في هذه المقالة ، سنقوم بجمع لوحة القيادة لتحليلات كبار المسئولين الاقتصاديين. سنقوم بإلغاء تحميل البيانات من خلال البرامج النصية بيثون ومن خلال ملفات .csv.
ماذا سوف تفريغ؟
لتحليل ديناميكيات مواقف عبارات البحث ، ستحتاج إلى إلغاء التحميل من
Yandex.Webmaster و
Google Search Console . لتقييم "فائدة" ضخ موضع عبارة البحث ، ستكون بيانات التردد مفيدة. يمكن الحصول عليها من
Yandex.Direct وإعلانات Google . حسنًا ، لتحليل سلوك الجانب الفني للموقع ، سنستخدم
Page Speed Insider .
 كبار المسئولين الاقتصاديين ديناميات المرور
كبار المسئولين الاقتصاديين ديناميات المرورجوجل وحدة التحكم في البحث
للتفاعل مع API ، سوف نستخدم مكتبة
searchconsole . يصف github بالتفصيل كيفية الحصول على الرموز اللازمة لتسجيل الدخول. سيكون الإجراء الخاص بتحميل البيانات وتحميلها في قاعدة بيانات MS SQL كما يلي:
def google_reports():
Yandex.Webmaster
لسوء الحظ ، لا يمكن لمشرف الموقع تحميل سوى 500 عبارة بحث. تحميل التخفيضات حسب البلد ونوع الجهاز ، إلخ. هو لا يستطيع أيضا. نظرًا لهذه القيود ، بالإضافة إلى تحميل المواضع لـ 500 كلمة من مشرفي المواقع ، سنقوم بتحميل البيانات من Yandex.Metrica إلى الصفحات المقصودة. بالنسبة لأولئك الذين ليس لديهم العديد من عبارات البحث ، ستكون 500 كلمة كافية. إذا كان جوهرك الدلالي وفقًا لـ Yandex واسعًا بما يكفي ، فسيتعين عليك تفريغ المراكز من مصادر أخرى أو كتابة محلل موضعك.
def yandex_reports(): token = "..."
سرعة الصفحة من الداخل
يتيح لك تقييم سرعة تنزيل محتوى الموقع. إذا بدأ تحميل الموقع ببطء أكثر ، فإن هذا يمكن أن يقلل بدرجة كبيرة من موضع الموقع في نتائج البحث.
إعلانات جوجل وياندكس المباشر
لتقدير وتيرة استعلامات البحث ، نقوم بإلغاء تحميل وتيرة SEO الأساسية لدينا.
 توقعات ميزانية ياندكس
توقعات ميزانية ياندكس جوجل الكلمات الرئيسية مخطط
جوجل الكلمات الرئيسية مخططياندكس متري
تحميل البيانات على وجهات النظر والزيارات إلى صفحات تسجيل الدخول من حركة المرور كبار المسئولين الاقتصاديين.
token = token headers = {"Authorization": "OAuth " + token} now = datetime.now() fr = (now - timedelta(days = 9)).strftime("%Y-%m-%d") to = (now - timedelta(days = 3)).strftime("%Y-%m-%d") res = requests.get("https://api-metrika.yandex.net/stat/v1/data/?ids=ids&metrics=ym:s:pageviews,ym:s:visits&dimensions=ym:s:startURL,ym:s:lastsignSearchEngine,ym:s:regionCountry,ym:s:deviceCategory&date1={0}&date2={1}&group=all&filters=ym:s:lastsignTrafficSource=='organic'&limit=50000".format(fr,to), headers=headers) a = json.loads(res.text) re = pd.DataFrame(columns=['page', 'device', 'view', 'dt_from', 'dt_to', 'engine', 'visits', 'country', 'pageviews']) for i in a['data']: temp={} temp['page'] = i['dimensions'][0]['name'] temp['engine'] = i['dimensions'][1]['name'] temp['country'] = i['dimensions'][2]['name'] temp['device'] = i['dimensions'][3]['name'] temp['view'] = i['metrics'][0] temp['visits'] = i['metrics'][1] temp['pageviews'] = i['metrics'][0] temp['dt_from'] = fr temp['dt_to'] = to re=re.append(temp, ignore_index=True) to_sql_server(re, 'yandex_pages')
الحصول على البيانات في Power BI
دعونا نرى ما تمكنا من تفريغ:
- google_positions و yandex_positions
- google_frequency و yandex_frequency
- google_speed و yandex_speed
- yandex_metrika
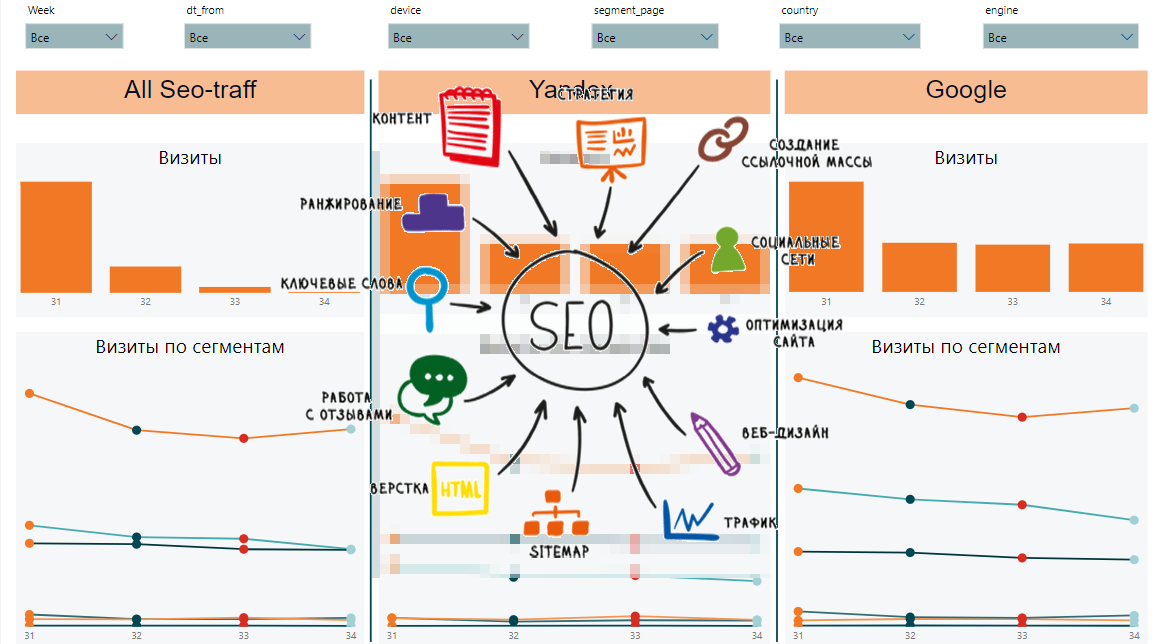
من هذه البيانات ، سنكون قادرين على جمع الديناميات حسب الأسبوع ، حسب القطاع ، والبيانات العامة حسب القطاعات والطلبات ، والديناميات والبيانات العامة حسب الصفحات وتنزيل سرعة المحتوى. هذا ما قد يبدو عليه التقرير النهائي:

من ناحية ، هناك الكثير من الإشارات المختلفة ومن الصعب فهم الاتجاهات العامة. من ناحية أخرى ، تعرض كل لوحة بيانات مهمة عن المواضع ، مرات الظهور ، النقرات ، نسبة النقر إلى الظهور ، سرعة تحميل الصفحة.
مقالات من الدورة: