استمرار ترجمة كتاب صغير:
"فهم وسطاء الرسائل" ،
المؤلف: Jakub Korab ، الناشر: O'Reilly Media، Inc. ، تاريخ النشر: يونيو 2017 ، ISBN: 9781492049296.
اكتملت الترجمة: tele.gg/middle_javaالجزء السابق:
فهم وسطاء الرسائل. تعلم آليات المراسلة من خلال ActiveMQ و Kafka. الفصل 2. ActiveMQالفصل 3
كافكا
تم تطوير Kafka على LinkedIn للتحايل على بعض قيود وسطاء الرسائل التقليديين ولتجنب الحاجة إلى تكوين وسطاء رسائل متعددين لتفاعلات مختلفة من نقطة إلى نقطة ، الموضحة في قسم "القياس الرأسي والأفقي" في الصفحة 28 في هذا الكتاب. اعتمد نظام LinkedIn بشدة على الامتصاص أحادي الاتجاه لكميات كبيرة جدًا من البيانات ، مثل نقرات الصفحات وسجلات الوصول ، مع السماح لأنظمة متعددة باستخدام هذه البيانات. صباحا، دون التأثير على أداء المنتجين أو konsyumerov الآخرين. في الواقع ، السبب في وجود Kafka هو الحصول على بنية المراسلة التي يصفها خط أنابيب Universal.
بالنظر إلى هذا الهدف النهائي ، نشأت متطلبات أخرى بشكل طبيعي. يجب على كافكا:
- كن سريعًا للغاية
- توفير قدر أكبر من نقل الرسائل
- دعم الناشر المشترك ونماذج نقطة إلى نقطة
- لا تبطئ مع إضافة المستهلكين. على سبيل المثال ، يتدهور أداء كل من قوائم الانتظار والمواضيع في ActiveMQ مع زيادة عدد المستهلكين في الوجهة.
- أن تكون قابلة أفقيا إذا استمرت رسالة واحدة في القيام بذلك فقط بأقصى سرعة للقرص ، فمن ثم لزيادة الأداء فمن المنطقي تجاوز حدود مثيل وسيط واحد
- تحديد الوصول إلى تخزين الرسائل واسترجاعها
لتحقيق كل هذا ، تبنت كافكا بنية أعادت تحديد أدوار ومسؤوليات العملاء وسماسرة المراسلة. يركز نموذج JMS بشكل كبير على الوسيط ، حيث يكون مسؤولاً عن توزيع الرسائل ، ويحتاج العملاء فقط للقلق بشأن إرسال واستقبال الرسائل. كافكا ، من ناحية أخرى ، هو موجه نحو العملاء ، حيث يتولى العميل العديد من وظائف الوسيط التقليدي ، مثل التوزيع العادل للرسائل ذات الصلة بين المستهلكين ، في مقابل تلقي وسيط سريع للغاية وقابل للتطوير. بالنسبة للأشخاص الذين يعملون مع أنظمة المراسلة التقليدية ، يتطلب العمل مع Kafka تغييرًا أساسيًا في الموقف.
أدى هذا الاتجاه الهندسي إلى إنشاء بنية تحتية للرسائل يمكنها زيادة الإنتاجية بعدة أوامر من الحجم مقارنة بالوسيط التقليدي. كما سنرى ، فإن هذا النهج محفوف بالتسويات ، مما يعني أن Kafka غير مناسب لأنواع معينة من الأحمال والبرامج المثبتة.
نموذج الوجهة الموحد
للوفاء بالمتطلبات المذكورة أعلاه ، قامت شركة كافكا بدمج اشتراك النشر والرسائل من نقطة إلى نقطة في نوع واحد من
موضوع المرسل إليه. هذا مربك بالنسبة للأشخاص الذين يعملون مع أنظمة المراسلة ، حيث تشير كلمة "topic" إلى آلية بث لا يمكن الاعتماد عليها (من الموضوع) من القراءة (غير قابلة للاستمرار). يجب اعتبار موضوعات كافكا نوعًا مختلطًا من الوجهة ، كما هو محدد في مقدمة هذا الكتاب.
في الجزء المتبقي من هذا الفصل ، ما لم نحدد صراحةً خلاف ذلك ، يشير مصطلح الموضوع إلى موضوع كافكا.
لكي نفهم تمامًا كيف تتصرف الموضوعات وما هي الضمانات التي توفرها ، نحتاج أولاً إلى التفكير في كيفية تنفيذها في كافكا.
كل موضوع في كافكا لديه مجلة خاصة به.المنتجون الذين يرسلون رسائل إلى كافكا يلحقون بهذه المجلة ، والمستهلكون يقرؤون من المجلة باستخدام مؤشرات تتحرك باستمرار إلى الأمام. يحذف كافكا بشكل دوري أقدم أجزاء المجلة ، بغض النظر عما إذا كانت الرسائل الموجودة في هذه الأجزاء قد تمت قراءتها أم لا. الجزء الرئيسي من تصميم كافكا هو أن الوسيط لا يهتم بما إذا كانت الرسائل قد قرأت أم لا - هذه مسؤولية العميل.
لم يتم العثور على مصطلحي "journal" و "index" في وثائق Kafka . وتستخدم هذه المصطلحات المعروفة هنا للمساعدة في فهم.
يختلف هذا النموذج تمامًا عن ActiveMQ ، حيث يتم تخزين الرسائل من جميع قوائم الانتظار في دفتر يومية واحد ، ويقوم الوسيط بتمييز الرسائل على أنها محذوفة بعد قراءتها.
دعنا الآن نذهب أكثر عمقًا وننظر إلى مجلة الموضوع بمزيد من التفاصيل.
