نقدم انتباهكم إلى الجزء الثاني من ترجمة المواد على نضال فريق gitlab.com ضد طغيان الزمن.

→ هنا ، بالمناسبة ، هو
الجزء الأول .
طلب الحد الأقصى لسرعة المعالجة
في هذه المرحلة ، لم نكن مهتمين ببساطة بزيادة قيم المعلمة
MaxStartups . على الرغم من أن الزيادة بنسبة 50٪ في هذه المعلمة أثبتت أنها جيدة ، إلا أن الزيادة الإضافية دون سبب كاف بدت وكأنها حل أولي للمشكلة. بالتأكيد كان هناك شيء آخر يمكننا القيام به.
نقلتني عمليات البحث إلى مستوى HAProxy ، والذي كان يقع أمام خوادم SSH. لدى HAProxy خيار
rate-limit sessions لطيفة الذي يؤثر على جزء من النظام الذي يقبل الطلبات الواردة. إذا تم تكوين هذا الخيار ، فسيتم استخدامه للحد من عدد طلبات TCP الجديدة في الثانية التي ترسلها الواجهة الأمامية للواجهات الخلفية ، مع ترك اتصالات واردة إضافية إلى مقبس TCP. إذا تجاوزت سرعة الطلبات الواردة الحد المسموح به (قابل للتغيير كل ميلي ثانية) ، فسيتم تأخير الاتصالات الجديدة ببساطة. يرى عميل TCP (في هذه الحالة ، SSH) ببساطة التأخير قبل تأسيس اتصال TCP. هذا ، في رأيي ، هو خطوة جميلة جدا. إلى أن تتجاوز السرعة التي يتم تلقي الطلبات بها ، لفترات طويلة جدًا ، الحد المسموح به ، سيعمل النظام جيدًا.
كان السؤال التالي هو اختيار قيمة خيار
rate-limit sessions ، والذي يجب أن نستخدمه. عُقد العثور على إجابة لهذا السؤال بسبب حقيقة أن لدينا 27 واجهة خلفية لـ SSH و 18 واجهة أمامية HAProxy (16 مفتاحًا رئيسيًا و 2 بديل بديل) ، بالإضافة إلى حقيقة أن الواجهات الأمامية لا تنسق مع بعضها البعض فيما يتعلق بسرعة معالجة الطلب . بالإضافة إلى ذلك ، كان علينا أن نأخذ في الاعتبار المدة التي تستغرقها خطوة المصادقة الخاصة بجلسة SSH الجديدة. لنفترض أن القيمة الأولى لـ
MaxStartups هي 150. هذا يعني أنه إذا
MaxStartups مرحلة المصادقة ثانيتين ، فيمكننا نقل كل جلسة خلفية فقط 75 جلسة جديدة في الثانية.
هنا يمكنك العثور على تفاصيل حول حساب قيمة
rate-limit sessions ، ولن أخوض في التفاصيل هنا. ألاحظ فقط أنه من أجل حساب هذه القيمة ، يجب أخذ أربعة معلمات في الاعتبار. الأول والثاني هو عدد الخوادم من كلا النوعين. والثالث هو قيمة
MaxStartups . الرابع هو
T - كم من الوقت يستغرق لمصادقة جلسة SSH. قيمة
T مهمة للغاية ، ولكن لا يمكن استنتاجها إلا تقريبًا. لقد فعلنا ذلك تمامًا ، وتركنا النتيجة في ثانيتين. نتيجة لذلك ، حصلنا على قيمة
rate-limit للنهايات الأمامية ، والتي بلغت 112.5. قمنا بتقريبه إلى 110.
والآن ، دخلت الإعدادات الجديدة حيز التنفيذ. ربما تعتقد أنه بعد كل هذا انتهى بسعادة؟ يجب أن يكون ذلك هو أن عدد الأخطاء هرع إلى الصفر والجميع كان سعيدا للغاية؟ حسنا ، في الواقع كان بعيدا عن جيد جدا. لم ينتج عن هذا التغيير أي تغييرات مرئية في معدل الخطأ. بصراحة ، كنت مستاء جدا. لقد فاتنا شيء مهم أو أسيء فهم جوهر المشكلة.
