في أبنية الخدمات الكبيرة أو المجهرية ، الخدمة الأكثر أهمية ليست دائمًا الأكثر إنتاجية وأحيانًا ليست مخصصة للتحميل الكبير. نحن نتحدث عن الخلفية. إنه يعمل ببطء - فهو يهدر الوقت في معالجة البيانات وينتظر استجابة بينه وبين نظام إدارة قواعد البيانات (DBMS) ، ولا يتغير. حتى إذا كان التطبيق نفسه يحجم بسهولة ، فإن حجم عنق الزجاجة هذا لا يزيد على الإطلاق. كيفية حل هذه المشكلة وضمان الأداء العالي؟ كيف يمكن توفير استجابة للنظام عندما تكون مصادر المعلومات المهمة صامتة؟

إذا كانت البنية الخاصة بك متوافقة تمامًا مع بيان رد الفعل ، فإن مكونات مقياس التطبيق إلى أجل غير مسمى مع زيادة الحمل بشكل مستقل عن بعضها البعض ، وتحمل سقوط أي عقدة - أنت تعرف الإجابة. ولكن إذا لم يكن الأمر كذلك ،
فسيقوم Oleg Nizhnikov (
Odomontois ) بإخبار كيف تم حل مشكلة قابلية التوسع في Tinkoff عن طريق إنشاء ذاكرة التخزين المؤقت المؤلمة Fallback على Scala دون إعادة كتابة التطبيق.
المذكرة. تحتوي المقالة على الحد الأدنى من كود Scala والحد الأقصى للمبادئ والأفكار العامة.الخلفية غير مستقرة أو بطيئة
عند التفاعل مع الواجهة الخلفية ، يكون التطبيق المتوسط سريعًا. لكن الخلفية تعمل الجزء الأكبر من العمل وتطحن معظم البيانات داخليًا - يستغرق وقتًا أطول. يضيع الوقت الإضافي في انتظار استجابة و DBMS. حتى إذا كان التطبيق نفسه يحجم بسهولة ، فإن حجم عنق الزجاجة هذا لا يزيد على الإطلاق. كيفية تخفيف العبء على الواجهة الخلفية وحل المشكلة؟
ذاكرة التخزين المؤقت المضمنة
الفكرة الأولى هي أخذ البيانات للقراءة ، والطلبات التي تستقبل البيانات ، وتكوين ذاكرة التخزين المؤقت على مستوى كل عقدة في الذاكرة.
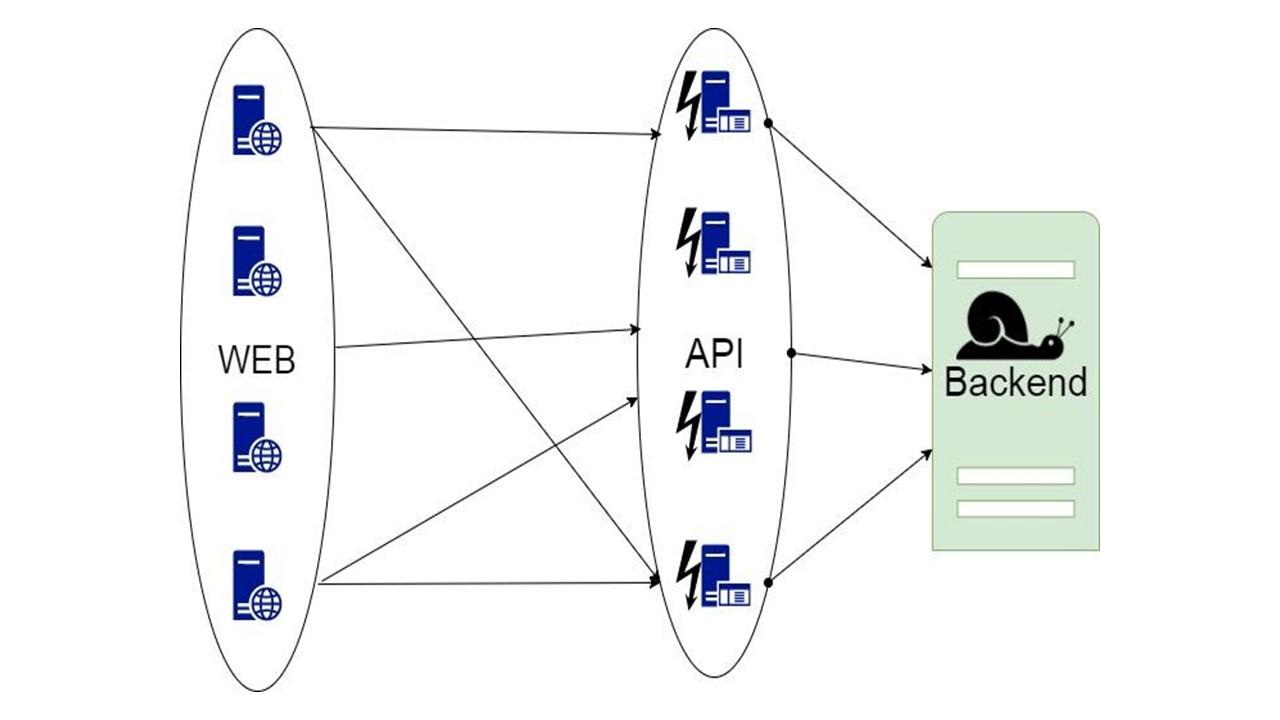
تعيش ذاكرة التخزين المؤقت حتى تتم إعادة تشغيل العقدة وتخزين آخر جزء فقط من البيانات. في حالة تعطل التطبيق والمستخدمين الجدد الذين لم يكونوا في آخر ساعة أو يوم أو أسبوع ، فلن يتمكن التطبيق من فعل أي شيء حيال ذلك.
الوكيل
الخيار الثاني هو وكيل ، والذي يأخذ جزء من الطلبات أو يعدل التطبيق.
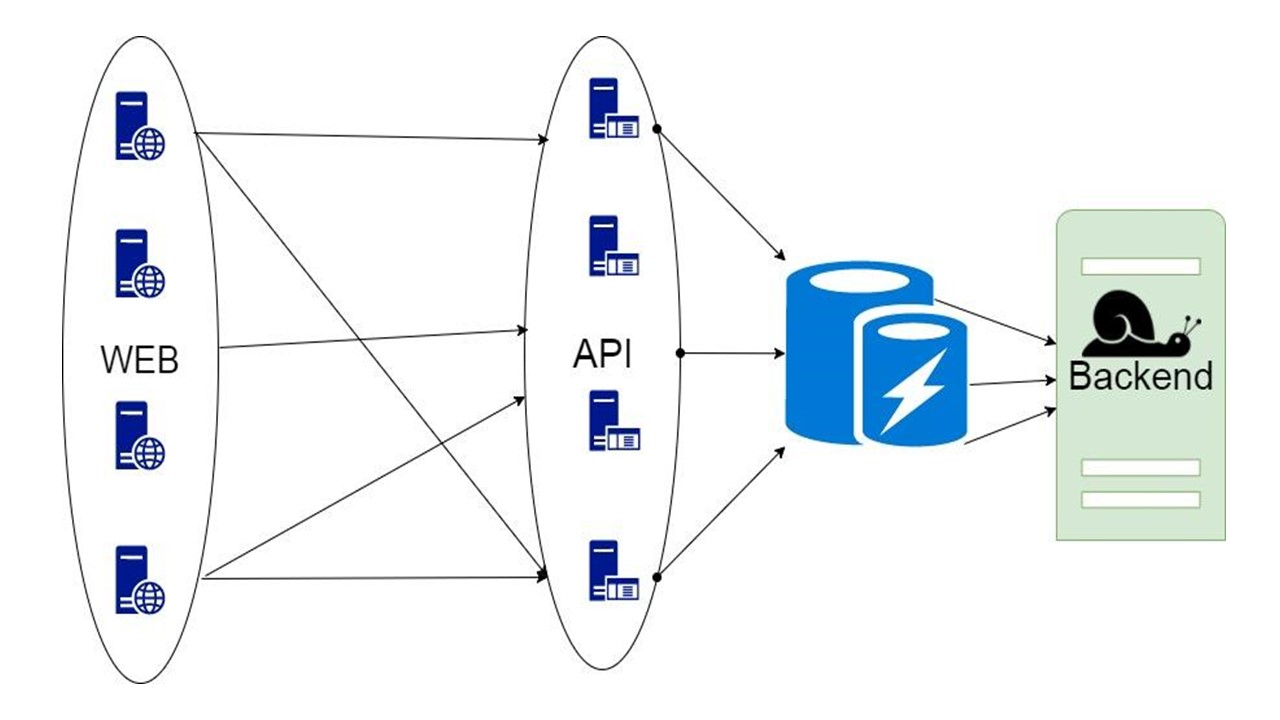
ولكن في الوكيل ، لا يمكنك القيام بكل العمل للتطبيق نفسه.
التخزين المؤقت قاعدة البيانات
الخيار الثالث صعب عندما يمكن وضع جزء من البيانات التي ترجعها الواجهة الخلفية في التخزين لفترة طويلة. عندما تكون هناك حاجة لذلك ، نعرض العميل ، حتى لو لم تعد ملائمة. هذا أفضل من لا شيء.
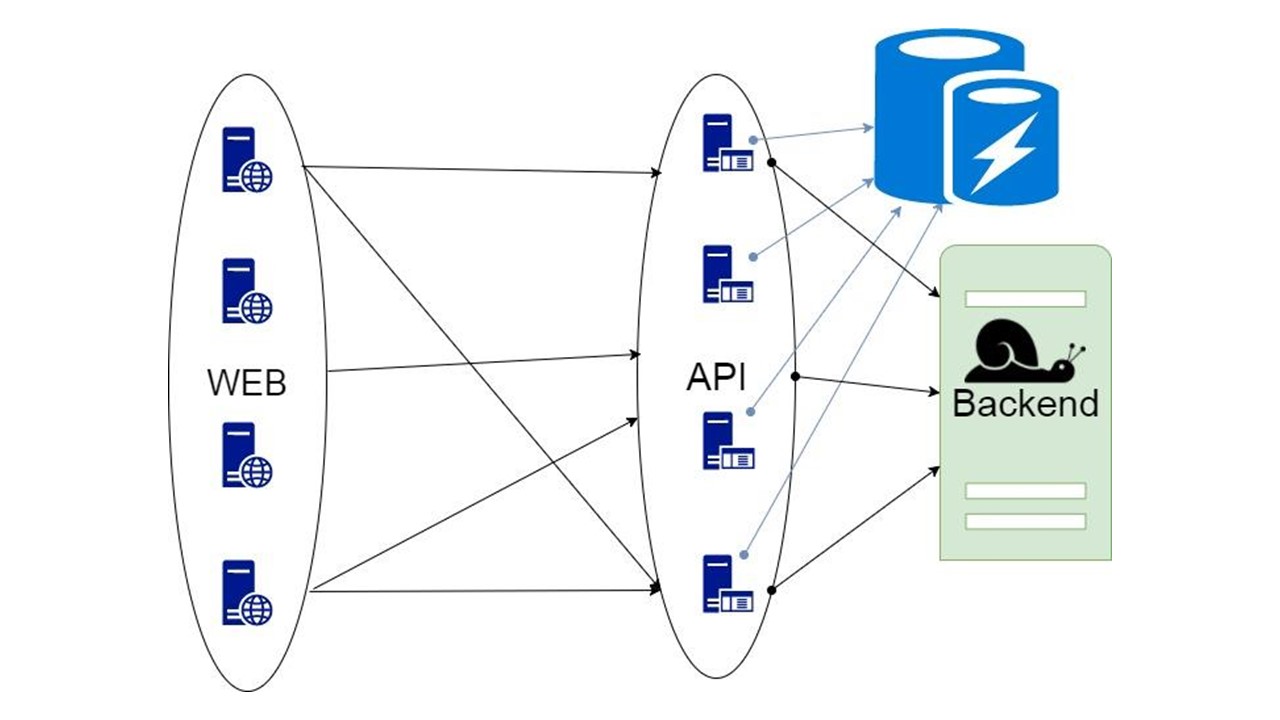
سيتم مناقشة هذا القرار.
