
TL ؛ د
- لتحقيق درجة عالية من الملاحظة من الحاويات والخدمات المجهرية والمجلات والمقاييس الأولية ليست كافية.
- من أجل التعافي بشكل أسرع وزيادة تحمل الأخطاء ، يجب أن تطبق التطبيقات مبدأ قابلية الملاحظة العالية (HOP).
- على مستوى التطبيق ، يتطلب NRA: تسجيل مناسب ، ومراقبة دقيقة ، والفحوصات الصحية ، وتتبع الأداء / الانتقال.
- استخدم الجاهزية Probe والشيكات luberProbe Kubernetes كعنصر HOP .
ما هو قالب التحقق من الصحة؟
عند تصميم تطبيق مهم للغاية ومتوفر للغاية ، من المهم للغاية التفكير في شيء مثل التسامح مع الخطأ. يعتبر التطبيق متسامح مع الأخطاء إذا تمت استعادته بسرعة بعد الفشل. يستخدم التطبيق السحابي النموذجي بنية microservice - عند وضع كل مكون في حاوية منفصلة. وللتأكد من أن التطبيق على k8s يمكن الوصول إليه بشكل كبير ، عند تصميم مجموعة ، فأنت بحاجة إلى اتباع أنماط معينة. من بينها هو قالب التحقق من الصحة. يحدد كيفية قيام التطبيق بالإبلاغ عن k8s حول أدائه. هذه ليست فقط معلومات حول ما إذا كان جراب يعمل ، ولكن أيضا حول كيفية قبول الطلبات والرد عليها. كلما عرفت Kubernetes عن أداء جراب ، والقرارات الأكثر ذكاء التي تتخذها حول توجيه حركة المرور وموازنة التحميل. وبالتالي ، فإن مبدأ مراقبة عالية للتطبيق في الوقت المناسب للرد على الاستفسارات.
مبدأ الملاحظة العالية (NRA)
مبدأ قابلية الملاحظة العالية هو أحد مبادئ تصميم التطبيقات في حاويات . في بنية الخدمات المصغرة ، لا تهتم الخدمات بكيفية معالجة طلبها (وهو محق في ذلك) ، ولكن من المهم كيفية الحصول على إجابات من تلقي الخدمات. على سبيل المثال ، لمصادقة مستخدم ، ترسل حاوية واحدة طلب HTTP آخر ، في انتظار استجابة بتنسيق معين - هذا كل شيء. يمكن لـ PythonJS أيضًا التعامل مع الطلب ، ويمكن ل Python Flask الاستجابة. تشبه حاويات بعضها البعض الصناديق السوداء ذات المحتوى المخفي. ومع ذلك ، يتطلب مبدأ NRA من كل خدمة الكشف عن العديد من نقاط النهاية لواجهة برمجة التطبيقات والتي توضح مدى كفاءتها ، وكذلك حالة الاستعداد والتسامح مع الخطأ. يطلب Kubernetes من هذه المقاييس التفكير في الخطوات التالية للتوجيه وموازنة التحميل.
يسجل تطبيق السحاب المصمم جيدًا الأحداث الرئيسية الخاصة به باستخدام تدفقات الإدخال / الإخراج القياسية STDERR و STDOUT. بعد ذلك ، يتم تشغيل خدمة مساعدة ، على سبيل المثال ، filebeat أو logstash أو fluentd ، لتوصيل السجلات إلى نظام مراقبة مركزي (على سبيل المثال Prometheus) ونظام جمع السجلات (ELK software suite). يوضح الرسم البياني أدناه كيفية عمل التطبيق السحابي وفقًا لقالب التحقق من الصحة ومبدأ المراقبة العليا.
