المادة ، الجزء الأول من الترجمة التي ننشرها اليوم ، مكرسة لمشكلة واسعة النطاق نشأت في gitlab.com. هنا سنتحدث عن كيفية العثور عليها ، وكيف قاتلوا معها ، وكيف ، في النهاية ، حلوها. بالإضافة إلى ذلك ، في مواجهة هذه المشكلة ، اكتشف فريق gitlab.com ما هو طغيان الساعات.

→
الجزء الثاني .
المشكلة
بدأنا في تلقي رسائل من العملاء ، عند العمل مع gitlab.com ، فإنها تواجه أخطاء بشكل دوري عند تنفيذ طلبات السحب. عادةً ما تحدث الأخطاء عند تنفيذ مهام CI أو أثناء تشغيل الأنظمة الآلية الأخرى المشابهة. تبدو رسائل الخطأ كالتالي:
ssh_exchange_identification: connection closed by remote host fatal: Could not read from remote repository
ومما زاد الموقف تعقيدًا أن رسائل الخطأ ظهرت بشكل غير منتظم ، كما يبدو ، بشكل غير متوقع. لم نتمكن من إعادة إنتاجها حسب الرغبة ، ولم نتمكن من تحديد أي علامة واضحة على ما كان يحدث على الرسوم البيانية أو في السجلات. رسائل الخطأ نفسها لم تجلب الكثير من الفوائد سواء. تم إبلاغ عميل SSH بأنه قد تمت مقاطعة الاتصال ، ولكن السبب في ذلك قد يكون أي شيء: عميل فاشل أو جهاز ظاهري غير مستقر أو جدار حماية لا نتحكم فيه أو إجراءات موفر غريبة أو مشكلة في طلبنا.
نحن ، في إطار برنامج GIT-over-SSH ، نتعامل مع عدد كبير جدًا من الاتصالات - حوالي 26 مليون اتصال يوميًا. هذا متوسط 300 اتصال في الثانية. لذلك ، تعد محاولة تحديد عدد صغير من الاتصالات الفاشلة من دفق البيانات الحالية بمهمة صعبة. كان الشيء الجيد في هذا الموقف هو أننا نحب حل المشكلات المعقدة.
الفكرة الأولى
اتصلنا بأحد عملائنا (بفضل Hubert Holtz من Atalanda) ، الذي واجه مشكلة عدة مرات في اليوم. هذا أعطانا موطئ قدم. كان Hubert قادرًا على تزويدنا بعنوان IP عام مناسب. هذا يعني أنه يمكننا التقاط الحزم على العقد الأمامية HAProxy الخاصة بنا لمحاولة عزل المشكلة عن طريق الاعتماد على مجموعة بيانات أقل من ما يمكن تسميته "جميع زيارات SSH". حتى أفضل ، استخدمت الشركة
منفذ بديل ssh . هذا يعني أننا كنا بحاجة إلى تحليل الوضع على خادمي HAProxy فقط ، وليس على ستة عشر.
تحليل الحزم ، ومع ذلك ، لم يكن متعة خاصة. على الرغم من القيود في حوالي 6.5 ساعة ، تم جمع حوالي 500 ميغا بايت حزم. وجدنا مركبات قصيرة العمر. تم إنشاء اتصال TCP ، أرسل العميل المعرف ، وبعد ذلك تم قطع اتصال خادم HAProxy الخاص بنا على الفور باستخدام تسلسل TCP FIN الصحيح. نتيجة لذلك ، كان لدينا تحت تصرفنا أول فكرة ممتازة. سمحت لنا أن نستنتج أنه تم إغلاق الاتصال بالتأكيد بمبادرة gitlab.com ، وليس بسبب شيء بيننا وبين العميل. هذا يعني أننا واجهنا مشكلة يمكننا التحقيق فيها وتصحيحها.
الدرس رقم 1. تحتوي قائمة الإحصائيات الخاصة بأداة Wireshark على الكثير من الأدوات المفيدة التي لم أكن أولي اهتمامًا بها قبل هذه الحالة.
على وجه الخصوص ، نحن نتحدث عن عنصر قائمة
Conversations ، والذي يمكنه عرض المعلومات الأساسية عن البيانات الملتقطة حول اتصالات TCP. هناك معلومات حول الوقت والحزم والبايت. يمكن فرز البيانات المعروضة في النافذة المقابلة. يجب أن استخدم هذه الأداة من البداية بدلاً من العبث يدويًا بالبيانات الملتقطة. ثم أدركت أنني بحاجة للبحث عن اتصالات مع عدد صغير من الحزم. سمحت لك نافذة
Conversations بالاهتمام بهم على الفور. بعد ذلك ، تمكنت من العثور على مركبات أخرى مماثلة والتأكد من أن الاتصال الأول لم يكن ظاهرة غير طبيعية.