ذاكرة التخزين المؤقت الاحتياطية
هذه هي مكتبتنا. مضمن في التطبيق ويتواصل مع الواجهة الخلفية. مع الحد الأدنى من التنقيح ، فإنه يحلل بنية البيانات ، ويولد تنسيقات التسلسل ، وبفضل خوارزمية Circuit Breaker ، يزيد من تحمل الأخطاء. يمكن تنفيذ التسلسل الفعال بأي لغة حيث يمكن تحليل الأنواع مسبقًا إذا تم تعريفها بدقة كافية.
المكونات
مكتبتنا تبدو مثل هذا.

الجزء الأيسر مخصص للتفاعل مع هذا المستودع ، والذي يتضمن عنصرين مهمين:
- المكون المسؤول عن عملية التهيئة - الإجراءات الأولية مع DBMS قبل استخدام Fallback Cache ؛
- وحدة توليد التسلسل التلقائي.
الجانب الأيمن هو الوظيفة العامة التي تتعلق بالاحتياطي.
كيف يعمل كل شيء؟ توجد استعلامات في منتصف التطبيق وأنواع وسيطة لتخزين الحالة. يعبر هذا النموذج عن البيانات التي تلقيناها من الواجهة الخلفية لطلب واحد أو أكثر. نرسل المعلمات إلى طريقتنا ، ونحصل على البيانات من هناك. تحتاج هذه البيانات إلى إجراء تسلسل بطريقة أو بأخرى حتى يتم وضعها في التخزين ، لذلك نلفها في الشفرة. وحدة منفصلة هي المسؤولة عن هذا. استخدمنا نمط قواطع دوائر.
متطلبات التخزين
مدة الصلاحية الطويلة - 30-500 يوم . قد تستغرق بعض الإجراءات وقتًا طويلاً ، وكل هذا الوقت مطلوب لتخزين البيانات. لذلك ، نريد تخزينًا يمكنه تخزين البيانات لفترة طويلة. في الذاكرة ليست مناسبة لهذا.
حجم البيانات الكبير - 100 جيجابايت - 20 تيرابايت . نريد تخزين عشرات تيرابايت من البيانات في ذاكرة التخزين المؤقت ، وأكثر من ذلك بسبب النمو. الحفاظ على كل هذا في الذاكرة غير فعال - معظم البيانات غير مطلوبة باستمرار. إنهم يكذبون لفترة طويلة ، في انتظار مستخدمهم ، الذي سيأتي ويسأل. في الذاكرة لا تندرج تحت هذه المتطلبات.
توافر البيانات عالية . يمكن أن يحدث أي شيء للخدمة ، لكننا نريد أن يبقى نظام إدارة قواعد البيانات متاحًا طوال الوقت.
تكاليف تخزين منخفضة . نرسل بيانات إضافية إلى ذاكرة التخزين المؤقت. نتيجة لذلك ، يحدث الحمل. عند تنفيذ الحل الخاص بنا ، نريد تقليله.
دعم الاستعلامات على فترات . كان ينبغي أن تكون قاعدة بياناتنا قادرة على سحب جزء من البيانات ليس فقط بكامله ، ولكن على فترات: قائمة الإجراءات ، سجل المستخدم لفترة معينة. لذلك ، قيمة المفتاح النقي غير مناسبة.
الافتراضات
متطلبات تضييق قائمة المرشحين. نحن نفترض أننا قمنا بتنفيذ الباقي ، وقمنا بالافتراضات التالية ، ونعرف سبب احتياجنا بالضبط إلى ذاكرة التخزين المؤقت الاحتياطية.
تكامل البيانات بين طلبين GET مختلفين غير مطلوب . لذلك ، إذا عرضوا حالتين مختلفتين لا تتفقان مع بعضهما البعض ، فسوف نتحمل هذا.
أهمية البيانات وإبطالها غير مطلوبة . في وقت الطلب ، من المفترض أن لدينا أحدث إصدار نعرضه.
نرسل ونستقبل البيانات من الواجهة الخلفية.
هيكل هذه البيانات معروف مقدما .
اختيار التخزين
كبدائل ، درسنا ثلاثة خيارات رئيسية.
الأول هو
كاساندرا . المزايا: توفر عالي ، قابلية للتوسعة سهلة وآلية تسلسل مدمجة مع مجموعة UDT.
UDT أو
أنواع المعرفة من قبل المستخدم ، تعني نوعًا ما. إنها تتيح لك تكديس الأنواع المهيكلة بكفاءة. حقول النوع معروفة مسبقا. يتم وضع علامة على حقول التسلسل هذه بعلامات منفصلة كما في مخازن بروتوكول. بعد قراءة هذا الهيكل ، من الممكن أن نفهم ما الحقول الموجودة على أساس العلامات. بيانات وصفية كافية لمعرفة اسمهم ونوعهم.
ميزة إضافية أخرى من Cassandra هي أنه إلى جانب مفتاح التقسيم يحتوي على
مفتاح تجميع إضافي. هذا هو مفتاح خاص ، بسببه يتم ترتيب البيانات على عقدة واحدة. يتيح لك ذلك تنفيذ خيار مثل استعلامات الفاصل.
كانت كاساندرا موجودة منذ فترة طويلة نسبيًا ، وهناك
العديد من حلول المراقبة لها ،
ونقطة واحدة هي JVM . ليس هذا هو الخيار الأكثر إنتاجية للأنظمة الأساسية التي يمكنك من خلالها كتابة DBMS. JVM لديه مشاكل مع جمع القمامة والحمل.
الخيار الثاني هو
CouchBase . المزايا: إمكانية الوصول إلى البيانات ، قابلية التوسع والخطط.
مع CouchBase ، تحتاج إلى التفكير أقل في التسلسل. هذا هو زائد وناقص - نحن لسنا بحاجة للسيطرة على نظام البيانات. هناك فهارس عمومية تسمح لك بتشغيل استعلامات الفاصل الزمني على مستوى المجموعة.
CouchBase هو مختلط حيث
تتم إضافة
Memcache إلى DBMS المعتادة
- ذاكرة التخزين المؤقت السريعة . يتيح لك تخزين جميع البيانات الموجودة على العقدة تلقائيًا - الأكثر سخونةً ، مع توفر كبير جدًا. بفضل ذاكرة التخزين المؤقت الخاصة به ، يمكن أن يكون CouchBase سريعًا إذا تم طلب نفس البيانات كثيرًا.
يمكن أن يكون
Schemaless و
JSON ناقصًا أيضًا. يمكن تخزين البيانات لفترة طويلة بحيث يكون للتطبيق وقت للتغيير. في هذه الحالة ، ستتغير أيضًا بنية البيانات التي ستقوم CouchBase بقراءتها وقراءتها. قد لا يكون الإصدار السابق متوافقًا. سوف تتعلم فقط عن هذا عند القراءة ، وليس عند تطوير البيانات ، عندما تكون في مكان ما في الإنتاج. علينا أن نفكر في الهجرة المناسبة ، وهذا هو بالضبط ما لا نريد القيام به.
الخيار الثالث هو
Tarantool . وتشتهر سرعته الفائقة. أنه يحتوي على محرك LUA الرائع الذي يسمح لك بكتابة مجموعة من المنطق الذي سيتم تنفيذه مباشرة على الخادم على LuaJit.
من ناحية أخرى ، هذه قيمة مفتاح معدلة. يتم تخزين البيانات في tuples. نحن بحاجة إلى التفكير لأنفسنا في التسلسل الصحيح ، وهذه ليست دائما مهمة واضحة. لديه Tarantool أيضا نهجا محددا
للتوسع . ما هو الخطأ معه ، وسوف نناقش أكثر.
مشاركة / النسخ المتماثل
ربما سيحتاج
تطبيقنا إلى
المشاركة / النسخ المتماثل . ثلاثة مستودعات تنفذها بشكل مختلف.
يقترح كاساندرا بنية تسمى عادة "حلقة".
