مرحباً بالجميع ، بعض المعلومات "من تحت الغطاء" هي تاريخ الورشة الهندسية لـ Alfastrakhovaniya - التي تثير عقولنا الفنية.

Apache Spark هي أداة رائعة تسمح لك بسرعة وسهولة بمعالجة كميات كبيرة من البيانات على موارد الحوسبة المتواضعة إلى حد ما (أعني معالجة نظام المجموعة).
تقليديا ، يتم استخدام دفتر jupyter في معالجة البيانات المخصصة. بالاقتران مع Spark ، يسمح لنا هذا بمعالجة إطارات البيانات الطويلة الأجل (يتعامل Spark مع تخصيص الموارد ، وتعيش إطارات التاريخ في مكان ما في المجموعة ، ومدة حياتها محدودة بعمر سياق Spark).
بعد نقل معالجة البيانات إلى Apache Airflow ، يتم تقليل عمر الإطارات إلى حد كبير - يظل سياق Spark داخل نفس بيان Airflow. كيف تتغلب على هذا ، لماذا تتجول وماذا تفعل ليفي به - اقرأ تحت الخفض.
دعونا نلقي نظرة على مثال بسيط للغاية: لنفترض أننا بحاجة إلى إلغاء البيانات في جدول كبير وحفظ النتيجة في جدول آخر لمزيد من المعالجة (عنصر نموذجي في خط أنابيب معالجة البيانات).
كيف سنفعل هذا:
- البيانات المحملة في dataframe (اختيار من جدول كبير والأدلة)
- نظرت إلى "عيون" في النتيجة (هل نجحت بشكل صحيح)
- تم حفظ dataframe في جدول Hive (على سبيل المثال)
استنادًا إلى نتائج التحليل ، قد نحتاج إلى إدراج معالجة محددة في الخطوة الثانية (استبدال القاموس أو أي شيء آخر). من حيث المنطق ، لدينا ثلاث خطوات
- الخطوة 1: تنزيل
- الخطوة 2: المعالجة
- الخطوة 3: حفظ
في دفتر jupyter ، هذه هي الطريقة التي نقوم بها - يمكننا معالجة البيانات التي تم تنزيلها لفترة طويلة بشكل تعسفي ، مما يتيح التحكم في موارد Spark.
من المنطقي توقع نقل هذا القسم إلى Airflow. وهذا هو ، أن يكون الرسم البياني من هذا النوع

لسوء الحظ ، لا يكون ذلك ممكنًا عند استخدام مجموعة Airflow + Spark: يتم تنفيذ كل عبارة Airflow في مترجم python الخاص بها ، وبالتالي ، من بين أمور أخرى ، يجب على كل عبارة "أن تستمر" بطريقة ما في نتائج أنشطتها. وبالتالي ، تتم معالجة "معالجتنا" في خطوة واحدة - "إزالة البيانات عن البيانات".
كيف يمكن إرجاع مرونة دفتر ملاحظات jupyter إلى Airflow؟ من الواضح أن المثال أعلاه هو "لا يستحق كل هذا العناء" (ربما ، على العكس من ذلك ، اتضح أنه خطوة معالجة جيدة مفهومة). ولكن لا يزال - كيفية جعل بيانات Airflow تنفذ في نفس سياق Spark على مساحة بيانات مشتركة؟
مرحبا بكم ليفي
منتج Hadoop للنظم الإيكولوجية يأتي لإنقاذ - Apache Livy.
لن أحاول هنا أن أصف نوع "الوحش". إذا كانت مختصرة جدًا وبالأسود والأبيض - تتيح لك Livy "حقن" رمز python في برنامج ينفّذه برنامج التشغيل:
- أولا نخلق جلسة ليفي
- بعد ذلك لدينا القدرة على تنفيذ كود الثعبان التعسفي في هذه الجلسة (تشبه إلى حد بعيد أيديولوجية المشتري / ipython)
وإلى كل هذا هناك واجهة برمجة تطبيقات REST.
بالعودة إلى مهمتنا البسيطة: مع Livy ، يمكننا حفظ المنطق الأصلي لإزالة الشذوذ
- في الخطوة الأولى (البيان الأول من الرسم البياني لدينا) سنقوم بتحميل وتنفيذ رمز تحميل البيانات في إطار البيانات
- في الخطوة الثانية (البيان الثاني) - قم بتنفيذ التعليمات البرمجية للمعالجة الإضافية اللازمة لهذا الإطار
- في الخطوة الثالثة - رمز لحفظ dataframe إلى الجدول
ما من ناحية Airflow قد يبدو كالتالي:
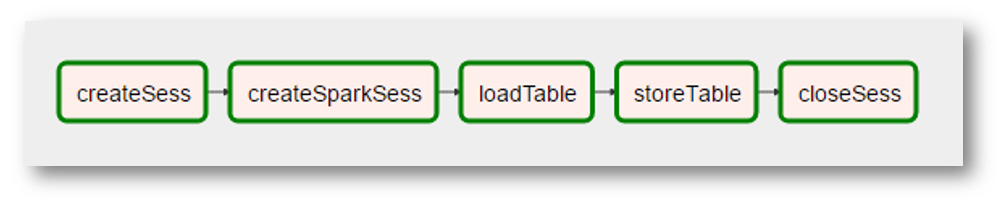
(نظرًا لأن الصورة عبارة عن لقطة شاشة حقيقية جدًا ، فقد تمت إضافة "حقائق" إضافية - أصبح إنشاء سياق Spark عملية منفصلة باسم غريب ، اختفى "معالجة" البيانات بسبب عدم الحاجة إليها ، إلخ.)
لتلخيص ، نحصل عليه
- بيان تدفق الهواء العالمي الذي ينفذ رمز الثعبان في جلسة ليفي
- القدرة على "تنظيم" رمز الثعبان إلى رسوم بيانية معقدة إلى حد ما (Airflow لذلك)
- القدرة على معالجة تحسينات المستوى الأعلى ، على سبيل المثال ، في أي ترتيب نحتاج إلى القيام بتحولاتنا حتى يتمكن Spark من الاحتفاظ بالبيانات العامة في ذاكرة نظام المجموعة لأطول فترة ممكنة
يحتوي خط الأنابيب النموذجي لإعداد البيانات للنمذجة على حوالي 25 استفسارًا في 10 جداول ، ومن الواضح أن بعض الجداول تستخدم أكثر من غيرها (نفس "البيانات العامة") وهناك شيء ما للتحسين.
ما التالي
لقد تم اختبار القدرة التقنية ، كما نعتقد - كيفية ترجمة تحولاتنا بشكل تقني إلى هذا النموذج. وكيفية التعامل مع التحسين المذكور أعلاه. لا نزال في بداية هذا الجزء من رحلتنا - عندما يكون هناك شيء مثير للاهتمام ، فإننا بالتأكيد سنشاركه.