نتيجة لذلك ، عدنا إلى السجلات (وأخيراً ، إلى معلومات HAProxy) وتمكنا من التأكد من أن الحد الأقصى لسرعة معالجة الاستعلام يعمل على الأقل من خلال العمل على الاستعلامات كما توقعنا. في السابق ، كانت المؤشرات المقابلة أعلى ، مما سمح لنا باستنتاج أننا نجحنا في الحد من السرعة التي يتم بها إرسال الطلبات الواردة للمعالجة. لكن كان من الواضح أن معدل وصول الطلبات لا يزال مرتفعًا للغاية. على الرغم من أنه كان من الواضح أيضًا أنه لم يقترب حتى من تلك المستويات عندما يمكن أن يكون له تأثير ملحوظ على النظام. عندما قمنا بتحليل عملية اختيار الخلفية (وفقًا لسجلات HAProxy) ، لاحظنا غرابة واحدة هناك. في بداية الساعة ، تم توزيع الاتصالات الخلفية بشكل غير متساو عبر خوادم SSH. في الفترة الزمنية التي تم اختيارها للتحليل ، تراوح عدد الاتصالات في الثانية على خوادم مختلفة من 30 إلى 121. وهذا يعني أن موازنة التحميل لدينا لم تؤدي وظيفتها بشكل جيد. أظهر تحليل التكوين أننا استخدمنا خيار
balance source ، بحيث يتصل العميل الذي يحمل عنوان IP محدد دائمًا بنفس الواجهة الخلفية. يمكن اعتبار هذا ظاهرة إيجابية في الحالات التي تكون هناك حاجة ملزمة للجلسة. لكننا نتعامل مع SSH ، لذلك نحن لسنا بحاجة إلى هذا. تمت تهيئة هذا الخيار من قبلنا ، لكننا لم نعثر على أي تلميحات حول سبب ذلك. لم نتمكن من العثور على سبب وجيه لمواصلة استخدامه. نتيجة لذلك ، قررنا التبديل إلى
leastconn . بفضل هذا الخيار ، توفر الاتصالات الواردة الجديدة واجهات مع الحد الأدنى لعدد الاتصالات الحالية. أثر هذا على استخدام موارد المعالج من خلال خوادم SSH (Git) الخاصة بنا. هنا هو الجدول الزمني المقابل.
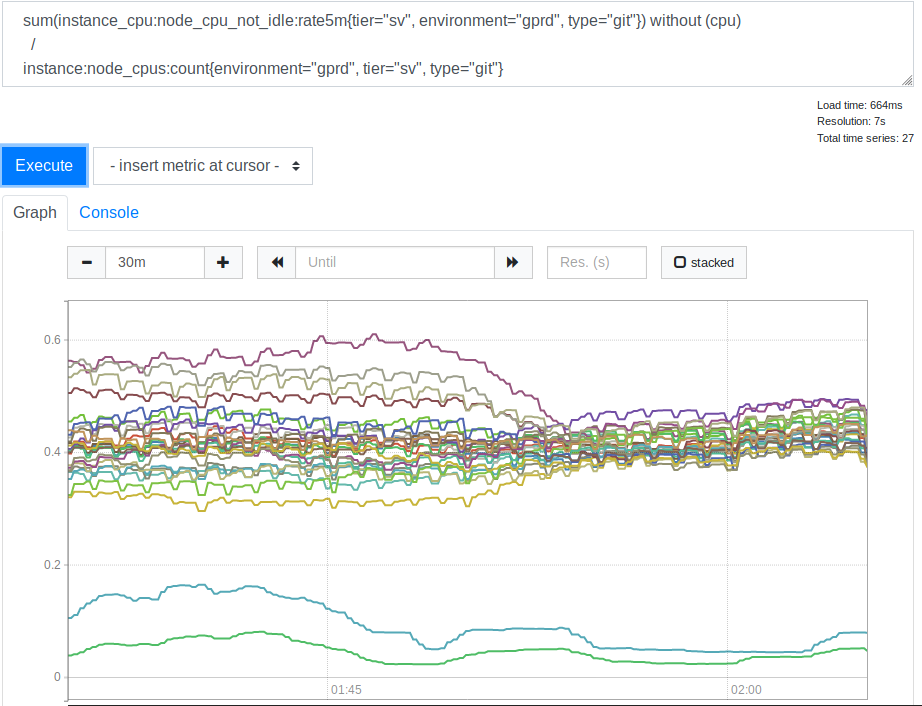 استهلاك وحدة المعالجة المركزية بواسطة الخوادم قبل وبعد تطبيق الخيار الأقل
استهلاك وحدة المعالجة المركزية بواسطة الخوادم قبل وبعد تطبيق الخيار الأقلبعد أن رأينا هذا ، أدركنا أن استخدام