سجل الانغماس
ما الذي تسبب في قطع HAProxy عن العميل؟ الخادم ، بالطبع ، لم يفعل ذلك بطريقة تعسفية ؛ فما كان يحدث كان يجب أن يكون له سبب أعمق ؛ إذا كنت تحب - "مستوى آخر من
السلاحف ". كان هناك شعور بأن الهدف التالي من الدراسة يجب أن يكون سجلات HAProxy. تم تخزين سجلاتنا في برنامج GCP BigQuery. هذا مناسب ، نظرًا لأن لدينا الكثير من السجلات ، ونحن بحاجة إلى تحليلها بشكل شامل. لكن أولاً ، تمكنا من تحديد إدخال السجل لأحد الحوادث ، والذي تم العثور عليه في الحزم التي تم التقاطها. اعتمدنا على الوقت وعلى منفذ TCP ، الذي كان إنجازًا كبيرًا في دراستنا. كانت التفاصيل الأكثر إثارة للاهتمام في السجل الذي تم العثور عليه هي
t_state (حالة الإنهاء) ، والتي كان لها قيمة
SD . فيما يلي مقتطف من وثائق HAProxy:
S: , . D: DATA.
وأوضح معنى معنى
D ببساطة شديدة. تم تأسيس اتصال TCP بشكل صحيح ، تم إرسال البيانات. تزامن هذا مع الأدلة التي تم الحصول عليها من الحزم التي تم التقاطها. تعني قيمة
S أن HAProxy استلمت رسالة إخفاق RST أو ICMP من الواجهة الخلفية. لكن لم نتمكن من العثور على فكرة على الفور عن سبب حدوث ذلك. قد يكون سبب ذلك أي شيء - من شبكة غير مستقرة (على سبيل المثال ، عطل أو ازدحام) إلى مشكلة على مستوى التطبيق. باستخدام BigQuery لتجميع البيانات على Git backends ، اكتشفنا أن المشكلة ليست مرتبطة بأي جهاز ظاهري معين. نحن بحاجة إلى مزيد من المعلومات.
أريد أن أشير إلى أن إدخالات السجل التي لها قيمة
SD لم تكن شيئًا خاصًا ومميزًا لمشكلتنا فقط. على المنفذ البديل - ssh ، تلقينا العديد من الطلبات بخصوص المسح الضوئي لـ HTTPS. أدى هذا إلى حقيقة أن قيمة
SD سقطت في السجلات عندما رأى خادم SSH رسالة
TLS ClientHello بينما كان يتوقع تلقي تحية SSH. هذا أدى لفترة وجيزة التحقيق لدينا بطريقة ملتوية.
بعد التقاط بعض حركة المرور بين HAProxy وخادم Git واستخدام أدوات Wireshark مرة أخرى ، اكتشفنا بسرعة أن SSHD على خادم Git ينفصل عن TCP FIN-ACK مباشرة بعد المصافحة الثلاثية TCP. لا يزال HAProxy لم يرسل حزمة البيانات الأولى ، ولكنه كان على وشك القيام بذلك. عندما أرسل الحزمة ، أجابه خادم Git بـ TCP RST. نتيجة لذلك - اكتشفنا الآن سبب كتابة HAProxy للسجلات حول فشل الاتصال مع قيمة
SD . أغلقت SSH الاتصال وفعلت ذلك عن قصد وبشكل صحيح ، وكان RST مجرد قطعة أثرية من حقيقة أن خادم SSH تلقى الحزمة بعد FIN-ACK. هذا لا يعني شيئا أكثر.
جدول بليغ
عند النظر في السجلات ذات قيم
SD في BigQuery وتحليلها ، أدركنا أن الأخطاء لها علاقة واضحة بالوقت. وهي وجدنا قمم في عدد الاتصالات الفاشلة خلال أول 10 ثوان من كل دقيقة. وقد لوحظ لمدة 5-6 ثواني.
