تحية ، الخبروفيت! تهانينا للجميع في يوم المبرمج وشاركنا ترجمة المقال الذي تم إعداده خصيصًا لطلاب الدورة التدريبية "High Load Architect" . "Shardirovat. أو لا قشرة. بدون محاولة ".
"Shardirovat. أو لا قشرة. بدون محاولة ".
- يوداسننتقل اليوم إلى فصل البيانات بين عدة خوادم MySQL. لقد انتهينا من المشاركة في بداية عام 2012 ، ولا يزال هذا النظام يستخدم لتخزين بياناتنا الأساسية.
قبل أن نناقش كيفية مشاركة البيانات ، دعنا نتعرف عليها بشكل أفضل. قم بإعداد ضوء لطيف ، واحصل على الفراولة في الشوكولاتة ، وتذكر اقتباسات من Star Trek ...
Pinterest هو محرك بحث عن كل ما يهمك. من حيث البيانات ، Pinterest هو أكبر رسم بياني لمصالح الإنسان في جميع أنحاء العالم. يحتوي على أكثر من 50 مليار دبوس تم حفظها من قبل المستخدمين على أكثر من مليار لوحة. يحتفظ الأشخاص ببعض المسامير لأنفسهم ومثل الدبابيس الأخرى ، والاشتراك في المسامير واللوحات والاهتمامات الأخرى ، وعرض موجز ويب لجميع المسامير واللوحات والاهتمامات التي اشتركوا فيها. ! ممتاز الآن لنجعلها قابلة للتطوير!
نمو مؤلم
في عام 2011 ، بدأنا في اكتساب الزخم. حسب بعض
التقديرات ، لقد نمت بشكل أسرع من أي شركة ناشئة معروفة في ذلك الوقت. حوالي سبتمبر 2011 ، كان كل مكون من بنيتنا الأساسية مثقلاً. كان لدينا العديد من تقنيات NoSQL تحت تصرفنا ، وكلها فشلت كارثية. كان لدينا أيضًا العديد من عبيد MySQL ، والتي اعتدنا قراءتها ، والتي تسببت في الكثير من الأخطاء الاستثنائية ، خاصة عند التخزين المؤقت. قمنا بإعادة بناء نموذج التخزين بالكامل. للعمل بكفاءة ، ونحن نقترب بعناية من تطوير المتطلبات.
متطلبات
- يجب أن يكون النظام بأكمله مستقرًا جدًا وسهل الاستخدام ويتدرج من حجم صندوق صغير إلى حجم القمر مع نمو الموقع.
- يجب أن يكون كل المحتوى الذي تم إنشاؤه بواسطة القلم متاحًا على الموقع في أي وقت.
- يجب أن يدعم النظام طلب المسامير N الموجودة على اللوحة بترتيب محدد (على سبيل المثال ، بالترتيب العكسي لوقت الإنشاء أو بالترتيب المحدد من قبل المستخدم). وينطبق الشيء نفسه على مثل pinners ، دبابيس بهم ، الخ
- للبساطة ، يجب أن تسعى للحصول على التحديثات بكل طريقة ممكنة. للحصول على الاتساق اللازم ، ستكون هناك حاجة إلى ألعاب إضافية ، مثل مجلة المعاملات الموزعة. إنه ممتع و (ليس كذلك) سهل!
فلسفة العمارة والملاحظات
نظرًا لأننا أردنا أن تمتد هذه البيانات إلى قواعد بيانات متعددة ، لم نتمكن من استخدام صلة ومفاتيح خارجية وفهارس فقط لجمع كل البيانات ، على الرغم من إمكانية استخدامها في الاستعلامات الفرعية التي لا تغطي قاعدة البيانات.
نحن بحاجة أيضًا إلى الحفاظ على موازنة التحميل على البيانات. قررنا أن نقل البيانات ، عنصرًا تلو الآخر ، سيجعل النظام معقدًا بلا داع ويسبب العديد من الأخطاء. إذا كنا بحاجة إلى نقل البيانات ، فمن الأفضل نقل العقدة الافتراضية بالكامل إلى عقدة فعلية أخرى.
من أجل التنفيذ السريع للتداول ، نحتاج إلى حل أبسط وأكثر ملاءمة وعقد مستقرة للغاية في نظامنا الأساسي للبيانات الموزعة.
كان لا بد من نسخ جميع البيانات إلى آلة الرقيق لإنشاء نسخة احتياطية ، مع توافر وإلقاء عالية إلى S3 ل MapReduce. نتفاعل مع سيد فقط على الإنتاج. على الإنتاج ، لن ترغب في الكتابة أو القراءة في الرقيق. تأخر الرقيق ، ويسبب خللًا غريبًا. إذا تم التقسيم ، فلا جدوى من التفاعل مع العبد في الإنتاج.
أخيرًا ، نحتاج إلى طريقة جيدة لإنشاء معرفات فريدة عالمية (UUIDs) لجميع كائناتنا.
كيف فعلنا التقسيم
ما كنا بصدد خلقه ، يجب أن نفي بالمتطلبات ، ونعمل بشكل مستقر ، بشكل عام ، ونكون قابليين للتطبيق ويمكن صيانتهما. لهذا السبب اخترنا
تقنية MySQL الناضجة بالفعل كتكنولوجيا أساسية. إننا نتوخى الحذر عمداً من التقنيات الجديدة للتحجيم التلقائي MongoDB و Cassandra و Membase ، لأنها كانت بعيدة كل البعد عن النضج (وفي حالتنا كسرت بطرق رائعة!).