leastconn هو فكرة جيدة. الخطان الموجودان أسفل الرسم البياني هما خوادم Canary الخاصة بنا ، ويمكنك تجاهلهما. ولكن قبل ذلك ، كان انتشار قيم تحميل وحدة المعالجة المركزية لخوادم مختلفة مرتبطًا بنسبة 2: 1 (من 30٪ إلى 60٪). هذا يشير بوضوح إلى أنه في وقت سابق تم تحميل بعض من خلفياتنا أكثر من غيرها بسبب اتصال العملاء بهم. لقد كانت مفاجأة لي. يبدو من المعقول توقع أن مجموعة واسعة من عناوين IP للعميل كانت كافية لتحميل خوادمنا بشكل أكثر توازنا. ولكن ، على ما يبدو ، من أجل تشويه مؤشرات تحميل الخادم ، كان العديد من العملاء الكبار كافيين ، يختلف سلوكه عن خيار متوسط.
الدرس رقم 4. عند تحديد إعدادات محددة تختلف عن الإعدادات الافتراضية ، قم بالتعليق عليها أو اترك رابطًا للمواد التي تشرح التغييرات. أي شخص سيتعين عليه التعامل مع هذه الإعدادات في المستقبل سيكون ممتنًا لك على ذلك.
هذه الشفافية هي
واحدة من القيم الأساسية لجيتلاب .
تمكين الخيار
leastconn ساعد أيضًا في تقليل مستويات الخطأ. وهذا بالضبط ما كنا نسعى إليه. لذلك ، قررنا ترك هذا الخيار. لكن مع الاستمرار في التجربة ، قاموا بتخفيض مستوى حدود سرعة معالجة الطلبات إلى 100 ، مما ساعد على زيادة تقليل مستوى الأخطاء. يشير هذا إلى أن التحديد الأولي لقيمة
T قد تم إجراؤه بشكل غير صحيح. لكن إذا كان الأمر كذلك ، فإن هذا المؤشر كان صغيراً للغاية ، مما أدى إلى وجود حد قوي للسرعة ، وحتى 100 طلب في الثانية كان ينظر إليها على أنها قيمة منخفضة للغاية ، ولم نكن مستعدين لتقليصها. لسوء الحظ ، لسبب داخلي ، كان هذان التغييران مجرد تجربة. كان علينا العودة إلى استخدام خيار
balance source وقصر سرعة معالجة الطلبات على 100 طلب في الثانية.
نظرًا لتعيين سرعة معالجة الاستعلام على مستوى منخفض يناسبنا ، وأنه لا يمكننا استخدام
leastconn ، فقد حاولنا زيادة معلمة
MaxStartups . في البداية قمنا بزيادة الرقم إلى 200 ، وهذا أعطى بعض التأثير. ثم - ما يصل إلى 250. اختفت الأخطاء بالكامل تقريبًا ولم يحدث شيء سيء.
الدرس رقم 5. على الرغم من أن MaxStartups العالية قد تبدو مرعبة ، إلا أن تأثيرها ضئيل جدًا على الأداء حتى عندما تكون أعلى بكثير من القيم الافتراضية.
ربما يكون هذا بمثابة رافعة كبيرة وقوية ، يمكننا استخدامها ، إذا لزم الأمر ، في المستقبل. ربما سنواجه مشكلات إذا كنا نتحدث عن شخصيات في المنطقة من عدة آلاف أو عدة عشرات الآلاف ، لكننا لا نزال بعيدين عن ذلك.