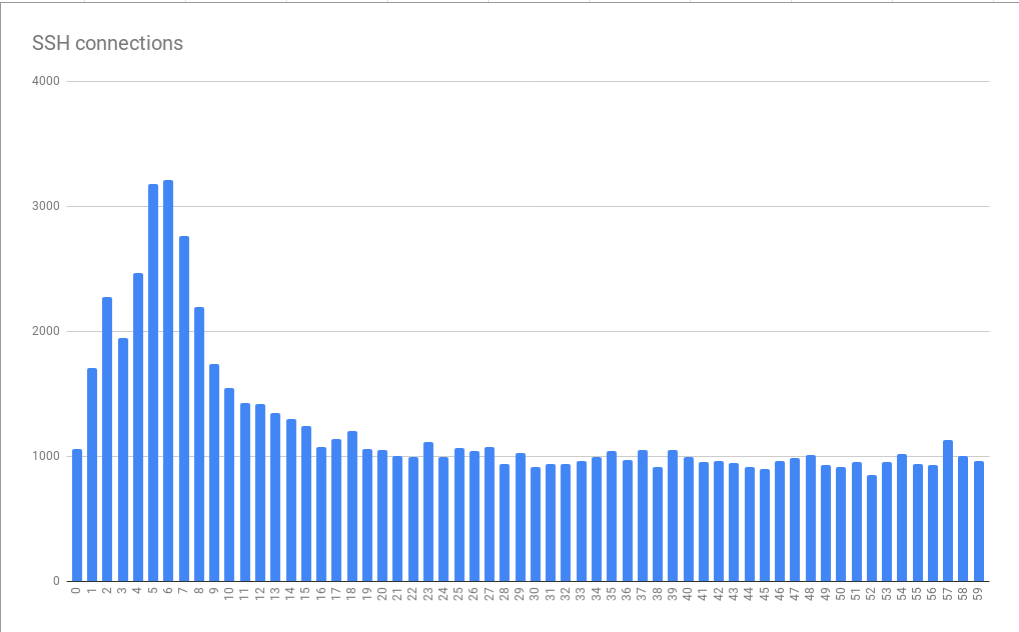 أخطاء الاتصال مجمعة في غضون دقائق إلى ثوان
أخطاء الاتصال مجمعة في غضون دقائق إلى ثوانيعتمد هذا المخطط على البيانات التي تم جمعها على مدار ساعات عديدة. تشير حقيقة أن نمط توزيع الخطأ الذي تم اكتشافه إلى أنه مستقر يشير إلى أن سبب الأخطاء يظهر بثبات في غضون دقائق وساعات فردية ، وربما أسوأ من ذلك ، فإنه يظهر بشكل ثابت في أوقات مختلفة من اليوم. من المثير جدًا أن يكون متوسط حجم الذروة أكبر بثلاثة أضعاف من الحمل الأساسي. هذا يعني أننا واجهنا مشكلة غير تافهة في التوسع. ونتيجة لذلك ، فإن ربط "مزيد من الموارد" في شكل أجهزة افتراضية إضافية ، مصممة لمساعدتنا على مواجهة أحمال الذروة ، يمكن أن يكون مكلفًا نظريًا. هذا يشير أيضًا إلى أننا نصل إلى نوع من القيود الشديدة. نتيجة لذلك ، تلقينا الدليل الأول حول المشكلة النظامية الأساسية التي تسبب أخطاء. دعوتها طغيان ساعات.
غالبًا ما لا يختلف Cron أو أنظمة الجدولة المشابهة في القدرة على تخصيص تنفيذ المهام إلى أقرب ثانية. إذا كانت هذه الأنظمة لديها مثل هذه القدرات ، فلن يتم استخدامها في كثير من الأحيان بسبب حقيقة أن الناس يفضلون النظر في الوقت ، مقسمة إلى فواصل زمنية ، يعبر عنها بأرقام دائرية جميلة. نتيجة لذلك ، تبدأ المهام في بداية دقيقة أو ساعة ، أو في لحظات أخرى مماثلة. إذا كانت المهام تحتاج إلى بضع ثوان لإعداد أمر
git fetch لتنزيل المواد من gitlab.com ، فقد يفسر ذلك النمط الذي وجدناه عندما يزداد التحميل على النظام بشكل حاد لعدة ثوانٍ كل دقيقة. في مثل هذه اللحظات ، يزداد عدد الأخطاء.
الدرس رقم 2. يستخدم الكثير من الأشخاص ، على ما يبدو ، تزامن الوقت الذي تم تكوينه بشكل صحيح (عبر NTP أو باستخدام آليات أخرى).