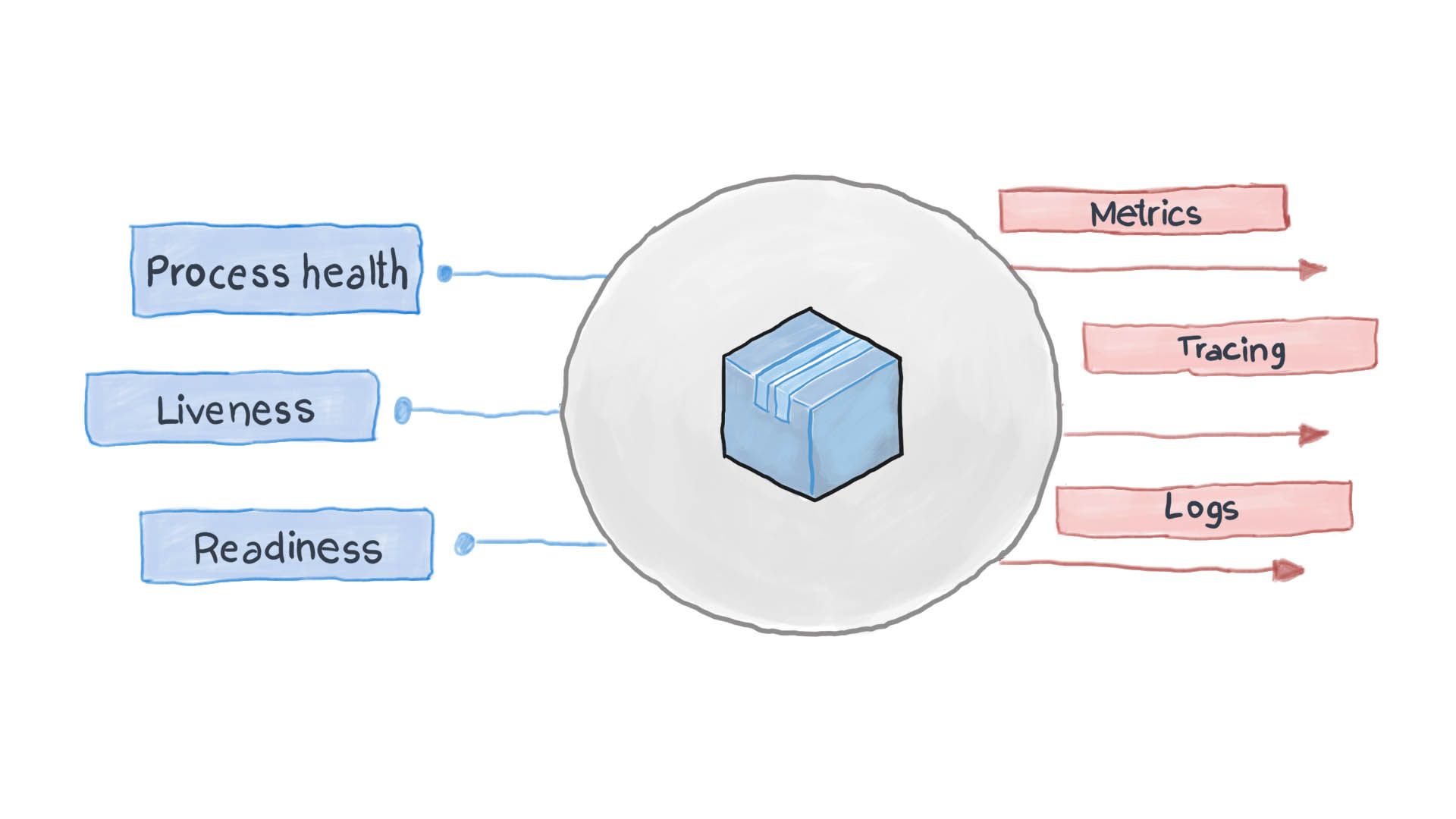
كيفية تطبيق Health Check Pattern في Kubernetes؟
من خارج الصندوق ، تراقب k8s حالة القرون باستخدام واحدة من وحدات التحكم (عمليات النشر ، و ReplicaSets ، و DaemonSets ، و StatefulSets ، وما إلى ذلك). بعد اكتشاف أن السنفرة قد سقطت لسبب ما ، تحاول وحدة التحكم إعادة تشغيلها أو نقلها إلى عقدة أخرى. ومع ذلك ، قد يبلغ pod أنه قيد التشغيل ، في حين أنه في حد ذاته لا يعمل. إليك مثال: تطبيقك يستخدم Apache كخادم ويب ، قمت بتثبيت المكون على عدة قرون من الكتلة. نظرًا لأن المكتبة لم يتم تكوينها بشكل صحيح ، فإن جميع طلبات التطبيق تستجيب بالكود 500 (خطأ خادم داخلي). عند التحقق من التسليم ، يعطي التحقق من حالة القرون