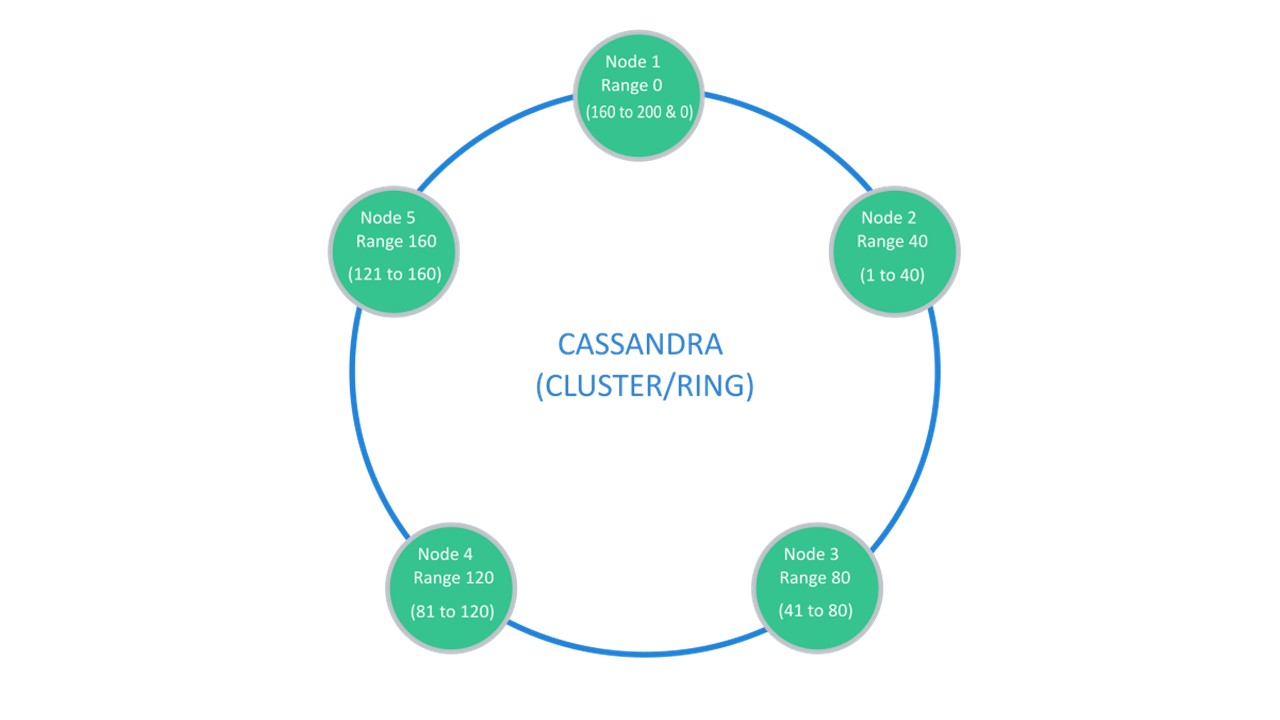
العديد من العقد متاحة. يخزن كل منهم بياناته وبياناته من أقرب عقد كنسخ متماثلة. إذا تسرب أحدهم ، يمكن للعقد المجاور لها تقديم جزء من بياناته حتى يرتفع التسرب.
Sharding \ Replication مسؤولة عن نفس البنية. لتفريغ إلى 10 قطع وعامل النسخ المتماثل 3 ، 10 العقد كافية. سيقوم كل من العقد بتخزين نسخ متماثلة 2 من تلك المجاورة.
في CouchBase ، يتم بناء بنية التفاعل بين العقد بشكل مشابه:
- هناك بيانات تم تمييزها على أنها نشطة ، وتكون العقدة نفسها مسؤولة عنها ؛
- هناك نسخ متماثلة من العقد المجاورة التي يخزنها CouchBase.
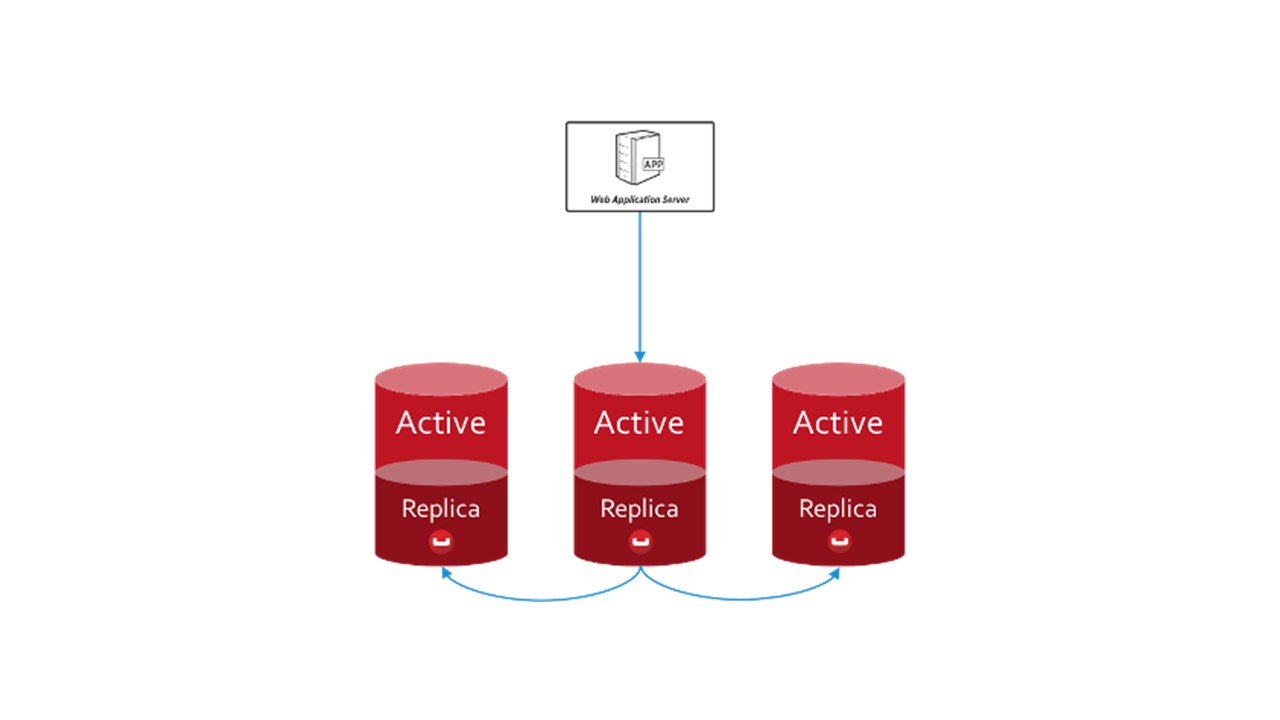
إذا سقطت عقدة واحدة ، فإن المجاورة لها ، المشتركة ، تتحمل مسؤولية الحفاظ على هذا الجزء من المفاتيح.
في Tarantool ، الهندسة المعمارية تشبه MongoDB. ولكن مع فارق بسيط: هناك مجموعات المشاركة التي يتم نسخها مع بعضها البعض.
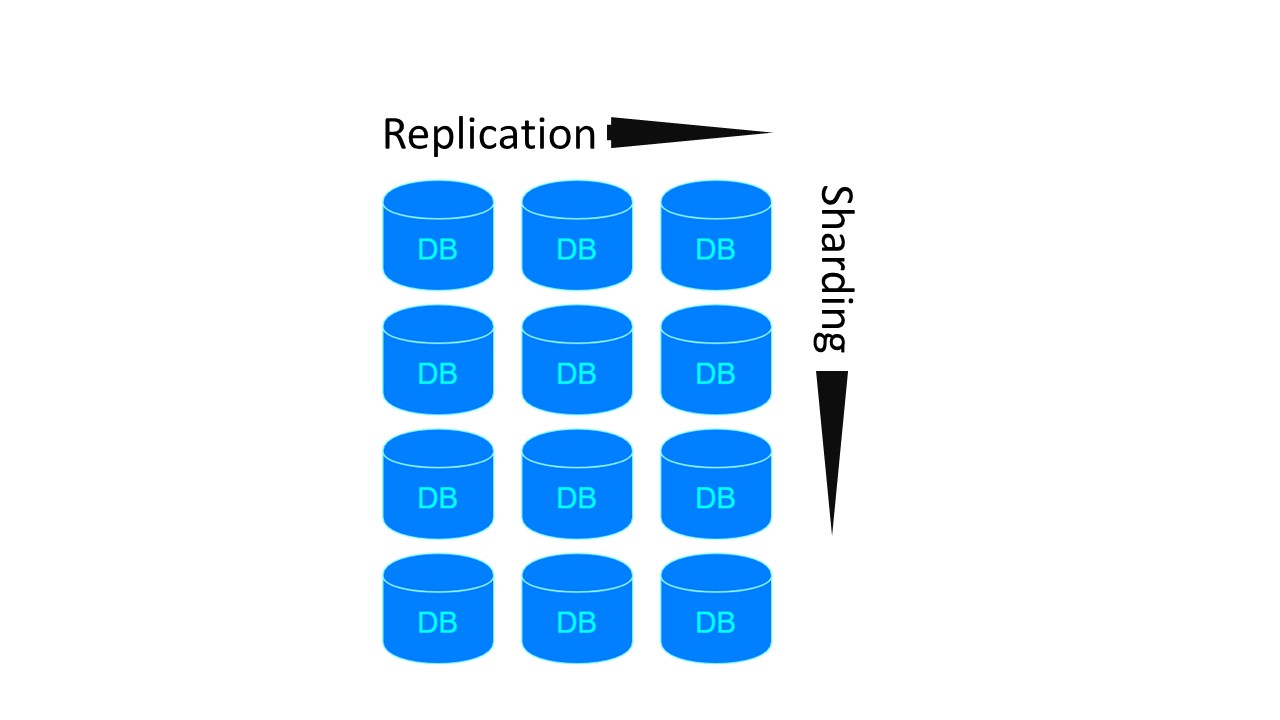
بالنسبة للمعماريتين السابقتين ، إذا أردنا إنشاء 4 قطع ومعامل النسخ المتماثل 3 ، يلزم وجود 4 عقد. ل Tarantool - 12! ولكن يتم تعويض العيب بالسرعة التي تضمنها Tarantool.
كاساندرا
لم تظهر الوحدات الاختيارية للمشاركة في Tarantool إلا مؤخرًا. لذلك ، اخترنا كاساندرا DBMS كمرشح رئيسي. أذكر أننا تحدثنا عن تسلسلها المحدد.
التسلسل التلقائي
يفترض بروتوكول SQL أنك حر إلى حد ما في تحديد مخطط بيانات.
يمكنك استخدام هذا كميزة. على سبيل المثال ، قم بإجراء تسلسل للبيانات بحيث لا يتم تخزين أسماء الحقول الطويلة لهياكلنا الورقية في كل مرة في قيمنا. في هذه الحالة ، سيكون لدينا بعض البيانات الوصفية التي تصف جهاز البيانات. تحدد UDTs نفسها أيضًا الحقول التي تتوافق مع العلامات والعلامات.
لذلك ، تتم عملية التسلسل التي يتم إنشاؤها تلقائيًا بنفس الطريقة تقريبًا. إذا كان لدينا واحد من الأنواع الأساسية التي يمكن أن تتطابق مع النوع من قاعدة البيانات واحد إلى واحد ، فإننا نفعل ذلك. مجموعة من الأنواع Int، Long، String، Double هي أيضًا في كاساندرا.
إذا تمت مصادفة حقل اختياري في بعض الهياكل ، فلن نقوم بأي شيء إضافي. نشير له النوع الذي يجب أن يتحول إلى هذا الحقل. سوف هيكل تخزين فارغة. إذا وجدنا لاغية في الهيكل على مستوى إلغاء التسلسل ، نفترض أن هذا هو عدم وجود قيمة.
يتم تحويل جميع أنواع المجموعات من المجموعة في Scala إلى قائمة الكتابة. هذه مجموعات مرتبة تحتوي على عنصر مطابقة فهرس.