إذا لم يكن هناك وقت متزامن ، فلن تظهر مشكلتنا بوضوح. مساء الخير ، NTP!
ولكن ما الذي يجعل SSH لقطع الاتصال؟
أقرب إلى جوهر المشكلة
دراسة وثائق SSHD ، اكتشفنا المعلمة
MaxStartups . يتحكم في الحد الأقصى لعدد الاتصالات غير المصادقة. يبدو من المعقول أن حد الاتصال قد تم استنفاده عندما يتعرض النظام في بداية الدقيقة للحمل الناتج عن مجموعة من المكالمات للمهام المجدولة من جميع أنحاء الإنترنت. تتكون المعلمة
MaxStartups من ثلاثة أرقام. الأول هو الحد الأدنى (عدد الاتصالات عند الوصول إلى أي فواصل في الاتصالات تبدأ). والثاني هو النسبة المئوية للمركبات التي تتجاوز الحد الأدنى للمركبات التي تحتاج إلى كسرها بشكل عشوائي. القيمة الثالثة هي الحد الأقصى المطلق لعدد الاتصالات ، وبعد ذلك يتم رفض جميع الاتصالات الجديدة. تبدو القيمة الافتراضية لـ MaxStartups 10: 30: 100 ، ثم تبدو إعداداتنا مثل 100: 30: 200. يشير هذا إلى أننا في الماضي قمنا بزيادة حدود الاتصال القياسية. ربما - حان الوقت لرفعها مرة أخرى.
اتضح أنه من غير
MaxStartups قليلاً أنه منذ أن تم تثبيت OpenSSH 7.2 على خوادمنا ، فإن الطريقة الوحيدة لرؤية الحدود الموضوعة في
MaxStartups هي التبديل إلى مستوى
Debug الأخطاء. مع هذا النهج ، يقع سيل من البيانات في السجلات. لذلك ، قمنا بتشغيل هذا الوضع لفترة وجيزة على أحد الخوادم. لحسن الحظ ، بعد دقيقتين ، أصبح من الواضح أن عدد الاتصالات تجاوز الحدود المحددة في
MaxStartups ، ونتيجة لذلك حدث انقطاع مبكر.
اتضح أنه في OpenSSH 7.6 (هذا الإصدار يأتي مع Ubuntu 18.04) يتم تنظيم نهج أكثر ملاءمة لتسجيل ما يتعلق
MaxStartups . هنا تحتاج فقط إلى التبديل إلى وضع التسجيل
Verbose . على الرغم من أنها ليست مثالية ، إلا أنها لا تزال أفضل من التبديل إلى مستوى
Debug .
الدرس رقم 3. يعتبر كتابة معلومات مفيدة للسجلات بمستويات التسجيل القياسية أمرًا جيدًا ، وتعتبر المعلومات المتعلقة بفصل مقصود لأي سبب من الأسباب مثيرة للاهتمام بالتأكيد لمسؤولي النظام.
الآن وقد اكتشفنا سبب المشكلة ، نشأ سؤال حول كيفية حلها. يمكننا زيادة القيم في معلمة
MaxStartups ، ولكن ما الذي
MaxStartups ذلك؟ بالتأكيد ، سيتطلب ذلك القليل من الذاكرة الإضافية ، لكن هل سيؤدي ذلك إلى أي عواقب سلبية في الأجزاء التي يتم فيها معالجة الطلبات؟ يمكننا التفكير في الأمر فقط ، لذلك قررنا اتخاذ إعدادات
MaxStartups الجديدة
MaxStartups . وهي تبادلناهم لما يلي: 150: 30: 300. في السابق ، بدوا مثل 100: 30: 200 ، وهذا هو - قمنا بزيادة عدد الاتصالات بنسبة 50 ٪. كان لهذا تأثير إيجابي قوي على النظام. في الوقت نفسه ، لم يتم ملاحظة بعض الآثار السلبية ، مثل زيادة الحمل على المعالجات.
