تحية! من العنوان ، لقد فهمت بالفعل ما سأتحدث عنه. سيكون هناك الكثير من المتشددين:
سنناقش Java ، C ، C ++ ، المجمّع ، قليلاً من Linux ، قليلاً من نواة نظام التشغيل. سنقوم أيضًا بتحليل حالة عملية ، لذلك ستكون المقالة في ثلاثة أجزاء كبيرة (ضخمة جدًا).
في البداية ، سنحاول إخراج كل شيء من الملفات التعريفية الحالية.
في الجزء الثاني ، سنقوم بإنشاء ملف تعريف صغير خاص بنا ، وسنرى في الجزء الثالث كيفية تحديد ما هو غير مألوف في الملف الشخصي ، لأن الأدوات الحالية ليست مناسبة جدًا لهذا الغرض. إذا كنت على استعداد للذهاب بهذه الطريقة - أنا في انتظاركم تحت خفض :)
محتوى
الوقت ووسائل الفهم - التعريف
من وجهة النظر اليومية ، 1 ثانية صغيرة جدًا. لكننا نعلم أن الثانية هي مليار نانو ثانية كاملة. ودع الأمر يستغرق حوالي 4 دورات للمعالجات في الثانية الواحدة فقط من الثانية ، وفي غضون ثانية واحدة ، يتم إجراء الكثير من الأشياء في الكمبيوتر والتي يمكن أن تحسن أو تزيد من سوء حياتنا.
لنفترض أننا نقوم بتطوير تطبيق في حد ذاته مهم بما فيه الكفاية للسرعة ، وبالنسبة لبعض أجزاء الكود ، يعد هذا أمرًا بالغ الأهمية بوجه عام. يتم تنفيذ هذه القطع ، على سبيل المثال ، مئات من مايكروثانية - بسرعة كافية ، لكنها [
أقسام الكود ] تؤثر بشكل مباشر على نجاح طلبنا ومقدار الأموال المكتسبة أو المفقودة. على سبيل المثال
عند إرسال أوامر لإبرام معاملات الصرف ، قد يكلف تأخير 100 ميكروثانية التبادل مليون روبل أو أكثر على كل معاملة ، والتي تكتمل بواحد ، لا اثنين ، أو حتى لا مائة.
وتم تعيين
المهمة لي: من ناحية ، تحتاج إلى إرسال جميع الطلبات في نفس الوقت ، ومن ناحية أخرى ، أرسلها حتى يكون التباين بين الأول والأخير ضئيلاً. أي أنه كان من الضروري تحديد وظيفة ترسل أوامر إلى البورصة. مهمة نموذجية ، باستثناء فارق بسيط واحد: وقت التنفيذ المميز لهذه الوظيفة
أقل بكثير من 100 ميكرون .
دعنا نفكر في كيفية تعريفنا لمائة نسخة من أجل فهم ما يحدث في الداخل.
ما يجب مراعاته عند اختيار هذه الأداة؟
- نادراً ما يتم تنفيذ قسم الكود الذي يهمنا ، أي 100 ميكروثانية يتم تنفيذها في مكان ما مرة واحدة في الثانية. وهذا في مقعد الاختبار ، وفي الإنتاج أقل من ذلك.
- سيكون من الصعب عزل هذا الجزء من الشفرة في علامة microbenchmark ، لأنه يؤثر على جزء كبير من المشروع ، وحتى الإدخال / الإخراج عبر الشبكة.
- وأخيراً ، والأهم من ذلك ، أريد أن يتوافق ملف التعريف الناتج مع السلوك الذي سيكون على خوادم الإنتاج لدينا.
كيف نأخذ في الاعتبار كل هذه الفروق الدقيقة وتعرف بطريقة صحيحة على طريقة الفائدة؟
من الناحية النظرية ، يمكن تقسيم جميع ملفات التعريف إلى مجموعتين من
أدوات القياس أو
أخذ العينات . دعونا نفكر في كل مجموعة على حدة.
تساهم
ملفات تعريف الأدوات في الكثير من النفقات العامة لأنها تعدل رمزنا الثانوي وتضيف سجل توقيت فيه. ومن هنا فإن العائق الرئيسي لمثل هذه الملامح: يمكن أن تؤثر بشكل كبير على التعليمات البرمجية القابلة للتنفيذ. نتيجة لذلك ، سيكون من الصعب تحديد مقدار تطابق ملف التعريف الناتج مع السلوك على خوادم الإنتاج: قد تعمل بعض التحسينات بشكل مختلف ، وبعضها يحدث ، والبعض الآخر لا يعمل. ربما ، على نطاقات زمنية أخرى - الثواني والدقائق والساعات - سوف نحصل على بيانات تمثيلية. لكن على نطاق 100 μs ، يمكن أن يؤدي التحسين المُشَغَّل أو الفاشل إلى أن يكون الملف الشخصي غير ممثل تمامًا. لذلك دعونا نلقي نظرة فاحصة على مجموعة أخرى من المحللون.
تساهم
ملفات تخصيص العينات إما في الحد الأدنى أو المتوسط. لا تؤثر هذه الأدوات بشكل مباشر على التعليمات البرمجية القابلة للتنفيذ ، ويتطلب استخدامها مزيدًا من الاهتمام منك. لذلك ، سوف نتطرق إلى المحللون. دعونا نرى ما هي البيانات وبأي شكل سنتلقى منهم.
كيف يعمل المحللون لأخذ العينات؟
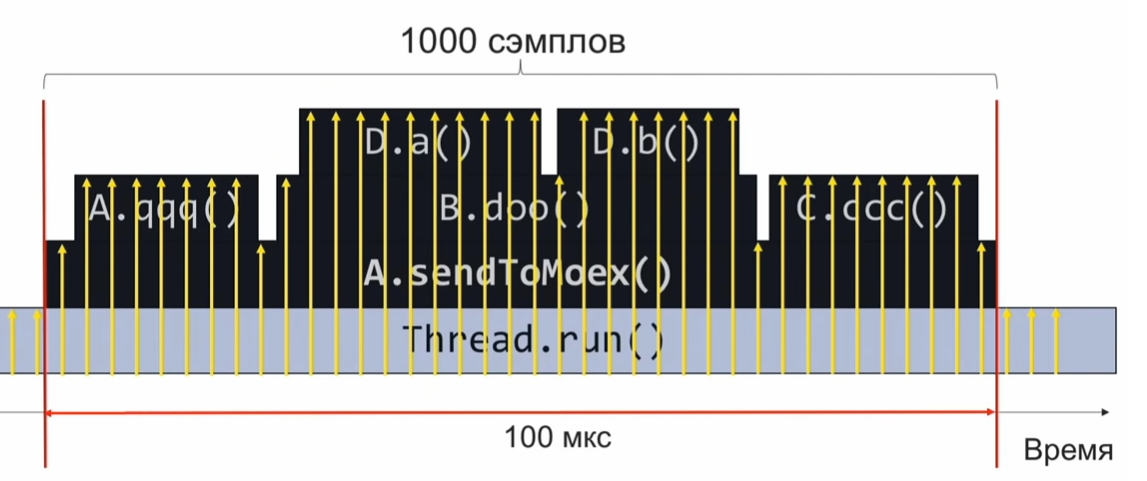
لفهم كيف يعمل منشئ ملفات التعريف أخذ العينات ، خذ بعين الاعتبار المثال التالي -
استدعاء الأسلوب
sendToMoex عدة طرق أخرى. نحن ننظر:
void sendToMoex() { a.qqq(); b.doo(); c.ccc() } void doo() { da(); db(); }
إذا راقبنا حالة مكدس الاستدعاءات وقت تنفيذ هذا القسم من البرنامج وقمنا بتسجيله بشكل دوري ، فسنحصل على المعلومات في النموذج التالي تقريبًا:

هذه مجموعة من مكدسات الاتصال. بافتراض أن العينات موزعة بالتساوي ، يشير عدد المكدسات المتطابقة إلى وقت التنفيذ النسبي للطريقة التي توجد أعلى الرصة.
في هذا المثال ، تم تنفيذ طريقة Da بقدر طريقة C.ccc ، وهذا يزيد مرتين عن طريقة Db. ومع ذلك ، قد لا يكون الافتراض بأن توزيع العينات صحيحًا تمامًا ، ومن ثم سيكون تقدير وقت التنفيذ غير صحيح.
كم مرة نحتاج إلى أخذ عينات؟
لنفترض أننا نريد أن نأخذ 1000 عينة في 100 ميكروثانية لفهم ما تم لعبه بالداخل. بعد ذلك ، نحسب بنسب بسيطة أننا إذا كنا بحاجة إلى إجراء 1000 عينة في 100 ،s ، فستكون 10 ملايين عينة في ثانية واحدة أو 1000000 عينة / ثانية.
إذا أخذنا عينات بهذه السرعة ، فعند تنفيذ الكود سنجمع 1000 عينة ونجمع ونفهم ما نجح بسرعة أو ببطء. بعد ذلك ، سوف نقوم بتحليل الأداء وضبط التعليمات البرمجية.
ومع ذلك ، فإن تردد 10 مليون عينة في الثانية هو الكثير. وإذا فشلنا في تحقيق مثل هذه السرعة من التنميط من البداية؟ افترض أننا جمعنا 10 عينات فقط لـ 10 عينات ، وليس 1000. في هذه الحالة ، نحتاج إلى انتظار التنفيذ التالي لرمز الملف التعريفي ، والذي سيحدث بعد ثانية واحدة (بعد كل شيء ، يتم تنفيذ التعليمات البرمجية المميزة مرة واحدة في الثانية). لذلك سوف نقوم بجمع 10 عينات أخرى. نظرًا لتوزيعها بالتساوي معنا ، يمكن دمجها في مجموعة مشتركة. يكفي الانتظار حتى يتم تنفيذ الكود الجانبي 1000/10 = 100 مرة ، وسنقوم بجمع 1000 عينة مطلوبة (10 عينات لكل منها 100 مرة).
اختيار منشئ ملفات التعريف
مسلحين بهذه المعرفة النظرية ، دعنا ننتقل إلى الممارسة.
خذ
منشئ ملفات التعريف. أداة رائعة (تستخدم استدعاء الجهاز الظاهري AsyncGetCallTrace) التي تجمع مكدس الاستدعاءات حتى تعليمة رمز البايت لجهاز Java الظاهري. معدل أخذ العينات المتزامن الأصلي هو
1000 عينة في الثانية الواحدة .
سنحل نسبة بسيطة: 1000000 عينة / ثانية - 1 ثانية ، 1000 عينة / ثانية - X ثانية.
لقد حصلنا على ذلك في التكرار القياسي لأخذ العينات من async-profiler ، وسوف يستغرق التنميط حوالي 3 ساعات. هذا وقت طويل من الناحية المثالية ، أرغب في تجميع ملف التعريف في أسرع وقت ممكن ، مباشرة بسرعة فائقة.
دعونا نحاول رفع تردد التشغيل
Async-profiler . للقيام بذلك ، في الملف التمهيدي ، نجد العلامة
-i ، التي تحدد الفاصل الزمني لأخذ العينات. دعنا نحاول تعيين علامة
-i1 (1 نانوثانية) ، أو
-i0 بشكل عام ، بحيث عينات منشئ ملفات التعريف دون توقف. حصلت على تردد حوالي 2.5 ألف عينة في الثانية. في هذه الحالة ، ستكون المدة الإجمالية للتوصيف حوالي ساعة واحدة. بالطبع ، ليس 3 ساعات ، ولكن أيضا ليست سريعة جدا. يبدو أنه من أجل تحقيق سرعات التنميط المطلوبة ، تحتاج إلى القيام بشيء مختلف نوعيًا ، للوصول إلى مستوى جديد.
لتحقيق ترددات أعلى بشكل ملحوظ ، يجب عليك التخلي عن استدعاء AsyncGetCallTrace واستخدام
perf ، وهو بروفايل Linux المتفرغ الموجود في كل توزيع لنظام Linux. ومع ذلك ، لا يعرف perf شيئًا عن Java ، ولا يزال يتعين علينا تدريب perf للعمل مع Java. في غضون ذلك ، دعونا نحاول الركض على هذا النحو المخيف:
$ perf record –F 10000 -p PID -g -- sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: .. 0.215 MB perf.data (4032 samples) ]
المزيد عن التدوين- سجل perf يعني أننا نريد تسجيل ملف تعريف.
- علامة
-F و الوسيطة 10،000 هي معدل أخذ العينات. - تشير علامة
-p إلى أننا نريد ملف تعريف PID المحدد لعملية Java الخاصة بنا فقط. - علامة
-g مسؤولة عن جمع مكدسات المكالمات. - أخيرًا ، في حالة النوم 1 ، نقصر إدخال ملف التعريف على ثانية واحدة.