ماذا يقول هذا عن تقديري للمعلمة
T ، الوقت الذي يستغرقه تثبيت جلسة SSH والمصادقة عليها؟ إذا كنت تعمل مع الصيغة لحساب مؤشر الحد الأقصى لسرعة معالجة الاتصال ، مع العلم أن 200 ليست كافية لمؤشر
MaxStartups ، و 250 كافية ، يمكنك معرفة أن
T لها على الأرجح قيمة من 2.7 إلى 3.4 ثانية. كنتيجة لذلك ، لم تكن القيمة المقدرة للثواني بعيدة عن الحقيقة ، ولكن القيمة الحقيقية ، بالطبع ، كانت أعلى من المتوقع. سوف نعود إلى هذا في وقت لاحق قليلا.
الخطوات النهائية
نظرنا مرة أخرى في السجلات ، مع الأخذ في الاعتبار ما عرفناه بالفعل ، وبعد بعض التفكير ، اكتشفنا أن المشكلة التي بدأت بها كلها يمكن تحديدها من خلال العلامات التالية. أولاً ، هذه قيمة
t_state تساوي
SD . ثانياً ، هذه هي قيمة
b_read (وحدات البايت التي يقرأها العميل) ، تساوي 0. كما ذكرنا سابقًا ، نعالج ما يقرب من 26 إلى 28 مليون اتصال SSH يوميًا. كان من غير السار أن نعلم أنه ، في خضم الكارثة ، ما يقرب من 1.5 ٪ من هذه الروابط قد تم كسرها بشكل كبير. من الواضح أن حجم المشكلة كان أكبر بكثير مما كنا نعتقد في البداية. علاوة على ذلك ، لم يكن هناك شيء لم نتمكن من اكتشافه مسبقًا (حتى عندما أدركنا أن
t_state="SD" أشار إلى المشكلة في السجلات) ، لكننا لم نفكر في كيفية القيام بذلك ، على الرغم من أننا ويجب أن تفكر في ذلك. ربما بسبب هذا ، قضينا وقتًا وجهدًا أكبر بكثير في حل المشكلة أكثر مما كان يمكن أن ننفقه.
الدرس رقم 6. قياس مستويات الخطأ الحقيقي في أقرب وقت ممكن.
إذا كنا ندرك في البداية مدى المشكلة ، فبإمكاننا الاهتمام بها. على الرغم من أن كيفية إدراكها ، لا تزال تعتمد على معرفة الخصائص التي تسمح لنا بوصف المشكلات.
إذا تحدثنا عن المزايا التي ظهرت بعد زيادة قيم
MaxStartups وضبط سرعة معالجة الطلبات ، يمكننا القول أن مستوى الخطأ انخفض إلى 0.001 ٪. هذا هو - ما يصل إلى عدة آلاف في اليوم. بدا هذا الموقف أفضل بكثير ، لكن مستوى مماثل من الأخطاء كان لا يزال أعلى من المستوى الذي نود الوصول إليه. بعد أن توصلنا إلى بعض الأشياء ، تمكنا مرة أخرى من استخدام خيار
leastconn الأخطاء تمامًا. بعد ذلك ، تمكنا من تنفس الصعداء.
العمل في المستقبل
من الواضح أن مرحلة مصادقة SSH لا تزال تستغرق الكثير من الوقت. ربما تصل إلى 3.4 ثانية. يمكن لـ GitLab استخدام
AuthorizedKeysCommand للبحث مباشرة عن مفتاح SSH في قاعدة بيانات. هذا مهم للغاية للعمليات السريعة عندما يكون هناك عدد كبير من المستخدمين. بخلاف ذلك ، يحتاج SSHD إلى قراءة ملف مفاتيح
authorized_keys كبير جدًا بالتتابع للعثور على المفتاح العمومي للمستخدم. هذه المهمة لا تتوسع بشكل جيد. قمنا بتنفيذ بحث باستخدام قدر معين من كود Ruby الذي يقوم بإجراء مكالمات على واجهة برمجة تطبيقات HTTP خارجية.
