لقد
صادفت مؤخرًا
مجموعة بيانات Kaggle مع بيانات عن 45 ألف فيلم من Full MovieLens Dataset. لا تحتوي البيانات على معلومات حول الممثلين والطاقم والمؤامرة وما إلى ذلك ، بل تتضمن أيضًا التصنيفات التي وضعها مستخدمو الأفلام للأفلام (26 مليون تقييم من 270 ألف مستخدم).
مهمة قياسية لمثل هذه البيانات هو نظام التوصية. لكن لسبب ما ، حدث لي أن
أتنبأ بتصنيف فيلم بناءً على المعلومات المتاحة قبل صدوره . أنا لست متذوقًا للسينما ، وبالتالي أركز عادةً على المراجعات ، واختر ما تراه من الأخبار. لكن المراجعين متحيزون أيضًا إلى حد ما - فهم يشاهدون أفلامًا مختلفة كثيرًا عن المشاهد العادي. لذلك ، بدا من المثير للاهتمام توقع كيفية تقدير الفيلم من قبل الجمهور العام.
لذلك ، تحتوي مجموعة البيانات على المعلومات التالية:
- معلومات حول الفيلم: وقت الإصدار والميزانية واللغة والشركة وبلد المنشأ ، إلخ. وكذلك التصنيف المتوسط (وسوف نتوقع ذلك)
- الكلمات المفتاحية (العلامات) حول المؤامرة
- أسماء الجهات الفاعلة والطاقم
- في الواقع التقييمات (التقديرات)
الكود المستخدم في المقالة (بيثون) متاح على
جيثب .
تصفية البيانات مسبقا
تحتوي المجموعة الكاملة على بيانات عن أكثر من 45 ألف فيلم ، ولكن نظرًا لأن المهمة هي التنبؤ بالتصنيف ، فأنت بحاجة إلى التأكد من أن تصنيفات فيلم معين موضوعية. على سبيل المثال ، في حقيقة أن الكثير من الناس قدّروا ذلك.
معظم الأفلام لها تصنيفات قليلة جدًا:

بالمناسبة ، فاجأني الفيلم الذي حصل على أكبر عدد من التصنيفات (14075) - وهذا هو
"التأسيس" . لكن الثلاثة التالية - "فارس الظلام" و "الصورة الرمزية" و "المنتقمون" تبدو منطقية تمامًا.
من المتوقع أن يكون عدد التصنيفات وميزانية الفيلم مترابطين (ميزانية منخفضة - تقييمات أقل). لذلك ، فإن إزالة الأفلام التي تحتوي على عدد قليل من التصنيفات يجعل النموذج المنحاز تجاه أفلام أكثر تكلفة:
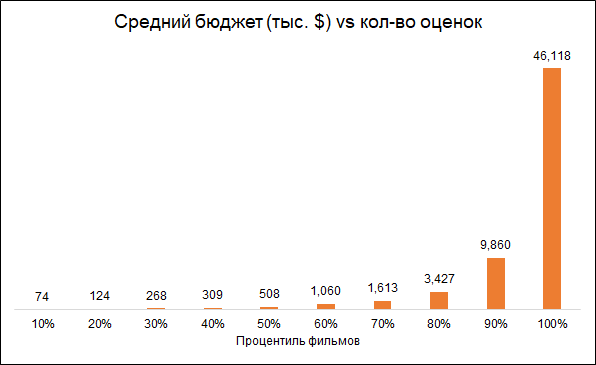
نترك أفلام التحليل مع 50+ تصنيفات.
بالإضافة إلى ذلك ، سنقوم بإزالة الأفلام التي تم إصدارها قبل بدء خدمة التصنيف (1996). المشكلة هنا هي أن الأفلام الحديثة يتم تصنيفها في المتوسط أسوأ من الأفلام القديمة ، وذلك ببساطة لأن من بين الأفلام القديمة التي يشاهدونها ويقيمونها الأفضل ، وبين الأفلام الحديثة ، كل شيء.
