مرحبا بالجميع. سأخبرك في هذا المقال لماذا اخترنا كافكا قبل تسعة أشهر في أفيتو ، وما هو عليه. سوف أشارك واحدة من حالات الاستخدام - وسيط الرسائل. أخيرًا ، دعنا نتحدث عن المزايا التي حصلنا عليها من تطبيق كافكا كنهج خدمة.
المشكلة

أولا ، سياق قليلا. منذ بعض الوقت ، بدأنا في الابتعاد عن الهندسة المعمارية المتجانسة ، والآن في Avito هناك بالفعل عدة مئات من الخدمات المختلفة. لديهم مستودعاتهم الخاصة ، ومجموعة التكنولوجيا الخاصة بهم ، وهم مسؤولون عن جزءهم من منطق الأعمال.
واحدة من المشاكل مع عدد كبير من الخدمات هو التواصل. غالباً ما تريد الخدمة A معرفة المعلومات الموجودة في الخدمة B. وفي هذه الحالة ، تصل الخدمة A إلى الخدمة B من خلال واجهة برمجة تطبيقات متزامنة. ترغب الخدمة B في معرفة ما يحدث مع الخدمات G و D ، وهؤلاء بدورهم مهتمون بالخدمات A و B. عندما يكون هناك العديد من الخدمات "الفضولية" ، تتحول الاتصالات بينهما إلى كرة متشابكة.
علاوة على ذلك ، في أي وقت ، قد تصبح الخدمة A غير متوفرة. وماذا تفعل في هذه الحالة ، الخدمة B وجميع الخدمات الأخرى المرتبطة بها؟ وإذا كنت بحاجة إلى إجراء سلسلة من المكالمات المتزامنة المتتالية لإكمال عملية تجارية ، فإن احتمال فشل العملية بأكملها يصبح أعلى (والأعلى ، كلما زادت هذه السلسلة).
اختيار التكنولوجيا

حسنا ، المشاكل واضحة. يمكنك التخلص منها عن طريق إنشاء نظام مراسلة مركزي بين الخدمات. الآن ، كل واحدة من الخدمات كافية لمعرفة فقط عن نظام المراسلة هذا. بالإضافة إلى ذلك ، يجب أن يكون النظام نفسه متسامحًا مع الأعطال وقابلًا للتوسع الأفقي ، وكذلك في حالة وقوع الحوادث ، قم بتجميع مخزن مؤقت للنداء للمعالجة اللاحقة.
دعونا الآن اختيار التكنولوجيا التي سيتم تنفيذ تسليم الرسائل. للقيام بذلك ، فهم أولاً ما نتوقعه منها:
- لا ينبغي أن تضيع الرسائل بين الخدمات ؛
- قد تتكرر الرسائل
- يمكن تخزين الرسائل وقراءتها على عمق عدة أيام (المخزن المؤقت المستمر) ؛
- يمكن للخدمات الاشتراك في البيانات التي تهمهم ؛
- يمكن للعديد من الخدمات قراءة نفس البيانات ؛
- قد تحتوي الرسائل على حمولة كبيرة تفصيلية (نقل الحالة بواسطة الحدث) ؛
- في بعض الأحيان تحتاج إلى ضمان رسالة النظام.
كان من الأهمية بمكان بالنسبة لنا أن نختار النظام الأكثر قابلية للتوسعة والموثوقية ذات الإنتاجية العالية (على الأقل 100 ألف رسالة في بضع كيلو بايت في الثانية).
في هذه المرحلة ، قلنا وداعًا لـ RabbitMQ (من الصعب الحفاظ على ثباته عند ارتفاع عدد الثواني) ، و SkyTools PGQ (ليس بالسرعة الكافية والقابلة للتطوير بشكل سيئ) و NSQ (غير مستمر). يتم استخدام كل هذه التقنيات في شركتنا ، لكنها لم تتناسب مع المهمة المنوطة بها.
ثم بدأنا في البحث عن تقنيات جديدة لنا - Apache Kafka و Apache Pulsar و NATS Streaming.
أول من يسقط بولسار. قررنا أن كافكا وبولسار هما حلان متشابهان إلى حد ما. وعلى الرغم من أن Pulsar يتم اختباره من قبل الشركات الكبيرة ، إلا أنه أحدث ويوفر زمن انتقال أقل (نظريًا) ، قررنا ترك Kafka من بين الاثنين ، باعتباره المعيار الفعلي لمثل هذه المهام. ربما سنعود إلى Apache Pulsar في المستقبل.