اكتشف ستان هيو ، رئيس قسم الهندسة لدينا ومصدر لا ينضب للمعرفة على GitLab ، أن مثيلات يونيكورن لخوادم Git / SSH تخضع للتحميل المستمر من الطلبات المقدمة إليها. هذا يمكن أن يقدم مساهمة كبيرة في الثواني الثلاث المطلوبة لمصادقة الطلبات. نتيجةً لذلك ، أدركنا أنه ينبغي لنا في المستقبل التحقيق في هذه المشكلة. ربما سنزيد عدد مثيلات Unicorn (أو Puma) على هذه العقد حتى لا تضطر خوادم SSH إلى الانتظار للوصول إليها. ومع ذلك ، هناك بعض المخاطر هنا ، لذلك يجب أن نكون حذرين وأن ننتبه إلى جمع وتحليل مؤشرات النظام. يستمر العمل على الإنتاجية ، ولكن الآن ، وبعد حل المشكلة الرئيسية ، تسير الأمور ببطء. قد نكون قادرين على تقليل قيمة
MaxStartups ، ولكن بما أن مستواها العالي لا يخلق التأثير السلبي على النظام الذي يبدو أنه
MaxStartups ، فإن هذا ليس ضروريًا بشكل خاص. سيكون من الأسهل على الجميع أن يعيشوا إذا كان بإمكان OpenSSH في أي وقت إخبارنا بمدى
MaxStartups من حدود
MaxStartups . سيكون من الأفضل أن نكون دائمًا على دراية. هذا هو أجمل بكثير من معرفة أن يتم تجاوز الحدود عند مواجهة اتصالات مقطوعة.
بالإضافة إلى ذلك ، نحتاج إلى نوع من نظام الإشعارات عندما تظهر إدخالات سجل HAProxy ، مما يشير إلى وجود مشكلة في الاتصالات التي تم قطع اتصالها. والحقيقة هي أن هذا ، في الممارسة العملية ، لا ينبغي أن يحدث على الإطلاق. إذا حدث هذا مرة أخرى ، فسوف نحتاج إلى زيادة قيم
MaxStartups ، أو إذا واجهنا نقصًا في الموارد ، فسوف نحتاج إلى إضافة المزيد من العقد Git / SSH إلى النظام.
النتائج
أجزاء من النظم المعقدة تتفاعل في أنماط معقدة. وفيها ، لحل المشاكل المختلفة ، يمكن للمرء أن يجد في كثير من الأحيان بعيدا عن "رافعة" واحدة. عند التعامل مع مثل هذه الأنظمة ، من المفيد معرفة الأدوات الموجودة فيها. الحقيقة هي أنهم جميعا لديهم إيجابيات وسلبيات. بالإضافة إلى ذلك ، تجدر الإشارة إلى أنه قد يكون من المخاطرة إجراء إعدادات معينة بناءً على الافتراضات والقيم المقدرة. الآن ، وبالنظر إلى المسار الذي قطعناه ، سأحاول أن أقيس بدقة أكبر قدر ممكن من الوقت اللازم لإكمال مصادقة الطلب ، والذي سيؤدي إلى القيمة التقريبية لـ
T التي استخلصتها ستكون أقرب إلى الحقيقة.
لكن الدرس الرئيسي الذي تعلمناه من كل هذا هو أنه عندما يخطط الكثير من الأشخاص للمهام بناءً على بعض المقاييس الزمنية اللطيفة ، فإن هذا ، بالنسبة لمقدمي الخدمات المركزيين مثل GitLab ، يؤدي إلى مشاكل غير عادية في التوسع.
إذا كنت أحد أولئك الذين يستخدمون أدوات تشغيل المهام المجدولة ، فقد تحتاج إلى التفكير في إعداد الوقت اللازم لبدء مهامك بطريقة جديدة. على سبيل المثال ، يمكنك جعل المهام "تغفو" لفترة من الوقت ، وتبدأ في العمل بعد 30 ثانية فقط من الإطلاق. يمكنك ، على سبيل المثال ، الإشارة إلى أوقات عشوائية خلال الساعة في جدول بدء المهمة (هنا يمكنك إضافة وقت انتظار عشوائي قبل التنفيذ الفعلي للمهمة). هذا سوف يساعدنا جميعًا في الحرب ضد طغيان الساعات.
أعزائي القراء! هل واجهت مشاكل مشابهة لتلك التي تم تخصيص هذه القصة لها؟