تتكون مجلة كافكا من عدة أقسام (
الشكل 3-1 ). كافكا يضمن الطلب الصارم في كل قسم. هذا يعني أنه سيتم قراءة الرسائل المكتوبة إلى القسم بترتيب معين بنفس الترتيب. يتم تطبيق كل قسم كملف سجل (سجل) متداول يحتوي على
مجموعة فرعية من جميع الرسائل المرسلة إلى الموضوع بواسطة المنتجين. يحتوي الموضوع الذي تم إنشاؤه على قسم واحد افتراضيًا. التقسيم هو فكرة كافكا المركزية للتحجيم الأفقي.
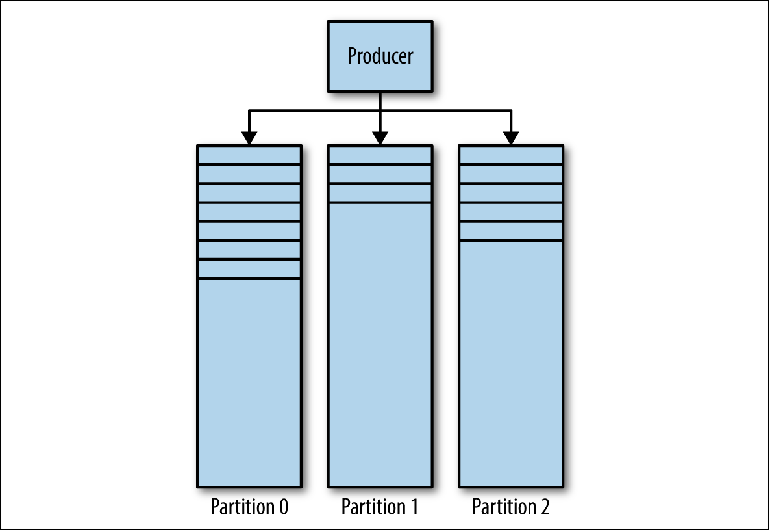 الشكل 3-1. أقسام كافكا
الشكل 3-1. أقسام كافكاعندما يرسل المنتج رسالة إلى موضوع كافكا ، فإنه يقرر القسم الذي سيتم إرسال الرسالة إليه. سننظر في هذا بمزيد من التفصيل في وقت لاحق.
قراءة الرسائل
يتحكم العميل الذي يريد قراءة الرسائل في مؤشر مسمى يسمى
مجموعة مستهلكين ، مما يشير إلى
إزاحة رسالة في قسم ما. الإزاحة هي موضع برقم متزايد يبدأ من 0 في بداية القسم. هذه المجموعة من المستهلكين ، المشار إليها في واجهة برمجة التطبيقات من خلال معرّف معرف من قبل المستخدم group_id ، تتوافق مع
مستهلك أو نظام منطقي واحد .
تقوم معظم أنظمة المراسلة بقراءة البيانات من المستلم عبر عدة مثيلات ومؤشرات ترابط لمعالجة الرسائل بشكل متوازٍ. وبالتالي ، سيكون هناك عادة العديد من الحالات للمستهلكين الذين يشاركون نفس المجموعة من المستهلكين.
يمكن تمثيل مشكلة القراءة على النحو التالي:
- الموضوع له عدة أقسام
- يمكن لمجموعات متعددة من المستهلكين استخدام الموضوع في نفس الوقت.
- يمكن لمجموعة من المستهلكين أن يكون لديهم عدة حالات منفصلة.
هذه مشكلة كثير إلى كثير غير تافهة. لفهم كيفية معالجة Kafka للعلاقات بين مجموعات المستهلكين ، وحالات المستهلكين والأقسام ، دعونا نلقي نظرة على سلسلة من النصوص البرمجية التي تزداد تعقيدًا.
المستهلكين ومجموعات المستهلكين
لنأخذ موضوع قسم واحد كنقطة انطلاق (
الشكل 3-2 ).
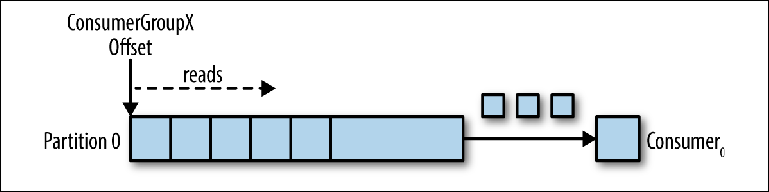 الشكل 3-2. يقرأ المستهلك من القسم
الشكل 3-2. يقرأ المستهلك من القسمعند اتصال مثيل المستهلك بمجموعة group_id الخاصة به لهذا الموضوع ، يتم تعيين قسم للقراءة والإزاحة في هذا القسم. يتم تكوين موضع هذا الإزاحة في العميل كمؤشر إلى الموضع الأحدث (الرسالة الأحدث) أو الموضع الأقدم (الرسالة الأقدم). يطلب المستهلك (استطلاعات) رسائل من الموضوع ، مما يؤدي إلى قراءته المتسلسلة من المجلة.
يتم إزاحة موضع الإزاحة بانتظام إلى كافكا وحفظها كرسائل في الموضوع الداخلي
_consumer_offsets . لا يزال يتم حذف الرسائل المقروءة ، على عكس الوسيط العادي ، ويمكن للعميل إرجاع الإزاحة لإعادة معالجة الرسائل التي تم عرضها بالفعل.
عند اتصال مستهلك منطقي ثانٍ باستخدام group_id آخر ، يتحكم في مؤشر ثانٍ مستقل عن الأول (
الشكل 3-3 ). وبالتالي ، فإن موضوع كافكا بمثابة قائمة انتظار يوجد فيها مستهلك واحد ، وكموضوع منتظم ، مشترك ناشر (pub-sub) ، مشترك فيه عدة مستهلكين ، مع ميزة إضافية تتمثل في حفظ جميع الرسائل ويمكن معالجتها عدة مرات.