وكان هناك مرشحان متبقيان: NATS Streaming و Apache Kafka. لقد درسنا كلا الحلين بشيء من التفصيل ، وقد توصل كلاهما إلى المهمة. ولكن في النهاية ، كنا خائفين من الشباب النسبي لـ NATS Streaming (وحقيقة أن أحد المطورين الرئيسيين ، Tyler Treat ، قرر ترك المشروع وبدء مشروعه - Liftbridge). في الوقت نفسه ، لم يسمح وضع التجميع لنظام NATS Streaming بتحجيم أفقي قوي (ربما لم تعد هذه مشكلة بعد إضافة وضع التقسيم في 2017).
ومع ذلك ، فإن NATS Streaming هي تقنية رائعة مكتوبة في Go وتدعمها Cloud Cloud Computing Foundation. على عكس Apache Kafka ، فإنه لا يحتاج إلى Zookeeper للعمل ( قد يكون من الممكن أن يقول الشيء نفسه عن Kafka قريبًا ) ، حيث ينفذ داخلها RAFT. في الوقت نفسه ، من السهل إدارة بث NATS. لا نستبعد أننا في المستقبل سنعود إلى هذه التكنولوجيا.
ومع ذلك ، أصبح أباتشي كافكا فائزنا اليوم. في الاختبارات التي أجريناها ، ثبت أنها سريعة جدًا (أكثر من مليون رسالة في الثانية الواحدة للقراءة والكتابة مع حجم رسالة يبلغ 1 كيلوبايت) ، وموثوقة بما يكفي ، وتجربة جيدة ومثبتة في بيع الشركات الكبرى. بالإضافة إلى ذلك ، يدعم Kafka عددًا من الشركات التجارية الكبرى على الأقل (على سبيل المثال ، نستخدم إصدار Confluent) ، بينما يحتوي Kafka على نظام بيئي متطور.
استعراض كافكا
قبل البدء ، أوصي فورًا بكتاب ممتاز - "كافكا: الدليل النهائي" (وهو أيضًا في الترجمة الروسية ، لكن المصطلحات تحطم الدماغ قليلاً). في ذلك يمكنك العثور على المعلومات اللازمة لفهم كافكا الأساسية وحتى أكثر من ذلك بقليل. وثائق Apache نفسها وبلوق Confluent مكتوبة بشكل جيد وسهل القراءة.
لذلك ، دعونا نلقي نظرة على كيف تعتبر كافكا وجهة نظر الطيور. يتكون هيكل كافكا الأساسي من المنتج والمستهلك والوسيط وحارس الحيوان.
وسيط

الوسيط مسؤول عن تخزين بياناتك. يتم تخزين جميع البيانات في شكل ثنائي ، والوسيط لا يعرف سوى القليل عن ماهيتها وعن بنيتها.
يوجد عادةً كل نوع منطقي من الحدث في موضوعه المنفصل (الموضوع). على سبيل المثال ، يمكن أن يقع حدث إنشاء الإعلان في العنصر item.created ، ويمكن أن يقع حدث التغيير في item.changed. يمكن اعتبار الموضوعات مصنفات للأحداث. على مستوى الموضوع ، يمكنك تعيين معلمات التكوين مثل:
- حجم البيانات المخزنة و / أو أعمارهم (retention.bytes ، retention.ms) ؛
- عامل تكرار البيانات (عامل النسخ المتماثل) ؛
- الحد الأقصى لحجم رسالة واحدة (max.message.bytes) ؛
- الحد الأدنى لعدد النسخ المتماثلة المتناسقة التي يمكن من خلالها كتابة البيانات للموضوع (min.insync.replicas) ؛
- القدرة على تجاوز الفشل إلى نسخة متماثلة متأخرة غير متزامنة مع فقد البيانات المحتمل (unclean.leader.election.enable) ؛
- وغيرها الكثير ( https://kafka.apache.org/documentation/#topicconfigs ).
