على الإنترنت ، لا تزال كلمة التحقق صالحة ، والتي تقدم كخيار للاستماع إلى النص من الصورة من خلال النقر على الزر المقابل. إذا كان شخص ما على دراية بالصورة أدناه و / أو مهتم بكيفية الالتفاف عليها باستخدام نظام التعرف على الصوت في وضع عدم الاتصال ، يُقترح قراءتها.
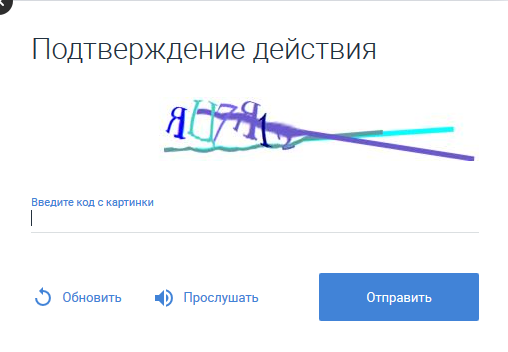
لن نقوم بمعذبة مؤامرات الخبراء في مجال التعرف على الكلام ، على الفور موضحًا أنه لم يتم تطوير أي نظام للتعرف على الصوت للأغراض الخاصة. يستخدم المقال Pocketsphinx القديم الجيد ، ولكن بدرجة معينة من التخصيص.
تدريب
"يمكنك الركض إلى مكتب المنافسين الذين لديهم تحكم صوتي على أجهزة الكمبيوتر ، وهم يهتفون" Sudo Era ناقص Eref Home "وتهرب." من التعليقات.
لذلك ، يقدم captcha الاستماع إلى نفسه من خلال النقر على الزر المناسب. إذا قمت بحفظ الملف الصوتي الناتج ، فيمكنك معرفة ما يشبه الصوت القصير في ملف MP3. في الوقت نفسه ، كما اتضح فيما بعد ، يتم تقديم كلمة captcha بصوت يتصرف بصوت أنثى أو ذكر. يختلف "رسم" نفس الأصوات التي يصدرها رجل وامرأة:
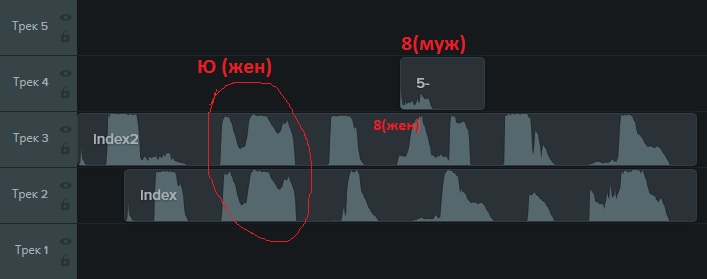
يبدو كل من الحروف (والروسية) ، والأرقام.
للوهلة الأولى ، كل شيء محزن. ولكن هناك نقطة إيجابية في أن الأصوات لنفس الحروف تتزامن.
حتى الآن ، هذه المعرفة لا تساعد كثيرا. كيفية دفع كل هذا في حزمة من أبو الهول؟
تثبيت Pocketsphinx ، نموذج الصوت الروسي
* هناك
مقال عن حبري حيث يتم تغذية الصوت إلى مترجم جوجل على الإنترنت من خلال إعادة توجيه إخراج الصوت. وهذا يمكن أن ينتهي هذا المنصب ، إذا كان كل هذا يعمل لهذه الحالة.
تثبيت Pocketsphinx نفسه على نظام التشغيل windows (وعلى نظام التشغيل linux أيضًا) ليس معقدًا جدًا - قم
بتنزيله وتثبيته.
نظرًا لأن pocketsphinx يأتي افتراضيًا مع اللغة الإنجليزية ، والنماذج الصوتية ، والقاموس ، فستحتاج إلى نفس اللغة الروسية.
قم بتنزيل النسخة الروسية -
رابط .
بعد تفريغ النموذج الروسي في بنية الملف ، يمكنك تجربة test .wav file decoder-text.wav برمز python التالي:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path
يجب عرض محتويات الملف الصوتي على السطر: "Ilya Ilf Evgeny Petrov Golden Calf."
إذا لم يتم إخراجها (كما في موقفي) ، فأنت بحاجة إلى تحويل decoder-test.wav إلى تنسيق صوتي آخر.
ستحتاج ffmpeg لهذا الغرض.
فمبيج
بعد تنزيل الأداة المساعدة ffmpeg ، ضع وحدة فك ترميز test.wav في C: \ python3 \ ffmpeg \ bin.
بعد ذلك ، قم بتحويل سطر الأوامر:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
بعد ذلك ، إصلاح الرابط إلى ملف الصوت المصدر في رمز بيثون:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
الآن ، بعد وضع الكود:

صحيح ، عليك الانتظار حتى المجيء الثاني ، يعمل الرمز ببطء شديد - حوالي 20 ثانية.
نقوم بتحويل الصوت captcha بنفس المبدأ من mp3 إلى wav وإطعام الصوت من captcha. ألقِ نظرة على الكود:

نوع من الجهل ، ولكن هناك نتيجة. كان يمكن أن يكون أسوأ بكثير لو لم يبرز شيء. كما هو الحال مع صوت الأنثى:

دعونا نرى كيفية تحسين النتيجة وفي نفس الوقت تسريعها.
قاموس
سوف تحتاج القاموس الخاص بك. في هذه الحالة ، ستتكون من جميع حروف الأبجدية الروسية (باستثناء b ، s ، b) والأرقام.
يجب وضع جميع الأحرف في ملف نص عادي ، واحد على كل سطر بترميز UTF-8.
تحتاج الآن إلى تحويل القاموس.
سوف تحتاج إلى تثبيت بيرل (هناك حاجة للمحول للعمل).
بعد ذلك ، قم بتنزيل المشروع لتحويل
ru4sphinx .
وتحويل القاموس الذي تم إنشاؤه مسبقًا:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
الإخراج هو قاموس للعمل:

يجب إعادة تسمية ملحق القاموس من .txt إلى تنسيق .dic ، ويجب وضع الملف نفسه في مكان يمكن الوصول إليه.
في شفرة python ، سنشير إلى موقع القاموس عن طريق تعليق القاموس القديم:
شغّل البرنامج وشاهد النتيجة:

أفضل ، ولكن بنفس السرعة ، وليس كل الحروف محددة بشكل صحيح.
إنشاء النموذج الخاص بك
سيؤدي هذا إلى زيادة كبيرة في سرعة العمل ودقة في النتيجة.
دعنا نذهب بعيدا عن
التعليمات .
اتبع
الرابط وقم بتحميل قاموسنا ، الذي تم إنشاؤه مسبقًا بتنسيق .txt (وليس .dic!) إلى موقع الويب:
انقر فوق "ترجمة ...". في الإخراج ، يمكنك تنزيل الحزمة الناتجة في أرشيف .tgz (يحتوي على جميع الملفات اللازمة):
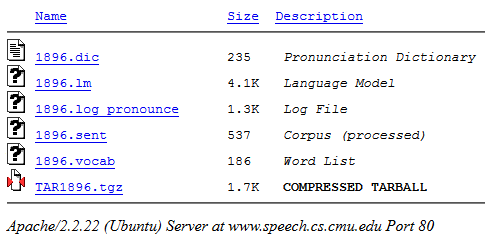
بعد ذلك ، نأخذ ملفًا بالملحق .lm (نموذجنا) من الأرشيف.
دعونا إصلاح البرنامج النصي الاعتراف بيثون عن طريق استبدال النموذج مع نموذج مصنوع حديثا:
نحن نحاول:

يعمل بشكل أسرع بكثير - أقل من ثانية ، بالإضافة إلى ذلك ، يتم تعريف جميع الحروف.
ولكن هنا هناك حاجة إلى ملاحظة صغيرة.
لا يتم التعرف على جميع الأحرف بشكل صحيح ، وإذا تم عرض حرف مختلف بدلاً من الحرف الصحيح ، فيمكنك تصحيح قاموس .dic الذي تم إنشاؤه مسبقًا عن طريق مطابقة مراسلات الحرف.
على سبيل المثال ، بدلاً من الحرف a ، يعرض e. من الضروري أخذ سطر من القاموس e:
ryونقلها (حذف القديم) ، وتغيير الرسالة:
ryولكن نظرًا لأن الحرف "a" موجود بالفعل في القاموس ، فأنت بحاجة إلى إضافة "(2)" (أو 3،4) إلى الحرف ، بشكل عام ، رقم تسلسلي ، اعتمادًا على عدد الأصوات الموجودة بالفعل في القاموس:
a(2) ryإعادة تحويل القاموس ليست ضرورية. بهذه الطريقة البسيطة ، يمكنك "التقاط" الصوتيات من جميع الحروف ، تقريبًا.
Cherchez la femme
نموذج العمل والمفردات ، ولكن ليس بصوت الأنثى. إذا كان صوت captcha أنثى ، فلن نحصل على أي شيء في الإخراج. هذا أمر جيد وسيء في نفس الوقت. أولا عن الخير.
إذا لم تتعرف على أي شيء عند بدء تشغيل البرنامج ، فهذا يعني أننا نتعامل مع صوت أنثوي ، حتى تتمكن من تصفية captcha "الإناث".
ولكن ماذا تفعل معهم؟
هنا تحتاج إلى العمل مع التحويل.
على سبيل المثال ، مع كلمة التحقق "الذكور" ، كان التردد 16000 ، وبالنسبة للإناث "كلمة التحقق" 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

يتم تعريف جميع الأصوات (في كل سطر حسب الصوت) ، ولكن مراسلاتها عرجاء.
من الأفضل إنشاء قاموس منفصل للنموذج الإناث ثم تحريره.
ومع ذلك ، هذا هو للدراسة الذاتية.
روابط مفيدة:
1.
home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom2. http: //itnan.ru/post.php؟ C = 1 & p = 351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femmeملفات:
1.
البرنامج .
2.
النموذج .
3.
النموذج الروسي .
4.
القاموس .
5.
اختبار CAPTCHA .
6.
ffmpeg .
7.
حزمة من captcha .