نتيجة ناجحة ، ومع ذلك ، يفكر العملاء بشكل مختلف. وصفنا هذا الموقف غير المرغوب فيه على النحو التالي:
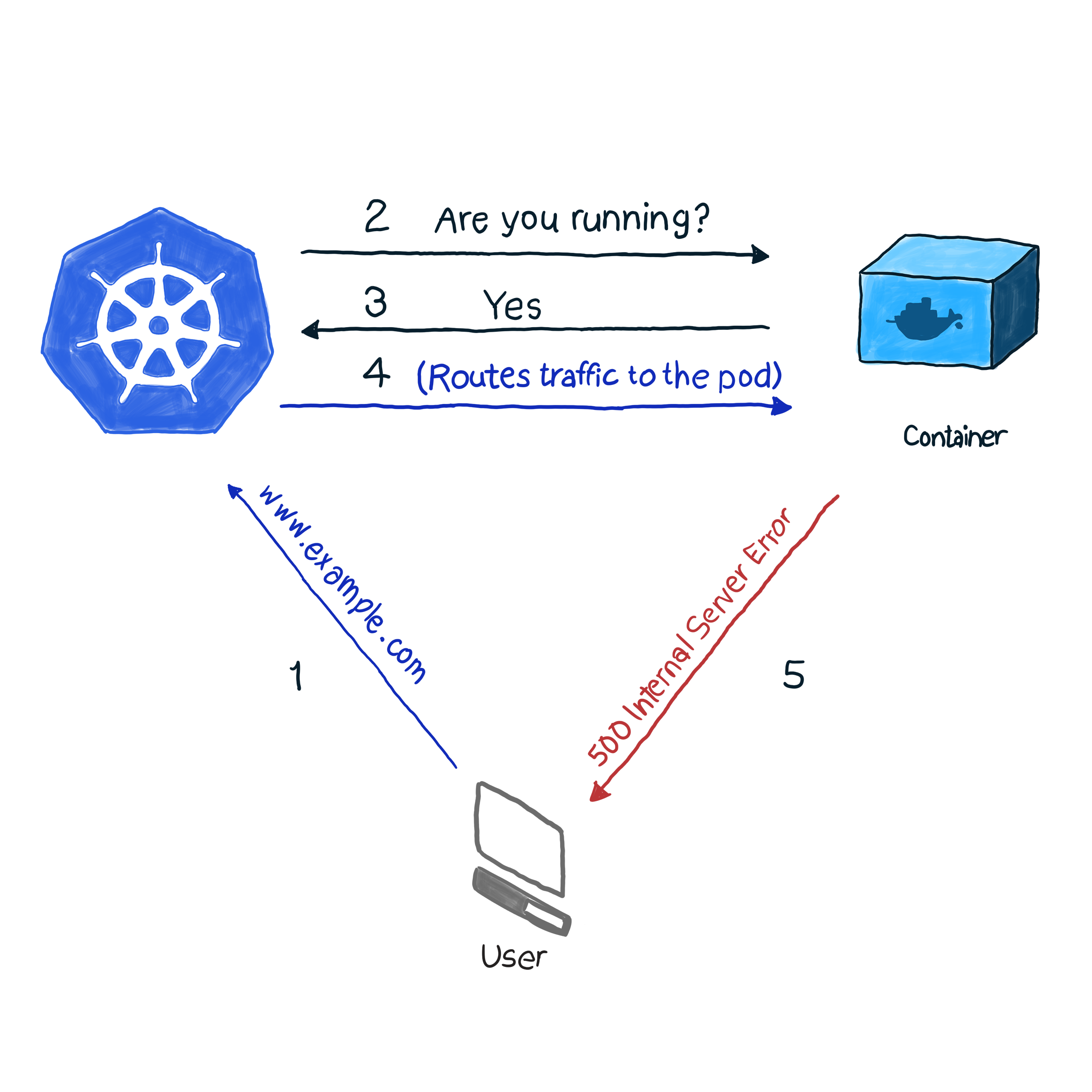
في المثال الخاص بنا ، يجري k8s فحصًا صحيًا . في هذا النوع من الفحص ، يتحقق kubelet باستمرار من حالة العملية في الحاوية. بمجرد أن يفهم أن العملية قد ارتفعت ، فإنه سيعيد تشغيلها. إذا تم التخلص من الخطأ بمجرد إعادة تشغيل التطبيق ، وتم تصميم البرنامج لإيقاف تشغيله عند وجود أي خطأ ، ثم اتباع NRA و Health Check Template ، يكون الفحص الصحي للعملية كافياً. إنه لأمر مؤسف أنه لا يتم إزالة جميع الأخطاء عن طريق إعادة التشغيل. في هذه الحالة ، توفر k8s طريقتين أعمق لاستكشاف أخطاء pod : livenessProbe و ReadinessProbe .