تضمن مجموعات المجموعات غير المرتبة وجود عنصر واحد بالضبط مع كل قيمة. كاساندرا لديها أيضا مجموعة خاصة نوع لهم.
على الأرجح ، سيكون لدينا الكثير من التعيين () ، خاصة مع مفاتيح السلسلة. كاساندرا لديه نوع خريطة خاص بالنسبة لهم. يتم كتابتها أيضًا ولها نوعان من المعلمات. حتى نتمكن من إنشاء نوع مناسب لأي مفتاح
هناك أنواع البيانات التي نعرّف أنفسنا في تطبيقنا. في العديد من اللغات يطلق عليهم
أنواع البيانات الجبرية . يتم تعريفهم عن طريق تعريف منتج معين من الأنواع ، أي ، هيكل. نخصص هذه البنية للنوع المحدد من قبل المستخدم. سيتوافق كل مجال من مجالات الهيكل مع حقل واحد في UDT.
النوع الثاني هو
مجموع أنواع الجبر . في هذه الحالة ، يتوافق النوع مع العديد من الأنواع الفرعية أو الأنواع الفرعية المعروفة سابقًا. أيضا ، بطريقة معينة ، نخصص له هيكل.
نوع بيانات الملخص يترجم إلى UDT
لدينا بنية ، ونعرضها واحدًا تلو الآخر - لكل حقل نقوم بتعريف الحقل في UDT الذي تم إنشاؤه في كاساندرا:
case class Account ( id: Long, tags: List[String], user: User, finData: Option[FinData] ) create type account ( id bigint, tags: frozen<list<text>>, user frozen<user>, fin_data frozen<fin_data> )
تتحول الأنواع البدائية إلى أنواع بدائية. رابط لنوع محدد مسبقًا قبل أن يتم تجميده. هذا غلاف خاص في كاساندرا ، مما يعني أنه لا يمكنك القراءة من هذا الحقل قطعة قطعة. المجمع "المجمدة" في هذه الحالة. يمكننا فقط قراءة أو حفظ المستخدم ، أو القائمة ، كما في حالة العلامات.
إذا التقينا حقل اختياري ، فإننا نتجاهل هذه الخاصية. نحن نأخذ فقط نوع البيانات المطابق لنوع الحقل الذي سيكون. إذا التقينا بغير هنا - عدم وجود قيمة - نكتب لاغية في الحقل المقابل. عند القراءة ، سنتخذ أيضًا المراسلات غير الفارغة.
إذا التقينا بنوع يحتوي على العديد من البدائل المعروفة مسبقًا ، فإننا نحدد أيضًا نوع بيانات جديد في كاساندرا. لكل بديل ، حقل في نوع البيانات لدينا في UDT.
نتيجة لذلك ، في هذا الهيكل ، لن يكون هناك سوى حقل واحد فقط في أي وقت. إذا قابلت نوعًا ما من المستخدمين ، واتضح أن ذلك كان بمثابة نسخة من المشرف في وقت التشغيل ، فسيحتوي حقل المشرف على بعض القيمة ، وسيكون الباقي فارغًا. للمشرف - المشرف ، والباقي - لاغية.
يسمح لك هذا بترميز البنية على النحو التالي: لدينا 4 حقول اختيارية ، ونحن نضمن أنه سيتم كتابة واحد منهم فقط. يستخدم كاساندرا علامة واحدة فقط لتحديد وجود حقل معين في الهيكل. بفضل هذا ، نحصل على بنية تخزين دون حمل.
في الواقع ، لحفظ نوع المستخدم ، إذا كان وسيطًا ، فسيتطلب الأمر نفس عدد البايتات المطلوبة لتخزين الوسيط. بالإضافة إلى بايت واحد لإظهار أي بديل معين موجود هنا.
التهيئة
التهيئة هي إجراء أولي يجب إكماله قبل أن نتمكن من استخدام احتياطينا.
كيف تعمل هذه العملية؟
- على كل عقدة نقوم بإنشاء تعريفات للجداول والأنواع ونصوص الاستعلام بناءً على الأنواع المعروضة.
- قراءة المخطط الحالي من DBMS. في Cassandra ، من السهل القيام بذلك بمجرد الاتصال به. عند الاتصال ، في جميع برامج التشغيل تقريبًا ، يقوم كائن "الجلسة" نفسه بضخ بيانات تعريف مساحة المفتاح التي يتصل بها. ثم يمكنك أن ترى ما لديهم.
- نحن نتصفح البيانات الوصفية ، ونقارن ونحقق من أن كل شيء نرغب في إنشائه مسموح به وأن الترحيل التدريجي ممكن.
- إذا كان كل شيء طبيعيًا وكانت التهيئة ممكنة ، فنحن نقوم بالترحيل.
- نحن نستعد الطلبات.
sealed trait User case class Anonymous extends User case class Registered extends User case class Moderator extends User case class Admin extends User create type user ( anonymous frozen<anonymous>, registered frozen<registered>, moderator frozen<moderator>, admin frozen<admin> )
يحدث مثل هذا. لدينا
أنواع وجداول واستعلامات . تعتمد الأنواع على أنواع أخرى ، تلك على الأنواع الأخرى. الجداول تعتمد على هذه الأنواع. تعتمد الاستعلامات بالفعل على الجداول التي يقرؤون البيانات منها. ستقوم التهيئة بالتحقق من كل هذه التبعيات وإنشاء كل ما يمكن أن تنشئه في قواعد بيانات إدارة قواعد البيانات وفقًا لقواعد معينة.
اكتب الترحيل
كيفية تحديد أن نوع يمكن ترحيلها تدريجيا؟
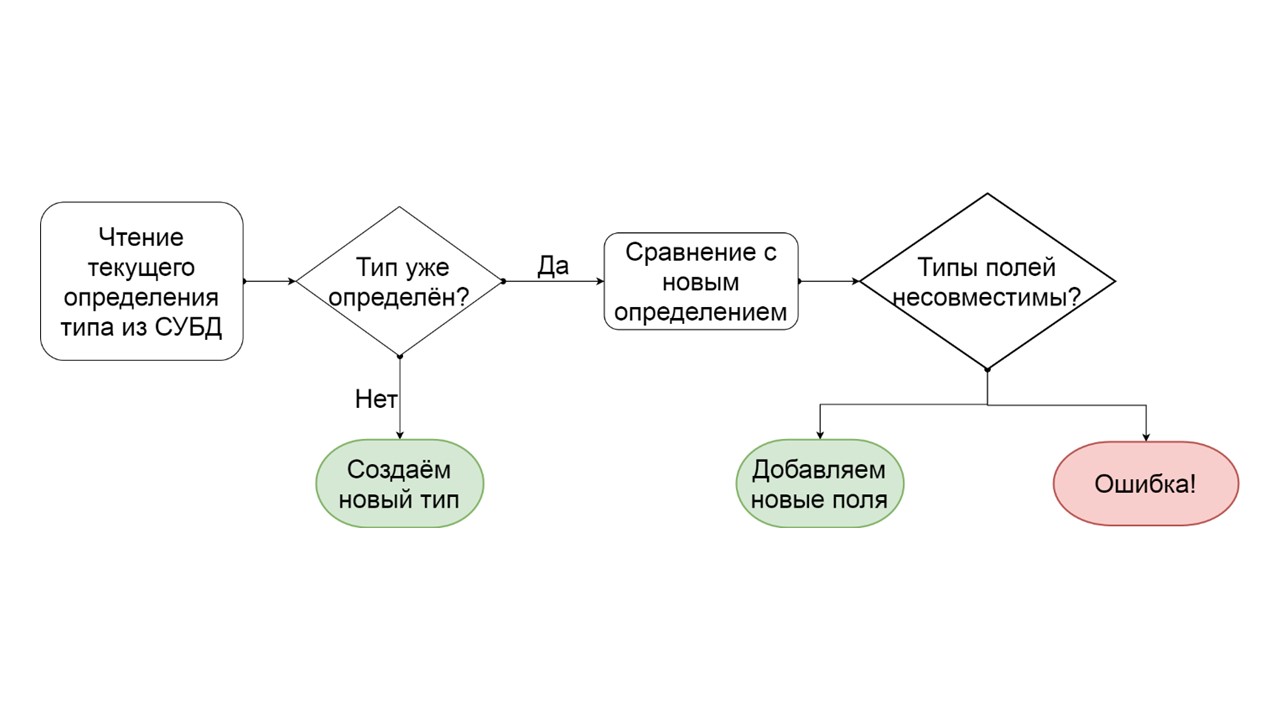
- نقرأ كيف يتم تعريف هذا النوع في DBMS.
- إذا لم يكن هناك مثل هذا النوع ، أي أننا توصلنا إلى نوع جديد - سنقوم بإنشائه.
- إذا كان هذا النوع موجودًا بالفعل ، فنحن نحاول مقارنة التعريف الحالي بالمجال بالتعريف الذي نريد إعطاءه لهذا النوع.
- إذا اتضح أننا نريد إضافة بعض الحقول التي لم تعد موجودة ، فنحن نفعل ذلك. إنشاء قائمة من عمليات تغيير نوع ALTER ، وبدء تشغيلها.
- إذا اتضح أن لدينا نوعًا من الحقول كان من نوع مختلف - فنحن ننتج خطأً. على سبيل المثال ، كانت هناك قائمة - أصبحت خريطة ، أو كان هناك رابط لنوع واحد يحدده المستخدم ، ونحن نحاول جعله مختلفًا.
يمكن للمطور رؤية هذا الخطأ حتى قبل أن يبدأ الوظيفة في الإنتاج. أفترض أن نظام البيانات نفسه بالضبط في بيئة التطوير الخاصة به. يرى أنه قام بطريقة ما بإنشاء مخطط بيانات غير قابل للترحيل ، ولتجنب هذه الأخطاء ، يمكنه تجاوز التسلسل الذي تم إنشاؤه تلقائيًا أو إضافة خيارات أو إعادة تسمية الحقول أو جميع الأنواع والجداول ككل.
التهيئة: أنواع
تخيل أن هناك عدة أنواع من التعاريف:
case class Product (id: Long, name: ctring, price: BigDecimal) case class UserOffers (valiDate: LocalDate, offers: Seq[Products]) case class UserProducts (user User, products: Map[Date, Product]) case class UserInfo: UserOffers, products: UserProducts)
فئة الحالة - فئة تحتوي على مجموعة من الحقول. هذا هو التماثلية للهيكل في الصدأ.
سنقوم بإنشاء تعريفات البيانات هذه تقريبًا لكل نوع من الأنواع الأربعة - ما الذي نريد أن نحدده في النهاية:
CREATE TYPE product (id bigint, name text, price decimal); CREATE TYPE user_offers (valid_date date, offers frozen<list<frozen<offer>>>); CREATE TYPE user_products (user frozen<user>, products frozen<map<date, frozen<product>>); CREATE TYPE user_jnfo (offers: frozen<user_offers>, products: frozen<user_products>);
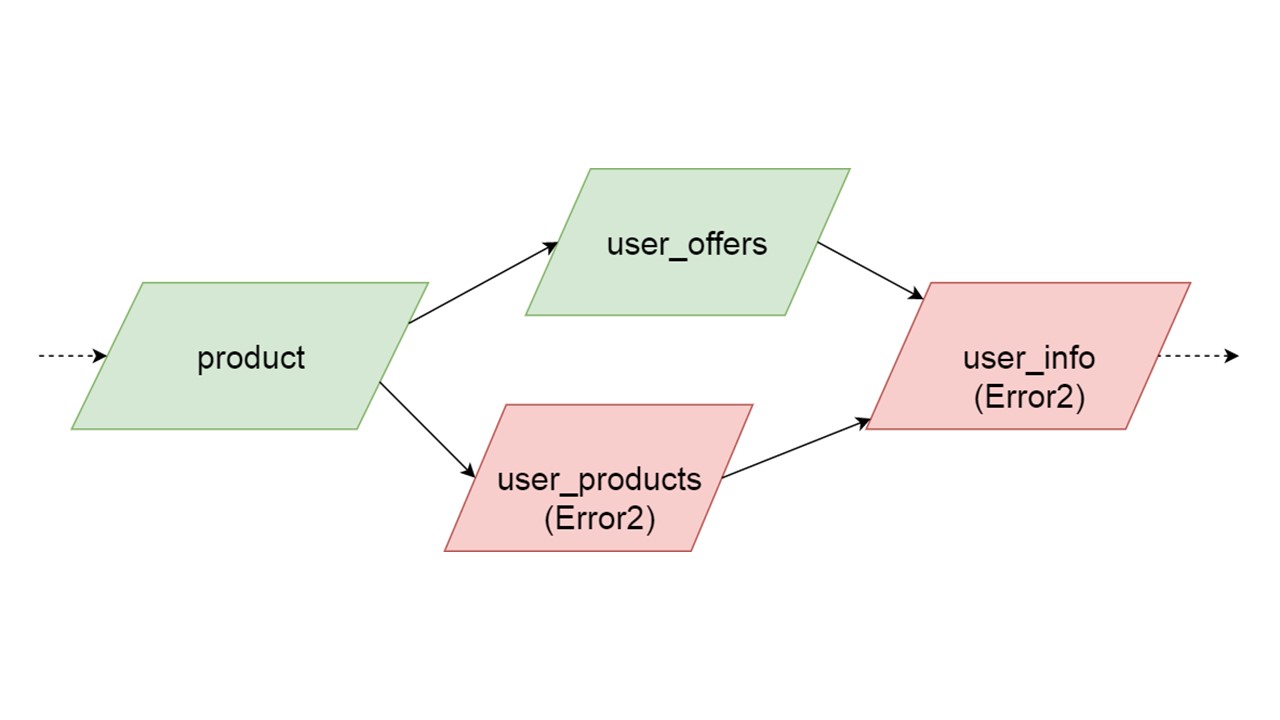
يعتمد نوع المستخدمون على نوع العرض ، ويعتمد المستخدمون على نوع المنتج ، user_info على النوعين الثاني والثالث.

لدينا مثل هذه التبعية بين الأنواع ، ونريد تهيئتها بشكل صحيح. يوضح الرسم التوضيحي أننا سنقوم بتهيئة user_offers و user_products بشكل متوازٍ. هذا لا يعني أننا سنطلق عمليتين متوازيتين. لا ، نبدأ جميع العبارات ، كل التحليلات بالتتابع ، حتى لا ننشئ بطريق الخطأ نفس النوع في خيطين متوازيين.
ولكن هناك بعض التوازي على مستوى تصحيح الخطأ. إذا حدث خطأ في الكتابة ، فكل شيء يعتمد عليه سيسحب الخطأ الأصلي.
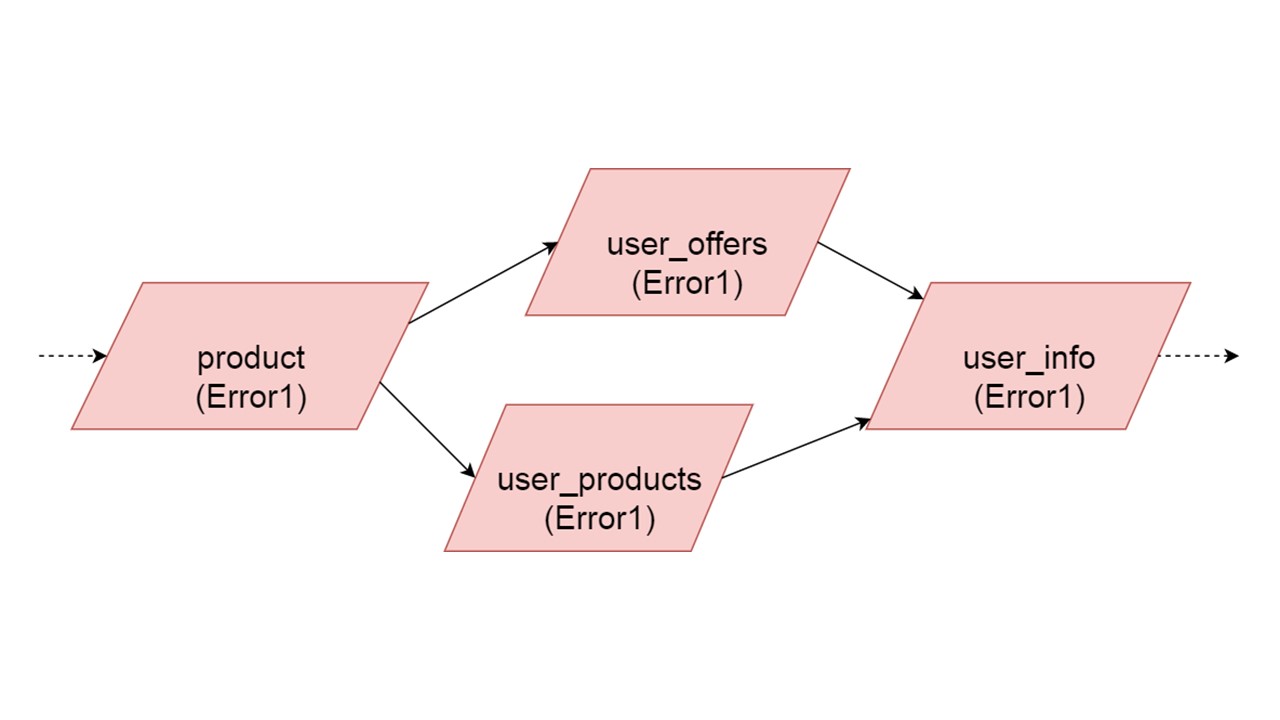
إذا تم إنشاء خطأ بواسطة أي من الفروع المتوازية ، فسيتم إنشاء كل شيء يعتمد على البيانات التي يتم ترحيلها بشكل طبيعي دون خطأ. إذا كان هناك تعريفات أخرى للجداول ، والبيانات المعدة منها ، فيمكننا تهيئة هذا الجزء من ذاكرة التخزين المؤقت الاحتياطية بأمان. سيتم فقد الاتصال فقط مع جزء من الواجهة الخلفية أو مع بعض الوظائف. تتم تهيئة الباقي.
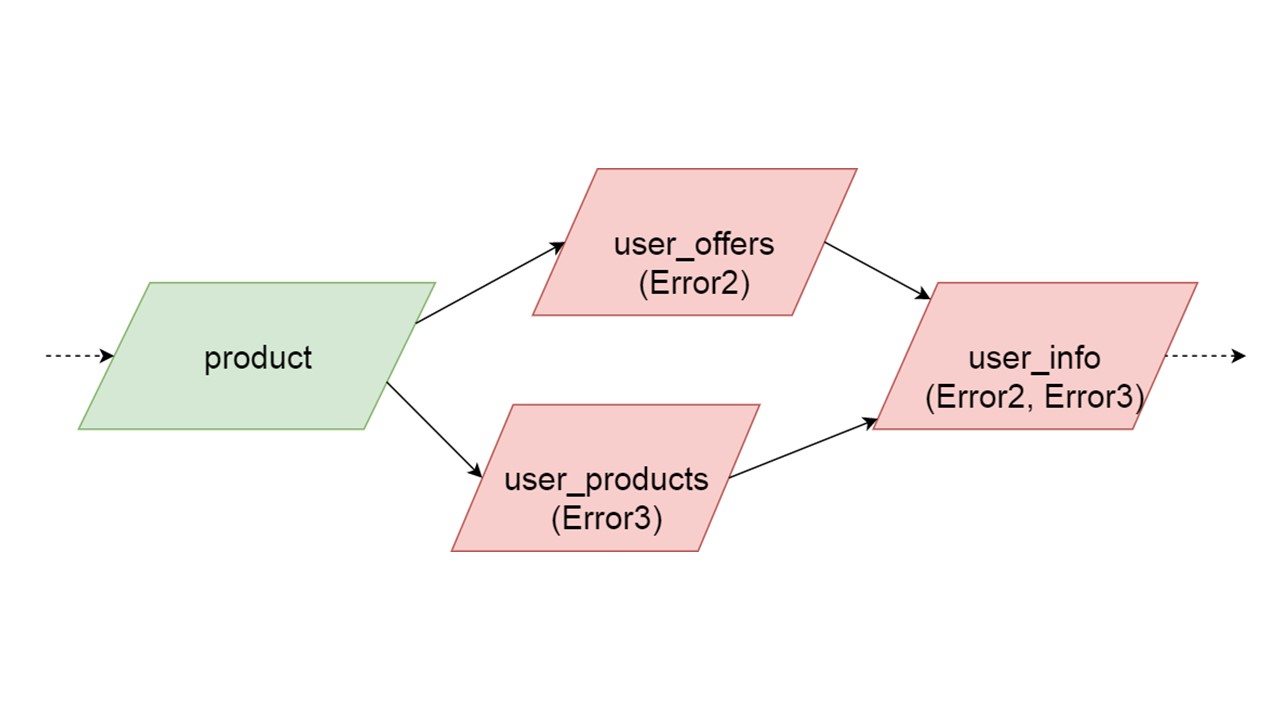
قد يحدث أن نوعين التي تتم تهيئة في وقت واحد إنشاء أخطاء مختلفة. في هذه الحالة ، ستؤدي الوظيفة التي تعتمد على كلا النوعين إلى نوع تلخيص من الخطأ. سيحصل المطور ، الذي يقوم بتهيئة وضع الرجوع للخلف في بيئة التطوير ، على قائمة كاملة بالبيانات التي بها أخطاء. بطبيعة الحال ، يمكن إصلاحه هنا والحصول على الخطأ أكثر. ولكن لن يكون هناك فرع واحد مستقل تمامًا يغلق الأخطاء التي يمكن أن نحصل عليها ، بغض النظر عن هذا الفرع.