لماذا نحتاج إلى جمع مكدسات المكالمات؟ نحن نحدد كل شيء على التوالي ، ثم من البيانات التي تم جمعها نستخرج الجزء الذي يهمنا (الطريقة المسؤولة عن تشكيل وإرسال الطلبات). علامة أن العينة التي تم جمعها تنتمي إلى البيانات التي نهتم بها هي وجود إطار مكدس
استدعاء الأسلوب
sendToMoex .
تعلم perf لبناء ملف تعريف تطبيق Java.
نقوم بتنفيذ الأمر perf record ... ، انتظر 1 ثانية ، وقم بتشغيل البرنامج النصي perf لمعرفة ما تم لمحة عنه؟ وسنرى شيئًا غير واضح جدًا:
$ perf script java 8079 2008793.746571: 3745505 cycles:uppp: 7fa1e88b53f8 [unknown] (/tmp/perf-11038.map) java 8079 2008793.747565: 3728336 cycles:uppp: 7fa1e88b5372 [unknown] (/tmp/perf-11038.map) java 8079 2008793.748613: 3731147 cycles:uppp: 7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
يبدو أنها عناوين ، لكن لا توجد أسماء لأساليب Java. لذلك ، تحتاج إلى تعليم perf لمطابقة هذه العناوين مع أسماء الطرق.
في عالم C و C ++ ، يتم استخدام معلومات تصحيح الأخطاء المزعومة لمطابقة العناوين وأسماء الوظائف. يتم تخزين المراسلات في قسم خاص من الملف القابل للتنفيذ: طريقة واحدة تكمن في مثل هذه العناوين ، طريقة أخرى تكمن في عناوين أخرى. Perf يسحب هذه المعلومات ويقوم بإجراء تعيين.
من الواضح أن برنامج التحويل البرمجي JIT للجهاز الظاهري لا يُنشئ معلومات تصحيح الأخطاء بهذا التنسيق. لا يزال أمامنا طريقة أخرى - كتابة البيانات على المراسلات الخاصة بالعناوين وأسماء الطرق في ملف خريطة perf خاص ، والذي سيعامله perf كإضافة إلى معلومات تصحيح الأخطاء المقروءة. يجب أن يكون ملف perf-map هذا في مجلد tmp وأن يحتوي على بنية البيانات التالية:
العمود الأول هو عنوان بداية رمز الطريقة ، والثاني هو طوله ، والعمود الثالث هو اسم الطريقة.
لذلك ، نحن بحاجة إلى إنشاء ملف مماثل. من الواضح أن هذا لا يمكن القيام به يدويًا (كيف نعرف في عناوين برنامج التحويل البرمجي JIT الذي سيضع الكود) ، لذلك سوف نستخدم البرنامج النصي create-java-perf-map.sh من مشروع perf-map-agent ، لتمريره من PID لعملية Java الخاصة بنا . الملف جاهز ، والتحقق من محتوياته ، وتشغيل perf-script مرة أخرى.
$ perf script java 8080 1895245.867498: cycles:uppp: 7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868176: 2127960 cycles:uppp: 7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868737: 1959990 cycles:uppp: 7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)
فويلا! نرى أسماء أساليب جافا! ما حدث للتو: قمنا بتدريس ملف التعريف perf ، الذي لا يعرف شيئًا عن Java ، لملف تعريف تطبيق Java عادي ومشاهدة طرق جافا الساخنة لهذا التطبيق!
ومع ذلك ، لتحليل أداء جزء البرنامج الذي نقوم باستجوابه ، ليس لدينا ما يكفي من مكدس الاستدعاءات لتصفية البيانات المهمة من جميع العينات التي تم جمعها.
كيفية الحصول على مكدس مكالمة؟أنت الآن بحاجة إلى القيام بشيء آخر باستخدام perf أو جهاز افتراضي للحصول على مكدسات المكالمات. لفهم ما يجب القيام به ، دعنا نتراجع ونرى كيف تعمل المكدس بشكل عام. تخيل أن لدينا ثلاث وظائف f1 ، f2 ، f3. علاوة على ذلك ، تستدعي f1 f2 ، و f2 تستدعي f3.
void f1() { f2(); } void f2() { f3(); } void f3() { ... }
في الوقت الذي
f3 تنفيذ الوظيفة
f3 ، دعنا نرى حالة المكدس في. نرى سجل
rsp ، والذي يشير إلى الجزء العلوي من المكدس. نعلم أيضًا أن الرصة لها عنوان إطار الرصة السابق. وكيف يمكنني الحصول على مكدس استدعاء؟
إذا استطعنا بطريقة ما الحصول على عنوان هذه المنطقة ، فعندئذ يمكننا أن نتخيل المكدس كقائمة متصلة ببساطة وفهم تسلسل المكالمات التي أوصلتنا إلى نقطة التنفيذ الحالية.
