على الرغم من أن الشبكات العصبية بدأت تستخدم لتوليف الكلام منذ وقت ليس ببعيد ( على سبيل المثال ) ، إلا أنها تمكنت بالفعل من تجاوز الأساليب التقليدية وكل عام تمر بمهام أحدث وأحدث.
على سبيل المثال ، منذ شهرين كان هناك تنفيذ لتوليف الكلام باستخدام الاستنساخ الصوتي في الوقت الحقيقي للاستنساخ الصوتي . دعنا نحاول معرفة مكوناتها ونحقق نموذجنا الصوتي متعدد اللغات (الروسية-الإنجليزية).
هيكل
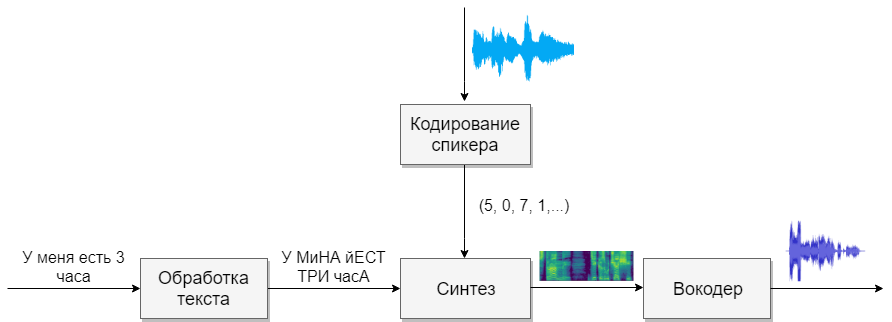
يتكون نموذجنا من أربع شبكات عصبية. الأول سيحول النص إلى صوتيات (g2p) ، أما الثاني فسيحول الخطاب الذي نريد استنساخه إلى متجه من العلامات (الأرقام). سيقوم الثالث بتوليف أطياف ميل بناءً على مخرجات الأولين. وأخيرًا ، سوف يستقبل الرابع الصوت من الطيفية.
مجموعات البيانات
هذا النموذج يحتاج إلى الكثير من الكلام. أدناه هي القواعد التي سوف تساعد في هذا.
معالجة الكلمات
المهمة الأولى ستكون معالجة النصوص. تخيل النص بالصيغة التي سيتم بها التعبير عنها. سنعرض الأرقام بالكلمات ، وسنفتح الاختصارات. اقرأ المزيد في المقال حول التوليف . هذه مهمة صعبة ، لذا لنفترض أننا قمنا بالفعل بمعالجة النص (تمت معالجته في قواعد البيانات أعلاه).
والسؤال التالي الذي يجب طرحه هو ما إذا كنت تريد استخدام تسجيل العنب أو التسجيل الصوتي. للحصول على صوت أحادي أحادي اللغة ، يكون نموذج الحروف مناسبًا أيضًا. إذا كنت ترغب في العمل باستخدام نموذج متعدد اللغات متعدد الصوت ، فأنصحك باستخدام النسخ (Google أيضًا ).
G2P
للغة الروسية ، هناك تطبيق يسمى russian_g2p . إنها مبنية على قواعد اللغة الروسية وتتواءم بشكل جيد مع المهمة ، ولكن لها عيوب. ليس كل الكلمات الإجهاد ، وأيضا ليست مناسبة لنموذج متعدد اللغات. لذلك ، خذ القاموس الذي تم إنشاؤه لها ، وأضف القاموس للغة الإنجليزية وإطعام الشبكة العصبية (على سبيل المثال ، 1 ، 2 )
قبل تدريب الشبكة ، يجدر التفكير في أن الأصوات من لغات مختلفة تبدو متشابهة ، ويمكنك اختيار حرف واحد لها ، وهذا أمر مستحيل. كلما زاد عدد الأصوات الموجودة ، زاد صعوبة تعلم النموذج ، وإذا كان هناك عدد قليل منها ، فسيكون للنموذج لهجة. تذكر أن تؤكد الشخصيات الفردية مع حروف العلة المجهدة. بالنسبة للغة الإنجليزية ، يلعب الضغط الثانوي دورًا صغيرًا ، ولن أميزه.