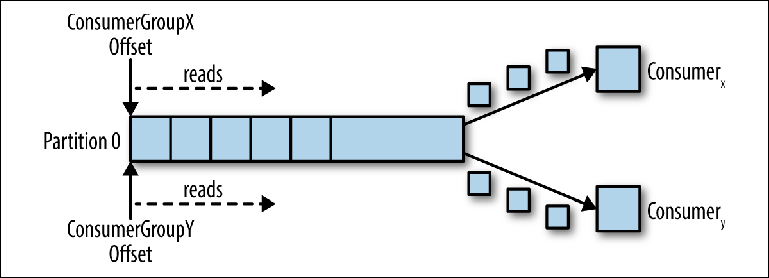 الشكل 3-3. قراءة اثنين من المستهلكين في مجموعات مختلفة من المستهلكين من نفس القسم
الشكل 3-3. قراءة اثنين من المستهلكين في مجموعات مختلفة من المستهلكين من نفس القسمالمستهلكون في المجموعة الاستهلاكية
عندما يقرأ أحد مثيلات العميل البيانات من القسم ، فإنه يتحكم بالكامل في المؤشر ويعالج الرسائل ، كما هو موضح في القسم السابق.
إذا تم توصيل عدة مثيلات من المستهلكين بنفس group_id للموضوع بقسم واحد ، فسيتم التحكم في المثيل الذي تم توصيله في النهاية على المؤشر ومن ثم سيصلك كل الرسائل (
الشكل 3-4 ).
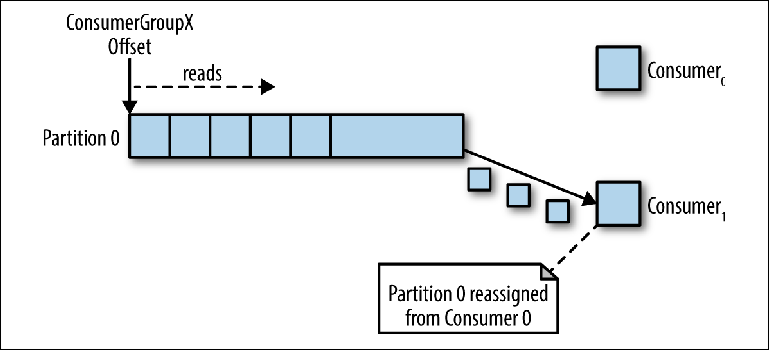 الشكل 3-4. قراءة اثنين من المستهلكين في نفس المجموعة من المستهلكين من نفس القسم
الشكل 3-4. قراءة اثنين من المستهلكين في نفس المجموعة من المستهلكين من نفس القسميمكن اعتبار وضع المعالجة هذا ، الذي يتجاوز فيه عدد حالات المستهلكين عدد الأقسام ، نوعًا من المستهلك الاحتكاري. قد يكون ذلك مفيدًا إذا كنت بحاجة إلى تجميع "سلبي نشط" (أو "حار دافئ") لحالات المستهلكين الخاصة بك ، على الرغم من أن التشغيل الموازي لعدة مستهلكين ("نشط نشط" أو "ساخن ساخن") أكثر نموذجية من المستهلكين في وضع الاستعداد.
يمكن أن يكون سلوك توزيع الرسائل ، المذكور أعلاه ، مفاجئًا مقارنة بكيفية تصرف قائمة انتظار JMS منتظمة. في هذا النموذج ، سيتم توزيع الرسائل المرسلة إلى قائمة الانتظار بالتساوي بين العميلين.
في أغلب الأحيان ، عندما ننشئ عدة مثيلات للمترجمين ، فإننا نقوم بذلك إما للمعالجة المتوازية للرسائل ، أو لزيادة سرعة القراءة ، أو لزيادة ثبات عملية القراءة. بما أنه يمكن لمثيل واحد فقط للمستهلك قراءة البيانات من أحد الأقسام ، فكيف يتحقق ذلك في كافكا؟
طريقة واحدة للقيام بذلك هي استخدام مثيل واحد للمستهلك لقراءة كافة الرسائل وإرسالها إلى تجمع مؤشر الترابط. على الرغم من أن هذا النهج يزيد من إنتاجية المعالجة ، إلا أنه يزيد من تعقيد منطق المستهلكين ولا يفعل شيئًا لزيادة استقرار نظام القراءة. إذا تم إيقاف تشغيل مثيل واحد من المستهلك بسبب انقطاع التيار الكهربائي أو حدث مماثل ، فسيتوقف تصحيح التجارب المطبعية.
الطريقة المعتادة لحل هذه المشكلة في كافكا هي استخدام المزيد من الأقسام.
التقسيم
الأقسام هي الآلية الرئيسية لموازنة القراءة وتوسيع نطاق الموضوع إلى ما وراء عرض النطاق الترددي لمثيل واحد للوسيط. لفهم ذلك بشكل أفضل ، دعنا ننظر إلى الموقف الذي يوجد فيه موضوع به قسمان ويشترك المستهلك في هذا الموضوع (
الشكل 3-5 ).
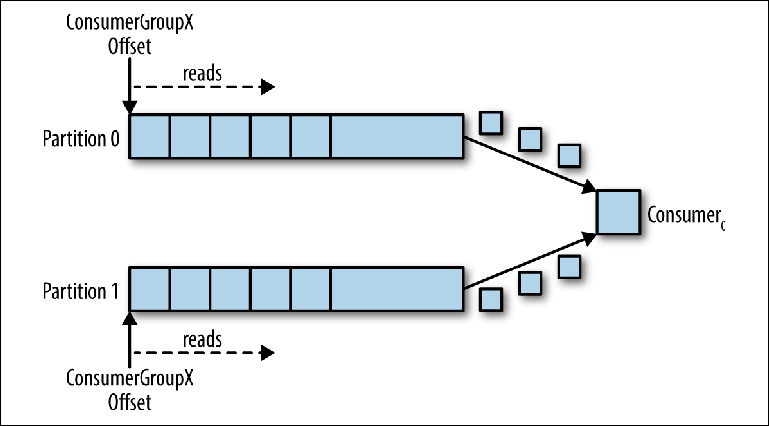 الشكل 3-5. يقرأ مستهلك واحد من عدة أقسام
الشكل 3-5. يقرأ مستهلك واحد من عدة أقسامفي هذا السيناريو ، يتم منح الخبير الاستشاري السيطرة على المؤشرات المقابلة لـ group_id في كلا القسمين ، وتبدأ قراءة الرسائل من كلا القسمين.
