مرحباً هبر.
بعد تجربة قاعدة بيانات مشهورة مكونة من 60000 رقم مكتوب بخط اليد ، MNIST ، ظهر السؤال المنطقي حول ما إذا كان هناك شيء مشابه ، ولكن مع دعم ليس فقط للأرقام ، ولكن أيضًا للأحرف. كما اتضح ، فهناك ، وتسمى هذه القاعدة ، كما قد تتصور ، Extended MNIST (EMNIST).
إذا كان أي شخص مهتمًا بكيفية استخدام قاعدة البيانات هذه ، فيمكنك التعرف على نص بسيط ، مرحبًا بك في cat.
 ملاحظة
ملاحظة : هذا المثال تجريبي وتعليمي ، كنت مهتمًا فقط برؤية ما يأتي منه. لم أخطط ولا أخطط للقيام ببرنامج FineReader الثاني ، فالكثير من الأشياء هنا ، بالطبع ، لم يتم تنفيذها. لذلك ، لا يتم قبول المطالبات في أسلوب "لماذا" ، "بالفعل أفضل" ، إلخ. من المحتمل وجود مكتبات OCR جاهزة لبايثون بالفعل ، ولكن كان من المثير للاهتمام أن تفعل ذلك بنفسك. بالمناسبة ، بالنسبة لأولئك الذين يرغبون في معرفة كيفية عمل FineReader الحقيقي ، هناك مقالتان على مدونة Habré الخاصة بهم لعام 2014:
1 و
2 (ولكن بالطبع ، بدون أكواد المصدر والتفاصيل ، كما في أي مدونة للشركات). حسنًا ، لنبدأ ، كل شيء مفتوح هنا وكل شيء مفتوح المصدر.
على سبيل المثال سنأخذ النص العادي. هنا واحد:
مرحبا العالم
ودعونا نرى ما الذي يمكن عمله به.
تقسيم النص إلى حروف
الخطوة الأولى هي تقسيم النص إلى حروف منفصلة. يعد OpenCV مفيدًا لهذا ، على نحو أكثر دقة وظيفة findContours الخاصة به.
افتح الصورة (cv2.imread) ، وقم بترجمتها إلى b / w (cv2.cvtColor + cv2.threshold) ، قم بزيادة قليلاً (cv2.erode) وابحث عن الخطوط العريضة.
image_file = "text.png" img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
نحصل على شجرة معالم ذات تسلسل هرمي (المعلمة cv2.RETR_TREE). أولاً ، الخطوط العريضة العامة للصورة ، ثم الخطوط العريضة للأحرف ، ثم الخطوط العريضة الداخلية. نحن بحاجة فقط إلى الخطوط العريضة للرسائل ، لذلك أتحقق من أن "المخطط" هو المخطط العام. هذا أسلوب مبسط ، وقد لا ينجح هذا في عمليات الفحص الحقيقية ، على الرغم من أنه ليس من الضروري التعرف على لقطات الشاشة.
النتيجة:
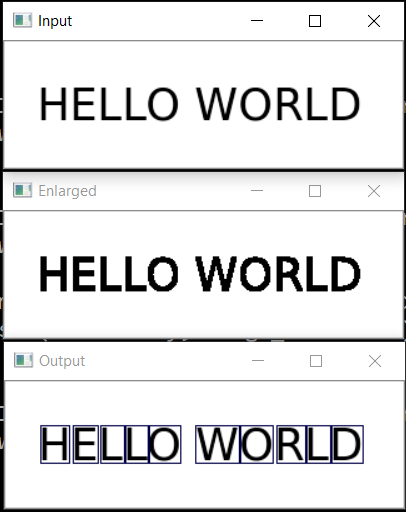
والخطوة التالية هي حفظ كل حرف ، بعد تغيير حجمه مسبقًا إلى مربع 28 × 28 (في هذا التنسيق يتم تخزين قاعدة بيانات MNIST). تم تصميم OpenCV على أساس numpy ، حتى نتمكن من استخدام وظائف العمل مع صفائف للمحاصيل والقياس.
def letters_extract(image_file: str, out_size=28) -> List[Any]: img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
في النهاية ، نقوم بتصنيف الحروف حسب إحداثي X ، تمامًا كما ترى ، نحفظ النتائج في شكل tuple (x ، w ، letter) ، بحيث يمكن تحديد المسافات من المسافات بين الحروف.
تأكد من أن كل شيء يعمل:
cv2.imshow("0", letters[0][2]) cv2.imshow("1", letters[1][2]) cv2.imshow("2", letters[2][2]) cv2.imshow("3", letters[3][2]) cv2.imshow("4", letters[4][2]) cv2.waitKey(0)

الرسائل جاهزة للاعتراف بها ، وسوف نتعرف عليها باستخدام شبكة تلافيفية - هذا النوع من الشبكات مناسب تمامًا لمثل هذه المهام.
الشبكة العصبية (CNN) للتعرف عليها
تحتوي مجموعة بيانات مصدر EMNIST على 62 حرفًا مختلفًا (A..Z ، 0..9 ، إلخ):
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
بناءً على ذلك ، تحتوي الشبكة العصبية على 62 ناتجًا ، عند الإدخال ، ستتلقى 28 × 28 صورة ، بعد التعرف على "1" سيكون في إخراج الشبكة المقابل.
إنشاء نموذج الشبكة.
from tensorflow import keras from keras.models import Sequential from keras import optimizers from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization from keras.optimizers import SGD, RMSprop, Adam from keras import backend as K from keras.constraints import maxnorm import tensorflow as tf def emnist_model(): model = Sequential() model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu')) model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(len(emnist_labels), activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy']) return model
كما ترون ، هذه شبكة تلافيفية كلاسيكية تسلط الضوء على ميزات معينة من الصورة (عدد المرشحات 32 و 64) ، حيث يتصل "الإخراج" بشبكة MLP "الخطية" ، والتي تشكل النتيجة النهائية.
تدريب الشبكة العصبية
نمر إلى أطول مرحلة - تدريب الشبكة. للقيام بذلك ، نأخذ قاعدة بيانات EMNIST ، والتي يمكن تنزيلها
من الرابط (حجم الأرشيف 536 ميجابايت).
لقراءة قاعدة البيانات ، استخدم مكتبة idx2numpy. سنقوم بإعداد البيانات للتدريب والتحقق من الصحة.
import idx2numpy emnist_path = '/home/Documents/TestApps/keras/emnist/' X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte') y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte') X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte') y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte') X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1)) X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1)) print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels)) k = 10 X_train = X_train[:X_train.shape[0] // k] y_train = y_train[:y_train.shape[0] // k] X_test = X_test[:X_test.shape[0] // k] y_test = y_test[:y_test.shape[0] // k]
قمنا بإعداد مجموعتين للتدريب والتحقق من الصحة. الشخصيات نفسها عبارة عن مصفوفات عادية يسهل عرضها:

نستخدم أيضًا 1/10 فقط من مجموعة البيانات للتدريب (المعلمة k) ، وإلا ستستغرق العملية 10 ساعات على الأقل.
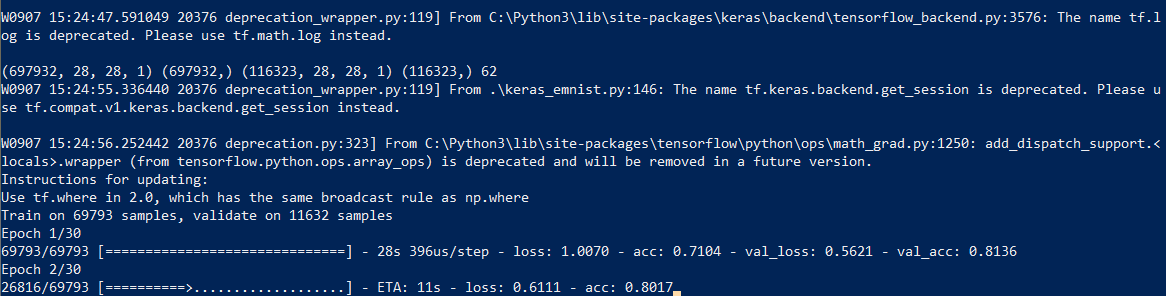
نبدأ التدريب على الشبكة ، في نهاية العملية نقوم بحفظ النموذج المدربين على القرص.
تستغرق عملية التعلم نفسها حوالي نصف ساعة:
يجب القيام بذلك مرة واحدة فقط ، ثم سنستخدم ملف النموذج المحفوظ بالفعل. عند الانتهاء من التدريب ، كل شيء جاهز ، يمكنك التعرف على النص.
اعتراف
للاعتراف ، نقوم بتحميل النموذج ونستدعي دالة Forecast_classes.
model = keras.models.load_model('emnist_letters.h5') def emnist_predict_img(model, img): img_arr = np.expand_dims(img, axis=0) img_arr = 1 - img_arr/255.0 img_arr[0] = np.rot90(img_arr[0], 3) img_arr[0] = np.fliplr(img_arr[0]) img_arr = img_arr.reshape((1, 28, 28, 1)) result = model.predict_classes([img_arr]) return chr(emnist_labels[result[0]])
كما اتضح ، تم تدوير الصور في مجموعة البيانات مبدئيًا ، لذلك يتعين علينا تدوير الصورة قبل التعرف عليها.
الوظيفة الأخيرة ، التي تستقبل ملفًا به صورة عند الإدخال وتعطي خطًا في الإخراج ، تشغل 10 سطور فقط من الكود:
def img_to_str(model: Any, image_file: str): letters = letters_extract(image_file) s_out = "" for i in range(len(letters)): dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0 s_out += emnist_predict_img(model, letters[i][2]) if (dn > letters[i][1]/4): s_out += ' ' return s_out
نستخدم هنا عرض الأحرف المحفوظة مسبقًا لإضافة مسافات إذا كان التباعد بين الأحرف أكثر من 1/4 من الحرف.
مثال للاستخدام:
model = keras.models.load_model('emnist_letters.h5') s_out = img_to_str(model, "hello_world.png") print(s_out)
النتيجة:

ميزة مضحكة هي أن الشبكة العصبية "تخلط" بين الحرف "O" والرقم "0" ، ومع ذلك ، فإنه ليس من المستغرب منذ تحتوي مجموعة EMNIST الأصلية على أحرف وأرقام
مكتوبة بخط اليد ليست مثل الحروف المطبوعة تمامًا. من الناحية المثالية ، للتعرف على نصوص الشاشة ، تحتاج إلى إعداد مجموعة منفصلة بناءً على خطوط الشاشة ، وتدريب شبكة عصبية عليها بالفعل.
استنتاج
كما ترون ، ليس الآلهة هم الذين يحرقون الأواني ، وما بدا أنه "سحر" بمساعدة المكتبات الحديثة أصبح بسيطًا للغاية.
نظرًا لأن Python عبارة عن نظام أساسي مشترك ، ستعمل الشفرة في كل مكان ، على أنظمة Windows و Linux و OSX. مثل Keras يتم نقله إلى iOS / Android ، لذلك من الناحية النظرية ، يمكن أيضًا استخدام النموذج المدرب على
الأجهزة المحمولة .
بالنسبة لأولئك الذين يرغبون في تجربة من تلقاء أنفسهم ، شفرة المصدر هي تحت المفسد.
كالعادة ، كل التجارب الناجحة.