نتيجة لذلك ، تحتوي المجموعة النهائية على حوالي 6 آلاف فيلم.
الميزات المستخدمة
سوف نستخدم عدة مجموعات من الميزات:
- البيانات الوصفية للفيلم : ما إذا كان الفيلم ينتمي إلى "المجموعة" (سلسلة من الأفلام) ، وبلد الإصدار ، وشركة التصنيع ، ولغة الفيلم ، والميزانية ، والنوع ، وسنة وشهر إصدار الفيلم ، ومدته
- الكلمات الرئيسية: لكل فيلم هناك قائمة من العلامات التي تصف المؤامرة. نظرًا لوجود العديد من الكلمات ، تمت معالجتها على النحو التالي: تم تجميعها في مجموعات تشابه (على سبيل المثال ، حادث وحادث سيارة) ، استنادًا إلى هذه المجموعات والكلمات الفردية ، تم إجراء تحليل PCA ، وتم اختيار المكونات الأكثر أهمية من نتائجها. هذا خفض البعد من مساحة الميزة.
- "المزايا" السابقة للممثلين الذين قاموا ببطولة الفيلم. لكل ممثل ، تم تشكيل قائمة الأفلام التي قام ببطولتها في وقت سابق وحساب تصنيف هذه الأفلام. لذلك لكل فيلم تم تشكيل مؤشر يجمع نجاح الأفلام التي قام الممثلون بنجمة في وقت سابق.
- "جوائز الأوسكار". إذا كان الممثلون أو المخرج أو المنتج أو كاتب السيناريو أو المصور قد شاركوا سابقًا في فيلم رشح أو حصل على جائزة الأوسكار لأفضل فيلم أو اتجاه أو سيناريو ، فقد أخذ ذلك في الاعتبار في النموذج. بالإضافة إلى ذلك ، إذا كانت الجهات الفاعلة مرشحة أو فائزة بجائزة الأوسكار لأفضل ممثل مساعد أو دور دعم ، فقد تم أخذ ذلك في الاعتبار أيضًا. معلومات عن جوائز الأوسكار الواردة من ويكيبيديا.
بعض الإحصاءات مثيرة للاهتمام
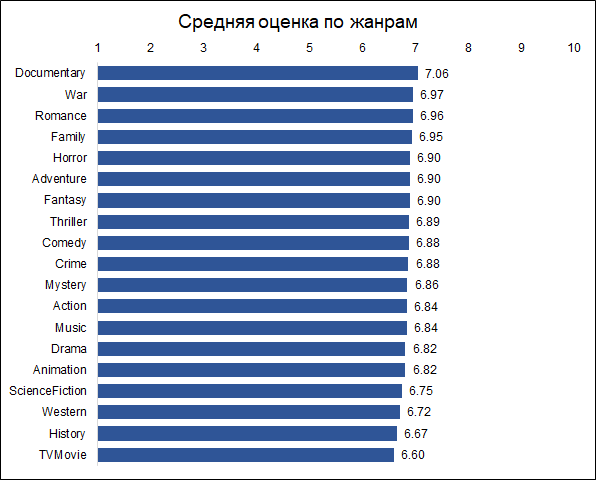
الأفلام الوثائقية تحصل على أعلى التصنيفات. هذا سبب وجيه للإشارة إلى أن الأفلام المختلفة يتم تقييمها من قبل أشخاص مختلفين ، وإذا تم تصنيف الأفلام الوثائقية حسب هواة الإجراءات ، فقد تكون النتائج مختلفة. أي أن التقديرات متحيزة بسبب التفضيلات الأولية للجمهور. ولكن هذا ليس مهمًا بالنسبة لمهمتنا ، لأننا نريد أن نتوقع تقييمًا غير موضوعي مشروطًا (كما لو كان كل مشاهد شاهد كل الأفلام) ، أي الفيلم الذي سيُمنح للجمهور الفيلم.
بالمناسبة ، من المثير للاهتمام أن الأفلام التاريخية تم تصنيفها أقل بكثير من الأفلام الوثائقية.