عندما تتم إضافة compurator إضافية إلى هذا الموضوع لنفس group_id ، يعيد Kafka تعيين (إعادة تخصيص) أحد الأقسام من الأول إلى الثاني. بعد ذلك ، سيتم طرح كل مثيل للمستهلك من قسم واحد من الموضوع (
الشكل 3-6 ).
لضمان أن تتم معالجة الرسائل بشكل متوازٍ في 20 موضوعًا ، ستحتاج إلى 20 قسمًا على الأقل. إذا كان هناك عدد أقل من الأقسام ، فسيظل لديك عملاء ليس لديهم ما تعمل عليه ، كما هو موضح سابقًا في مناقشة شاشات العرض الحصرية.
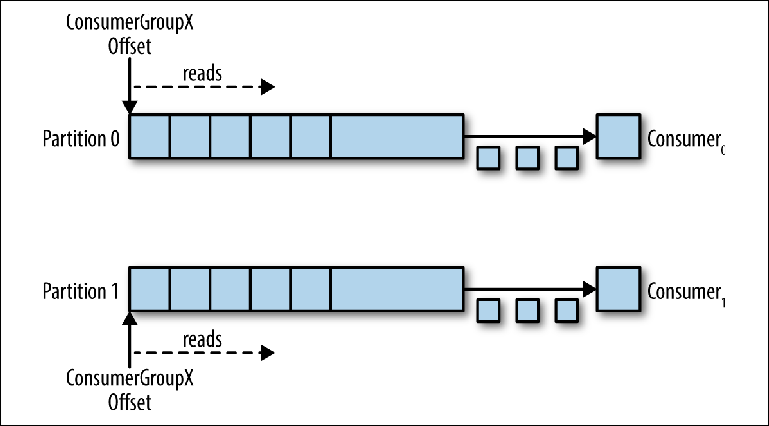 الشكل 3-6. قراءة مستهلكين في نفس المجموعة من المستهلكين من أقسام مختلفة
الشكل 3-6. قراءة مستهلكين في نفس المجموعة من المستهلكين من أقسام مختلفةيقلل هذا المخطط بدرجة كبيرة من تعقيد وسيط Kafka مقارنةً بتوزيع الرسائل الضروري لدعم قائمة انتظار JMS. ليست هناك حاجة لرعاية النقاط التالية:
- أي مستهلك يجب أن يتلقى الرسالة التالية بناءً على توزيع ذهاب وإياب ، أو سعة التخزين المؤقت الحالية للإعداد المسبق ، أو الرسائل السابقة (كما هو الحال مع مجموعات رسائل JMS).
- ما هي الرسائل التي تم إرسالها إلى أي المستهلكين وينبغي أن يكونوا مستاؤون في حالة الفشل.
كل ما ينبغي على وسيط كافكا أن يفعله هو إرسال رسائل باستمرار إلى المستشار عندما يطلب منهم ذلك.
ومع ذلك ، لا تختفي متطلبات مزامنة تصحيح الأخطاء وإعادة إرسال الرسائل غير الناجحة - فالمسؤولية عنها تنتقل ببساطة من الوسيط إلى العميل. هذا يعني أنه يجب أخذها في الاعتبار في شفرتك.
إرسال الرسائل
مسؤولية تحديد القسم الذي سيتم إرسال الرسالة إليه هي الجهة المنتجة للرسالة. لفهم الآلية التي يتم بها ذلك ، عليك أولاً التفكير في ما نرسله بالفعل.
بينما نستخدم في JMS بنية رسالة تحتوي على بيانات أولية (رؤوس وخصائص) وجسم يحتوي على حمولة ، في كافكا الرسالة هي
زوج القيمة الرئيسية . يتم إرسال حمولة الرسالة كقيمة. من ناحية أخرى ، يتم استخدام المفتاح بشكل أساسي للتقسيم ويجب أن يحتوي على
مفتاح خاص بمنطق العمل لوضع الرسائل ذات الصلة في القسم نفسه.
في الفصل 2 ، ناقشنا سيناريو المراهنة عبر الإنترنت ، عندما ينبغي معالجة الأحداث ذات الصلة بالترتيب من قبل مستهلك واحد:
- تم تكوين حساب المستخدم.
- يتم إضافة الأموال إلى الحساب.
- يتم المراهنة على سحب الأموال من الحساب.
إذا كان كل حدث رسالة مرسلة إلى الموضوع ، فسيكون معرف الحساب في هذه الحالة هو المفتاح الطبيعي.
عند إرسال رسالة باستخدام واجهة برمجة تطبيقات Kafka Producer ، يتم تمريرها إلى وظيفة التقسيم ، والتي ، بالنظر إلى الرسالة والحالة الحالية لمجموعة Kafka ، تقوم بإرجاع معرف القسم الذي يجب إرسال الرسالة إليه. يتم تنفيذ هذه الميزة في Java من خلال واجهة Partitioner.
هذه الواجهة هي كما يلي:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }
يستخدم تطبيق Partitioner خوارزمية التجزئة العامة للأغراض العامة على المفتاح أو round-robin إذا لم يتم تحديد المفتاح لتحديد القسم. هذه القيمة الافتراضية تعمل بشكل جيد في معظم الحالات. ومع ذلك ، في المستقبل سوف ترغب في كتابة الخاصة بك.
