقسم السطر: من البداية إلى 35 حرفًا ومن 39 حرفًا إلى النهاية. وهذا هو ، نحن القضاء على الفجوة في الوسط:

نضع محتويات الفضاء في منتصف السطر في col3 ، لأنه قد لا تكون مسافة إذا كان التغيير مكتوبًا في سطر واحد على التوالي:

علاوة على ذلك ، إذا كان السطر يبدأ برأس التغيير (لقد كتبنا هذه الرؤوس إلى متغير أ) ، فسنكتب هذا السطر على الفور للتفوق دون أي تقسيم وإضافة السطر - x + = 1 (أو x = x + 1). الخطوط الفارغة ، الذي صادفنا ، نفتقد.
النظر في مقتطف الشفرة التالي:
if len(col2)==0:
إذا كان طول جزأين من السلسلة هو 0 ، فهذا يعني أنه غير موجود ، ثم test2 يحصل على الجزء الأول من السلسلة. إذا كان هناك مسافة في السطر ، ولكن الجزء الثاني من الخط غائب ، فإن الجزء الأول والثاني من السطر ، على التوالي ، يقعان في الاختبار والاختبار 2.
إذا كان هناك مسافة في السطر ، والخط غير فارغ ويبلغ طوله أكثر من 60 حرفًا ، فسيتم إضافته إلى test3.
إذا كان الخط فارغًا ، فقد مررنا بالتغيير بأكمله ، ثم نكتب كل شيء نجمعه في خلايا excel ، ونفحص الفراغ في الاختبار في وقت واحد (بحيث لا يكون فارغًا) وطول test3.
أخيرًا ، احفظ ملف excel:
wb.save('2.xlsx')
الأنماط والخط ومحاذاة النص في الثعبان
أضف بعض الجمال إلى طاولتنا.
على وجه الخصوص ، سوف نجعلها بحيث عند إخراج البيانات ، يتم تمييز رؤوس التغيير بخط غامق ، والنص نفسه أصغر وتنسيقه لسهولة القراءة.
بيثون يسمح لك أن تفعل هذا. للقيام بذلك ، نحتاج إلى إضافة وتغيير الكود في الأماكن التي نسجل فيها النتائج في ملف excel:
from openpyxl.styles import Font, Color,NamedStyle, Alignment
al= Alignment(horizontal="justify", vertical="top") ft = Font(name='Calibri', size=9) ft2 = Font(name='Calibri', size=9,bold=True)
if line.startswith(a): sheet.cell(row=x, column=1).value=line
if line==y:
if len(test3)>0:
هذا هو ، في الواقع ، أضفنا فقط الأساليب المطبقة .font و. المحاذاة.
استغرق البرنامج بأكمله النموذج:
قانون from __future__ import unicode_literals import codecs import openpyxl from openpyxl.styles import Font, Color,NamedStyle, Alignment """ 1. Consultant+ , .txt ????????????????????????????????????????????????????????????????????????? 15 1 48 15) 15) excel . word - txt : .txt : 2.xlsx """
لذلك ، في النهاية ، بعد معالجة الملف من خلال البرنامج ، لدينا جدول لائق إلى حد ما مع تغييرات في القانون:
يمكن تنزيل البرنامج من الرابط -
هنا .
مثال ملف للمعالجة من قبل البرنامج
هنا .