مرحبا يا هبر.
هذا المقال هو استمرار منطقي لتصنيف
أفضل مقالات هبر لعام 2018 . وعلى الرغم من أن السنة لم تنته بعد ، ولكن كما تعلمون ، في الصيف ، كانت هناك تغييرات في القواعد ، وبالتالي ، فقد أصبح من المثير للاهتمام معرفة ما إذا كانت تؤثر على أي شيء.

بالإضافة إلى الإحصائيات نفسها ، سيتم تقديم تصنيف محدث للمقالات ، بالإضافة إلى عدد قليل من أكواد المصدر لأولئك المهتمين بكيفية عمل ذلك.
بالنسبة لأولئك الذين يرغبون في ما حدث ، واصلت تحت الخفض. أولئك الذين يرغبون في إجراء تحليل أكثر تفصيلاً لأقسام الموقع يمكنهم أيضًا رؤية
الجزء التالي .
مصدر البيانات
هذا التصنيف غير رسمي ، وليس لدي أي بيانات داخلية. كما ترون بسهولة ، وبالنظر إلى شريط العناوين في المتصفح ، فإن جميع المقالات في Habré لها ترقيم من طرف إلى طرف. التالي هو مسألة تقنية ، لقد قرأنا جميع المقالات في صف واحد في دورة (في سلسلة رسائل واحدة مع إيقاف مؤقت حتى لا يتم تحميل الخادم). تم الحصول على القيم نفسها بواسطة محلل بسيط في Python (رمز المصدر
هنا ) وتخزينها في ملف CSV من هذا النوع تقريبًا:
2019-08-11T22:36Z,https://habr.com/ru/post/463197/,"Blazor + MVVM = Silverlight , ",votes:11,votesplus:17,votesmin:6,bookmarks:40,views:5300,comments:73
2019-08-11T05:26Z,https://habr.com/ru/news/t/463199/," NASA ",votes:15,votesplus:15,votesmin:0,bookmarks:2,views:1700,comments:7تحويل
للتحليل سوف نستخدم بيثون وبانداس وماتبلوتليب. بالنسبة لأولئك الذين لا يهتمون بالإحصاءات ، يمكنهم تخطي هذا الجزء والانتقال فورًا إلى المقالات.
تحتاج أولاً إلى تحميل مجموعة البيانات في الذاكرة وتحديد البيانات للسنة المطلوبة.
import pandas as pd import datetime import matplotlib.dates as mdates from matplotlib.ticker import FormatStrFormatter from pandas.plotting import register_matplotlib_converters df = pd.read_csv("habr.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ') df['datetime'] = dates year = 2019 df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (df['datetime'] < pd.Timestamp(datetime.date(year+1, 1, 1)))] print(df.shape)
اتضح أنه لهذا العام (على الرغم من أنه لم ينته بعد) في وقت كتابة هذا التقرير ، تم نشر 12715 مقالة. للمقارنة ، على مدار عام 2018 - 15904. بشكل عام ، الكثير - حوالي 43 مقالة في اليوم (وهذا فقط بتصنيف إيجابي ، كم عدد المقالات التي تم تنزيلها سلبية أو محذوفة ، يمكنك تخمين أو حذف تقريبًا معرفات).
حدد الحقول اللازمة من مجموعة البيانات. كمقاييس ، سوف نستخدم عدد مرات المشاهدة والتعليقات وقيم التصنيف وعدد الإشارات المرجعية المضافة.
def to_float(s):
الآن تمت إضافة البيانات إلى مجموعة البيانات ، ويمكننا استخدامها. تجميع البيانات حسب اليوم واتخاذ القيم المتوسطة.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.median().reset_index() grouped['counts'] = days_count['counts'] counts_per_day = grouped['counts'].values counts_per_day_avg = grouped['counts'].rolling(window=20).mean() view_per_day = grouped['views'].values view_per_day_avg = grouped['views'].rolling(window=20).mean() votes_per_day = grouped['votes'].values votes_per_day_avg = grouped['votes'].rolling(window=20).mean() bookmarks_per_day = grouped['bookmarks'].values bookmarks_per_day_avg = grouped['bookmarks'].rolling(window=20).mean()
الآن بالنسبة للجزء الممتع ، يمكننا إلقاء نظرة على الرسوم البيانية.