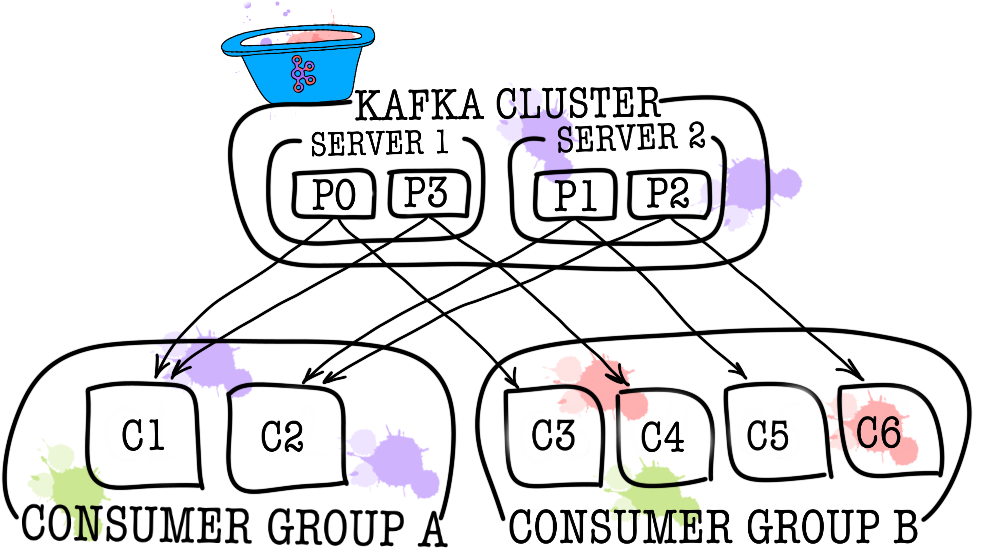
بدوره ، يتم تقسيم كل موضوع إلى قسم واحد أو أكثر (قسم). هو في القسم الذي تسقط الأحداث في نهاية المطاف. إذا كان هناك أكثر من وسيط واحد في المجموعة ، فسيتم توزيع الأقسام بالتساوي على جميع الوسطاء (إلى أقصى حد ممكن) ، مما سيتيح لك إمكانية زيادة حجم الكتابة والقراءة في موضوع واحد على العديد من الوسطاء في وقت واحد.
على القرص ، يتم تخزين البيانات لكل قسم كملفات قطعة ، بشكل افتراضي تساوي جيجابايت واحد (يتم التحكم فيها عن طريق log.segment.bytes). تتمثل إحدى الميزات المهمة في حذف البيانات من الأقسام (عند تشغيل الاستبقاء) فقط من خلال الشرائح (لا يمكنك حذف حدث واحد من القسم ، ويمكنك حذف المقطع بالكامل فقط وغير نشط فقط).
حارس الحديقة
يعمل Zookeeper كمستودع بيانات التعريف والمنسق. هو الذي يستطيع أن يقول ما إذا كان السماسرة على قيد الحياة (يمكنك أن تنظر إليه من خلال عيون حارس الحيوان من خلال الأوامر ls /brokers/ids zookeeper-shell) ، أي من السماسرة هو وحدة التحكم ( get /controller ) ، ما إذا كانت الأقسام في حالة متزامن مع النسخ المتماثلة الخاصة بهم ( get /brokers/topics/topic_name/partitions/partition_number/state ). أيضًا ، سينتقل المنتج والمستهلك إلى zookeeper أولاً لمعرفة أي وسيط يتم تخزين المواضيع والأقسام. في الحالات التي يكون فيها عامل النسخ المتماثل أكبر من 1 محددًا للموضوع ، سيشير الحارس إلى أي الأقسام هي القادة (سيتم كتابتها إلى والقراءة منها). في حالة تعطل الوسيط ، سيتم تسجيل معلومات حول أقسام المتصدرين الجديدة (اعتبارًا من الإصدار 1.1.0 بشكل غير متزامن ، وهذا أمر مهم ).
في الإصدارات الأقدم من Kafka ، كان zookeeper مسؤولًا أيضًا عن تخزين الإزاحات ، ولكن الآن يتم تخزينها في موضوع خاص __consumer_offsets على الوسيط (على الرغم من أنه لا يزال بإمكانك استخدام zookeeper لهذه الأغراض).
أسهل طريقة لتحويل بياناتك إلى قرع هي مجرد فقدان المعلومات باستخدام zookeeper. في مثل هذا السيناريو ، سيكون من الصعب للغاية فهم ماذا وأين نقرأ منه.
منتج
غالبًا ما يكون المنتج خدمة تكتب البيانات مباشرةً إلى Apache Kafka. يختار المنتج موضوعًا ، سيتم تخزين رسائله المواضيعية فيه ، ويبدأ في كتابة المعلومات عليه. على سبيل المثال ، يمكن أن يكون المنتج خدمة إعلانية. في هذه الحالة ، سيرسل أحداثًا مثل "إنشاء الإعلانات" ، "تحديث الإعلان" ، "حذف الإعلان" ، إلخ إلى الموضوعات المواضيعية. كل حدث هو زوج القيمة الرئيسية.