كتابة استراتيجية التقسيم الخاصة بك
دعونا نلقي نظرة على مثال عندما تريد إرسال البيانات الأولية مع حمولة الرسالة. الحمولة في مثالنا هي تعليمات لإجراء إيداع في حساب اللعبة. التعليمات هي شيء نود أن نضمن عدم تعديله أثناء الإرسال ، ونريد أن نتأكد من أن النظام المتفوق الموثوق به هو الوحيد القادر على بدء هذه التعليمات. في هذه الحالة ، توافق أنظمة الإرسال والاستقبال على استخدام التوقيع لمصادقة الرسالة.
في JMS العادية ، نقوم ببساطة بتحديد خاصية توقيع الرسالة وإضافتها إلى الرسالة. ومع ذلك ، لا يوفر Kafka لنا آلية لنقل البيانات الوصفية - فقط المفتاح والقيمة.
نظرًا لأن القيمة هي الحمولة النافعة للتحويل المصرفي (حمولة التحويل المصرفي) ، والتي نريد الحفاظ على تكاملها ، فليس لدينا خيار سوى تحديد بنية البيانات لاستخدامها في المفتاح. على افتراض أننا نحتاج إلى معرف حساب للتقسيم ، نظرًا لأن جميع الرسائل المتعلقة بالحساب يجب أن تتم معالجتها بالترتيب ، فسنتوصل إلى بنية JSON التالية:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }
نظرًا لأن قيمة التوقيع ستختلف باختلاف الحمولة ، فإن استراتيجية تجزئة واجهة التقسيم الافتراضية لن تجمع الرسائل ذات الصلة بشكل موثوق. لذلك ، سوف نحتاج إلى كتابة استراتيجيتنا الخاصة ، والتي ستحلل هذا المفتاح ومشاركة قيمة accountId.
يتضمن Kafka اختباريًا لاكتشاف تلف الرسائل في المستودع ويحتوي على مجموعة كاملة من ميزات الأمان. وحتى مع ذلك ، تظهر متطلبات الصناعة في بعض الأحيان ، مثل المتطلبات المذكورة أعلاه.
يجب أن تضمن إستراتيجية تقسيم المستخدم انتهاء جميع الرسائل ذات الصلة في نفس القسم. على الرغم من أن هذا يبدو بسيطًا ، إلا أنه يمكن تعقيد المتطلبات نظرًا لأهمية طلب الرسائل ذات الصلة ومدى ثبات عدد الأقسام في الموضوع.
يمكن أن يتغير عدد الأقسام في الموضوع بمرور الوقت ، حيث يمكن إضافتها إذا تجاوز عدد الزيارات التوقعات الأولية. وبالتالي ، يمكن ربط مفاتيح الرسائل بالقسم الذي تم إرساله إليه في الأصل ، مما يعني وجود جزء من الحالة التي يجب توزيعها بين مثيلات المنتج.
عامل آخر في الاعتبار هو التوزيع الموحد للرسائل بين الأقسام. كقاعدة عامة ، لا يتم توزيع المفاتيح بالتساوي عبر الرسائل ، ولا تضمن وظائف التجزئة توزيعًا عادلًا للرسائل لمجموعة صغيرة من المفاتيح.
من المهم الإشارة إلى أنه بغض النظر عن كيفية تقسيم الرسائل ، فقد يلزم إعادة استخدام الفاصل نفسه.
النظر في شرط لتكرار البيانات بين مجموعات كافكا في مواقع جغرافية مختلفة. لهذا الغرض ، يأتي Kafka مع أداة سطر أوامر تسمى MirrorMaker ، والتي تستخدم لقراءة الرسائل من كتلة واحدة ونقلها إلى أخرى.
يجب على MirrorMaker فهم مفاتيح الموضوع المنسوخ من أجل الحفاظ على الترتيب النسبي بين الرسائل أثناء النسخ المتماثل بين الكتل ، لأن عدد الأقسام لهذا الموضوع قد لا يتزامن في مجموعتين.
استراتيجيات التقسيم المخصصة نادرة نسبيًا ، حيث أن التجزئات الافتراضية أو العمل المستدير الافتراضي يعمل بنجاح في معظم السيناريوهات. ومع ذلك ، إذا كنت بحاجة إلى ضمانات صارمة للطلب أو كنت بحاجة إلى استخراج البيانات الوصفية من الحمولات الصافية ، فإن التقسيم شيء يجب عليك إلقاء نظرة فاحصة عليه.
تأتي مزايا قابلية التوسع والأداء لدى كافكا من نقل بعض مسؤوليات الوسيط التقليدي إلى العميل. في هذه الحالة ، يتم اتخاذ قرار بشأن توزيع الرسائل ذات الصلة المحتملة بين العديد من المستهلكين الذين يعملون بالتوازي.
يجب على وسطاء JMS أيضًا التعامل مع هذه المتطلبات. ومن المثير للاهتمام ، أن آلية إرسال الرسائل ذات الصلة إلى نفس الحساب المنفذة من خلال JMS Message Groups (نوع من موازنة حمل لزجة (SLB) استراتيجية موازنة) يتطلب أيضا المرسل لتمييز الرسائل على أنها ذات صلة. في حالة JMS ، يكون الوسيط مسؤولًا عن إرسال هذه المجموعة من الرسائل ذات الصلة إلى أحد العملاء العديدين ونقل ملكية المجموعة إذا كان العميل قد سقط.
