بحثًا عن مجموعة بيانات مثيرة للاهتمام وبسيطة ، صادفت هذا الرجل الوسيم .
عن هذا الجمال
أنه يحتوي على بيانات عن نمو ووزن 10000 من الرجال والنساء . لا يوجد وصف لا شيء "لا لزوم لها". فقط الطول والوزن وعلامة الكلمة. أعجبتني هذه البساطة الغامضة.
حسنًا ، لنبدأ!
ما كان مثيرا للاهتمام بالنسبة لي؟
- ما هو نطاق الوزن والطول بالنسبة لمعظم الرجال والنساء؟
- أي نوع من الرجل "المتوسط" والمرأة "المتوسطة" هم؟
- هل يمكن أن يتنبأ نموذج تعلم آلة KNN البسيط من هذه البيانات بالوزن حسب الطول ؟
دعنا نذهب!

النظرة الأولى
أولا ، تحميل الوحدات اللازمة
عندما وقفت المكتبات تمامًا - حان الوقت لتحميل DataSet نفسها وإلقاء نظرة على العناصر العشرة الأولى. هذا ضروري حتى تكون القناة الهضمية لدينا هادئة ، وقد حملنا كل شيء بشكل صحيح.
بالمناسبة ، لا تنزعج من أن الطول والوزن يختلفان عما اعتدنا عليه. هذا بسبب نظام قياس مختلف: البوصات والجنيه ، بدلاً من السنتيمترات والكيلوغرام .
data = pd.read_csv('weight-height.csv') data.head(10)
حسن! نرى أن المداخل العشرة الأولى هي "رجال". نرى طولهم والوزن . البيانات المحملة بشكل جيد.
الآن يمكنك إلقاء نظرة على عدد الصفوف في المجموعة.
data.shape >> (10000, 3)
عشرة آلاف سطر / سجلات. ولكل منها ثلاثة معايير . ما تحتاجه!
حان الوقت لإصلاح نظام القياس. الآن هنا سم و كيلوغرام.
data['Height'] *= 2.54 data['Weight'] /= 2.205
الآن أصبح أكثر دراية. ويخبرنا السجل الأول عن رجل يبلغ ارتفاعه حوالي 190 سم ويزن حوالي 110 كجم. رجل كبير. دعنا ندعوه بوب.
ولكن كيف نفهم: هل هو كثير أو قليل مقارنة بالباقي؟ هل من الممكن أننا جميعا زائد أو ناقص الفول؟ هذا هو في وقت لاحق قليلا.
الآن لنكتشف مدى تناسق النوعين في مجموعة البيانات هذه؟
data['Gender'].value_counts() >> Male 5000 Female 5000 Name: Gender, dtype: int64
من الناحية المثالية منقسم بالتساوي. وهذا أمر جيد ، لأنه إذا كان هناك: 9999 رجل وامرأة واحدة ، فلن يكون هناك أي معنى في التظاهر بأن مجموعة البيانات هذه تكشف كلا الجنسين بشكل متساوٍ. في حالتنا ، كل شيء على ما يرام!
تقسيم وتعلم!
يشير الحدس الآن إلى أنه سيكون من الصحيح الفصل بين الجنسين واستكشاف كل منهما على حدة. في الواقع ، في كثير من الأحيان نرى أن الرجال والنساء لديهم طول زائد ووزن مختلفان أو ناقصان
دعنا نلقي نظرة على الإحصاءات الوصفية الصغيرة التي توفرها لنا وحدة الباندا .
الرجال :
data_male.describe()
النساء :
data_female.describe()
برنامج تعليمي صغير على المعلومات أعلاهبلغة واضحة:
الإحصاءات الوصفية هي مجموعة من الأرقام / الخصائص لوصف. ربما هذا هو أسهل لفهم نوع الإحصاءات.
تخيل أنك تصف معالم الكرة. يمكن أن يكون:
- كبيرة / صغيرة
- السلس / الخام
- الأزرق / الأحمر
- كذاب / وليس حقا.
مع تبسيط قوي ، يمكننا أن نقول أن الإحصاءات الوصفية تشارك في هذا . لكنه يفعل هذا ليس مع الكرات ، ولكن مع البيانات.
وهنا المعلمات من الجدول أعلاه:
- العد - عدد الحالات.
- mean - متوسط أو مجموع كل القيم مقسومًا على عددها.
- الأمراض المنقولة جنسيا - الانحراف المعياري أو جذر التباين. يُظهر تناثر القيم بالنسبة إلى المتوسط.
- دقيقة - الحد الأدنى للقيمة أو الحد الأدنى.
- 25 ٪ - الربع الأول. يظهر قيمة أدناه 25 ٪ من السجلات.
