كنت مهتمًا دائمًا بكيفية توزيع الكتب بشكل أفضل في مكتبتي الإلكترونية. ونتيجة لذلك ، توصلت إلى هذا الخيار مع حساب تلقائي لعدد الصفحات والأشياء الجيدة الأخرى. أطلب كل المهتمين تحت القط.
الجزء 1. دروببوإكس
جميع الكتب المتوفرة لدي في صندوق الإسقاط. هناك 4 فئات قمت بتقسيمها إلى كل شيء: كتاب ، مرجع ، فني ، غير فني. لكنني لا أضيف الكتب المرجعية إلى الجهاز اللوحي.
معظم الكتب هي .epub ، والباقي .pdf. وهذا هو ، الحل النهائي يجب أن تغطي بطريقة ما كلا الخيارين.
المسارات إلى الكتب هي شيء من هذا القبيل:
///// / .epub
إذا كان الكتاب خياليًا ، تتم إزالة الفئة (أي "التصميم" في الحالة أعلاه).
قررت عدم الإزعاج مع واجهة برمجة تطبيقات دروببوإكس ، لحسن الحظ لدي تطبيقهم الذي يقوم بمزامنة المجلد. أي أن الخطة هي: أخذ الكتب من مجلد ، وتشغيل كل كتاب من خلال عداد الكلمات ، وإضافته إلى Notion.
الجزء 2. إضافة خط
يجب أن يبدو الجدول نفسه شيئًا كهذا. تنبيه: من الأفضل القيام بأسماء الأعمدة بالأحرف اللاتينية.
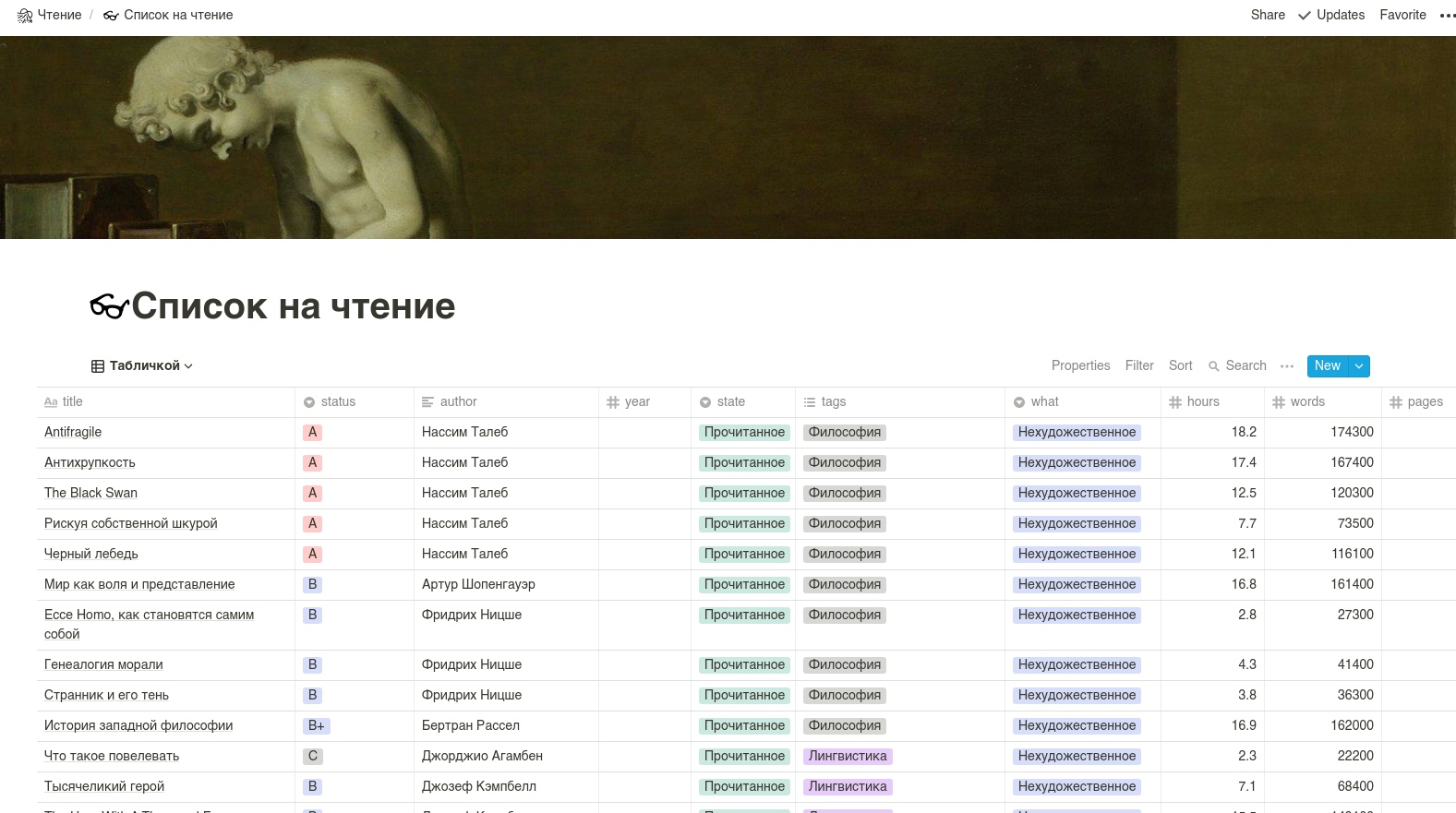
سنستخدم واجهة برمجة تطبيقات المفهوم غير الرسمية ، لأن الرسالة الرسمية لم يتم تسليمها بعد.