ترميز السماعة
تشبه الشبكة مهمة تحديد المستخدم عن طريق الصوت. في الإخراج ، يحصل المستخدمون المختلفون على متجهات مختلفة بأرقام. أقترح استخدام تطبيق CorentinJ نفسه ، والذي يعتمد على المقال . النموذج عبارة عن LSTM من ثلاث طبقات مع 768 عقدة ، تليها طبقة متصلة بشكل كامل مكونة من 256 خلية عصبية ، مما يعطي متجهًا يتكون من 256 رقمًا.
أظهرت التجربة أن شبكة مدربة على اللغة الإنجليزية تتحدث اللغة الروسية بشكل جيد. هذا يبسط الحياة إلى حد كبير ، حيث يتطلب التدريب الكثير من البيانات. أوصي بأخذ نموذج مدرّب بالفعل وإعادة التدريب باللغة الإنجليزية من VoxCeleb و LibriSpeech ، بالإضافة إلى كل الكلام الروسي الذي تجده. لا يحتاج المشفر إلى شرح توضيحي لشظايا الكلام.
تدريب
- قم بتشغيل
python encoder_preprocess.py <datasets_root> لمعالجة البيانات - تشغيل "visdom" في محطة منفصلة.
- قم بتشغيل
python encoder_train.py my_run <datasets_root> لتدريب المشفر
تركيب
دعنا ننتقل إلى التوليف. النماذج التي أعرفها لا تحصل على صوت مباشر من النص ، لأنه صعب (الكثير من البيانات). أولاً ، ينتج النص صوتًا في شكل طيفي ، وعندها فقط ستترجم الشبكة الرابعة إلى صوت مألوف. لذلك ، نفهم أولاً كيف يرتبط الشكل الطيفي بالصوت. من الأسهل معرفة المشكلة العكسية المتمثلة في كيفية الحصول على برنامج طيفي من الصوت.
ينقسم الصوت إلى مقاطع من 25 مللي ثانية بزيادات قدرها 10 مللي ثانية (الافتراضي في معظم الطرز). بعد ذلك ، باستخدام تحويل فورييه لكل قطعة ، يتم حساب الطيف (التذبذبات التوافقية ، يعطي مجموعها الإشارة الأصلية) ويتم تقديمها في شكل رسم بياني ، حيث يكون الشريط العمودي هو طيف مقطع واحد (في التردد) ، وفي السلسلة الأفقية - تسلسل من الأجزاء (في الوقت المناسب). هذا الرسم البياني يسمى الطيفية. إذا تم تشفير التردد بشكل غير خطي (الترددات المنخفضة أفضل من الترددات العليا) ، فسوف يتغير المقياس العمودي (ضروري لتقليل البيانات) ، ثم يسمى هذا الرسم البياني باسم الطيفية Mel. هذه هي الطريقة التي تعمل بها السمع البشري ، ونسمع انحرافًا طفيفًا في الترددات المنخفضة أفضل من الترددات العليا ، وبالتالي لن تعاني جودة الصوت
هناك العديد من تطبيقات التوليف الطيفي الجيدة مثل Tacotron 2 و Deepvoice 3 . كل نموذج من هذه النماذج له تطبيقاته الخاصة ، على سبيل المثال 1 ، 2 ، 3 ، 4 . سوف نستخدم (مثل CorentinJ) طراز تاكوترون من ريحان ماما.
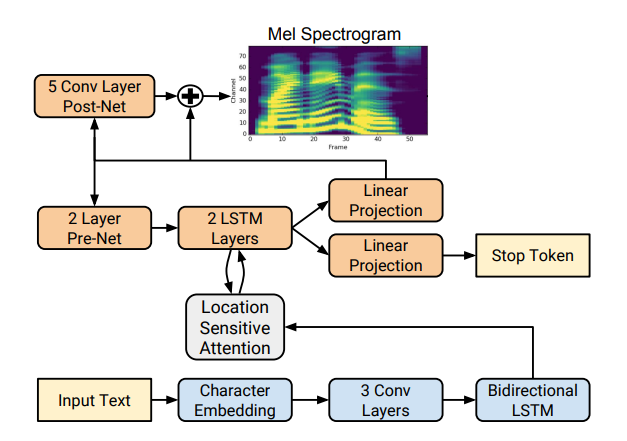
يستند Tacotron على شبكة seq2seq مع آلية الاهتمام. اقرأ التفاصيل في المقال .