اتفاق المنتج
التقسيم ليس هو الشيء الوحيد الذي يجب مراعاته عند إرسال الرسائل. دعونا نلقي نظرة على أساليب send () لفئة المنتج في واجهة برمجة تطبيقات Java:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback);
تجدر الإشارة إلى أن كلا الطريقتين تُرجعان المستقبل ، مما يشير إلى أن عملية الإرسال لم تتم على الفور. نتيجة لذلك ، اتضح أن الرسالة (ProducerRecord) تتم كتابتها إلى المخزن المؤقت للإرسال لكل قسم نشط ويتم إرسالها إلى الوسيط في دفق الخلفية في مكتبة عميل Kafka. على الرغم من أن هذا يجعل العمل سريعًا بشكل لا يصدق ، إلا أنه يعني أن التطبيق الذي لا يتمتع بالخبرة يمكن أن يفقد الرسائل إذا تم إيقاف العملية.
كما هو الحال دائمًا ، هناك طريقة لجعل عملية الإرسال أكثر موثوقية نظرًا للأداء. يمكن ضبط حجم هذا المخزن المؤقت على 0 ، وسيتم فرض مؤشر ترابط تطبيق الإرسال على الانتظار حتى يتم إرسال الرسالة إلى الوسيط ، كما يلي:
RecordMetadata metadata = producer.send(record).get();
مرة أخرى عن قراءة الرسائل
قراءة الرسائل لديها صعوبات إضافية تحتاج إلى النظر فيها. على عكس واجهة برمجة تطبيقات JMS ، والتي يمكن أن تبدأ مستمع الرسائل استجابةً لرسالة ، فإن واجهة
Consumer Kafka تقوم باستطلاعات فقط. دعونا نلقي نظرة فاحصة على طريقة
الاستطلاع () المستخدمة لهذا الغرض:
ConsumerRecords < K, V > poll(long timeout);
قيمة الإرجاع للأسلوب هي بنية حاوية تحتوي على العديد من كائنات
ConsumerRecord من عدة أقسام يحتمل أن تكون.
ConsumerRecord نفسه هو كائن حامل لزوج قيمة المفتاح مع بيانات التعريف المرتبطة ، مثل القسم الذي اشتق منه.
كما تمت مناقشته في الفصل 2 ، يجب أن نتذكر باستمرار ما يحدث للرسائل بعد معالجتها بنجاح أو دون جدوى ، على سبيل المثال ، إذا كان العميل لا يستطيع معالجة الرسالة أو إذا كانت المقاطعة تعمل. في JMS ، تم التعامل مع هذا من خلال وضع الاعتراف. سيحذف الوسيط الرسالة التي تمت معالجتها بنجاح أو يعيد تسليم الرسالة الأولية أو المقلوبة (شريطة استخدام المعاملات).
كافكا يعمل بطريقة مختلفة تماما. لا يتم حذف الرسائل في الوسيط بعد التدقيق ، وتقع مسؤولية ما يحدث عند الفشل على الكود نفسه.
كما قلنا من قبل ، ترتبط مجموعة من المستهلكين بإزاحة في المجلة. يتوافق موضع السجل المرتبط بهذا الانحياز مع الرسالة التالية التي ستصدر استجابةً
للاستطلاع () . حاسمة في القراءة هي النقطة في الوقت الذي تزداد فيه هذه الإزاحة.
بالعودة إلى نموذج القراءة الذي تمت مناقشته مسبقًا ، تتكون معالجة الرسائل من ثلاث مراحل:
- استرداد رسالة للقراءة.
- معالجة الرسالة.
- تأكيد الرسالة.
يأتي مستشار المستهلك Kafka مع
خيار التكوين
enable.auto.commit . هذا إعداد افتراضي شائع الاستخدام ، كما هو الحال عادةً مع الإعدادات التي تحتوي على كلمة "تلقائي".
قبل تطبيق Kafka 0.10 ، أرسل العميل الذي يستخدم هذه المعلمة إزاحة آخر رسالة قراءة في
الاستطلاع التالي
() بعد إجراء المعالجة. هذا يعني أن أي رسائل تم جلبها بالفعل يمكن إعادة معالجتها إذا كان العميل قد عالجها بالفعل ، لكن تم إتلافها بشكل غير متوقع قبل استدعاء
الاستطلاع () . نظرًا لأن الوسيط لا يحتفظ بأي حالة فيما يتعلق بعدد مرات قراءة الرسالة ، فلن يعلم المستهلك التالي الذي يسترجع هذه الرسالة أن شيئًا سيئًا قد حدث. كان هذا السلوك المعاملات الزائفة. تم الإزاحة فقط في حالة نجاح معالجة الرسالة ، ولكن في حالة توقف العميل ، أرسل الوسيط الرسالة نفسها مرة أخرى إلى عميل آخر. كان هذا السلوك متوافقًا مع ضمان تسليم الرسائل "
مرة واحدة على الأقل ".
في Kafka 0.10 ، تم تغيير رمز العميل بطريقة بدأت الالتزام من قبل مكتبة العميل بشكل دوري ، وفقًا للإعداد
auto.commit.interval.ms . يوجد هذا السلوك في مكان ما بين أوضاع JMS AUTO_ACKNOWLEDGE و DUPS_OK_ACKNOWLEDGE. عند استخدام الالتزام التلقائي ، يمكن تأكيد الرسائل بغض النظر عما إذا كانت قد تمت معالجتها بالفعل - يمكن أن يحدث هذا في حالة المستهلك البطيء. إذا تمت مقاطعة الضاغطة ، فسيتم استرجاع الرسائل بواسطة الضاغط التالي ، بدءًا من موضع آمن ، مما قد يؤدي إلى تخطي الرسائل. في هذه الحالة ، لم يفقد كافكا الرسائل ، لكن كود القراءة ببساطة لم يعالجها.
هذا الوضع له نفس الاحتمالات كما في الإصدار 0.9: يمكن معالجة الرسائل ، ولكن في حالة الفشل ، قد لا يتم إغلاق الإزاحة ، مما قد يؤدي إلى تكرار التسليم. كلما زاد عدد الرسائل التي تسترجعها عند إجراء
الاستطلاع () ، زادت هذه المشكلة.