- 50 ٪ - الربع الثاني أو الوسيط. يظهر قيمة أعلى وتحت نفس عدد الإدخالات.
- 75 ٪ - الربع الثالث. عن طريق اللاهوت مع الربع الأول ، ولكن أقل من 75 ٪ من السجلات.
- كحد أقصى - القيمة القصوى أو الحد الأقصى.
متوسط القيمة حساسة للغاية للانبعاثات! إذا تلقى أربعة أشخاص راتبا قدره 10000 ₽ ، والخامس - 460000 ،000. سيكون هذا المتوسط - 100 000 ₽. وسيظل الوسيط كما هو - 10 000 ₽.
هذا لا يعني أن المتوسط مؤشر سيء. يجب معالجتها بعناية أكبر.
بالمناسبة ، هناك عقبة مع الوسيط أيضًا.
إذا كان عدد القياسات غريب. هذا الوسيط هو القيمة في الوسط ، إذا وضعت البيانات "حسب النمو".
وإذا كان الأمر كذلك ، فإن الوسيط هو المتوسط بين الاثنين "الأكثر مركزية".
إذا كانت مجموعة البيانات تحتوي فقط على أعداد صحيحة وكان الوسيط الكسري ، فلا تفاجأ. على الأرجح عدد القياسات حتى.
مثال :
جلب الابن علامات من المدرسة. كان هناك خمسة دروس تلقاها: 1 ، 5 ، 3 ، 2 ، 4
خمسة تقييمات → كمية غريبة
النمو: 1 ، 2 ، 3 ، 4 ، 5
خذ المركزية - 3
النتيجة المتوسطة - 3
في اليوم التالي ، أحضر الابن من المدرسة درجات جديدة: 4 ، 2 ، 3 ، 5
أربعة تصنيفات → كمية غريبة
نبني بالنمو: 2 ، 3 ، 4 ، 5
خذ القطع المركزية: 3 ، 4
نجد متوسطهم: 3.5
المتوسط - 3.5
الاستنتاج: أحسنت الابن :)
نرى أنه في الرجال يبلغ المتوسط والوسيط 175 سم و 85 كجم. وفي النساء : 162 سم و 62 كجم. هذا يخبرنا أنه لا توجد انبعاثات قوية. أو أنها متناظرة على جانبي الوسيط. وهو نادر جدا.
لكن كلا الجنسين لديهما انحرافات طفيفة عن المتوسط من المتوسط. لكنها غير ذات أهمية وأنها مرئية فقط على المئات. دعنا ننتقل!
Gistograma
هذا رسم بياني يرسم القيم من الحد الأدنى إلى الحد الأقصى في ترتيب النمو ، ويظهر عدد الحالات الفردية.
fig, axes = plt.subplots(2,2, figsize=(20,10)) plt.subplots_adjust(wspace=0, hspace=0) axes[0,0].hist(data_male['Height'], label='Male Height', bins=100, color='red') axes[0,1].hist(data_male['Weight'], label='Male Weight', bins=100, color='red', alpha=0.4) axes[1,0].hist(data_female['Height'], label='Female Height', bins=100, color='blue') axes[1,1].hist(data_female['Weight'], label='Female Weight', bins=100, color='blue', alpha=0.4) axes[0,0].legend(loc=2, fontsize=20) axes[0,1].legend(loc=2, fontsize=20) axes[1,0].legend(loc=2, fontsize=20) axes[1,1].legend(loc=2, fontsize=20) plt.savefig('plt_histogram.png') plt.show()

يتم توزيع البيانات على شكل جرس. تشبه الى حد بعيد التوزيع الطبيعي .
بالإضافة إلى الاختبارات الإحصائية للتوزيع الطبيعي ، هناك اختبار بصري. إذا كان التوزيع حسب النوع والمنطق طبيعيًا - فيمكننا افتراض بعض الافتراضات بأننا نتعامل معه.
يمكن للمرء القيام باختبار الحالة الطبيعية الإحصائية وتحديد قيمة p ، ولكن لا استطيع هذا هو خارج نطاق المقال.
تعلم العمل مع الأقلام
يمكن الباندا العد الكثير بالنسبة لنا. لكن عليك أن تحسب على الأقل بعض الإحصاءات بنفسك. الآن سوف أعرض كيفية حساب الانحراف المعياري .
دعونا نفعل ذلك على سبيل المثال من الرجال والسمة - النمو.
متوسط
الصيغة:
حيث
- م - متوسط القيمة
- N هو عدد الحالات
- ني - مثيل واحد
كود:
mean = data_male['Height'].mean() print('mean:\t{:.2f}'.format(mean)) >> mean: 175.33
متوسط الارتفاع - 175 سم
الانحراف التربيعي
حيث
- دي - انحراف واحد
- ني - مثيل واحد
- م - المتوسط
كود:
data_male['Height_d'] = (data_male['Height'] - mean) ** 2 data_male['Height_d'].head(10) >> 0 149.927893 1 0.385495 2 166.739089 3 47.193692 4 4.721246 5 20.288347 6 0.375539 7 2.964214 8 25.997623 9 200.149603 Name: Height_d, dtype: float64
تشتت
الصيغة:
حيث
- D هي قيمة التشتت
- دي - انحراف واحد
- N هو عدد الحالات
كود:
disp = data_male['Height_d'].mean() print('disp:\t{:.2f}'.format(disp)) >> disp: 52.89
تشتت - 53
الانحراف المعياري
الصيغة:
حيث
- الأمراض المنقولة جنسيا - قيمة الانحراف المعياري
- D هي قيمة التشتت
كود:
std = disp ** 0.5 print('std:\t{:.2f}'.format(std)) >> std: 7.27
الانحراف المعياري - 7
فواصل الثقة
سنكتشف الآن نطاقات النمو والوزن 68٪ و 95٪ و 99.7٪ من الرجال والنساء .
هذا ليس بالأمر الصعب - تحتاج إلى إضافة وطرح الانحراف المعياري عن المتوسط. يبدو مثل هذا:
- 68 ٪ - زائد أو ناقص الانحراف المعياري
- 95 ٪ - زائد أو ناقص اثنين من الانحرافات القياسية
- 99.7 ٪ - زائد أو ناقص ثلاثة الانحرافات القياسية
نكتب وظيفة مساعدة من شأنها أن تنظر في هذا:
def get_stats(series, title='noname'):
حسنًا ، قم بتطبيقه على البيانات:
رجال | نمو
get_stats(data_male['Height'], title='Male Height') >> = MALE HEIGHT = = Mean: 175 = Std: 7 = = = = = 68% is from 168 to 183 = 95% is from 161 to 190 = 99.7% is from 154 to 197
رجال | الوزن
get_stats(data_male['Height'], title='Male Height') >> = MALE WEIGHT = = Mean: 85 = Std: 9 = = = = = 68% is from 76 to 94 = 95% is from 67 to 103 = 99.7% is from 58 to 112
النساء | نمو
get_stats(data_male['Height'], title='Male Height') >> = FEMALE HEIGHT = = Mean: 162 = Std: 7 = = = = = 68% is from 155 to 169 = 95% is from 148 to 176 = 99.7% is from 141 to 182
النساء | الوزن
get_stats(data_male['Height'], title='Male Height') >> = FEMALE WEIGHT = = Mean: 62 = Std: 9 = = = = = 68% is from 53 to 70 = 95% is from 44 to 79 = 99.7% is from 36 to 87
ومن هنا الاستنتاجات:
- معظم الرجال: 154 سم - 197 سم و 58 كجم - 112 كجم.
- معظم النساء: 141 سم - 182 سم و 36 كجم - 87 كجم.
الآن يبقى فقط تطبيق التعلم الآلي على هذه المجموعة ومحاولة التنبؤ بالوزن حسب الطول.
أقرب الجيران
الخوارزمية "إلى أقرب الجيران" بسيطة. يوجد لمهام التصنيف - لتمييز قطة عن كلب - وللمهام الانحدار - لتخمين الوزن بالطول. هذا هو ما نحتاجه!
بالنسبة إلى الانحدار ، يستخدم الخوارزمية التالية:
- يتذكر جميع نقاط البيانات
- عندما تظهر نقطة جديدة ، فإنها تبحث عن K المجاورة لها (يتم تعيين الرقم K من قبل المستخدم)
- المتوسطات النتيجة
- يعطي إجابة
تحتاج أولاً إلى تقسيم مجموعة البيانات إلى أجزاء التدريب والاختبار واختبار الخوارزمية
التجريب على الرجال
X_train, X_test, y_train, y_test = train_test_split(data_male['Height'], data_male['Weight'])
مقسمة ، لقد حان الوقت للمحاولة.
لن نذهب بعيدا ونتوقف عند ثلاثة جيران. لكن السؤال هو: هل يمكن لهذا النموذج تخمين وزني؟
knr3.predict([[180]])[0, 0] >> 88.67596236265881
88kg قريب جدا. هذا الثاني ، وزني هو 89.8kg
الرسم البياني التنبؤ للرجال
الوقت لبناء الجزء المفضل من العلوم هو الرسومات.
array_male = []

نموذج وتخطيط الرسم البياني للمرأة
X_train, X_test, y_train, y_test = train_test_split(data_female['Height'], data_female['Weight']) knr3 = KNeighborsRegressor(n_neighbors=3) knr3.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1)) knr3.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1)) >> 0.8135681584074799
array_female = []

وبالطبع من المثير للاهتمام كيف تبدو هذه الرسوم البيانية معًا:
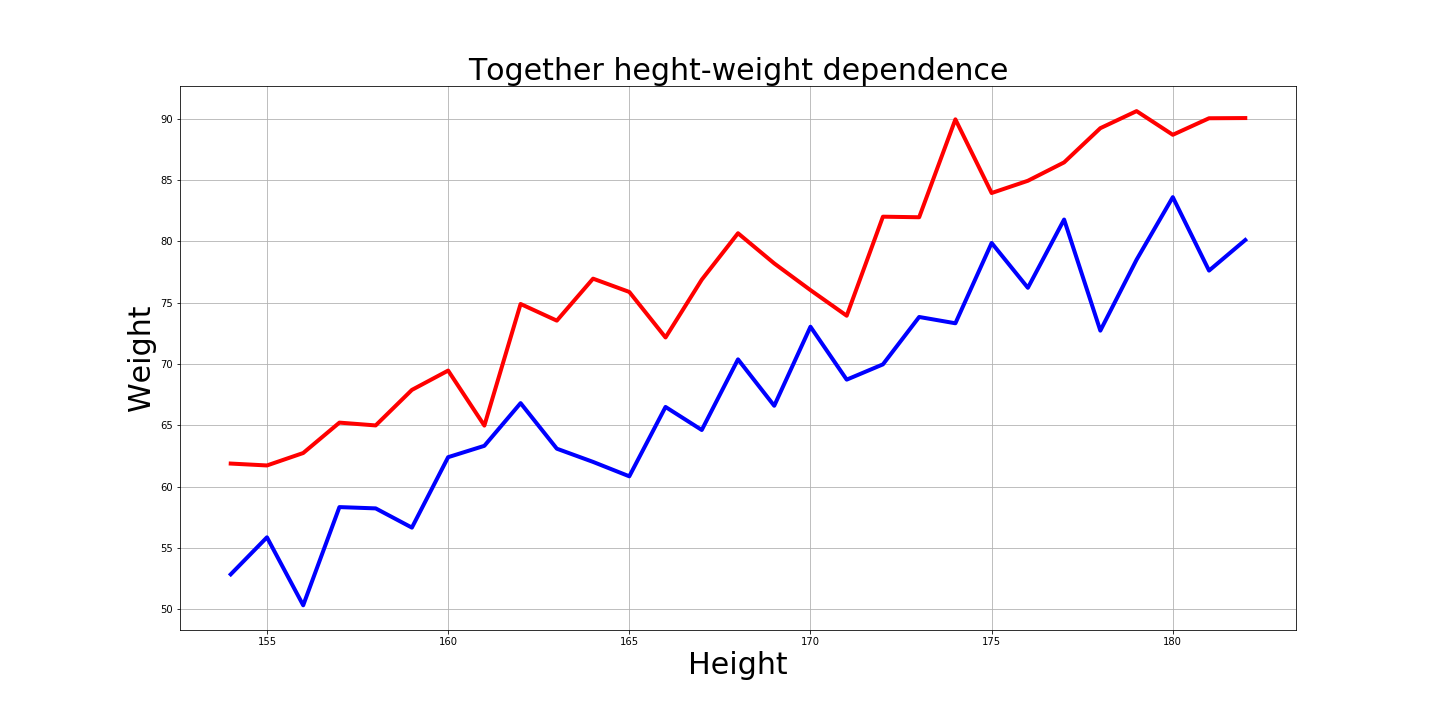
إجابات على الأسئلة
- ما هو نطاق الوزن والطول بالنسبة لمعظم الرجال والنساء؟
99.7٪ من الرجال: من 154 سم إلى 197 سم ومن 58 كجم إلى 112 كجم.
و 99.7٪ من النساء: من 141 سم إلى 182 سم ومن 36 كجم إلى 87 كجم.
- أي نوع من الرجل "المتوسط" والمرأة "المتوسطة" هم؟
الرجل المتوسط هو 175 سم و 85 كجم.
و المرأة المتوسطة هي 162 سم و 62 كجم.
- هل يتنبأ نموذج تعلم آلة KNN البسيط من هذه البيانات بالوزن حسب الطول؟
نعم ، توقع النموذج 88 كجم ، ولدي 89.8 كجم.
كل ما فعلته ، جمعت هنا
سلبيات المقال
- لا يوجد وصف لمجموعة البيانات. ربما كان العمر وعوامل أخرى في الناس مختلفة. لذلك ، لا يمكن للمرء أن يقبل ذلك على الإيمان ، ولكن من أجل التجربة - من فضلك.
- بطريقة جيدة - كان من الضروري إجراء اختبار لطبيعية التوزيع
خاتمة
مثل إذا كنت تصل إلى الفاصل 99.7 ٪