التهيئة: الجداول
بعد ذلك نقوم بإنشاء الجداول.
def getOffer (user: User, number: Long): Future[OfferData] create table get_offer( key frozen<tuple<frozen<user>, bigint>>PRIMARY KEY, value frozen<friend_data> )
يمكن لمثل هذا الطلب مباشرة تشغيل طلب REST أو SOAP ، أو إنشاء عمليات إضافية داخل ، أو حتى تشغيل عدة طلبات. كل هذا يتوقف على الكود الخاص بك - كيف نظمت الكود سيكون كذلك. لا يقوم Backback تمامًا بتحليل ما يحدث داخل الطريقة التي تعلق بها مثل هذا كعب الروتين.
يجب أن تكون الطريقة غير متزامنة ، لأن Fallback هو نفسه.
في سكالا ، يتم تمييز هذا بنوع خاص من المستقبل. هذا يعني أن النتيجة ستعود يومًا ما. عندما تكون بالضبط - إنه غير معروف: ربما على الفور ، أو ربما لا.
للطريقة ، قم بإنشاء جدول. المفتاح في الجدول هو مجموعة من جميع الأنواع التي تتوافق مع معلمات هذه الطريقة. القيمة غير الأساسية هي النتيجة ، والتي يتم إرجاعها بشكل غير متزامن. لكل جدول من هذه الجداول ، نقوم بإعداد استبيانين حدوديين مقدمًا: إدراج البيانات وقراءة البيانات.
insert into get_offer(key, value) values (?key, ?value); select value from get_offer where key = ?key;
كل شيء جاهز للتفاعل مع DBMS. يبقى لمعرفة كيف سنقرأ البيانات من Fallback.
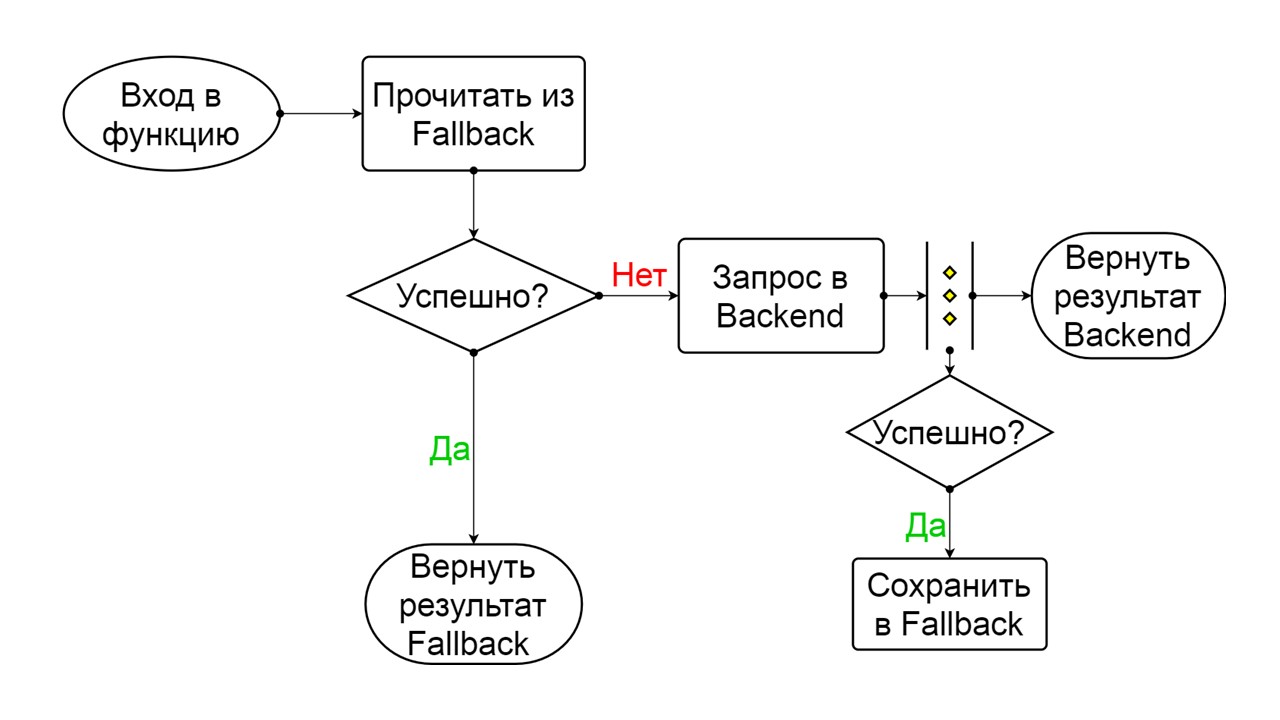
قاطع الدائرة
هنا ، تنتقل المسؤولية إلى منطقة نمط قواطع الدائرة الشهيرة.
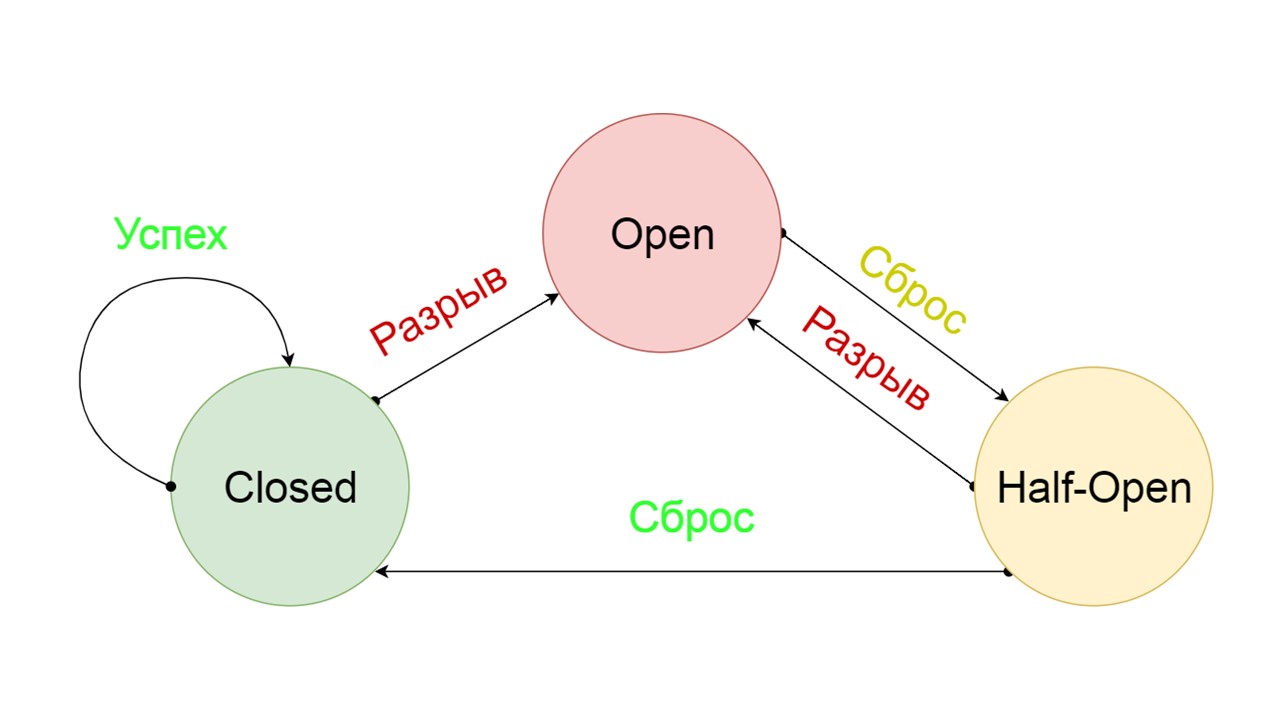
قواطع دوائر نموذجية تشمل ثلاث ولايات.
مغلق - الحالة الافتراضية المغلقة التي تغلق خلفيتنا. المبدأ هو أننا نقرأ البيانات أولاً من الخلفية ، وفقط إذا لم نتمكن من الحصول عليها ، انتقل إلى Fallback. إذا تمكنا من الحصول على البيانات ، فنحن لا نبحث في Fallback ، ولكننا نحفظ البيانات فيه ولا يحدث شيء.
إذا استمرت المشكلات واحدة تلو الأخرى ، فإننا نفترض أن الواجهة الخلفية تكذب. من أجل عدم إغراقها بكمية هائلة من الطلبات الجديدة ، ننتقل إلى
فتح - في حالة ممزقة . في ذلك ، نحاول قراءة البيانات فقط من Fallback. إذا لم ينجح الأمر ، فسنرجع خطأً على الفور ، ولا نلمس الواجهة الرئيسية.
بعد فترة من الوقت ، قررنا معرفة ما إذا كانت الخلفية قد استيقظت ، ونحاول إعادة تعيين الحالة
نصف المفتوحة - وهي حالة قصيرة العمر . طول حياته هو طلب واحد.
في الحالة القصيرة العمر ، نختار الإغلاق مرة أخرى أو فتحها لفترة أطول. إذا وصلنا إلى الحالة الاحتياطية في الحالة نصف المفتوحة ، وتلقينا الطلب التالي ، فسنذهب إلى الحالة المغلقة. إذا لم نتمكن من الوصول ، فإننا نعود إلى فتح ، ولكن لفترة طويلة.