دعونا نرى عدد المنشورات على حبري في عام 2019.
import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (16, 8) fig, ax = plt.subplots() plt.bar(year_days, counts_per_day, label='Articles/day') plt.plot(year_days, counts_per_day_avg, 'g-', label='Articles avg/day') plt.xticks(rotation=45) ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y")) ax.xaxis.set_major_locator(mdates.MonthLocator(interval=1)) plt.legend(loc='best') plt.tight_layout() plt.show()
النتيجة مثيرة للاهتمام. كما ترون ، هبر قليلاً "النقانق" خلال العام. لا أعرف السبب.

للمقارنة ، يبدو 2018 "أكثر سلاسة":

بشكل عام ، لم أر أي انخفاض حاد في عدد المقالات المنشورة في عام 2019 على الرسم البياني. علاوة على ذلك ، على العكس من ذلك ، يبدو أنه نما قليلاً منذ الصيف.
لكن الرسمين التاليين يثبطانني قليلاً.
متوسط مرات المشاهدة لكل مقالة:

تصنيف متوسط لكل مادة:
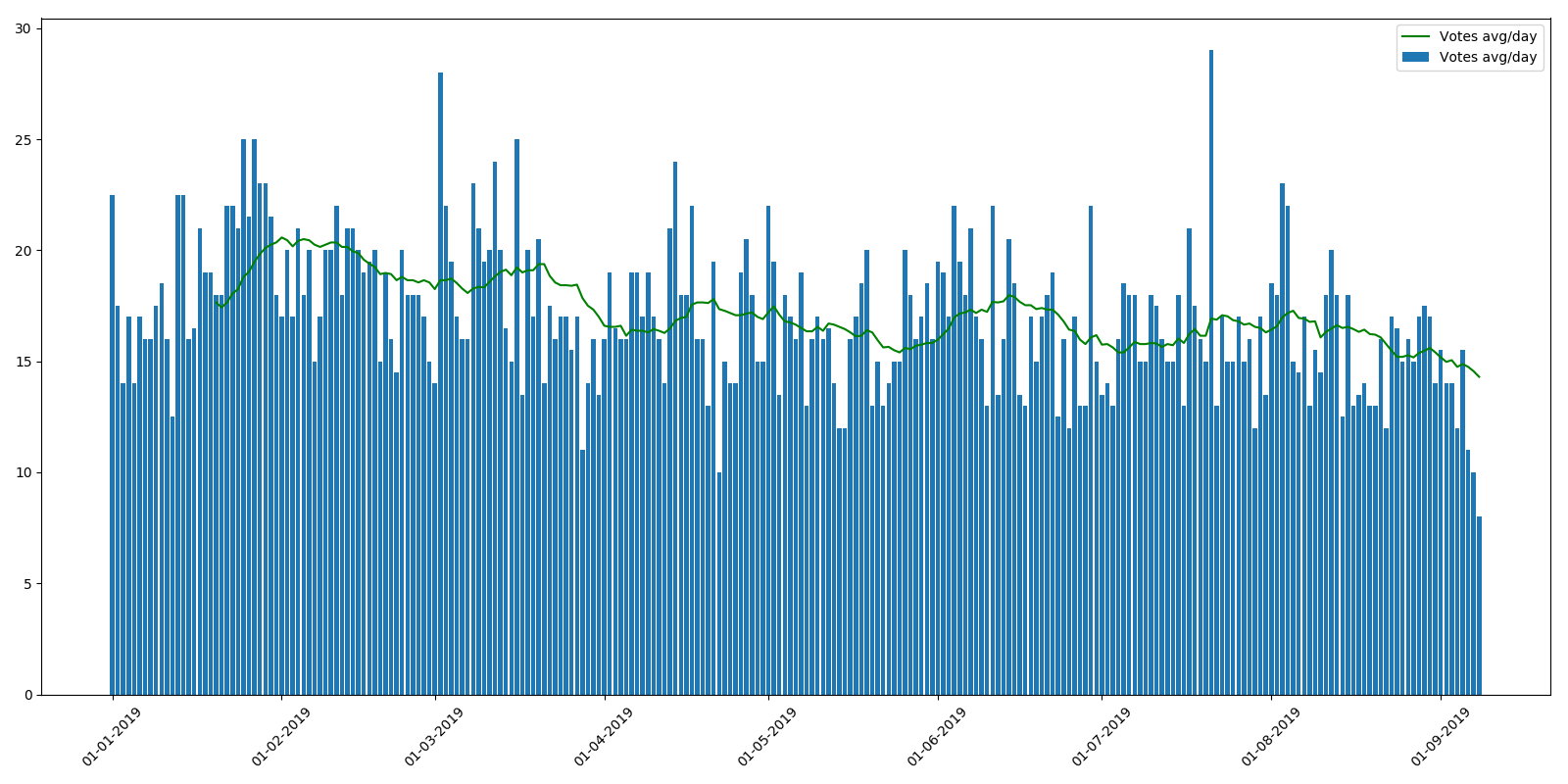
كما ترون ، انخفض متوسط عدد مرات المشاهدة خلال العام قليلاً. يمكن تفسير ذلك بحقيقة أن المقالات الجديدة لم يتم فهرستها بعد بواسطة محركات البحث ، ولا يتم العثور عليها كثيرًا. لكن الانخفاض في متوسط التصنيف لكل مقالة هو أمر غير مفهوم. الشعور هو أن القراء إما ببساطة ليس لديهم الوقت لتصفح العديد من المقالات أو عدم الاهتمام بالتقييمات. من وجهة نظر برنامج مكافأة المؤلفين ، هذا الاتجاه غير سارة للغاية.