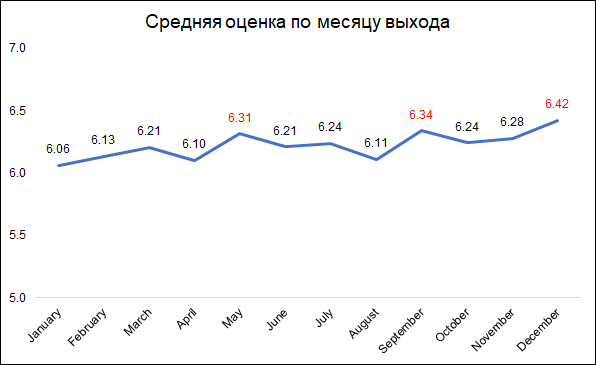
 يتم منح أعلى التصنيفات للأفلام التي تم إصدارها في ديسمبر وسبتمبر ومايو.
يتم منح أعلى التصنيفات للأفلام التي تم إصدارها في ديسمبر وسبتمبر ومايو.ربما يمكن تفسير ذلك على النحو التالي:
- في ديسمبر ، أصدرت الشركات أفضل الأفلام لجمع شباك التذاكر خلال عطلة عيد الميلاد
- في سبتمبر ، ستصدر أفلام تشارك في النضال من أجل جائزة الأوسكار
- مايو هو وقت الإفراج عن الافلام الصيفية.
 يعتمد تصنيف الأفلام قليلاً على الميزانية
يعتمد تصنيف الأفلام قليلاً على الميزانية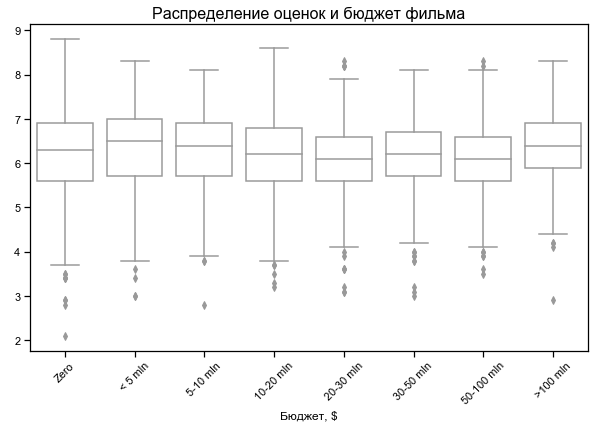
ميزانية صفر لبعض الأفلام - ربما لا توجد بيانات
أعلى تصنيف أقصر وأطول الأفلام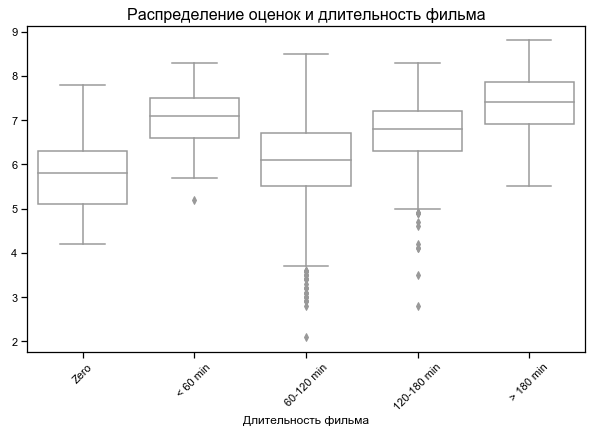
بالنسبة لبعض الأفلام ، يشار إلى مدة الصفر - ربما لا توجد بيانات
النتائج على مجموعات ميزات مختلفة
مهمتنا - التنبؤ التصنيف - مهمة الانحدار. سنختبر ثلاثة نماذج - الانحدار الخطي (مثل خط الأساس) و SVM و XGB. كمقياس للجودة ، نختار RMSE. يوضح الرسم البياني أدناه قيم RMSE على مجموعة التحقق من الصحة لطرز مختلفة ومجموعات مختلفة من الميزات (أردت أن أفهم ما إذا كان الأمر يستحق العبث بالكلمات الرئيسية ومع جوائز الأوسكار). تم تصميم جميع الطرز باستخدام معلمات تشعبية أساسية.
كما ترون ، تتمتع XGB بأفضل نتيجة مع مجموعة كاملة من الميزات (بيانات تعريف الفيلم + الكلمات الرئيسية + جوائز الأوسكار).
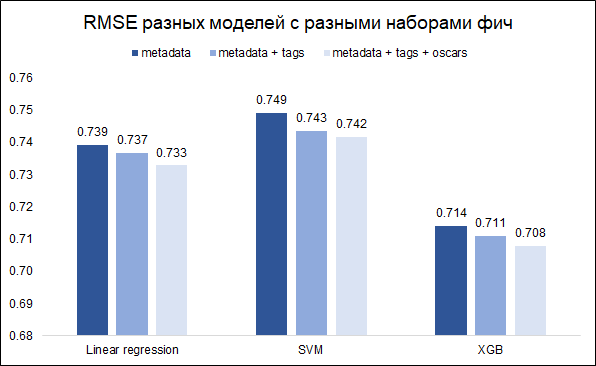
عن طريق ضبط المعلمات الفائقة ، كان من الممكن تقليل RMSE من 0.708 إلى 0.706
تحليل الأخطاء والتعليقات النهائية
نحن نفترض أن الأخطاء التي تقل عن 5٪ صغيرة (حوالي الثلث) ، والأخطاء التي تزيد عن 20٪ كبيرة (حوالي 10٪). في حالات أخرى (أكثر بقليل من النصف) سننظر في معدل الخطأ.
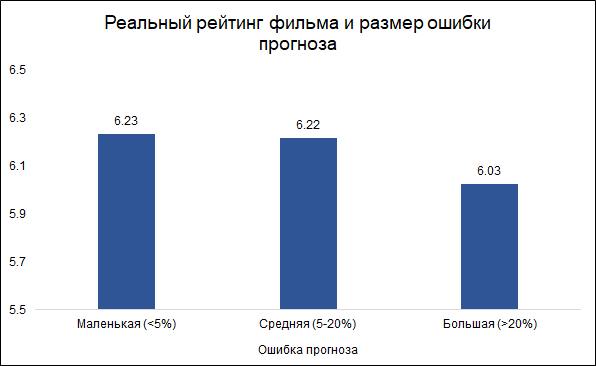
ومن المثير للاهتمام أن حجم الخطأ وتصنيف الفيلم مرتبطان:
فالأرجح أن يرتكب النموذج أخطاء في الأفلام الجيدة وفي أحيان كثيرة على أفلام سيئة. يبدو الأمر منطقيًا: الأفلام الجيدة ، مثلها مثل أي عمل آخر ، يصنعها أشخاص أكثر خبرة ومهنية. حول فيلم تارانتينو بمشاركة براد بيت ، يمكنك القول مقدمًا إنه على الأرجح سيظهر جيدًا. في الوقت نفسه ، يمكن أن يكون الفيلم منخفض الميزانية مع ممثلين غير معروفين جيدًا وسيئًا ، ومن الصعب الحكم عليه دون رؤيته.
فيما يلي أهم ميزات النموذج (تشير متغيرات PCA إلى الكلمات الرئيسية التي تمت معالجتها والتي تصف مؤامرة الفيلم):

تنتمي اثنتان من هذه الميزات إلى جوائز الأوسكار ، والتي تم ترشيحها مسبقًا من قبل أي من أعضاء الفريق (مخرج ، منتج ، كاتب سيناريو ، مصور) ، أو أفلام قام فيها الممثلون بنجمة. كما ذكر أعلاه ، يرتبط خطأ التوقع بتقييم الفيلم ، وبهذا المعنى ، يمكن أن تكون الترشيحات السابقة لجوائز الأوسكار محددًا جيدًا للنموذج. في الواقع ، الأفلام التي لديها ترشيح أوسكار واحد على الأقل (بين الممثلين أو الفرق) لديها متوسط خطأ متوقع قدره 8.3 ٪ ، وتلك التي ليس لديها مثل هذه الترشيحات - 9.8 ٪. من بين أفضل 10 ميزات مستخدمة في النموذج ، فإن ترشيحات أوسكار هي التي توفر أفضل اتصال مع حجم الخطأ.
