في السنوات الأخيرة ، حققت
الترجمة الآلية العصبية (NMP) باستخدام نماذج "المحولات" نجاحًا غير عادي. عادة ما يتم تدريب صناديق النقد الدولي القائمة على شبكات عصبية عميقة من البداية إلى النهاية في حالات متوازية للغاية من النصوص (أزواج النص) فقط على أساس البيانات نفسها ، دون الحاجة إلى تعيين قواعد لغوية دقيقة.
على الرغم من كل النجاحات ، يمكن أن تكون نماذج NMP حساسة للتغيرات الصغيرة في بيانات الإدخال ، والتي يمكن أن تتجلى في شكل أخطاء متعددة - نقص الترجمة والترجمة المفرطة والترجمة غير الصحيحة. على سبيل المثال ، الاقتراح الألماني التالي ، "محول" NMP عالي الجودة سوف يترجم بشكل صحيح.
"Der Sprecher des Untersuchungsausschusses hat angekündigt، vor Gericht zu ziehen، falls sich die geladenen Zeugen weiterhin weigern sollten، eine Aussage zu machen."
(الترجمة الآلية: "أعلن المتحدث باسم لجنة التحقيق أنه إذا استمر الشهود الذين استدعوا يرفضون الإدلاء بشهاداتهم ، فسيتم تقديمه إلى المحكمة.")
الترجمة: أعلن ممثل لجنة التحقيق أنه إذا استمر الشهود المدعوون في رفض الإدلاء بشهادتهم ، فسوف يخضع للمساءلة.
ومع ذلك ، عند إجراء تغيير بسيط في الجملة الواردة ، واستبدال كلمة geladenen بالمرادف vorgeladenen ، تتغير الترجمة بشكل كبير (وتصبح غير صحيحة):
"Der Sprecher des Untersuchungsausschusses hat angekündigt، vor Gericht zu ziehen، falls sich die vorgeladenen Zeugen weiterhin weigern sollten، eine Aussage zu machen."
(الترجمة الآلية: "أعلنت لجنة التحقيق أنه سيقدم إلى العدالة إذا استمر الشهود الذين تمت دعوتهم في رفض الشهادة").
الترجمة: أعلنت لجنة التحقيق أنه سيقدم إلى العدالة إذا استمر الشهود المدعوون في رفض الشهادة.
لا يسمح عدم استقرار نماذج NMP بتطبيق الأنظمة التجارية على المهام التي يكون فيها مستوى مماثل من عدم الاستقرار غير مقبول. لذلك ، فإن توفر نماذج التعلم المستدام للتعلم ليس أمرًا مرغوبًا فحسب ، ولكنه ضروري في كثير من الأحيان. في الوقت نفسه ، على الرغم من أن دراسة الشبكات العصبية تدرس بنشاط من قبل مجموعة من الباحثين في مجال رؤية الكمبيوتر ، إلا أن هناك مواد قليلة عن نماذج NMP للتعلم المستقر.
في مقالتنا
، "الترجمة الآلية المستدامة ذات المدخلات التعددية المزدوجة" ، نقترح نهجًا يستخدم أمثلة الخصومة المتولدة لتحسين ثبات نماذج الترجمة الآلية لتغيرات المدخلات الصغيرة. نقوم بتدريس نموذج NMP مستقر للتغلب على الأمثلة التنافسية الناتجة مع الأخذ في الاعتبار المعرفة حول هذا النموذج ولتشويه توقعاته. نظهر أن هذا النهج يحسن كفاءة نموذج NMP في الاختبارات القياسية.
نموذج التدريب مع AdvGen
يجب أن يولد نموذج NMP المثالي ترجمات مماثلة لمدخلات مختلفة لها اختلافات بسيطة. فكرة منهجنا هي التدخل في نموذج الترجمة باستخدام المدخلات التنافسية على أمل زيادة ثباتها. يتم ذلك باستخدام خوارزمية توليد Adversarial Generation (AdvGen) ، التي تولد أمثلة تنافسية صالحة تتداخل مع النموذج ثم تغذيها في نموذج التدريب. على الرغم من أن هذه الطريقة مستوحاة من فكرة الشبكات التنافسية التوليدية (GSS) ، فإنها لا تستخدم شبكة تمييزية ، ولكنها تستخدم ببساطة مثالاً تنافسياً في التدريب ، في الواقع ، تنويع وتوسيع مجموعة التدريب.