ماذا نحتاج لهذا؟ نحتاج إلى سجل rbp إضافي سوف يشير إلى المنطقة الصفراء. اتضح أن سجل rbp يسمح لـ perf بالحصول على مكدس الاتصال ، لفهم التسلسل الذي أوصلنا إلى النقطة الحالية. أوصي بقراءة هذه التفاصيل في
واجهة النظام الثنائية للتطبيق V. يصف كيف يتم استدعاء الأساليب في Linux.

لقد فهمنا مشكلتنا. نحتاج إلى إجبار الجهاز الظاهري على استخدام سجل rbp لغرضه الأصلي - كمؤشر إلى بداية إطار المكدس. هذه هي الطريقة التي يجب أن تستخدم برنامج التحويل البرمجي JIT سجل rbp. هناك إشارة PreserveFramePointer في الجهاز الظاهري لهذا. عند تمرير هذه العلامة إلى الجهاز الظاهري ، سيبدأ الجهاز الظاهري في استخدام سجل rbp لغرضه التقليدي. ثم يمكن أن تدور Perf المكدس. وحصلنا على مكدس مكالمة حقيقية في الملف الشخصي. ساهم العلم من قبل بريندان جريج سيئة السمعة في JDK8u60 فقط.
نبدأ الجهاز الظاهري مع العلم الجديد. قم بتشغيل
create-java-perf-map ، ثم
perf record perf script . الآن يمكننا إنشاء ملف تعريف دقيق مع مكدسات المكالمات:
$ perf script java 18657 1901247.601878: 979583 cycles:uppp: 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7f285d007b10 Interpreter (...) 7f285d0004e7 call_stub (...) 67d0db [unknown] (... libjvm.so) ... 708c start_thread (... libpthread-2.26.so)
علمنا منشئ ملفات التعريف perf ، المضمّن في معظم توزيعات Linux ، العمل مع تطبيقات Java. لذلك ، لا يمكننا الآن رؤية الأقسام الساخنة من الشفرة فحسب ، ولكن أيضًا تسلسل المكالمات التي أدت إلى النقطة الساخنة الحالية. إنجاز رائع ، بالنظر إلى أن profiler perf لا يعرف شيئًا عن java. نحن فقط علمنا كل هذا!
زيادة معدل أخذ العينات perf
دعونا نحاول رفع تردد التشغيل إلى 10 مليون عينة في الثانية. الآن لدينا تردد أقل بكثير.
لأتمتة جميع المهام التي قمنا بها للتو ، يمكنك استخدام البرنامج النصي
perf-java-record-stack من مشروع perf-map-agent. لديه قلم رائع - متغير البيئة
perf_record-freq ، حيث يمكنك ضبط تردد أخذ العينات. أولاً ، دعونا نضع 100 ألف عينة في الثانية ونحاول تشغيلها. تظهر رسالة فظيعة في وحدة التحكم بأننا تجاوزنا الحد الأقصى المسموح به لتكرار أخذ العينات:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID ... Maximum frequency rate (30000) reached. Please use -F freq option with lower value or consider tweaking /proc/sys/kernel/perf_event_max_sample_rate. ...