بالمناسبة ، لم يكن هذا هو الحال في عام 2018 ، والجدول الزمني أكثر أو أقل.
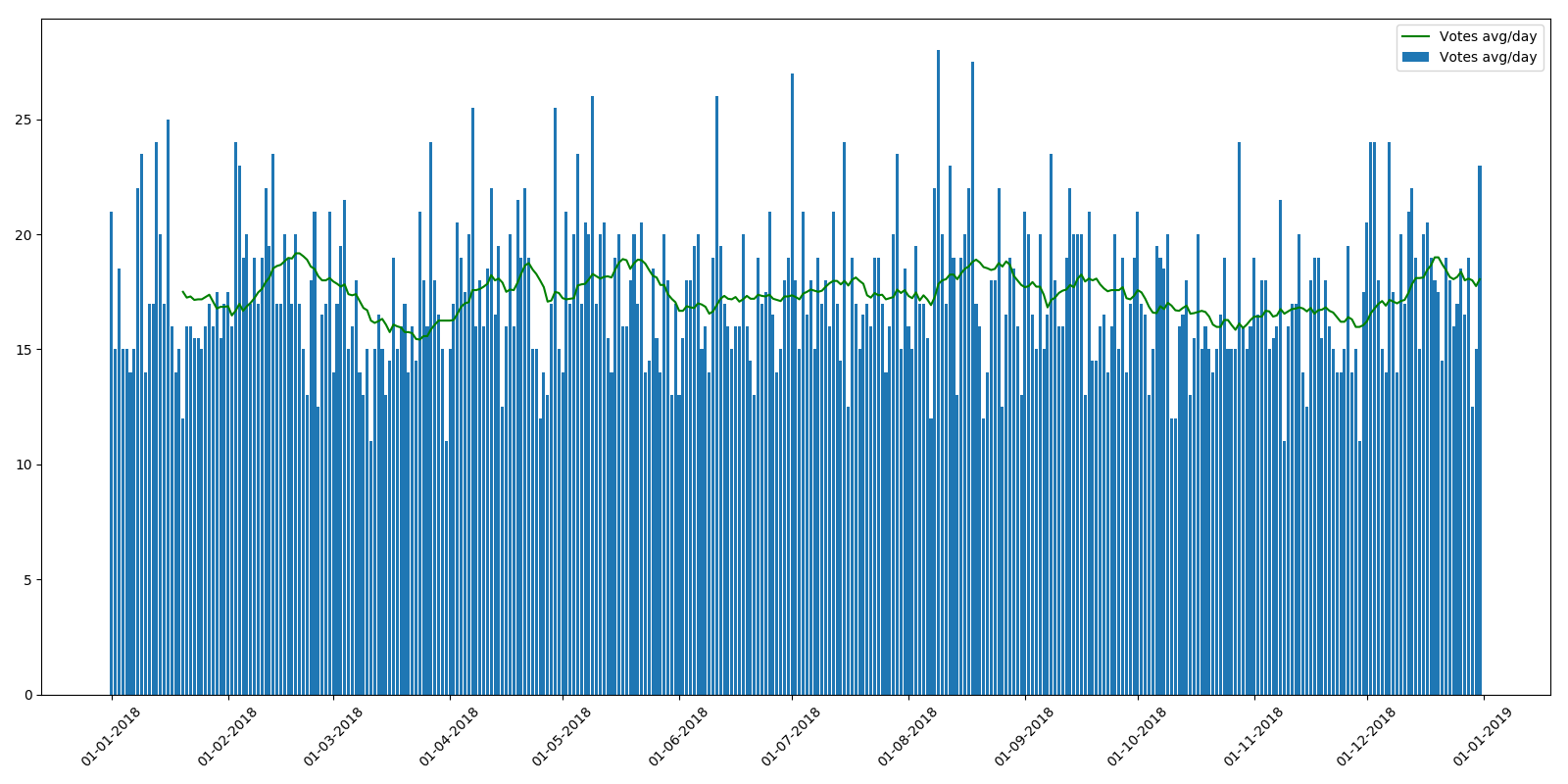
بشكل عام ، لدى مالكي الموارد شيء للتفكير فيه.