LivenessProbe
أثناء livenessProbe ، يُجري kubelet ثلاثة أنواع من الاختبارات: لا يكتشف فقط ما إذا كان جراب pod يعمل ، ولكن ما إذا كان جاهزًا لتلقي الطلبات والرد عليها بشكل كافٍ:
- تعيين طلب HTTP إلى جراب. يجب أن تحتوي الاستجابة على رمز استجابة HTTP في النطاق من 200 إلى 399. وهكذا ، تشير أكواد 5xx و 4xx إلى وجود مشكلة في الجراب ، حتى إذا كانت العملية قيد التشغيل.
- للتحقق من البرامج غير المرتبطة بخدمات HTTP (على سبيل المثال ، خادم بريد Postfix) ، يلزمك إنشاء اتصال TCP.
- تنفيذ أمر تعسفي للقرنة (داخليًا). يعتبر التحقق ناجحًا إذا كان رمز خروج الأمر 0.
مثال على كيفية عمل هذا. يحتوي تعريف pod التالي على تطبيق NodeJS يعطي خطأ 500 لطلبات HTTP. للتأكد من إعادة تشغيل الحاوية بعد تلقي هذا الخطأ ، نستخدم المعلمة livenessProbe:
apiVersion: v1 kind: Pod metadata: name: node500 spec: containers: - image: magalix/node500 name: node500 ports: - containerPort: 3000 protocol: TCP livenessProbe: httpGet: path: / port: 3000 initialDelaySeconds: 5
لا يختلف هذا عن أي تعريف .spec.containers.livenessProbe ، لكننا نضيف كائنًا .spec.containers.livenessProbe . تقبل المعلمة httpGet المسار حيث يتم إرسال طلب HTTP GET (في مثالنا ، هذا هو / ، ولكن في سيناريوهات المعركة قد يكون هناك أيضًا شيء مثل /api/v1/status ). ما زال livenessProbe يقبل المعلمة initialDelaySeconds ، والتي initialDelaySeconds عملية التحقق من الصحة لانتظار عدد محدد من الثواني. هناك حاجة إلى التأخير لأن الحاوية تحتاج إلى وقت للبدء ، وعند إعادة تشغيلها ، لن تكون متاحة لفترة من الوقت.
لتطبيق هذا الإعداد على كتلة ، استخدم:
kubectl apply -f pod.yaml
بعد بضع ثوان ، يمكنك التحقق من محتويات pod باستخدام الأمر التالي:
kubectl describe pods node500
العثور على ما يلي في نهاية الإخراج.
كما ترون ، بدأت livenessProbe طلب HTTP GET ، فقد أحدثت الحاوية خطأ 500 (الذي تمت برمجته لـ) ، وأعد kubelet إعادة تشغيله.
إذا كنت مهتمًا بكيفية برمجة تطبيق NideJS ، فإليك app.js و Dockerfile اللذين تم استخدامهما:
app.js
var http = require('http'); var server = http.createServer(function(req, res) { res.writeHead(500, { "Content-type": "text/plain" }); res.end("We have run into an error\n"); }); server.listen(3000, function() { console.log('Server is running at 3000') })
Dockerfile
FROM node COPY app.js / EXPOSE 3000 ENTRYPOINT [ "node","/app.js" ]
من المهم الانتباه إلى هذا: لن تعيد livenessProbe تشغيل الحاوية إلا في حالة حدوث عطل. إذا لم تعمل إعادة التشغيل على إصلاح الخطأ الذي يتعارض مع تشغيل الحاوية ، فلن تتمكن kubelet من اتخاذ التدابير اللازمة للقضاء على العطل.
readinessProbe
يعمل readinessProbe بشكل مشابه لـ livenessProbes (طلبات GET واتصالات TCP وتنفيذ الأوامر) ، باستثناء إجراءات تحري الخلل وإصلاحه. لا يتم إعادة تشغيل الحاوية التي يتم تسجيل الفشل فيها ، ولكنها معزولة عن حركة المرور الواردة. تخيل أن إحدى العبوات تقوم بالكثير من العمليات الحسابية أو تحت الحمل الثقيل ، مما يزيد من وقت الاستجابة للطلبات. في حالة livenessProbe ، يتم تشغيل فحص توفر الاستجابة (عبر معلمة فحص timeoutSeconds) ، وبعد ذلك تقوم kubelet بإعادة تشغيل الحاوية. عند بدء تشغيله ، تبدأ الحاوية في أداء مهام كثيفة الاستخدام للموارد وإعادة تشغيلها مرة أخرى. هذا يمكن أن يكون حاسما للتطبيقات التي تهتم سرعة الاستجابة. على سبيل المثال ، السيارة في الطريق في انتظار استجابة من الخادم ، يتم تأخير الاستجابة - وتعطل السيارة.