كما نوقش في قسم "طرح الرسائل من قائمة الانتظار" في
الفصل 2 ، لا يوجد شيء مثل تسليم الرسائل لمرة واحدة في نظام المراسلة ، بالنظر إلى أوضاع الفشل.
في Kafka ، هناك طريقتان لإصلاح (الالتزام) الإزاحة (الإزاحة): تلقائيًا ويدويًا. في كلتا الحالتين ، يمكن معالجة الرسائل عدة مرات ، في حالة معالجة الرسالة ولكن فشل قبل الالتزام. لا يمكنك أيضًا معالجة الرسالة على الإطلاق إذا حدث الالتزام في الخلفية وتم إكمال الكود قبل بدء المعالجة (ربما في الإصدار 0.9 من Kafka والإصدارات السابقة).
يمكنك التحكم في عملية ارتكاب الإزاحة يدويًا في Kafka
Consumer API من خلال تعيين
enable.auto.com ، للإتصال كاذبة والاتصال بأحد الطرق التالية بشكل صريح:
void commitSync(); void commitAsync();
إذا كنت ترغب في معالجة الرسالة "مرة واحدة على الأقل" ، فيجب عليك الالتزام
بالإزاحة يدويًا باستخدام
oblSync () عن طريق تنفيذ هذا الأمر فور معالجة الرسائل.
لا تسمح هذه الطرق بمعالجة الرسائل المعترف بها قبل معالجتها ، لكنها لا تفعل شيئًا للتخلص من تكرار المعالجة المحتمل ، بينما تخلق في نفس الوقت ظهور المعاملة. كافكا لا يوجد لديه المعاملات. ليس لدى العميل فرصة للقيام بما يلي:
- استرجاع رسالة الاستعادة تلقائيًا. يجب على المستهلكين أنفسهم التعامل مع الاستثناءات الناشئة عن الحمولات الصعبة ومشكلات انقطاع الخلفية ، حيث لا يمكنهم الاعتماد على الوسيط لإعادة تسليم الرسائل.
- إرسال رسائل إلى العديد من المواضيع داخل عملية ذرية واحدة. كما سنرى قريبًا ، يمكن التحكم في العديد من الموضوعات والأقسام على أجهزة مختلفة في مجموعة Kafka ، والتي لا تنسق المعاملات عند الإرسال. في وقت كتابة هذا التقرير ، تم إنجاز بعض الأعمال لجعل ذلك ممكنًا مع KIP-98.
- ربط قراءة رسالة واحدة من موضوع واحد مع إرسال رسالة أخرى إلى موضوع آخر. مرة أخرى ، تعتمد بنية Kafka على العديد من الآلات المستقلة التي تعمل كحافلة واحدة ولم تبذل أية محاولة لإخفائها. على سبيل المثال ، لا توجد مكونات API تسمح للمستهلك والمنتج بالربط في معاملة. في JMS ، يتم توفير ذلك بواسطة كائن الجلسة الذي يتم من خلاله إنشاء MessageProducers و MessageConsumers .
إذا لم نتمكن من الاعتماد على المعاملات ، فكيف يمكننا توفير دلالات أقرب إلى تلك التي توفرها أنظمة المراسلة التقليدية؟
إذا كان هناك احتمال أن تزيد إزاحة العميل قبل معالجة الرسالة ، على سبيل المثال ، أثناء فشل العميل ، فلن يكون لدى العميل أي طريقة لمعرفة ما إذا كانت مجموعة العملاء قد فاتتهم الرسالة عند تعيين القسم. وبالتالي ، تتمثل إحدى الاستراتيجيات في إرجاع الإزاحة إلى الموضع السابق. يوفر API Kafka Consumer Advisor الطرق التالية لهذا:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions);
يمكن
البحث عن طريقة
() مع هذه الطريقة
offsetsForTimes (خريطة <TopicPartition، Long> timestampsToSearch) للعودة إلى حالة في أي نقطة معينة في الماضي.
ضمنيًا ، يعني استخدام هذا النهج أنه من المحتمل جدًا أن تتم قراءة بعض الرسائل التي تمت معالجتها مسبقًا ومعالجتها مرة أخرى. لتجنب ذلك ، يمكننا استخدام القراءة العاطفية ، كما هو موضح في الفصل 4 ، لتتبع الرسائل التي سبق عرضها والتخلص من التكرارات.
كبديل ، يمكن أن يكون رمز المستهلك بسيطًا إذا كان فقدان الرسائل أو تكرارها مسموحًا به. عندما ننظر إلى سيناريوهات الاستخدام التي عادةً ما يتم استخدام كافكا لها ، على سبيل المثال ، معالجة أحداث السجل والمقاييس وتتبع النقرات وما إلى ذلك ، فإننا نفهم أن فقدان الرسائل الفردية لن يكون له تأثير كبير على التطبيقات المحيطة. في مثل هذه الحالات ، تكون القيم الافتراضية مقبولة. من ناحية أخرى ، إذا كان طلبك يحتاج إلى تحويل مدفوعات ، فيجب عليك العناية بعناية بكل رسالة فردية. كل ذلك يأتي إلى السياق.
تظهر الملاحظات الشخصية أنه مع زيادة كثافة الرسائل ، تنخفض قيمة كل رسالة فردية. تميل الرسائل ذات الحجم الكبير إلى أن تصبح ذات قيمة عند عرضها في شكل مجمع.
عالية التوفر
يختلف نهج التوفر العالي من Kafka عن ActiveMQ. تم تطوير Kafka على أساس مجموعات قابلة للتطوير أفقياً حيث تتلقى جميع مثيلات الوسيط الرسائل وتوزعها في وقت واحد.