ولكن دعونا لا نتحدث عن الأشياء الحزينة. بشكل عام ، يمكننا القول أن هابر "نجا" من التغييرات الصيفية بنجاح كبير ، ولم ينخفض عدد المقالات على الموقع.
تصنيف
الآن ، في الواقع ، التقييم. مبروك للذين ضربوه. واسمحوا لي أن أذكرك مرة أخرى بأن التقييم غير رسمي ، وربما فاتني شيء ما ، وإذا كان من المؤكد أن يكون هناك مقال هنا ، لكنه ليس كذلك ، سأضيفه يدويًا. كتقييم ، أستخدم المقاييس المحسوبة ، والتي يبدو لي أنها مثيرة للاهتمام للغاية.
أعلى مشاهدة الموادأهم المقالات عن نسبة التقييمات إلى المشاهداتأهم المقالات عن نسبة التعليقات إلى المشاهداتأعلى المقالات الأكثر إثارة للجدلأعلى تصنيف الموادأعلى المواد المرجعيةأعلى من قبل عرض نسبة المرجعيةأعلى تعليق الموادوأخيرًا ، آخر منع للإيقاف بعدد الكراهية- تقاعد في 22،922 تعليقًا ، التقييم + 259.0 / -100.0
- قرأت 80 يستأنف ، لدي أسئلة ، 635 تعليقات ، تصنيف + 135.0 / -94.0
- عزيزي ، نحن نقتل الإنترنت ، 933 تعليقات ، تصنيف + 392.0 / -83.0
- الدولة و T- القتلة ، 752 تعليقات ، تصنيف + 83.0 / -80.0
- Windows 2019 , ? , 881 , +123.0/-70.0
- : , . 1 , 394 , +100.0/-68.0
- ' ': 109 , , , 361 , +240.0/-68.0
- , . , 259 , +101.0/-63.0
- , , 1271 , +131.0/-63.0
- - , 179 , +147.0/-62.0
- , 668 , +315.0/-60.0
- , 597 , +208.0/-60.0
- , 246 , +105.0/-59.0
- , , 215 , +141.0/-58.0
- , 1098 , +131.0/-58.0
- Go , 70 , +76.0/-57.0
- '-' , 272 , +154.0/-55.0
- Apple , 96 , +90.0/-52.0
- , 764 , +164.0/-52.0
- خمسة اتجاهات مخيفة للتنمية الحديثة ، 262 تعليقات ، تصنيف + 95.0 / -52.0
يا للعجب. لدي بعض العينات الأكثر إثارة للاهتمام ، لكنني لن أتحمل القراء.استنتاج
عند بناء التصنيف ، لفتت الانتباه إلى نقطتين بدت مثيرة للاهتمام.أولا ، بعد كل شيء ، 60 ٪ من أعلى هي المقالات في هذا النوع geektimes. ما إذا كان سيكون هناك عدد أقل منها العام المقبل ، وكيف سيبدو هابر بدون مقالات حول البيرة ، والفضاء ، والدواء ، وما إلى ذلك - لا أعرف. سوف تفقد القراء شيئا بالتأكيد. لنرى.
ثانياً ، تبين أن قمة المرجعية كانت عالية الجودة بشكل غير متوقع. هذا أمر مفهوم من الناحية النفسية ، وقد لا يهتم القراء بالتقييم ، وإذا كانت هناك حاجة لمقال ، فسوف يقومون بإضافته إلى الإشارات المرجعية. وهنا فقط أكبر تركيز للمقالات المفيدة والخطيرة. أعتقد أنه يجب على مالكي الموقع النظر بطريقة أو بأخرى في العلاقة بين عدد الإشارات المرجعية وبرنامج الحوافز إذا كانوا يريدون زيادة هذه الفئة المعينة من المقالات هنا على حبري.شيء من هذا القبيل.
آمل أن تكون مفيدة.قائمة المقالات طويلة ، لكنها على الأرجح الأفضل. استمتع بالقراءة للجميع.