لذلك ، ظهرت الفكرة لبناء نموذجين منفصلين: أحدهما للأفلام التي رشح فيها الممثلون أو الفريق لجائزة الأوسكار ، والثاني للبقية. كانت الفكرة أن هذا يمكن أن يقلل من الخطأ العام. ومع ذلك ، فشلت التجربة: أعطى النموذج العام RMSE 0.706 ، وقدم اثنان منفصلان 0.715.
لذلك ، سنترك النموذج الأصلي. نتائج دقتها هي كما يلي: RMSE في عينة التدريب - 0.688 ، في عينة التحقق من الصحة - 0.706 ، وفي عينة الاختبار - 0.732.
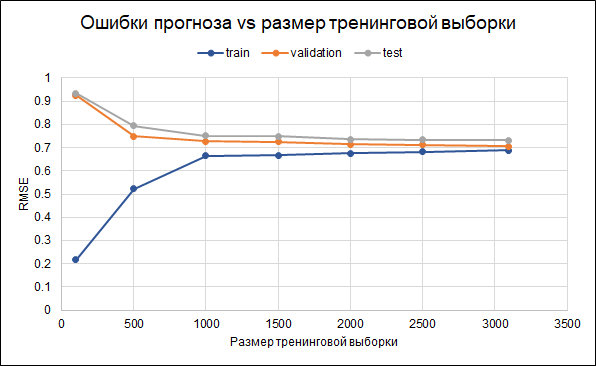
وهذا هو ، هناك بعض التحليق. تم بالفعل ضبط معلمات التنظيم في النموذج نفسه. هناك طريقة أخرى لتقليل التجاوز يمكن أن تتمثل في جمع المزيد من البيانات. لفهم ما إذا كان هذا سيساعد ، سنبني رسمًا بيانيًا للأخطاء لأحجام مختلفة من نموذج التدريب - من 100 إلى الحد الأقصى المتاح 3.000. يوضح الرسم البياني أنه بدءًا من حوالي 2.5 ألف نقطة في مجموعة التدريب ، والأخطاء في مجموعة التدريب والتحقق من صحتها وتغيير الاختبار صغيرة ، أي أن الزيادة في العينة لن يكون لها تأثير كبير.
 ماذا يمكنك أن تحاول تحسين النموذج:
ماذا يمكنك أن تحاول تحسين النموذج:- في البداية ، يتم اختيار الأفلام بشكل مختلف (حد مختلف لعدد الأصوات ، وحدود إضافية على المتغيرات الأخرى)
- لا يتم استخدام جميع التصنيفات لحساب التصنيف - فمن الممكن تحديد مستخدمين أكثر نشاطًا أو إزالة أولئك الذين يقدمون تقييمات سيئة فقط
- جرب طرقًا مختلفة لاستبدال البيانات المفقودة
ومن المثير للاهتمام ، أن فيلم "Batman and Robin" لعام 1997 كان أكبر خطأ في التنبؤ (7 نقاط تنبؤ بدلاً من 4.2 نقاط حقيقية). حصل الفيلم مع أرنولد شوارزنيجر وجورج كلوني وأوما ثورمان على
11 ترشيحًا لجائزة التوت الذهبي (وفوزًا
واحدًا) ، وتصدر
قائمة أسوأ 50 فيلمًا في التاريخ من Empire newsreel ، وأدى إلى
إلغاء التتمة وإعادة تشغيل السلسلة بأكملها . حسنا ، هنا النموذج ، ربما ، كان مخطئا تماما مثل رجل :)