الخطوة الأولى هي إثارة غضب البيانات من خلال AdvGen. نبدأ باستخدام محول لحساب فقدان عملية النقل بناءً على العرض الوارد الأصلي ، وعرض المدخلات المستهدفة ، وعرض الناتج المستهدف. تقوم AdvGen باختيار الكلمات في الجملة الأصلية بشكل عشوائي ، بناءً على افتراض التوزيع الموحد. تحتوي كل كلمة على قائمة مماثلة من الكلمات المتشابهة ، أي مرشحين بديلين. منه ، تحدد AdvGen الكلمة التي من المرجح أن تؤدي إلى أخطاء في إخراج المحول. ثم يتم تغذية هذه الجملة الخصم ولدت إلى المحولات ، بدءا مرحلة الدفاع.
 أولاً ، يتم تطبيق نموذج المحول على الجملة الواردة (أسفل اليسار) ، ثم يتم حساب خسارة الترجمة مع جملة المخرجات الهدف (أعلى القمة) وجملة الإدخال المستهدفة (في منتصف اليمين ، تبدأ بـ "<sos>"). يقبل AdvGen الجملة الأصلية ، وتوزيع اختيار الكلمات ، ومرشحي الكلمات ، وفقدان الترجمة كمدخلات ، ويخلق مثالًا على شفرة المصدر للخصم.
أولاً ، يتم تطبيق نموذج المحول على الجملة الواردة (أسفل اليسار) ، ثم يتم حساب خسارة الترجمة مع جملة المخرجات الهدف (أعلى القمة) وجملة الإدخال المستهدفة (في منتصف اليمين ، تبدأ بـ "<sos>"). يقبل AdvGen الجملة الأصلية ، وتوزيع اختيار الكلمات ، ومرشحي الكلمات ، وفقدان الترجمة كمدخلات ، ويخلق مثالًا على شفرة المصدر للخصم.في مرحلة الدفاع ، يتم إرجاع شفرة المصدر للخصم إلى المحول. يتم حساب خسارة الترجمة مرة أخرى ، ولكن هذه المرة باستخدام مصدر الإدخال المثير للجدل. باستخدام الأسلوب نفسه كما كان من قبل ، تستخدم AdvGen جملة واردة مستهدفة ، وتوزيع اختيار الكلمات المحسوب من مصفوفة الانتباه ، والمرشحين لاستبدال الكلمات ، وفقدان الترجمة لإنشاء مثال على شفرة المصدر المثيرة للجدل.
 في مرحلة الدفاع ، تصبح شفرة المصدر للخصم هي المدخلات للمحول ، ويتم حساب خسائر الترجمة. باستخدام الطريقة نفسها كما كان من قبل ، تنشئ AdvGen مثالًا على شفرة المصدر المثيرة للجدل استنادًا إلى الإدخال الهدف.
في مرحلة الدفاع ، تصبح شفرة المصدر للخصم هي المدخلات للمحول ، ويتم حساب خسائر الترجمة. باستخدام الطريقة نفسها كما كان من قبل ، تنشئ AdvGen مثالًا على شفرة المصدر المثيرة للجدل استنادًا إلى الإدخال الهدف.أخيرًا ، يتم رد الجملة المعادية على المحول ، ويتم حساب فقد الاستقرار بناءً على مثال مصدر الخصومة ، ومثال الخصومة للمدخلات المستهدفة والجملة المستهدفة. إذا أدى التدخل في النص إلى خسائر كبيرة ، يتم تقليلها إلى الحد الأدنى بحيث عندما تتعرض النماذج لاضطرابات مماثلة ، فإنها لا تكرر الخطأ نفسه. من ناحية أخرى ، إذا كان الاضطراب يؤدي إلى خسائر صغيرة ، فلا شيء يحدث ، مما يشير إلى أن النموذج قادر بالفعل على مواجهة مثل هذه الاضطرابات.
أداء النموذج
نوضح فعالية نهجنا من خلال تطبيقه على اختبارات الترجمة القياسية من الصينية إلى الإنجليزية ومن الإنجليزية إلى الألمانية. حصلنا على تحسن كبير في الترجمة بمقدار 2.8 و 1.6 نقطة ، على التوالي ، مقارنةً بالنموذج المتنافس للمحول ، ونحقق جودة قياسية جديدة للترجمة.
 مقارنة بين نماذج المحولات في الاختبارات القياسية
مقارنة بين نماذج المحولات في الاختبارات القياسيةثم نقوم بتقييم أداء نموذجنا على مجموعة بيانات صاخبة باستخدام إجراء مماثل للإجراء الموضح لـ AdvGen. نحن نأخذ بيانات الإدخال الخالصة ، على سبيل المثال ، تلك المستخدمة في الاختبارات القياسية للمترجمين ، ونختار عشوائيًا الكلمات التي نستبدلها بكلمات مماثلة. نجد أن نموذجنا يُظهر ثباتًا محسّنًا مقارنةً بالطرز الحديثة الأخرى.
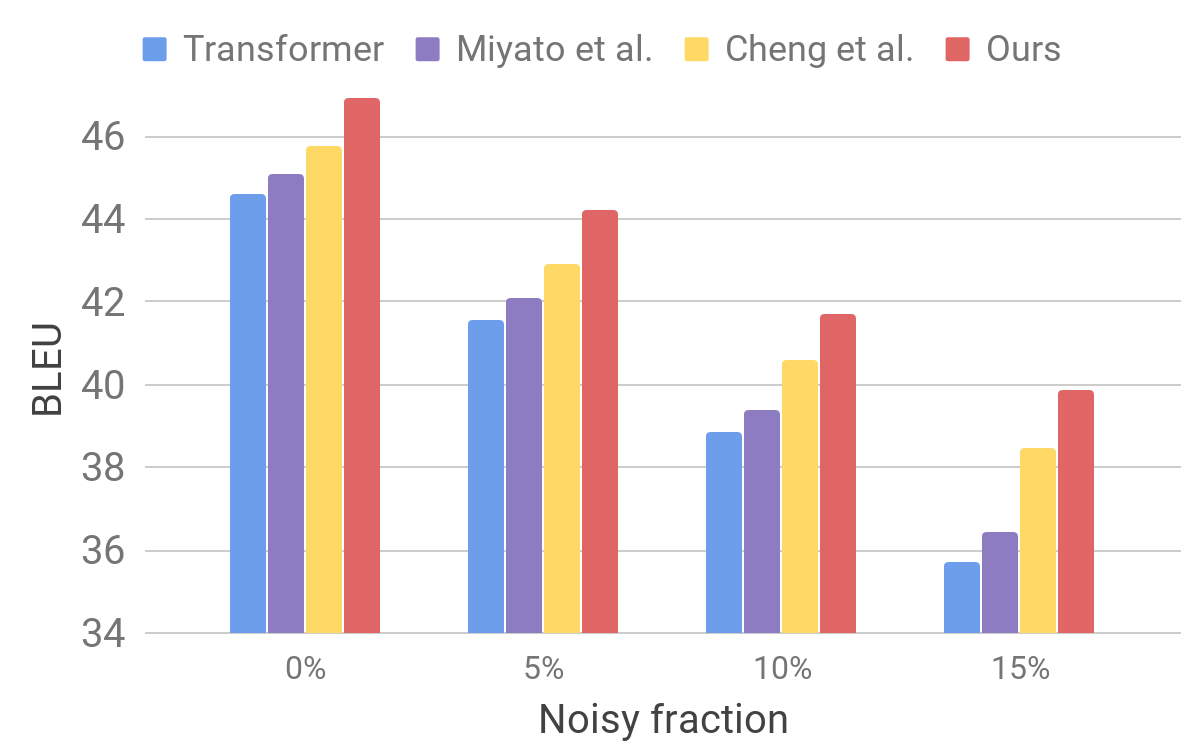 مقارنة بين المحولات والنماذج الأخرى على بيانات المدخلات الصاخبة
مقارنة بين المحولات والنماذج الأخرى على بيانات المدخلات الصاخبةتوضح هذه النتائج أن أساليبنا قادرة على التغلب على الاضطرابات الصغيرة الناشئة في الجملة القادمة وتحسين كفاءة التعميم. إنه متقدم على نماذج الترجمة المنافسة ويحقق كفاءة ترجمة قياسية في الاختبارات القياسية. نأمل أن يصبح نموذج المترجم لدينا أساسًا ثابتًا لتحسين نتائج حل العديد من المشكلات التالية ، خاصة تلك الحساسة أو غير المتسامحة لنصوص الإدخال غير الكاملة.