في حالتي ، كان الحد 30 ألف عينة في الثانية. يقول Perf على الفور أي وسيطة kernel تحتاج إلى إصلاح ، والتي
sysctl إما باستخدام echo sudo tee إلى الملف المطلوب ، أو مباشرة من خلال
sysctl . لذلك:
$ echo '1000000' | sudo tee /proc/sys/kernel/perf_event_max_sample_rate
او نحو ذلك:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
الآن نحن نقول للنواة أن الحد الأقصى للتردد هو الآن مليون عينة في الثانية الواحدة. نبدأ منشئ ملفات التعريف مرة أخرى ونشير إلى تكرار 200 ألف عينة في الثانية. سيعمل الملف التعريفي لمدة 15 ثانية ويمنحنا مليون عينة. يبدو أن كل شيء على ما يرام. على الأقل لا توجد رسائل خطأ هائلة. ولكن ما هو التردد الذي حصلنا عليه بالفعل؟ اتضح أن فقط 70 ألف عينة في الثانية الواحدة. ما الخطأ الذي حدث؟
دعنا نرى إخراج
dmesg :
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700 ... [84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
هذا هو ناتج نواة لينكس. لقد أدركنا أننا نأخذ عينات في كثير من الأحيان ، ويستغرق الكثير من الوقت ، وبالتالي فإن النواة تخفض التردد. اتضح أننا نحتاج إلى فك مقبض آخر في kernel - يطلق عليه
kernel.perf_cpu_time_max_percent ويتحكم في مقدار الوقت الذي يمكن أن تنفقه kernel على المقاطعات من perf.
سوف نطلب تردد أخذ العينات من 200 ألف عينة في الثانية الواحدة. وبعد 15 ثانية نحصل على 3 ملايين عينة - 200 ألف عينة في الثانية.
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID Recording events for 15 seconds ... ... [ perf record: Captured ... (2.961.252 samples) ]
الآن دعونا نرى الملف الشخصي. تشغيل
perf script :
$ perf script ... java ... native_write_msr (/.../vmlinux) java ... Loop2.main (/tmp/perf-29621.map) java ... native_write_msr (/.../vmlinux) ...
نرى وظائف غريبة والوحدة القابلة للتنفيذ vmlinux - نواة لينكس. هذا بالتأكيد ليس رمزنا. ماذا حدث؟ تبين أن التردد كان مرتفعًا لدرجة أن كود النواة بدأ يسقط في العينات. أي أنه كلما زاد التردد ، كلما كانت هناك عينات لا تتعلق بشفرتنا ، بل بنواة Linux.
طريق مسدود.
نستخدم (صراحة) الأحداث PMU / PEBS الأجهزة
ثم قررت تجربة استخدام تقنية أجهزة PMU / PEBS - وحدة مراقبة الأداء ، أخذ العينات وفقًا لأحداث دقيقة. يسمح لك بتلقي إعلامات بأن حدثًا قد حدث بعدد معين من المرات. وهذا ما يسمى "الفترة". على سبيل المثال ، قد نتلقى إعلامات حول تنفيذ المعالج لكل تعليمات العشرين. لنلقِ نظرة على مثال. اسمح بتطبيق xor الآن ، والحصول على عداد PMU القيمة 18 ؛ ثم تأتي التعليمات mov - العداد 19؛ والتعليمات التالية ،
إضافة٪ r14 ،٪ r13 ، ستظهر وحدة إدارة المشروع كـ "ساخن".
ثم تبدأ دورة جديدة: يتم تنفيذ
inc - تتم إعادة تعيين وحدة إدارة المشروع إلى 1. وتكرارات قليلة للدورة تمر. في النهاية ، نتوقف عند تعليمات
mov ، تستجمع وحدة إدارة المشروع 19. بيان الإضافة التالي ، ومرة أخرى نحتفل به. انظر القائمة:
mov aaa, bbbb xor %rdx, %rdx L_START: mov $0x0(%rbx, %rdx),%r14 add %r14, %r13 ; (PMU "") cmp %rdx,100000000 jne L_START
لا تلاحظ الشذوذ؟ دورة من خمس تعليمات ، ولكن في كل مرة نحتفل بنفس التعليمات بأنها ساخنة. من الواضح أن هذا غير صحيح: فكل التعليمات "ساخنة". إنهم يقضون الوقت أيضًا ، ونحن نحتفل بواحد فقط. والحقيقة هي أنه بين الفترة والعداد لعدد الإرشادات في التكرار لدينا عامل مشترك 4. يتضح أنه في كل تكرار رابع سنضع نفس التعليمات كـ "ساخن". لتجنب هذا السلوك ، تحتاج إلى اختيار رقم كفترة يتم فيها تقليل احتمال حدوث مقسوم مشترك بين عدد التكرارات في الحلقة والعداد نفسه. من الناحية المثالية ، ينبغي أن تكون الفترة أولية ، أي مشاركة فقط على نفسك وعلى الوحدة. على سبيل المثال أعلاه: يجب عليك اختيار فترة تساوي 23. ثم سنضع علامة بالتساوي على جميع التعليمات في هذه الدورة بأنها "ساخنة".
تم دعم تقنية PMU / PEBS في شكلها الحديث منذ عام 2009 على الأقل ، أي أنها متوفرة على أي كمبيوتر تقريبًا. لتطبيقه بشكل صريح ، دعنا
perf-java-record-stack بتعديل البرنامج النصي
perf-java-record-stack . استبدل علامة
-F بـ
-e ، التي تحدد بشكل صريح استخدام PMU / PEBS.
... sudo perf record -F $PERF_RECORD_FREQ ... ...
تحويل البرنامج النصي:
... sudo perf record -e cycles –c 10007 ... ...
أنت تعرف بالفعل ما هي الخصائص التي يجب أن تمتلكها أي فترة - نحتاج إلى رقم أولي. بالنسبة لحالتنا ، ستكون الفترة 10007.
أطلقوا النص المعدل المعدل لـ java-record-stack وحصلوا على 4.5 مليون عينة في 15 ثانية - ما يقرب من 300 ألف عينة في الثانية الواحدة ، عينة واحدة كل 3 ميكروثانية. وهذا هو ، لتنفيذ واحد من التعليمات البرمجية لدينا لمحة ، ل 100 wes سوف نجمع 33 عينات. في هذا التردد ، يبلغ إجمالي وقت جمع البيانات الشخصية 30 ثانية فقط. لا تشرب حتى كوب من القهوة! في الواقع ، كل شيء أكثر تعقيدًا بقليل. ماذا يحدث إذا بدأ تنفيذ التعليمات البرمجية لدينا ليس مرة واحدة في الثانية ، ولكن مرة واحدة كل 5 ثوان؟ عندها ستنمو مدة التوصيف إلى 2.5 دقيقة ، وهي أيضًا نتيجة جيدة.
لذلك ، في 30 ثانية ، يمكنك الحصول على ملف تعريف يغطي جميع احتياجات بحثنا بالكامل. الفوز؟
لكن شعور بعض الخدعة القذرة لم يتركني. لنعد إلى الموقف الذي يتم فيه تنفيذ التعليمات البرمجية الخاصة بنا كل 5 ثوانٍ. بعد ذلك ، يستغرق التنميط 150 ثانية ، سنجمع خلالها حوالي 45 مليون عينة. من بين هؤلاء ، نحتاج إلى 1000 فقط ، أي 0.002٪ من البيانات التي تم جمعها. كل شيء آخر هو القمامة ، التي تبطئ عمل الأدوات الأخرى وتضيف النفقات العامة. نعم ، تم حل المشكلة ، ولكن تم حلها في الجبهة ، وقوة ، كليلة حادة.
وفي ذلك المساء ، عندما حصلت على ملف تعريف تفصيلي لأول مرة بمساعدة perf ، كان لدي حلم. كنت ذاهبة إلى المنزل من العمل والتفكير ، لكن سيكون من الرائع أن تتمكن المكواة من تجميع الملف الشخصي نفسه وحتى دقة المجهرية والثانية ، وسنقوم بتحليل النتائج فقط. هل يتحقق حلمي؟ ما رايك
ملخص قصير:
- لإنشاء ملف تعريف لتطبيق Java باستخدام perf ، تحتاج إلى إنشاء ملف يحتوي على معلومات حول الرموز باستخدام برامج نصية من مشروع perf-map-agent
- لجمع معلومات ليس فقط حول مقاطع التعليمات البرمجية الساخنة ، ولكن أيضًا عن المكدسات ، تحتاج إلى تشغيل جهاز ظاهري باستخدام علامة -XX: + علامة PreserveFramePointer
- إذا كنت ترغب في زيادة معدل أخذ العينات ، يجب الانتباه إلى sysctl'and kernel.perf_cpu_time_max_percent و kernel.perf_event_max_sample_rate.
- إذا بدأت عينات من النواة غير المرتبطة بالتطبيق في الدخول إلى الملف الشخصي ، يجب أن تفكر في تحديد فترة PMU / PEBS صراحة.
هذه المقالة (وأجزائها التالية) هي نسخة من التقرير ، مقتبسة في شكل نص. إذا كنت لا ترغب في القراءة فقط ، ولكن أيضًا الاستماع إلى التوصيفات ، في
إشارة إلى العرض التقديمي.