لماذا نريد حتى كتابة مدونة تنافسية؟ لأن المعالجات توقفت عن النمو على طول الانخفاضات وبدأت في النمو على طول النوى. يتزايد عدد مراكز المعالج كل عام ، ونريد الاستفادة منها بفعالية. Go هي اللغة التي تم إنشاؤها لهذا الغرض. الوثائق تقول ذلك.
نأخذ Go ، ابدأ في كتابة التعليمات البرمجية التنافسية. بالطبع ، نتوقع أن نتمكن بسهولة من كبح قوة كل نواة من معالجنا. هل هذا صحيح؟
اسمي أرتيمي. هذا المنشور هو نسخة مجانية من حديثي مع GopherCon Russia. يبدو أنه محاولة لإعطاء زخم للأشخاص الذين يرغبون في معرفة كيفية كتابة رمز تنافسي جيد.
فيديو من مؤتمر GopherCon Russia
نماذج التفاعل
لفهم ما إذا كان تطبيق Go يجعل الأمر أكثر سهولة بالنسبة لنا ، دعنا ننظر إلى نموذجين للتفاعل: الذاكرة المشتركة وتمرير الرسائل .

الذاكرة المشتركة عبارة عن ذاكرة مشتركة تستخدمها مؤشرات ترابط متعددة لتبادل البيانات. يجب مزامنة الوصول إلى الذاكرة. عادة ما يتم تنفيذ هذا التزامن من خلال نوع من الأقفال. يعتبر هذا النهج التواصل الضمني.
تقول خدمة تمرير الرسائل أننا سنتفاعل بشكل صريح ، ولهذا سنستخدم القنوات التي سنرسل الرسائل إليها. يعتمد CSP ( التواصل المتسلسل ) ونموذج الممثل على هذا النهج.

يقول Rob Pike ، وهو الأب المؤسس لـ Go ، أنك بحاجة إلى التخلي عن البرمجة منخفضة المستوى باستخدام الذاكرة المشتركة واستخدام نهج تمرير الرسائل . سيساعدك هذا النهج في كتابة التعليمات البرمجية بطريقة أسهل وأكثر كفاءة والأهم من ذلك مع وجود عدد أقل من الأخطاء. الذهاب يختار نهج CSP . نفس النهج أثر بشكل كبير على تطوير لغة مثل Erlang.
سؤال: هل صحيح أننا إذا أخذنا Go ، فكل شيء سيكون على ما يرام؟

صادفت دراسة وجدت فيها هذا الجهاز اللوحي. يعرض الجهاز اللوحي عدد الأخطاء المتعلقة بالأقفال وعددها. يعرض العمود الأول المنتجات التي تم أخذها في الدراسة. هذه هي المنتجات الأكثر شعبية مكتوبة في الذهاب. يُظهر عمود "الذاكرة المشتركة" عدد الأخطاء التي تنشأ بسبب الاستخدام غير السليم للذاكرة المشتركة ، ويظهر عمود "تمرير الرسائل" ، على التوالي ، عدد الأخطاء الناتجة عن "تمرير الرسائل".
الشيء الأكثر أهمية في هذه اللوحة هو الخط الكلي . إذا نظرت إليه ، فستلاحظ وجود أخطاء أكثر عند استخدام " تمرير الرسائل" أكثر من استخدام الذاكرة المشتركة . أنا متأكد من أن الأشخاص الذين يكتبون Kubernetes أو Docker أو etcd هم من المطورين ذوي الخبرة ، ولكن حتى " تمرير الرسائل" الخاص بهم لا يحفظ من الأخطاء ، علاوة على ذلك ، فإن هذه الأخطاء لا تقل عن "الذاكرة المشتركة".
حتى مجرد الذهاب والبدء في كتابة رمز خالية من الأخطاء سوف تفشل.
التزامن والتوازي
عندما نبدأ الحديث عن التنمية متعددة الخيوط ، نحتاج إلى تقديم مفاهيم مثل التزامن والتوازي . في عالم Go ، هناك تعبير "التزامن ليس توازي" . خلاصة القول هي أن التزامن يدور حول التصميم ، أي كيفية تصميم برنامجنا. التوازي هو مجرد وسيلة لتنفيذ التعليمات البرمجية لدينا.

إذا كان لدينا العديد من مؤشرات الترابط من التعليمات التي يتم تنفيذها في وقت واحد ، ثم نقوم بتنفيذ التعليمات البرمجية بالتوازي. التوازي يتطلب المنافسة. لن يكون من الممكن موازاة برنامج دون تصميم تنافسي ، في حين أن القدرة التنافسية لا تتطلب التوازي ، لأن البرنامج الذي يمكن أن يعمل على العديد من النوى ، في الواقع ، يمكن أن يعمل على نواة واحدة.
Go هي لغة تساعدنا على كتابة البرامج التنافسية ، وتساعدنا في بناء التصميم. إنها تسمح لك بالتفكير قليلاً في الأمور ذات المستوى المنخفض.
قانون أمدال
نريد استخدام نوى المعالج ، نكتب بعض الرموز لهذا الغرض. ولكن السؤال الذي يطرح نفسه: ما هو نوع الزيادة في الإنتاجية التي نحصل عليها مع زيادة في عدد النوى. لذا ، فإن التسارع الذي يمكن أن نحصل عليه ، هو في الواقع مقيد بقانون أمدال .
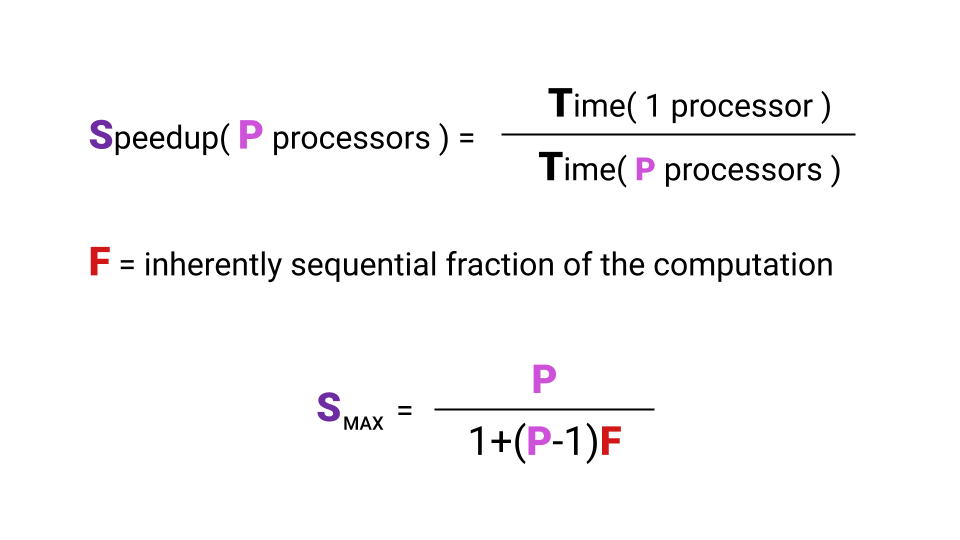
ما هو التسارع؟ التسريع هو الوقت الذي يتم فيه تشغيل البرنامج على معالج واحد مقسومًا على الوقت الذي يتم فيه تشغيل البرنامج على معالجات P. تشير الحرف F ( Fraction ) إلى جزء البرنامج الذي يجب تنفيذه بالتتابع. وهنا ليس من الضروري الخوض في المعادلة ، الشيء الرئيسي هو ملاحظة أن الحد الأقصى للتسريع الذي نحصل عليه بزيادة في عدد النوى يعتمد على F. ألقِ نظرة على الرسم البياني لتصور هذه العلاقة.
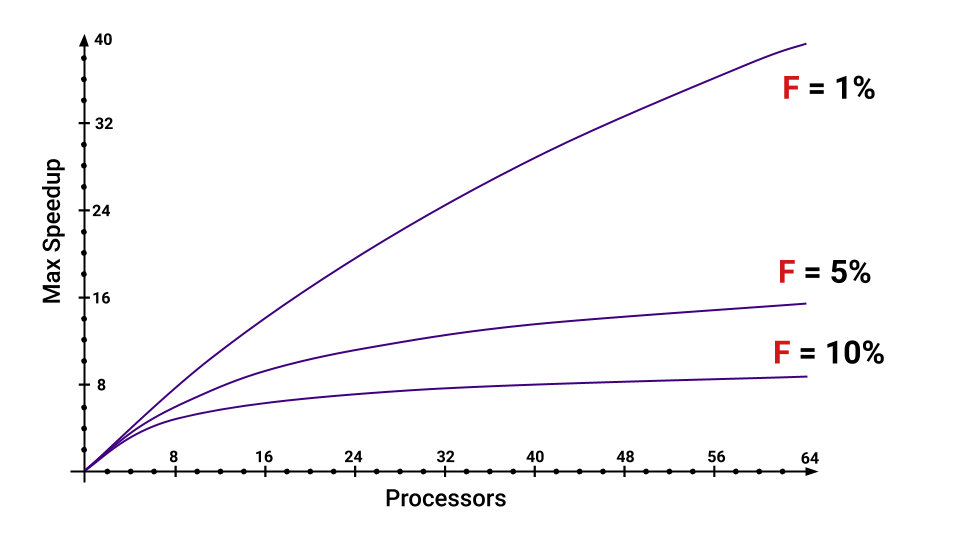
حتى إذا كان لدينا فقط 5٪ من البرنامج ليتم تنفيذه بشكل متتابع ، فإن الحد الأقصى للتسريع الذي نحصل عليه سينخفض بدرجة كبيرة مع زيادة عدد المراكز. يمكنك تقدير ما هي الأجزاء التي تزيد F.
وحدة المعالجة المركزية منضم مقابل I / O منضم
ليس من المنطقي دائمًا استخدام تعدد العمليات. تحتاج أولا إلى إلقاء نظرة على نوع الحمل. هناك نوعان من التحميل: CPU Bound و I / O Bound . الفرق هو أنه مع CPU Bound ، نحن مقيدون من خلال أداء المعالج ، ومع I / O Bound ، فإننا نقتصر على سرعة نظام الإدخال / الإخراج الفرعي الخاص بنا. ولا حتى السرعة ، ولكن وقت الانتظار للحصول على إجابة. الانتقال إلى الإنترنت - في انتظار الإجابة ، والذهاب إلى القرص - في انتظار الإجابة مرة أخرى. ما هو الفرق ، كم عدد النوى الموجودة ، إذا كان معظم الوقت في انتظار إجابة؟
لذلك ، نواة واحدة أو ألف ، لن نحصل على زيادة في الأداء مع تحميل I / O Bound. ولكن إذا كان لدينا تحميل وحدة المعالجة المركزية منضم ، فهناك فرصة للحصول على تسريع عند موازاة برنامجنا.
على الرغم من وجود حالات عند تحميل وحدة المعالجة المركزية (CPU) الظاهرة ، إلا أنها تتحول فعليًا إلى إدخال / إخراج منضم. على سبيل المثال ، إذا كنا نريد أن نأخذ ونلخص جميع عناصر مجموعة كبيرة ، ماذا سنفعل؟ سنكتب دورة ، كل شيء سوف يعمل. ثم نفكر: "لذلك لدينا مجموعة من النوى. دعنا نأخذ ذلك فقط ، ونقسم المجموعة إلى أجزاء ونقوم بموازنة كل شيء ". ماذا ستكون النتيجة؟
والنتيجة هي موقف يقوم فيه معالجنا بمعالجة البيانات بشكل أسرع من إدارته من الذاكرة. في هذه الحالة ، في معظم الوقت سننتظر البيانات من الذاكرة ، والتحميل ، الذي بدا وكأنه وحدة المعالجة المركزية منضم ، يتحول بالفعل إلى I / O Bound.
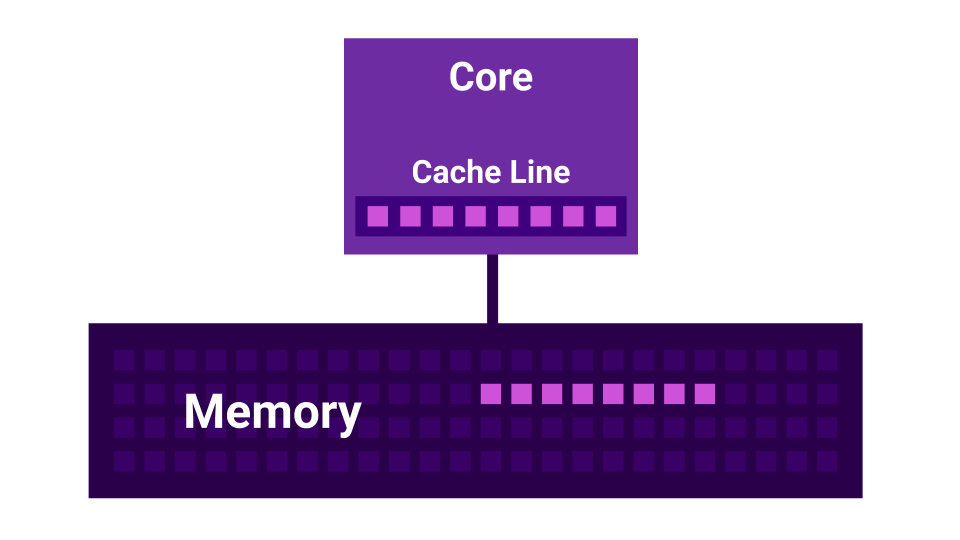
تقاسم كاذبة
علاوة على ذلك ، هناك قصة مثل مشاركة خاطئة . مشاركة خاطئة هي حالة عندما تبدأ النوى بالتداخل مع بعضها البعض. هناك نواة أولى ، وهناك نواة ثانية ، ولكل منها ذاكرة L1 مخبأة . L1 Cache مقسمة إلى خطوط ( Cache Line ) من 64 بايت. عندما نحصل على بعض البيانات من الذاكرة ، نحصل دائمًا على ما لا يقل عن 64 بايت. من خلال تغيير هذه البيانات ، نقوم بتعطيل ذاكرات التخزين المؤقت لجميع النوى.

اتضح أنه في حالة تغيير اثنين من النوى البيانات قريبة جدا من بعضها البعض ( على مسافة أقل من 64 بايت ) ، فإنها تبدأ في التدخل مع بعضها البعض ، وإبطال ذاكرة التخزين المؤقت. في هذه الحالة ، إذا تمت كتابة البرنامج بشكل متسلسل ، فسيعمل بشكل أسرع من استخدام عدة نوى تتداخل مع بعضها البعض. لمزيد من النوى ، وانخفاض الأداء.
المنظمون
سنرتفع إلى المستوى التالي من التجريد - إلى المخططين.
عندما يبدأ العمل برمز تنافسي ، تظهر الجداول. Go لديه ما يسمى جدولة مساحة المستخدم التي تعمل على goroutines . يحتوي نظام التشغيل أيضًا على جدولة خاصة به ، والتي تعمل مع مؤشرات ترابط نظام التشغيل . وحتى المعالج ليس بهذه البساطة. على سبيل المثال ، لدى المعالجات الحديثة تنبؤات فرعية وطرق أخرى لإفساد صورتنا الجميلة عن الخطية في العالم.
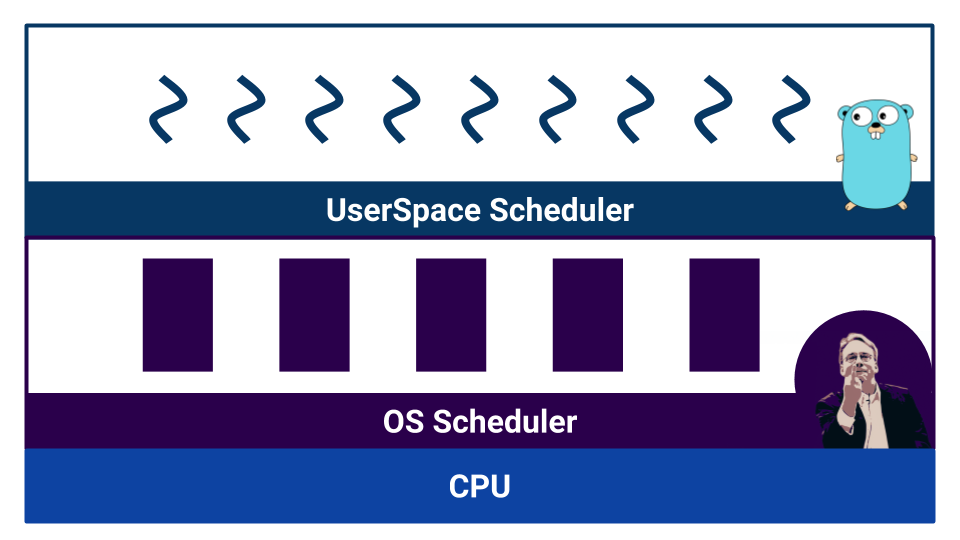
يتم تقسيم المجدولين حسب نوع تعدد المهام. هناك تعدد المهام التعاونية وتعدد المهام الوقائية . في حالة تعدد المهام التعاونية ، تقرر عملية التنفيذ نفسها متى تحتاج إلى نقل التحكم إلى عملية أخرى ، وفي حالة تعدد المهام المزدحمة ، هناك مكون خارجي - جدولة ، يتحكم في مقدار الموارد المخصصة لهذه العملية.

تتيح تعدد المهام التعاونية لعملية واحدة "احتكار" مورد وحدة المعالجة المركزية بأكمله. في تعدد المهام الاستباقية ، لن يحدث هذا ، لأن هناك هيئة مسيطرة. ولكن مع تعدد المهام التعاونية ، يكون تبديل السياق أكثر كفاءة ، لأن العملية تعرف على وجه اليقين عند النقطة التي من الأفضل فيها التحكم في عملية أخرى. في تعدد المهام الاستباقية ، يمكن لجدولة إيقاف العملية في أي وقت - أنها ليست فعالة للغاية. في الوقت نفسه ، في تعدد المهام الاستباقية ، يمكننا توفير نفس المورد لكل عملية بفضل برنامج جدولة خارجي.
يستخدم نظام التشغيل جدولة بناءً على تعدد المهام الاستباقية ، لأن نظام التشغيل مطلوب لضمان شروط متساوية لكل مستخدم. ماذا عن الذهاب؟
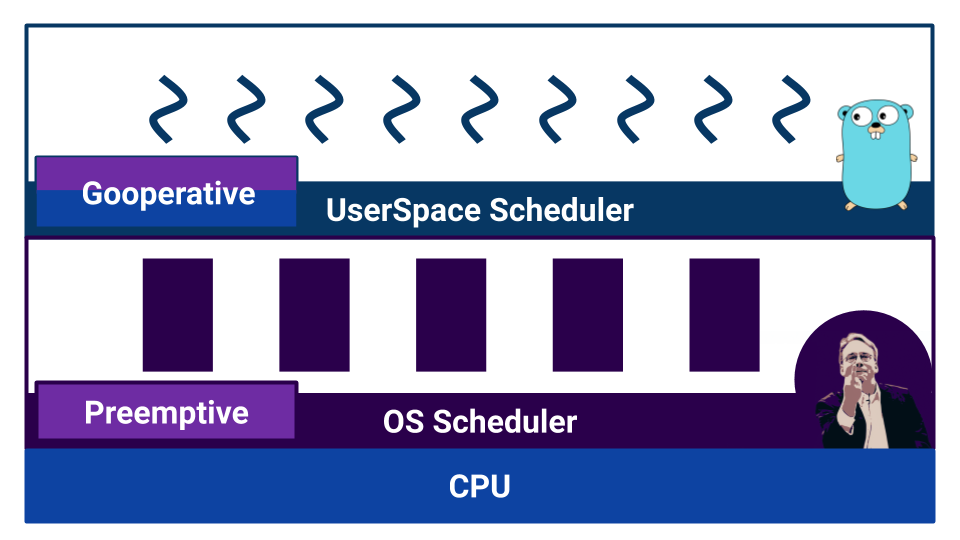
إذا قرأنا الوثائق ، فإننا نعلم أن برنامج الجدولة في Go هو إجراء وقائي. ولكن عندما نبدأ في الفهم ، اتضح أن تطبيق Go لا يحتوي على برنامج جدولة كمكون خارجي. في Go ، يقوم برنامج التحويل البرمجي بتعيين نقاط تبديل السياق. وعلى الرغم من أننا ، كمطورين ، لا نحتاج إلى تبديل السياق يدويًا ، إلا أنه لا يتم تحويل التحكم إلى المكون الخارجي. بفضل هذا ، تعتبر Go فعالة للغاية في تحويل goroutine إلى أخرى. لكن سوء فهم ميزات عمل مثل هذا "المخطط" يمكن أن يؤدي إلى سلوك غير متوقع. على سبيل المثال ، ماذا سينتج هذا الكود؟

مثل هذا الرمز سوف يتجمد.
لماذا؟ لأنه في البداية ، باستخدام GOMAXPROCS ، أجبرنا البرنامج على استخدام نواة واحدة فقط. بعد ذلك ، تم وضع goroutine في قائمة الانتظار ، والتي من خلالها يجب أن تعمل دورة لا نهاية لها. ثم ننتظر 500 مللي ثانية وطباعة x . بعد time.Sleep سيبدأ goroutine بالفعل ، ولكن لن يكون هناك طريقة للخروج من الحلقة اللانهائية ، لأن المترجم لن يضع نقطة تبديل السياق. يتجمد البرنامج.
وإذا أضفنا runtime.Gosched() داخل الحلقة ، فسيكون كل شيء على ما يرام ، لأننا runtime.Gosched() صراحة إلى أننا نريد تبديل السياق.
هذه الميزات تحتاج أيضا إلى معرفة وتذكر.
تحدثنا عن تبديل السياق ، ولكن أين عادةً ما يقوم Go بإدخال نقاط التبديل؟

عادةً ما يتم إدراج runtime.morestack() و runtime.newstack() في الوقت الذي يتم استدعاء الوظيفة فيه. runtime.Goshed() يمكننا تزويد أنفسنا. وبالطبع ، يحدث تبديل السياق أثناء الأقفال وارتفاعات الشبكة ومكالمات النظام. يمكنك أن تبحث في هذا الموضوع تقرير لكريل لاشكيفيتش . جيد جدا ، أنا أنصح.
دعنا نذهب أبعد من ذلك إلى الكود. سوف ننظر في الأخطاء.
حالة السباق
واحدة من الأخطاء الأكثر شعبية التي نرتكبها هي Race Condition . خلاصة القول هي أنه عندما نفعل ، على سبيل المثال ، زيادة ، في الواقع نحن لا نقوم بعملية واحدة ، ولكن عدة: المعالج يقرأ البيانات من الذاكرة للتسجيل وتحديث السجل وكتابة البيانات إلى الذاكرة.

لا يتم تنفيذ هذه العمليات الثلاث تلقائيًا. لذلك ، يمكن لبرنامج الجدولة في أي وقت ، وفي أي من هذه العمليات ، سحب تدفقنا. اتضح أن الإجراء لم ينته ، وبسبب هذا نحن نلاحظ الأخطاء.
فيما يلي مثال على هذا الرمز ( يتم تحليل الزيادة على الفور في عدة عمليات ).

يمكن لبرنامج الجدولة أن يستبق الخيط الأول بعد تنفيذ السطر الأول ، والخيط الثاني بعد التحقق من الحالة. في هذه الحالة ، يقع كلا التدفقين في القسم الحرج ، وبالتالي يكون "حرجًا" - لا يمكن إدخال كلا التدفقين هناك في وقت واحد.
يمكننا قفل باستخدام sync.Mutex من حزمة sync القياسية. يسمح لنا حظر الوصول بالإشارة صراحة إلى أنه يجب تنفيذ التعليمات البرمجية بواسطة مؤشر ترابط واحد في كل مرة. باستخدام هذا الرمز ، نحصل على ما نحتاجه.

الأقفال هي عملية مكلفة للغاية. لذلك ، هناك عمليات ذرية على مستوى المعالج. في هذه الحالة ، يمكن إجراء الزيادة الذرية عن طريق استبدالها بعملية atomic.AddInt64 من الحزمة atomic .
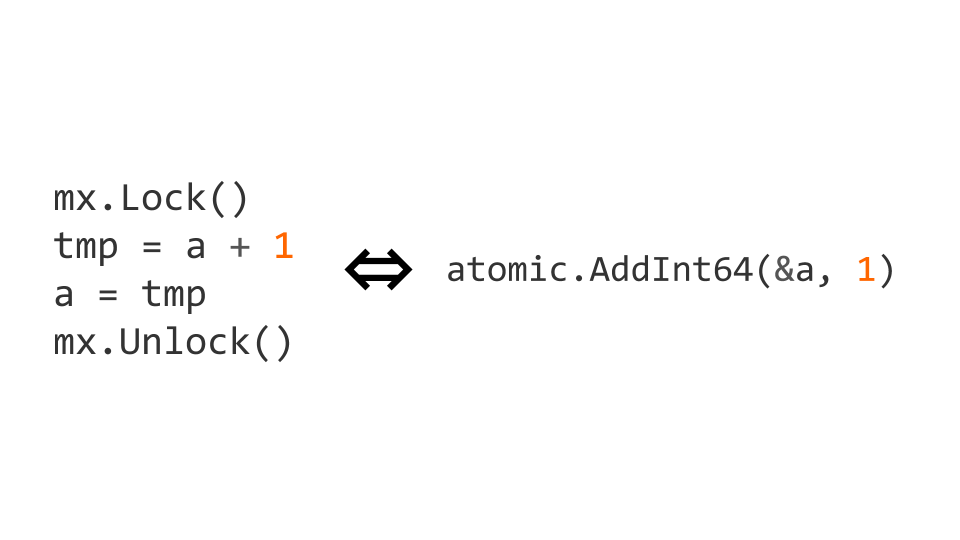
إذا بدأنا العمل بتعليمات ذرية ، فعلينا ألا نكتب فقط ذريًا ، بل نقرأها أيضًا أيضًا. إذا لم نفعل ذلك ، فقد تنشأ مشاكل.
التحسين - ماذا يمكن أن يحدث خطأ؟
أقفال جيدة ، ولكن يمكن أن تكون مكلفة. الذرات رخيصة بما فيه الكفاية حتى لا تقلق بشأن الأداء.
لذلك تعلمنا أن بدائل التزامن تقدم حملًا ، وقررنا إضافة تحسين - سنقوم بفحص العلم دون النظر إلى تعدد العمليات ، ثم التحقق من استخدام بدائل التزامن. كل شيء يبدو على ما يرام ويجب أن تعمل.

كل شيء على ما يرام ، إلا أن المترجم يحاول تحسين رمز لدينا. ماذا يفعل؟ لقد قام بتبديل تعليمات المهمة ، وحصلنا على سلوك غير صالح ، لأننا قمنا done يصبح true قبل تعيين قيمة المتغير "
لا تحاول القيام بهذه التحسينات - فبسببها ستواجه الكثير من المشاكل. أنصحك بقراءة مواصفات The Go Memory Model ومقال بقلم دميتري فيوكوفا ( dvyukov ) سباقات البيانات الحميدة: ما الذي يمكن أن يكون خاطئًا ؟ لفهم القضايا بشكل أفضل.
إذا كنت تعتمد حقًا على الأداء على الأقفال - فاكتب رمزًا خالٍ من الأقفال ، لكنك لست بحاجة إلى القيام بوصول غير متزامن إلى الذاكرة.
مأزق
المشكلة التالية التي سنواجهها هي حالة توقف تام. قد يبدو أن كل شيء تافه للغاية هنا. هناك نوعان من الموارد ، على سبيل المثال ، اثنين من Mutex . في الخيط الأول ، نلتقط أولاً Mutex الأول ، وفي الخيط الثاني نلتقط أولاً Mutex الثاني. علاوة على ذلك ، Mutex أخذ Mutex الثاني في الخيط الأول ، لكننا لن نكون قادرين على القيام بذلك ، لأنه قد تم حظره بالفعل. في الخيط الثاني ، سنحاول أن نأخذ ، على التوالي ، أول Mutex وأيضًا كتلة. ها هو ، الجمود.
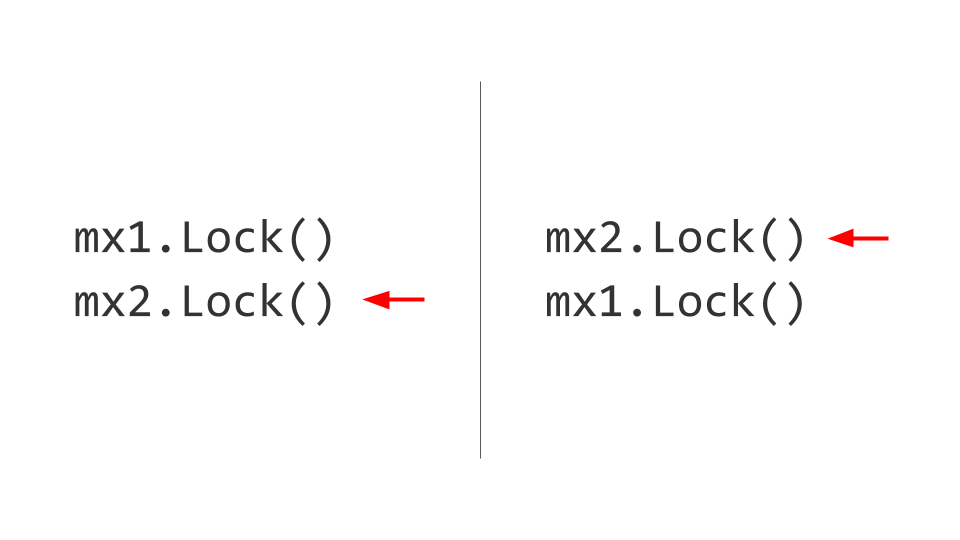
لن تتمكن أي من هذين الموضوعين من التقدم أكثر ، لأن كلاهما سينتظر المورد. كيف يتم حل هذا؟ نحن مبادلة الأقفال ، ومن ثم لا تنشأ مشاكل. بالطبع ، من السهل القول ، لكن الحفاظ على هذه القاعدة طوال عمر المنتج ليس بالأمر السهل. إذا كان ذلك ممكنًا ، فقم بذلك - خذ القفل بنفس الترتيب واعطيه
قد يبدو أن المطورين ذوي الخبرة لا يواجهون مثل هذه الأخطاء ، ولكن هنا مثال على حالة توقف تام من رمز المشروع وغيرها.

المهم هنا هو أن الكتابة إلى قناة غير مقيدة تمنع ؛ والكتابة ، تحتاج إلى قارئ من ناحية أخرى. بأخذ mutex ، ينتظر مؤشر الترابط الأول ظهور القارئ. مؤشر الترابط الثاني لم يعد التقاط mutex. طريق مسدود.
أنصحك بتجربة اللعبة المثيرة The Deadlock Empire . في هذه اللعبة ، تتصرف كجدول زمني يجب تبديل السياق لمنع تنفيذ التعليمات البرمجية بشكل صحيح.
نوع من المشاكل
ما هي المشاكل التي لا تزال موجودة؟ لقد بدأنا بشروط سباق . بعد ذلك نظرنا إلى Deadlock (لا يزال هناك متغير منه Livelock ، وهذا هو عندما لا يمكننا التقاط المورد ، ولكن لا توجد أقفال واضحة). هناك Starvation ، وهذا عندما نذهب إلى الطابعة لطباعة قطعة من الورق ، وهناك قائمة انتظار ، ولا يمكننا الوصول إلى المورد. نظرنا في سلوك البرنامج مع False Sharing . لا تزال هناك مشكلة - Lock Contention ، عندما يتحلل الأداء بسبب الكثير من المنافسة على مورد (على سبيل المثال ، كائن مزامنة واحد يحتاج إليه عدد كبير من مؤشرات الترابط).

كشف السباق
Go قوي مع صندوق الأدوات المقدم من الصندوق. سباق الكاشف هو واحد من هذه الأداة. استخدامه بسيط: نكتب الاختبارات أو نقوم بتشغيلها على عبء قتالي وأخطاء في الصيد.
يمكنك قراءة المزيد حول استخدام Race Detector في الوثائق ، لكن تذكر أنه يحتوي على قيود. دعونا نتناولها بمزيد من التفصيل.

أولاً ، لم يتم التحقق من الكود الذي لم يتم تنفيذه بواسطة Race Detector. لذلك ، يجب أن تكون تغطية الاختبار عالية. بالإضافة إلى ذلك ، يتذكر Race Detector سجل المكالمات لكل كلمة في الذاكرة ، ولكن سجل المكالمات هذا له عمق. في Go ، على سبيل المثال ، هذا العمق يتكون من أربعة إلى أربعة عناصر وأربعة عمليات وصول. إذا لم يكتشف سباق العرق سباقًا في هذا العمق ، فهو يعتقد أنه لا يوجد سباق. لذلك ، على الرغم من أن Race Detector ليس مخطئًا على الإطلاق ، إلا أنه لن يلحق كل الأخطاء. يمكنك أن تأمل في Race Detector ، لكن عليك أن تتذكر حدوده. بشكل منفصل ، يمكنك أن تقرأ عن خوارزمية العمل .
كتلة الملف الشخصي
Block Profile هي أداة أخرى تسمح لنا بإيجاد وإصلاح مشاكل الحظر.

يمكن استخدامه على مستوى الاختبار القياسي ، ويمكن مشاهدته أثناء الحمل القتالي. لذلك ، إذا كنت تبحث عن مشاكل مرتبطة بمزامنة الوصول إلى البيانات ، فحاول البدء باستخدام Race Detector وتابع استخدام Block Profile.
مثال البرنامج
دعونا نلقي نظرة على الكود الحقيقي الذي يمكننا أن نتعثر عليه. سنكتب وظيفة تتطلب ببساطة مجموعة من الطلبات وتحاول تنفيذها: كل طلب بالتسلسل. في حالة إرجاع أي من الطلبات لخطأ ، تقوم الدالة بإنهاء التنفيذ.

إذا كتبنا في Go ، يجب علينا استخدام القوة الكاملة للغة. نحن نحاول. نحصل على ثلاثة أضعاف الرمز.

سؤال: هل هناك أي أخطاء في الكود؟
بالطبع! دعونا ننظر في أي منها.
في الحلقة نركض goroutines. لتنسيق goroutine ، نستخدم sync.WaitGroup . ولكن ماذا نفعل خطأ؟ بالفعل داخل goroutine قيد التشغيل ، ندعو wg.Add(1) ، أي نضيف goroutine واحدًا آخر للانتظار. وباستخدام wg.Wait() ، فإننا ننتظر استكمال جميع goroutines. ولكن قد يحدث أنه بحلول الوقت الذي يتم فيه استدعاء wg.Wait() ، لن يتم بدء تشغيل goroutine واحد. في هذه الحالة ، wg.Wait() في أن كل شيء قد تم ، وسوف نغلق القناة wg.Wait() من الوظيفة دون أخطاء ، معتقدًا أن كل شيء على ما يرام.

ماذا سيحدث بعد ذلك؟ بعد ذلك ، سيتم بدء تشغيل goroutines ، وسيتم تنفيذ التعليمات البرمجية ، وربما يُرجع أحد الطلبات خطأً. يتم كتابة خطأ في قناة مغلقة ، والكتابة إلى قناة مغلقة هي حالة من الذعر. طلبنا سوف تعطل. من غير المحتمل أن يكون هذا هو ما أردت الحصول عليه ، لذلك نقوم بتصحيحه من خلال الإشارة مقدمًا إلى عدد المرات التي سنطلقها.

ربما لا تزال هناك بعض المشاكل؟
يوجد خطأ يتعلق بكيفية ظهور كائن req داخل الوظيفة. يعمل المتغير req بمثابة تكرار للدورة ، ونحن لا نعرف القيمة التي سيكون لها في وقت إطلاق goroutine.

في الممارسة العملية ، في هذا الكود ، من المرجح أن تساوي قيمة req العنصر الأخير من المصفوفة. لذلك ، فقط أرسل نفس الطلب N مرة. إصلاح: تمرير طلبنا بشكل صريح كحجة إلى الوظيفة.

دعونا نلقي نظرة فاحصة على كيفية تعاملنا مع الأخطاء. نعلن قناة مخزنة في فتحة واحدة. عند حدوث خطأ ، نرسله إلى هذه القناة. يبدو أن كل شيء على ما يرام: حدث خطأ - لقد عدنا هذا الخطأ من إحدى الوظائف.

لكن ماذا لو عادت جميع الطلبات بخطأ؟
ثم الكتابة إلى القناة سوف تحصل على الخطأ الأول فقط ، والباقي سيمنع تنفيذ goroutines. نظرًا لأنه لن يكون هناك المزيد من القراءات من القناة في الوقت الذي تنتهي فيه الوظيفة ، نحصل على تسرب goroutine. أي أن كل هؤلاء الذين لم يتمكنوا من كتابة الخطأ إلى القناة يتعطلون ببساطة في الذاكرة.
نحن نصلحها بكل بساطة: نختار في قناة الفتحة عدد الطلبات. هذا يحل مشكلتنا وليس كفاءة الذاكرة للغاية ، لأنه إذا كان لدينا مليار الطلبات ، نحن بحاجة إلى تخصيص مليار فتحات.

نحن حل المشاكل. الرمز الآن تنافسية. ولكن المشكلة تكمن في سهولة القراءة - مقارنة بالإصدار المتزامن من الكود ، فهناك الكثير. وهذا ليس رائعًا ، لأن تطوير البرامج التنافسية أمر صعب بالفعل ، فلماذا نعقّده بالكثير من الشفرات؟

Errgroup
أقترح زيادة إمكانية قراءة الكود.
أحب استخدام حزمة errgroup بدلاً من sync.WaitGroup . لا تتطلب هذه الحزمة تحديد عدد goroutines المتوقع ، ويسمح لك بتجاهل مجموعة الأخطاء. هذه هي الطريقة التي ستبدو بها errgroup عند استخدام errgroup :

علاوة على ذلك ، يتيح errgroup تنظيم مكونات برنامجنا بشكل مريح باستخدام السياق . ماذا اقصد
لنفترض أن لدينا عدة مكونات لبرنامجنا ، إذا فشل أحدها على الأقل ، فنحن نريد إنهاء جميع المكونات الأخرى بعناية. وهكذا errgroup فإن errgroup عند حدوث خطأ ، تكمل context ، وبالتالي تتلقى جميع المكونات إشعارًا بضرورة إكمال العمل.

يمكن استخدام هذا لإنشاء برامج معقدة متعددة المكونات التي تتصرف بشكل متوقع.
النتائج
اجعلها بسيطة بقدر الإمكان. أفضل بشكل متزامن. يعد تطوير البرامج ذات مؤشرات الترابط عمومًا عملية معقدة تؤدي إلى ظهور أخطاء غير سارة.

لا تستخدم التزامن الضمني. إذا كنت مستريحًا بالفعل ، فكر في كيفية التخلص من الأقفال ، وكيفية عمل خوارزمية خالية من الأقفال.
Go هي لغة جيدة لكتابة البرامج التي تعمل بفعالية مع عدد كبير من النوى ، لكنها ليست أفضل من جميع اللغات الأخرى ، وستظهر الأخطاء دائمًا. لذلك ، حتى إذا كنت مسلحًا بـ Go ، فحاول أن تفهم عدة مستويات من التجريدات أقل مما تعمل.