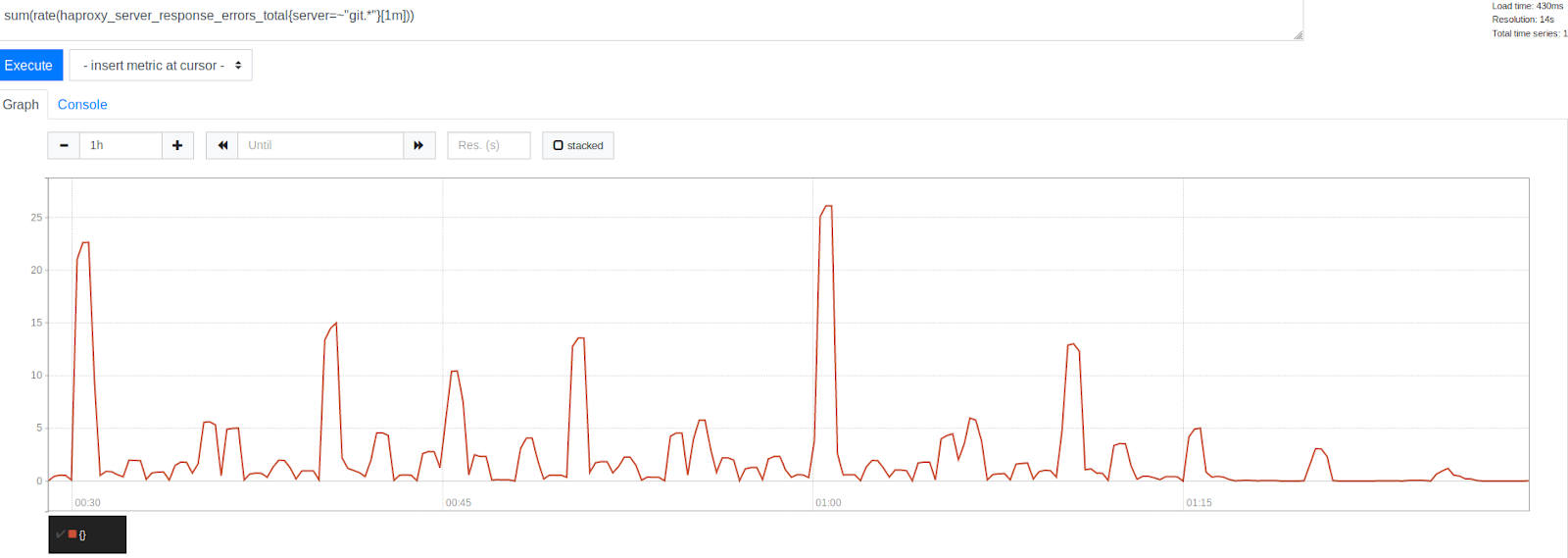 عدد الأخطاء قبل وبعد زيادة MaxStartups بنسبة 50 ٪
عدد الأخطاء قبل وبعد زيادة MaxStartups بنسبة 50 ٪لاحظ انخفاض كبير في الأخطاء بعد الطابع الزمني 1:15. يشير هذا بوضوح إلى أننا تمكنا من التخلص من جزء كبير من الأخطاء ، على الرغم من أن بعضها ما زال موجودًا. من المثير للاهتمام أن نلاحظ أن الأخطاء مجمعة حول طوابع زمنية ممثلة بأرقام دائرية جميلة. هذه هي بداية الساعة ، كل 30 و 15 و 10 دقائق. مما لا شك فيه ، استمر طغيان الساعة. في بداية كل ساعة ، يتم ملاحظة أعلى قمة للأخطاء. هذا ، بالنظر إلى ما توصلنا إليه بالفعل ، يبدو مفهوما تماما. يخطط الكثير من الأشخاص لتشغيل المهام كل ساعة يتم تشغيلها بعد 0 دقيقة من بداية الساعة. أكدت هذه الحقيقة نظريتنا أن ذروة الخطأ ناتجة عن إطلاق المهام المجدولة. يشير هذا إلى أننا كنا على المسار الصحيح في حل المشكلة عن طريق ضبط حدود النظام.
من دواعي سرورنا أن تغيير حد
MaxStartups يؤد إلى تأثيرات سلبية ملحوظة. ظل استخدام وحدة المعالجة المركزية على خوادم SSH عند نفس المستوى كما كان من قبل ، ولم يزداد الحمل على أنظمتنا أيضًا. لقد كان لطيفًا جدًا ، مع الأخذ في الاعتبار أننا قبلنا الآن المزيد من الاتصالات ، من تلك التي كانت ستنقطع ببساطة من قبل. بالإضافة إلى ذلك ، لم يتفاقم الوضع بسبب قيامنا بذلك في وقت كانت فيه أنظمتنا محملة بشكل كبير. بدا كل شيء واعدا.
أن تستمر ...
أعزائي القراء! ما الأدوات التي تستخدمها لتحليل حركة المرور والسجلات؟