انتقل إلى Notion ، واضغط على Ctrl + Shift + J ، وانتقل إلى التطبيق -> ملفات تعريف الارتباط ، وانسخ token_v2 واتصل بها TOKEN. ثم نذهب إلى الصفحة التي نحتاجها مع لوحة المكتبة ونسخ الرابط. دعوة الفكرة.
ثم نكتب الرمز للتواصل مع Notion.
database = client.get_collection_view(NOTION) current_rows = database.default_query().execute()
بعد ذلك ، لنكتب وظيفة لإضافة سطر إلى الملصق.
def add_row(path, file, words_count, pages_count, hours): row = database.collection.add_row() row.title = file tags = path.split("/") if len(tags) >= 1: row.what = tags[0] if len(tags) >= 2: row.state = tags[1] if len(tags) >= 3: if tags[0] == "": row.author = tags[2] elif tags[0] == "": row.tags = tags[2] elif tags[0] == "": row.tags = tags[2] if len(tags) >= 4: row.author = tags[3] row.hours = hours row.pages = pages_count row.words = words_count
ما يجري هنا. نأخذ ونضيف صفًا جديدًا إلى الجدول في الصف الأول. بعد ذلك ، قمنا بتقسيم طريقنا بواسطة "/" والحصول على العلامات. العلامات - من حيث "الفني" ، "التصميم" ، من هو المؤلف وهلم جرا. ثم وضعنا جميع الحقول اللازمة للوحة.
الجزء 3. عد الكلمات والساعات وغيرها من المسرات
هذه مهمة أكثر تعقيدًا. كما نتذكر ، لدينا تنسيقان: epab و pdf. إذا كان كل شيء واضحًا مع epab - ربما هناك كلمات هناك ، فماذا عن pdf ليس بهذه البساطة: يمكن أن يتكون ببساطة من الصور الملصقة.
لذا فإن وظيفة حساب الكلمات في pdf ستبدو كما يلي: نحن نأخذ عدد الصفحات ونضربها في ثابت معين (متوسط عدد الكلمات في الصفحة).
ومن هنا:
def get_words_count(pages_number): return pages_number * WORDS_PER_PAGE
هذا هو WORDS_PER_PAGE لصفحة A4 حوالي 300.
الآن دعونا نكتب وظيفة لحساب الصفحات. سوف نستخدم PyPDF2 .
def get_pdf_pages_number(path, filename): pdf = PdfFileReader(open(os.path.join(path, filename), 'rb')) return pdf.getNumPages()
بعد ذلك ، سنكتب شيئًا صغيرًا لحساب الصفحات في epaba. نحن نستخدم epub_converter . هنا نأخذ كتابًا ، ونحوله إلى سطور ، ولكل سطر نحسب الكلمات.
def get_epub_pages_number(path, filename): book = open_book(os.path.join(path, filename)) lines = convert_epub_to_lines(book) words_count = 0 for line in lines: words_count += len(line.split(" ")) return round(words_count / WORDS_PER_PAGE)
الآن دعونا نفعل الوقت العد. نأخذ عدد الكلمات المفضل لدينا ونقسم على سرعة القراءة.
def get_reading_time(words_count): return round(((words_count / WORDS_PER_MINUTE) / 60) * 10) / 10
الجزء 4. توصيل جميع الأجزاء
نحن بحاجة إلى الالتفاف على جميع المسارات الممكنة في مجلد الكتب لدينا. تحقق مما إذا كان هناك بالفعل كتاب في Notion: إذا كان هناك بالفعل ، فلم نعد بحاجة إلى إنشاء سطر.
ثم نحتاج إلى تحديد نوع الملف ، بناءً على هذا ، حساب عدد الكلمات. أضف كتابًا في النهاية.
إليك الكود الذي نحصل عليه:
for root, subdirs, files in os.walk(BOOKS_DIR): if len(files) > 0 and check_for_excusion(root): for file in files: array = file.split(".") filetype = file.split(".")[len(array) - 1] filename = file.replace("." + filetype, "") local_root = root.replace(BOOKS_DIR, "") print("Dir: {}, file: {}".format(local_root, file)) if not check_for_existence(filename): print("Dir: {}, file: {}".format(local_root, file)) if filetype == "pdf": count = get_pdf_pages_number(root, file) else: count = get_epub_pages_number(root, file) words_count = get_words_count(count) hours = get_reading_time(words_count) print("Pages: {}, Words: {}, Hours: {}".format(count, words_count, hours)) add_row(local_root, filename, words_count, count, hours)
والوظيفة للتحقق مما إذا تم إضافة الكتاب تبدو كالتالي:
def check_for_existence(filename): for row in current_rows: if row.title in filename: return True elif filename in row.title: return True return False
استنتاج
شكرا لكل من قرأ هذا المقال. أتمنى أن تساعدك على قراءة المزيد :)