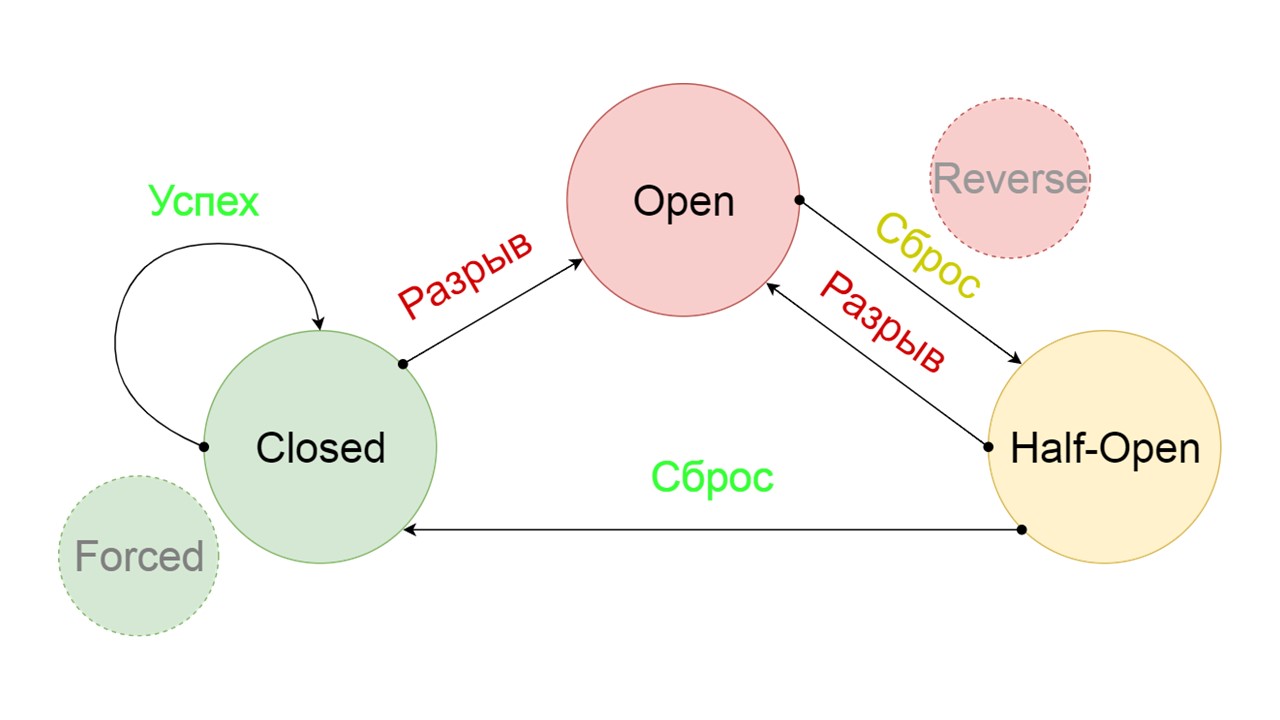
أضفنا حالتين إضافيتين لا يرتبطان بشكل واضح بدائرة Circuit Breaker:
- دولة قسرية مغلقة بقوة ؛
- عكس - الأولوية لفتح ، مغلقة الحالة المقلوبة.
دعونا نرى ماذا يفعلون.
مبدأ تشغيل الدول
مغلقة. المخطط كبير ، لكنه يكفي لفهم المبدأ العام منه. نحن نبقي على احتياطي Fallback بالتوازي مع الطريقة التي نعيد بها النتيجة من الخلفية ، إذا سارت الأمور على ما يرام ونقرأ من Fallback. إذا كان الأمر سيئًا في كل مكان ، فسنرجع أولوية الخطأ.
من الخطأين ، حدد خطأ الواجهة الخلفية.
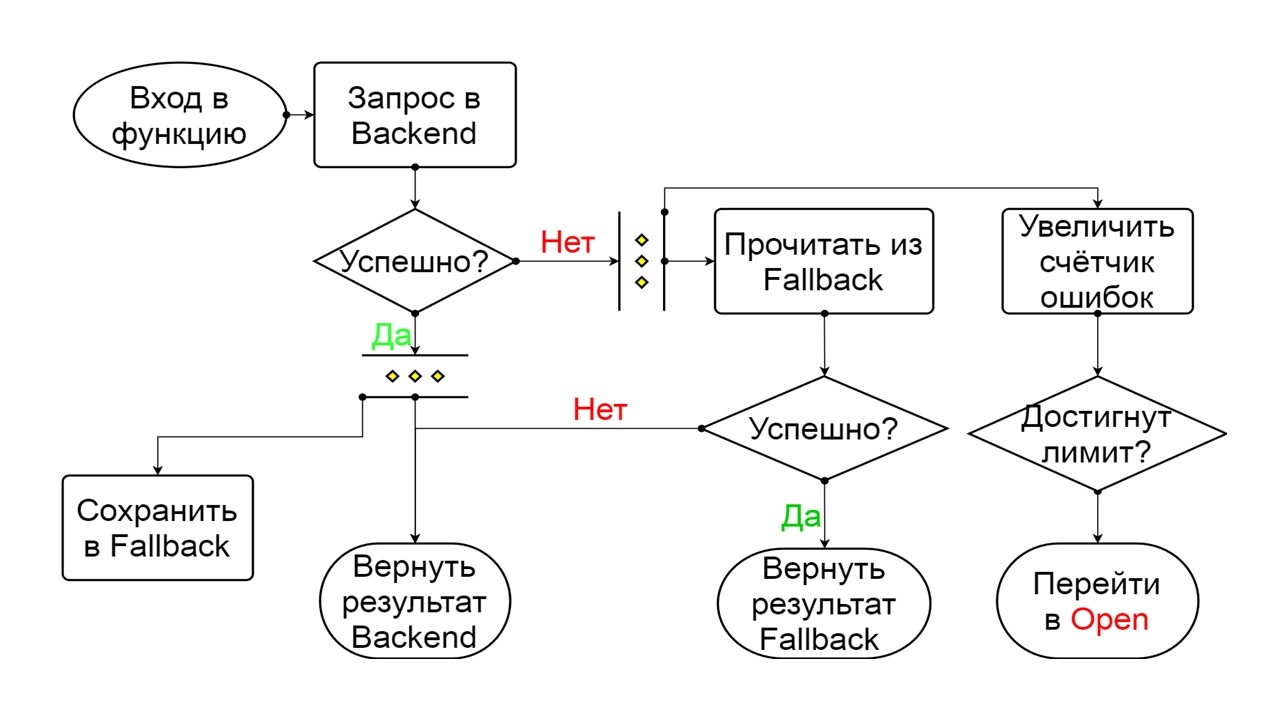
إذا لم تكن هناك أخطاء ، فنحن نزيد العداد بالتوازي مع هذا ونذهب إلى الحالة المفتوحة عندما يكون هناك الكثير من الطلبات.
 مفتوحة.
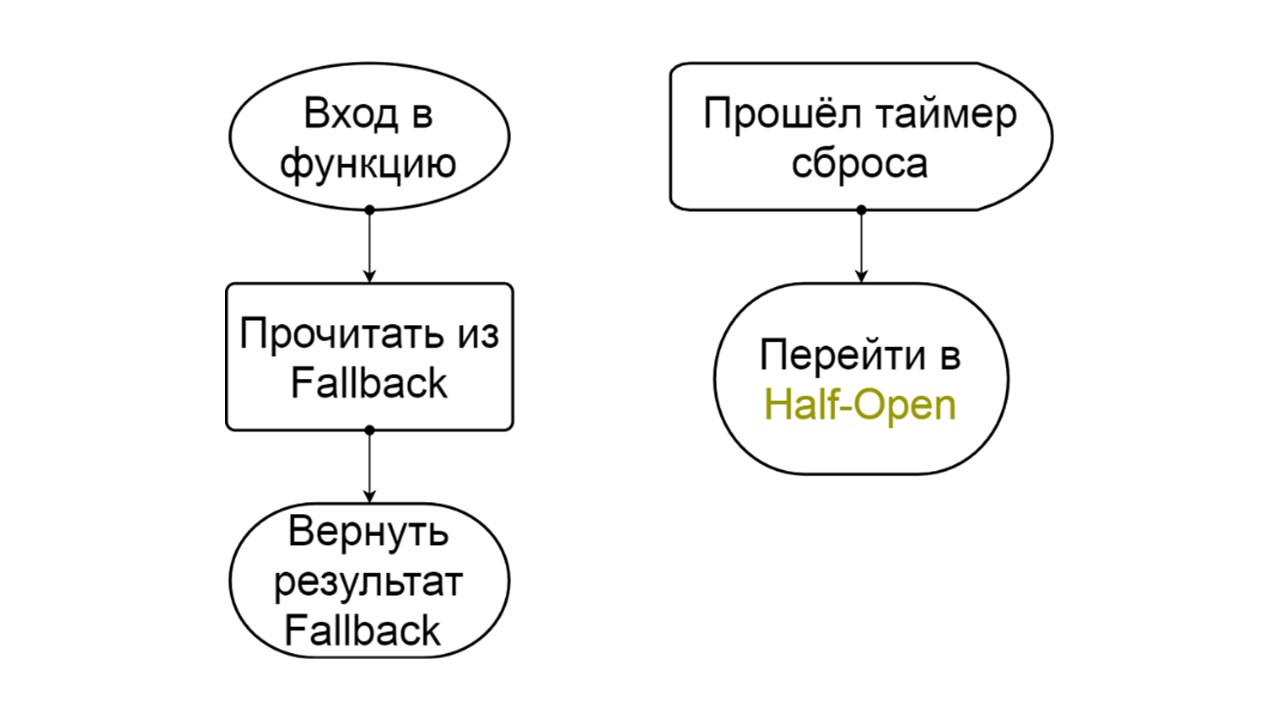
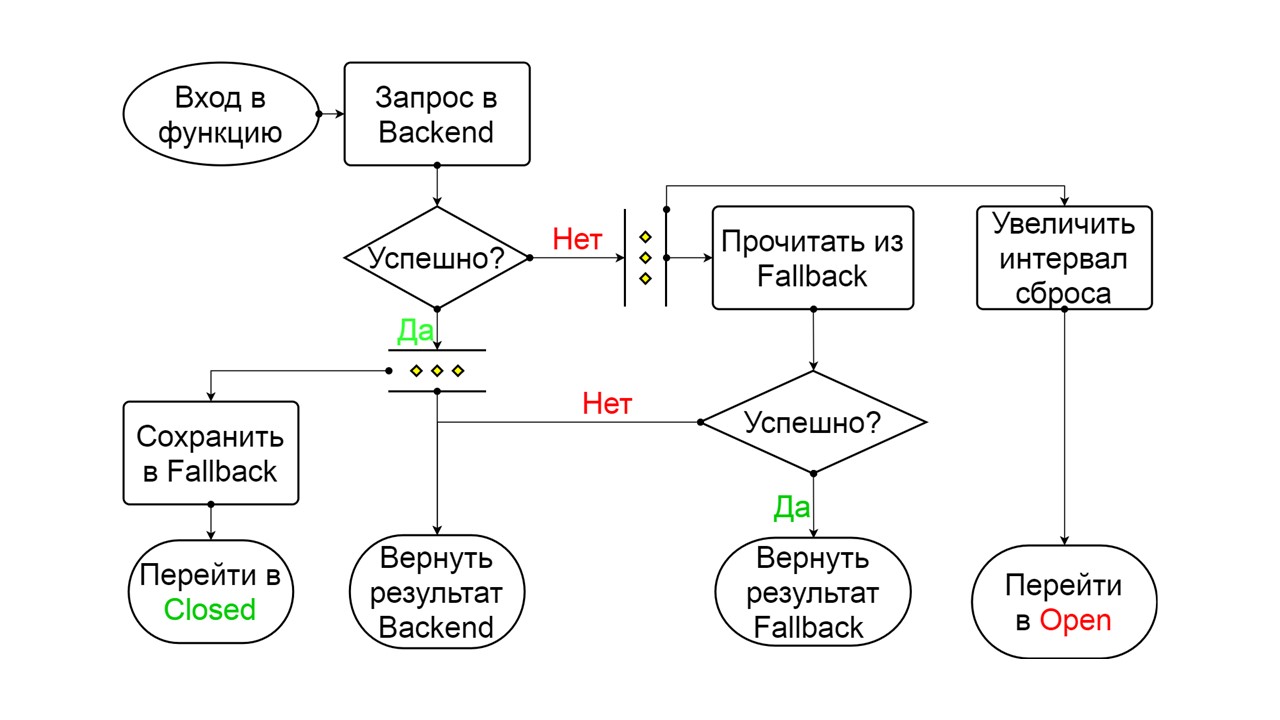
مفتوحة. حالة فتح المفتوحة أبسط - نقرأ باستمرار من Fallback ، بغض النظر عن ما يحدث ، وبعد فترة من الوقت نحاول التحول إلى حالة نصف مفتوحة.