دعنا نكتب تعريف الجاهزية الذي يحدد وقت الاستجابة لطلب GET لمدة لا تزيد عن ثانيتين ، وسوف يستجيب التطبيق لطلب GET في 5 ثوانٍ. يجب أن يبدو ملف pod.yaml كما يلي:
apiVersion: v1 kind: Pod metadata: name: nodedelayed spec: containers: - image: afakharany/node_delayed name: nodedelayed ports: - containerPort: 3000 protocol: TCP readinessProbe: httpGet: path: / port: 3000 timeoutSeconds: 2
توسيع جراب مع kubectl:
kubectl apply -f pod.yaml
انتظر بضع ثوان ، ثم انظر إلى كيفية عمل الجاهزية:
kubectl describe pods nodedelayed
في نهاية الاستنتاج ، يمكنك أن ترى أن بعض الأحداث تشبه هذا .
كما ترون ، لم يقم kubectl بإعادة تشغيل برنامج pod عندما تجاوز وقت المسح 2 ثانية. بدلا من ذلك ، ألغى الطلب. يتم إعادة توجيه الاتصالات الواردة إلى القرون الأخرى العاملة.
ملاحظة: الآن وبعد إزالة الحمل الزائد من الحافظة ، يرسل kubectl الطلبات إليه مرة أخرى: لم تعد الردود على طلب GET تتأخر.
للمقارنة: فيما يلي ملف app.js المعدل:
var http = require('http'); var server = http.createServer(function(req, res) { const sleep = (milliseconds) => { return new Promise(resolve => setTimeout(resolve, milliseconds)) } sleep(5000).then(() => { res.writeHead(200, { "Content-type": "text/plain" }); res.end("Hello\n"); }) }); server.listen(3000, function() { console.log('Server is running at 3000') })
TL ؛ د
قبل ظهور التطبيقات السحابية ، كانت السجلات هي الوسيلة الرئيسية لمراقبة حالة التطبيقات والتحقق منها. ومع ذلك ، لم يكن هناك أي وسيلة لاتخاذ أي خطوات استكشاف الأخطاء وإصلاحها. السجلات مفيدة اليوم ، يجب جمعها وإرسالها إلى نظام تجميع السجل لتحليل حالات الطوارئ واتخاذ القرارات. [ كل هذا يمكن القيام به دون استخدام التطبيقات السحابية monit ، على سبيل المثال ، ولكن مع k8s أصبح أسهل بكثير :) - Ed. ]
اليوم ، يجب إجراء التصحيحات في الوقت الفعلي تقريبًا ، لذلك يجب ألا تكون التطبيقات مربعات سوداء. لا ، يجب عليهم إظهار نقاط النهاية التي تسمح لأنظمة المراقبة بطلب وجمع بيانات قيمة عن حالة العمليات حتى يتمكنوا من الاستجابة على الفور إذا لزم الأمر. هذا يسمى قالب Health Check Design ، الذي يتبع مبدأ المراقبة العليا (NRA).
تقدم Kubernetes افتراضيًا نوعين من الفحوصات الصحية: الجاهزية و livenessProbe. كلاهما يستخدم نفس أنواع الاختبارات (طلبات HTTP GET ، اتصالات TCP ، وتنفيذ الأوامر). أنها تختلف في القرارات التي يتم اتخاذها استجابة للمشاكل في القرون. تقوم livenessProbe بإعادة تشغيل الحاوية على أمل ألا يحدث الخطأ مرة أخرى ، وأن يعزل ReadinessProbe الحافظة من حركة المرور الواردة حتى يتم حل سبب المشكلة.
يجب أن يتضمن التصميم المناسب للتطبيق كلا النوعين من التحقق وأنهما يجمعان بيانات كافية ، خاصةً عند إنشاء استثناء. يجب أن يُظهر أيضًا نقاط نهاية واجهة برمجة التطبيقات الضرورية التي تنقل مقاييس الحالة الصحية المهمة إلى نظام المراقبة (وتسمى أيضًا بروميثيوس).