تدريب
لا تنسَ تحرير الأدوات المساعدة / symbols.py إذا لم تقم بتجميع الكلام باللغة الإنجليزية فقط ، و hparams.p ، ولكن أيضًا preprocess.py.
يتطلب التوليف الكثير من الصوت النظيف والمميز بشكل جيد من السماعات المختلفة. هنا لغة أجنبية لن تساعد.
- قم بتشغيل
python synthesizer_preprocess_audio.py <datasets_root> لإنشاء صوت وطيفية معالجين - قم بتشغيل
python synthesizer_preprocess_embeds.py <datasets_root> لتشفير الصوت (احصل على علامات الصوت) - قم بتشغيل
python synthesizer_train.py my_run <datasets_root> لتدريب المزج
مشفر صوتي
الآن يبقى فقط لتحويل الطيفية إلى الصوت. لهذا ، فإن الشبكة الأخيرة هي مشفر الصوت. السؤال الذي يطرح نفسه ، إذا تم الحصول على الطيفية من الصوت باستخدام تحويل فورييه ، هل من الممكن الحصول على الصوت مرة أخرى باستخدام التحول العكسي؟ الجواب نعم ولا. تحتوي التذبذبات التوافقية التي تشكل الإشارة الأصلية على السعة والطور ، وتحتوي الطيفية لدينا على معلومات فقط عن السعة (من أجل تقليل المعلمات والعمل مع الطيفية) ، لذلك إذا قمنا بتحويل فورييه العكسي ، فسنحصل على صوت سيء.
لحل هذه المشكلة ، ابتكروا خوارزمية Griffin-Lim سريعة. يفعل تحويل فورييه معكوس من الطيفية ، والحصول على صوت "سيئة". ثم يقوم بإجراء تحويل مباشر لهذا الصوت ويتلقى طيفًا يحتوي بالفعل على القليل من المعلومات حول المرحلة ، ولا تتغير السعة في العملية. بعد ذلك ، يتم أخذ التحول العكسي مرة أخرى ويتم الحصول على صوت أنظف. لسوء الحظ ، فإن جودة الكلام الناتجة عن هذه الخوارزمية تترك الكثير مما هو مرغوب فيه.
تم استبداله بأجهزة تشفير صوتية عصبية مثل WaveNet و WaveRNN و WaveGlow وغيرها. استخدم CorentinJ نموذج WaveRNN بواسطة fatchord

للمعالجة المسبقة للبيانات ، يتم استخدام طريقتين. إما الحصول على الطيفية من الصوت (باستخدام تحويل فورييه) ، أو من النص (باستخدام نموذج التوليف). جوجل يوصي النهج الثاني.
تدريب
- قم بتشغيل
python vocoder_preprocess.py <datasets_root> لتجميع البرامج الطيفية - قم بتشغيل
python vocoder_train.py <datasets_root> لـ python vocoder_train.py <datasets_root>
في المجموع
لدينا نموذج لتوليف الكلام متعدد اللغات الذي يمكنه استنساخ صوت.
تشغيل مربع الأدوات: python demo_toolbox.py -d <datasets_root>
أمثلة يمكن سماعها هنا
نصائح واستنتاجات
- تحتاج إلى الكثير من البيانات (> 1000 صوت ،> 1000 ساعة)
- سرعة التشغيل قابلة للمقارنة مع الوقت الحقيقي فقط في تركيب 4 جمل على الأقل
- بالنسبة إلى المشفر ، استخدم النموذج المدرّب مسبقًا للغة الإنجليزية ، مع إعادة التدريب قليلاً. هي في حالة جيدة
- يعمل المزج المدرّب على البيانات "النظيفة" بشكل أفضل ، لكن الاستنساخ أسوأ من الشخص الذي تدرب على حجم أكبر ، لكن البيانات القذرة
- النموذج يعمل بشكل جيد فقط على البيانات التي درستها
يمكنك تجميع صوتك عبر الإنترنت باستخدام colab ، أو الاطلاع على تطبيقي على github وتنزيل الأوزان الخاصة بي.