تتكون مجموعة Kafka من العديد من مثيلات الوسيط التي تعمل على خوادم مختلفة. تم تصميم Kafka للعمل على أجهزة تقليدية قائمة بذاتها ، حيث تحتوي كل عقدة على مساحة تخزين خاصة بها. لا يُنصح باستخدام التخزين المرتبط بالشبكة (SAN) نظرًا لأن العقد الحسابية المتعددة يمكن أن تتنافس على فترات التخزين وتسبب تعارضات.
كافكا هو
باستمرار على النظام. لا يقوم الكثير من مستخدمي Kafka بإطفاء مجموعاتهم مطلقًا ، ويوفر البرنامج دائمًا تحديثات من خلال إعادة تشغيل متسقة. يتحقق ذلك من خلال ضمان التوافق مع الإصدار السابق للرسائل والتفاعلات بين الوسطاء.
السماسرة مرتبطون
بمجموعة خوادم
ZooKeeper ، والتي تعمل بمثابة سجل تكوين محدد ويتم استخدامها لتنسيق أدوار كل وسيط. ZooKeeper نفسه هو نظام موزع يوفر توفرًا عاليًا من خلال النسخ المتماثل للمعلومات عن طريق إنشاء
النصاب القانوني .
في الحالة الأساسية ، يتم إنشاء الموضوع في كتلة Kafka بالخصائص التالية:
- عدد الأقسام. كما نوقش سابقًا ، تعتمد القيمة الدقيقة المستخدمة هنا على المستوى المطلوب من القراءة المتزامنة.
- يحدد معامل النسخ المتماثل (العامل) عدد مثيلات الوسيط في الكتلة التي يجب أن تحتوي على سجلات لهذا القسم.
باستخدام ZooKeepers للتنسيق ، يحاول Kafka توزيع أقسام جديدة إلى حد ما بين الوسطاء في الكتلة. يتم ذلك عن طريق حالة واحدة ، والتي تعمل بمثابة المراقب المالي.
في وقت التشغيل
لكل قسم من أقسام الموضوع ، يعين
المراقب المالي الوسيط أدوار
القائد (القائد والسيد والقائد)
والأتباع (المتابعين والعبيد والمرؤوسين). يتولى الوسيط ، بصفته قائد هذا القسم ، مسؤولية استلام جميع الرسائل المرسلة إليه من قبل المنتجين ، وتوزيع الرسائل على المستهلكين. عند إرسال رسائل إلى قسم الموضوع ، يتم نسخها إلى عقد كل وسيط بصفتها متابعين لهذا القسم. تسمى كل عقدة تحتوي على سجلات القسم نسخة
متماثلة . يمكن للوسيط أن يتصرف كقائد لبعض الأقسام وكتاب تابع للآخرين.
يسمى المتتبع الذي يحتوي على جميع الرسائل المخزنة بواسطة زعيم
نسخة متماثلة (نسخة متماثلة في حالة متزامنة ، متماثلة متزامنة). إذا تم فصل الوسيط الذي يتصرف كقائد للقسم ، فإن أي وسيط يكون في الحالة المحدثة أو المتزامنة لهذا القسم يمكن أن يتولى دور القائد. هذا هو تصميم مستدام بشكل لا يصدق.
جزء من تكوين المنتج هو المعلمة
acks ، التي تحدد عدد النسخ المتماثلة التي يجب أن تتسلم استلام رسالة قبل أن يستمر دفق التطبيق في الإرسال: 0 ، 1 أو الكل. إذا تم تعيين القيمة على
الكل ، فعندما يتم استلام الرسالة ، فسيرسل الزعيم رسالة تأكيد إلى المنتج بمجرد استلامه تأكيدًا من النسخ المتماثلة العديدة (بما في ذلك نفسه) المعرّفة من قِبل
إعداد موضوع
min.insync.replicas (افتراضيًا 1). إذا تعذر نسخ الرسالة بنجاح ، فسيقوم المنتج بإلقاء استثناء للتطبيق (
NotEnoughReplicas أو
NotEnoughReplicasAfterAppend ).
3 (1 , 2 )
min.insync.replicas 2. , , , , .
. (acknowledgments) . , , , , , ( ).
باستخدام نظام النسخ المتماثل هذا ، يتجنب Kafka بذكاء الحاجة إلى كتابة كل رسالة فعليًا على القرص باستخدام عملية المزامنة () . سيتم كتابة كل رسالة يتم إرسالها من قبل المنتج إلى سجل القسم ، ولكن ، كما تمت مناقشته في الفصل 2 ، تتم الكتابة إلى الملف مبدئيًا في المخزن المؤقت لنظام التشغيل. إذا تم نسخ هذه الرسالة إلى نسخة أخرى من تطبيق كافكا وكانت موجودة في ذاكرتها ، فإن فقدان القائد لا يعني أن الرسالة نفسها قد ضاعت - فالنسخة المتزامنة يمكن أن تأخذها على عاتقها.إلغاء الاشتراك من عملية المزامنة ()يعني أن كافكا يمكنه استقبال الرسائل بالسرعة التي يمكنه بها كتابتها على الذاكرة. على العكس من ذلك ، كلما كان يمكنك تجنب مسح الذاكرة على القرص ، كان ذلك أفضل. لهذا السبب ، ليس من غير المألوف أن يقوم وسطاء Kafka بتخصيص 64 جيجابايت أو أكثر من الذاكرة. استخدام الذاكرة هذا يعني أنه يمكن لمثيل كافكا أن يعمل بسرعات عدة آلاف من المرات أسرع من وسيط الرسائل التقليدي.يمكن أيضًا تكوين كافكا لاستخدام المزامنة () . Kafka , , . Kafka , , ,
zero-copy (, ). , .
في مجموعة Kafka ، يكون الأداء العالي أكثر مما هو ممكن عند استخدام وسيط Kafka واحد ، حيث يمكن تغيير أقسام الموضوع أفقياً على العديد من الأجهزة المنفصلة.النتائج
, Kafka , , , . , , , . , , . , , , .
: tele.gg/middle_java...