بشكل افتراضي ، يتم توزيع جميع الأحداث بواسطة أقسام التقسيم باستخدام round-robin إذا لم يتم تعيين المفتاح (فقدان الترتيب) ، ومن خلال MurmurHash (المفتاح) إذا كان المفتاح موجودًا (الترتيب داخل نفس القسم).
تجدر الإشارة هنا على الفور إلى أن كافكا تضمن ترتيب الأحداث في قسم واحد فقط. ولكن في الواقع ، هذه ليست في كثير من الأحيان مشكلة. على سبيل المثال ، يمكنك إضافة كل التغييرات في نفس الإعلان إلى قسم واحد (وبالتالي الحفاظ على ترتيب هذه التغييرات في الإعلان). يمكنك أيضًا تمرير رقم تسلسل في أحد حقول الحدث.
مستهلك
المستهلك مسؤول عن استرداد البيانات من Apache Kafka. إذا عدت إلى المثال أعلاه ، يمكن للمستهلك أن يكون خدمة الإشراف. سيتم الاشتراك في هذه الخدمة في موضوع خدمة الإعلان ، وعندما يظهر إعلان جديد ، ستتلقى هذه الخدمة وتحللها من أجل الامتثال لبعض السياسات المحددة.
يتذكر Apache Kafka الأحداث الأخيرة التي تلقاها المستهلك (يتم استخدام موضوع خدمة __consumer__offsets لهذا الغرض) ، مما يضمن أنه عند القراءة الناجحة ، لن يتلقى المستهلك نفس الرسالة مرتين. ومع ذلك ، إذا استخدمت الخيار enable.auto.commit = true ومنحت تمامًا مهمة تتبع موضع المستهلك في الموضوع إلى Kafka ، فيمكنك فقد البيانات . في رمز الإنتاج ، يتم التحكم في موضع المستهلك يدويًا (يتحكم المطور في اللحظة التي يجب أن يحدث فيها التزام حدث القراءة).
في الحالات التي لا يكفي فيها مستهلك واحد (على سبيل المثال ، يكون تدفق الأحداث الجديدة كبيرًا جدًا) ، يمكنك إضافة عدد قليل من المستهلكين عن طريق ربطهم معًا في مجموعة المستهلكين. مجموعة المستهلكين منطقية هي نفس المستهلك تمامًا ، ولكن مع توزيع البيانات بين أعضاء المجموعة. يتيح ذلك لكل مشارك أخذ نصيبه من الرسائل ، وبالتالي زيادة سرعة القراءة.
نتائج الاختبار

أنا هنا لن أكتب الكثير من النص التوضيحي ، فقط مشاركة النتائج. تم إجراء الاختبار على 3 أجهزة فعلية (12 وحدة المعالجة المركزية ، ذاكرة الوصول العشوائي 384 جيجابايت ، 15k SAS DISK ، 10GBit / s Net) ، تم نشر الوسطاء والحارس في lxc.
اختبار الأداء
أثناء الاختبار ، تم الحصول على النتائج التالية.
- سرعة تسجيل رسائل بحجم 1 كيلو بايت في وقت واحد من قبل 9 منتجين - 1300000 حدث في الثانية.
- سرعة قراءة رسائل 1KB في نفس الوقت من قبل 9 مستهلكين - 1500000 حدث في الثانية.
اختبار التسامح مع الخطأ
أثناء الاختبار ، تم الحصول على النتائج التالية (3 وسطاء ، 3 حراس حيوانات).
- إنهاء غير طبيعي لأحد الوسطاء لا يؤدي إلى تعليق أو عدم إمكانية الوصول إلى الكتلة. يستمر العمل كالمعتاد ، لكن الوسطاء الباقون لديهم عبء كبير.
- يؤدي الإنهاء غير الطبيعي لاثنين من الوسطاء في حالة وجود مجموعة من ثلاثة وسطاء و min.isr = 2 إلى عدم إمكانية الوصول إلى المجموعة للكتابة ، ولكن من أجل سهولة القراءة. في الحالة min.isr = 1 ، تظل المجموعة متاحة للقراءة والكتابة. ومع ذلك ، يتناقض هذا الوضع مع متطلبات أمان البيانات العالي.
- إنهاء غير طبيعي لأحد خوادم Zookeeper لا يؤدي إلى إغلاق نظام مجموعة أو عدم إمكانية الوصول إليها. يستمر العمل كالمعتاد.
- يؤدي إنهاء غير طبيعي لخادمين Zookeeper إلى عدم إمكانية الوصول إلى نظام مجموعة حتى تتم استعادة واحد على الأقل من خوادم Zookeeper. هذا البيان صحيح بالنسبة لمجموعة Zookeeper من 3 خوادم. نتيجة لذلك ، بعد البحث ، تقرر زيادة مجموعة Zookeeper إلى 5 خوادم لزيادة التسامح مع الخطأ.
كافكا كخدمة

لقد تأكدنا من أن Kafka هي تقنية ممتازة تتيح لنا حل مجموعة المهام الخاصة بنا (تنفيذ وسيط الرسائل). ومع ذلك ، قررنا منع الخدمات من الوصول مباشرة إلى كافكا وإغلاقها في المقدمة من خلال خدمة نقل البيانات. لماذا فعلنا هذا؟ هناك بالفعل عدة أسباب.
تولى ناقل البيانات جميع المهام المتعلقة بالتكامل مع Kafka (تنفيذ وتكوين المستهلكين والمنتجين ، والرصد ، والتنبيه ، وقطع الأشجار ، والتوسع ، وما إلى ذلك). وبالتالي ، فإن التكامل مع وسيط الرسائل بسيط بقدر الإمكان.
يسمح ناقل البيانات بالاستخلاص من لغة أو مكتبة معينة للعمل مع Kafka.
سمح ناقل البيانات للخدمات الأخرى بالاستخلاص من طبقة التخزين. ربما في مرحلة ما سوف نقوم بتغيير Kafka إلى Pulsar ، ولن يلاحظ أحد أي شيء (تعرف جميع الخدمات فقط عن واجهة برمجة تطبيقات ناقل البيانات).
استغرق ناقل البيانات التحقق من صحة مخططات الأحداث.
باستخدام مصادقة ناقل البيانات يتم تنفيذه.
تحت غطاء ناقل البيانات ، يمكننا ، دون توقف ، تحديث إصدارات كافكا تكتمًا ، وإجراء تكوينات مركزية للمنتجين والمستهلكين والوسطاء ، إلخ.
أتاح لنا ناقل البيانات إضافة ميزات نحتاجها ليست في Kafka (مثل تدقيق الموضوعات ، ومراقبة الحالات الشاذة في المجموعة ، وإنشاء DLQ ، وما إلى ذلك).
يسمح ناقل البيانات بتنفيذ الفشل مركزيًا لجميع الخدمات.
في الوقت الحالي ، لبدء إرسال الأحداث إلى وسيط الرسائل ، ما عليك سوى توصيل مكتبة صغيرة برمز الخدمة الخاص بك. هذا كل شيء. لديك الفرصة للكتابة والقراءة والتوسعة بسطر واحد من التعليمات البرمجية. التنفيذ الكامل مخفي عنك ، فقط عدد قليل من العصي مثل حجم الدُفعة. تحت غطاء محرك السيارة ، ترفع خدمة ناقل البيانات العدد اللازم من مثيلات المنتجين والمستهلكين في Kubernetes وتضيف التكوين اللازم إليها ، ولكن كل هذا شفاف لخدمتك.
بالطبع ، لا توجد رصاصة فضية ، وهذا النهج له حدوده.
- يلزم دعم ناقل البيانات بمفرده ، على عكس مكتبات الجهات الخارجية.
- يزيد ناقل البيانات من عدد التفاعلات بين الخدمات ووسيط الرسائل ، مما يؤدي إلى انخفاض الأداء مقارنةً بالكافكا العارية.
- لا يمكن إخفاء كل شيء ببساطة عن الخدمات ، فنحن لا نريد تكرار وظيفة KSQL أو Kafka Streams في ناقل البيانات ، لذلك في بعض الأحيان يتعين عليك السماح للخدمات بالانتقال مباشرة.
في حالتنا ، تفوقت إيجابيات السلبيات ، وكان قرار تغطية وسيط الرسائل مع خدمة منفصلة له ما يبرره. خلال عام العملية ، لم يكن لدينا أي حوادث ومشاكل خطيرة.
ملاحظة: بفضل صديقتي ، إيكاترينا أوبلياليايفا ، على الصور الرائعة لهذا المقال. إذا كنت تحبهم ، فهناك المزيد من الرسوم التوضيحية.