نصف مفتوحة . تشبه الحالة في الهيكل مغلق. الفرق هو أنه في حالة وجود إجابة ناجحة ، نذهب إلى حالة مغلقة. في حالة الفشل - نعود إلى العلن بفاصل زمني ممتد.
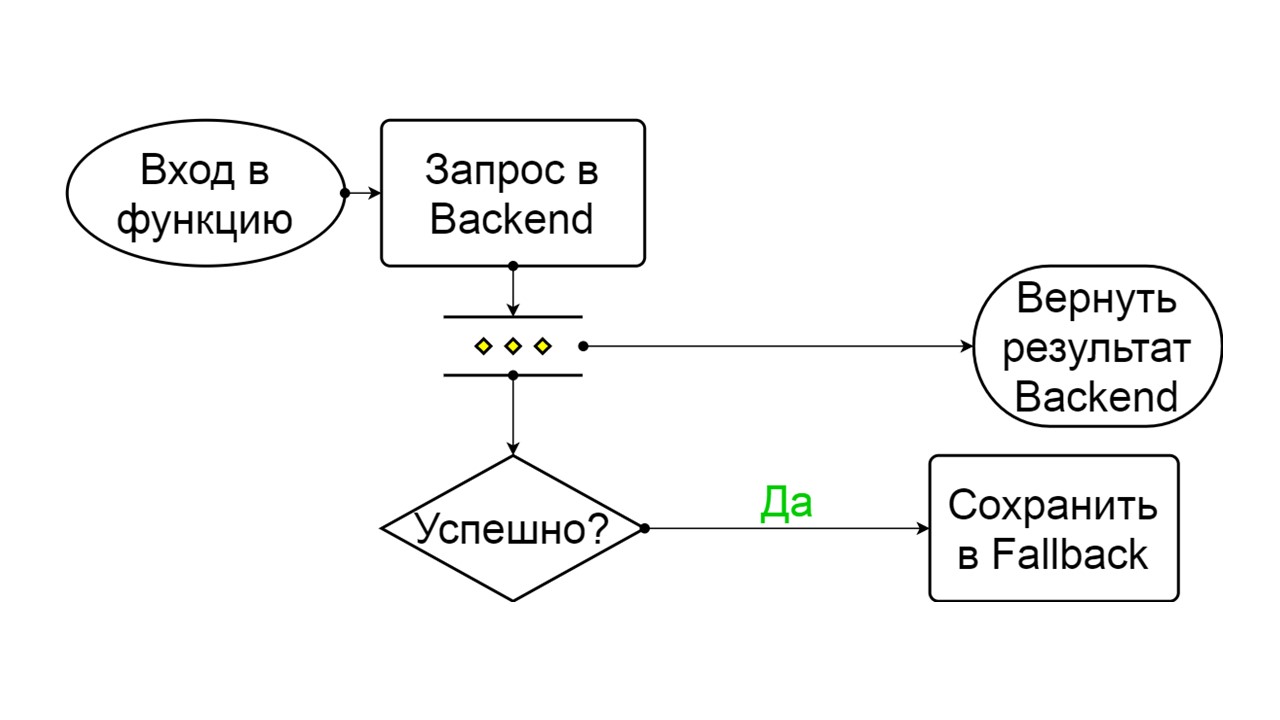
 القسري هو حالة إضافية لتسخين ذاكرة التخزين المؤقت
القسري هو حالة إضافية لتسخين ذاكرة التخزين المؤقت . عندما نملأها بالبيانات ، لا تحاول القراءة من Fallback أبدًا ، بل تضيف السجلات فقط.
 Reversed هي الحالة الثانية بعيدة المنال
Reversed هي الحالة الثانية بعيدة المنال . وهو يعمل مثل ذاكرة التخزين المؤقت المستمر. نقوم بتشغيل الحالة عندما نريد إزالة الحمل نهائيًا من الواجهة الخلفية ، حتى لو كانت البيانات غير ملائمة. عكس البحث الأول في Fallback ، وإذا فشل البحث ، فإنه يذهب إلى الواجهة الخلفية ويتعامل معه.
المشاكل
مع هذا المخطط برمته ، واجهنا العديد من المشاكل. الأخطر هو مع فهم كيفية عمل
البيانات المعدة في كاساندرا. تم إصلاح هذه المشكلة في الإصدار 4.0 ، الذي لم يتم إصداره بعد ، لذلك سأخبرك.
تم تصميم Cassandra لربط ملايين العملاء به في نفس الوقت ، والجميع يحاول إعداد بياناتهم المعدة. وبطبيعة الحال ، لا تعد Cassandra كل عبارة معدة ، وإلا ستنفذ الذاكرة. يقوم بحساب المعلمة MD5 بناءً على النص ومساحة المفتاح وخيارات الاستعلام. إذا تلقت نفس الطلب تمامًا بنفس MD5 بالضبط ، فسوف تأخذ الطلب الذي تم إعداده بالفعل. يحتوي بالفعل على معلومات حول البيانات الوصفية وكيفية التعامل معها.
ولكن هناك قضايا الإصدار. نحن نصدر إصدارًا جديدًا ، نجح في ترحيل عمليات الترحيل ، إضافة الحقول في أنواعها ، وتشغيل البيانات المعدة. لقد عادوا مع الإصدار السابق من حالتنا وبيانات التعريف الخاصة بنا - مع أنواع بدون حقول. في وقت قراءة البيانات ، نحاول كتابة الأعمدة الجديدة المطلوبة ، ونواجه حقيقة أنها ببساطة غير موجودة! وتقول كاساندرا إن هذا نوع مختلف عمومًا لا تعرفه.
لقد تعاملنا مع هذه المشكلة على النحو التالي: لقد
أضفنا نصًا فريدًا لكل طلب من طلباتنا المعدة .
create table get_offer( key frozen<tuple<frozen<user>, bigint>> PRIMARY KEY, value frozen<friend_data>, query_tag text ) insert into get_offer (key, value, query_tag) values (?key, ?value, 'tag_123'); select value as tag_123 from get_offer where key = ?key;
لن يكون لدينا ملايين العملاء المتصلين ، ولكن جلسة واحدة فقط لكل عقدة تحتوي على عدة اتصالات. لكل إعداد بيان مرة واحدة. نفترض أنه لا بأس إذا تم إنشاء نص فريد لكل نسخة من التطبيق أو لكل بداية للعقدة ، والذي سيكون بوضوح في نص طلبنا.
أضفنا حقل خاص لخداعه. عند الإدراج ، نكتب ثابتًا في هذا المجال. إنه فريد لكل إصدار تشغيل أو إصدار تطبيق - يتم تكوين هذا في المكتبة. عند القراءة ، نستخدم هذا الاسم كاسم مستعار للقيمة التي نحصل عليها. الطلب هو نفسه تمامًا ، ما زلنا نفعل قيمة تحديد ، ولكن النص مختلف. لا تدرك Cassandra أن هذا هو نفس الطلب ، وتقوم بحساب MD5 آخر وتقوم بإعداد الطلب مرة أخرى باستخدام بيانات تعريف جديدة.
المشكلة الثانية هي
سباق الهجرة . على سبيل المثال ، نريد أن نجعل عدة هجرات موازية. دعنا نبدأ بعض الملاحظات وفي نفس الوقت سوف تبدأ العمليات الحسابية ، فإنها ستعمل على إنشاء جداول وإنشاء أنواع. يمكن أن يؤدي هذا إلى حقيقة أنه في كل عقدة أو في كل من مؤشرات الترابط المتوازية سيكون كل شيء ناجحًا ويبدو أن جدولين قد تم إنشاؤهما بنجاح. لكن داخل كاساندرا يصبح مرتبكًا ، وسنتلقى مهلات للكتابة والقراءة.
يمكنك كسر Cassandra إذا حاولت موازاة العمليات من عدة مؤشرات ترابط أو من عقد متعددة.
إذا علمنا أنه يجب أن يكون لدينا ترحيل احتياطي ، فإننا ننتقل
من عقدة خاصة واحدة قبل الإصدار . عندها فقط سوف نبدأ جميع العقد خلال الإصدار. لذلك نحن حل هذه المشكلة.
المشكلة الثالثة هي
نقص البيانات في ذاكرة التخزين المؤقت للذاكرة الاحتياطية . قد يكون الأمر أننا "استعننا" بهذه الطريقة ، يجب أن نقوم بتخزين البيانات التاريخية لمدة عام ، ولكن في الواقع أطلقناها بالأمس.
تم حل المشكلة عن طريق الاحماء . استخدمنا الحالة القسرية وأطلقنا عقدًا خاصًا لن يتواصل مع مستخدمين حقيقيين. سوف يأخذون جميع المفاتيح الممكنة التي نفترضها وسوف يقومون بتسخين ذاكرة التخزين المؤقت في دائرة. الاحماء يجري بسرعة كبيرة حتى لا تقتل الخلفية التي نقرأ عنها.
تطبيقات التحجيم ، الخلفية ، البيانات الكبيرة والواجهة الأمامية - Scala مناسب لكل هذا. 26 نوفمبر ، نحن نعقد مؤتمرا محترفا لمطوري Scala . الأساليب والمناهج وعشرات الحلول لنفس المشكلة ، والفروق الدقيقة في استخدام الأساليب القديمة والمثبتة ، وممارسة البرمجة الوظيفية ، ونظرية رواد الفضاء الوظيفيين المتطرفين - سنتحدث عن كل هذا في المؤتمر. التقدم بطلب للحصول على تقرير إذا كنت ترغب في مشاركة تجربة Scala قبل 26 سبتمبر ، أو حجز التذاكر الخاصة بك .