بالإضافة إلى ذلك: ما زلت أوصي الشركات الناشئة لتجنب أشياء غريبة جديدة - فقط حاول استخدام MySQL. ثق بي. يمكنني إثبات ذلك بالندبات.
MySQL - التكنولوجيا أثبتت ثباتها وبساطتها - إنها تعمل. لا نستخدمها فحسب ، بل إنها تحظى بشعبية في الشركات الأخرى ذات المقاييس الأكثر إثارة للإعجاب. يلبي MySQL حاجتنا إلى تبسيط استعلامات البيانات ، واختيار نطاقات بيانات محددة ومعاملات على مستوى الصف. في الواقع ، توجد في ترسانته فرص أكثر بكثير ، لكننا جميعًا لا نحتاج إليها. لكن MySQL هو حل "محاصر" ، لذلك كان لا بد من تبادل البيانات. هنا هو الحل لدينا:
بدأنا مع ثمانية خوادم EC2 ، مثيل واحد من MySQL على كل:
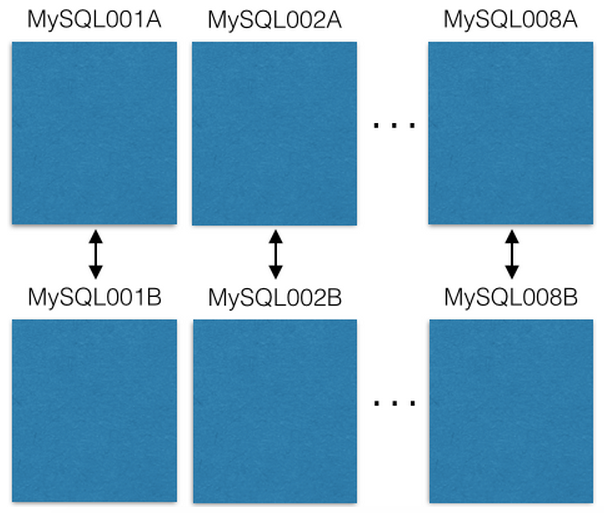
يتم نسخ كل خادم رئيسي لنظام MySQL إلى مضيف النسخ الاحتياطي في حالة حدوث عطل أساسي. خوادم الإنتاج الخاصة بنا للقراءة فقط أو الكتابة لإتقان. أنصحك أن تفعل كذلك. هذا يبسط إلى حد كبير ويتجنب الأخطاء مع تأخير النسخ المتماثل.
لكل كيان MySQL العديد من قواعد البيانات:

لاحظ أنه يتم تسمية كل قاعدة بيانات بشكل فريد: db00000 ، db00001 إلى dbNNNNN. كل قاعدة بيانات هي جزء من بياناتنا. لقد اتخذنا قرارًا معماريًا ، وعلى أساسه يقع جزء فقط من البيانات في القشرة ، ولا يتجاوز هذا القشرة أبدًا. ومع ذلك ، يمكنك الحصول على سعة أكبر من خلال نقل القطع إلى أجهزة أخرى (سنتحدث عن ذلك لاحقًا).
نحن نعمل مع جدول التكوين الذي يشير إلى الأجهزة التي لديها شظايا:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”}, {“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”}, ... {“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
يتغير هذا التكوين فقط عندما نحتاج إلى نقل القطع أو استبدال المضيف. إذا مات
master ، فيمكننا استخدام
slave الحالي ، ومن ثم التقاط واحد جديد. يوجد التهيئة في
ZooKeeper ، وعند تحديثها ، يتم إرسالها إلى الخدمات التي تخدم MySQL shard.
يحتوي كل قشرة على نفس مجموعة الجداول:
pins boards و
users_has_pins و
users_likes_pins و
pin_liked_by_user ، إلخ. سأتحدث عن هذا بعد قليل.
كيف نوزع بيانات هذه القطع؟
نقوم بإنشاء معرف 64 بت الذي يحتوي على معرّف الشدة ونوع البيانات الموجودة فيه والمكان الذي توجد فيه هذه البيانات في الجدول (المعرف المحلي). يتكون معرّف الحدث من 16 بت ، ومعرف النوع هو 10 بت ، والمعرف المحلي هو 36 بت. سوف يلاحظ علماء الرياضيات المتقدمون أن هناك 62 بت فقط. لقد علمتني تجربتي السابقة كمطور للمترجم ولوحة الدارات أن وحدات النسخ الاحتياطي تستحق ثقلها بالذهب. لذلك ، لدينا اثنين من هذه البتات (لتعيين الصفر).
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
لنأخذ هذا الرقم:
https://www.pinterest.com/pin/241294492511762325/ ، دعنا نحلل معرفه 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
وبالتالي ، فإن الكائن الدبوس يعيش في 3429 قشرة. نوعه هو "1" (أي ، "Pin") ، وهو على الخط 7075733 في الجدول pin. على سبيل المثال ، دعنا نتخيل أن هذه القشرة موجودة في MySQL012A. يمكننا الحصول عليه على النحو التالي:
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
هناك نوعان من البيانات: الكائنات والتعيينات. تحتوي الكائنات على أجزاء ، مثل بيانات الدبوس.
جداول الكائنات
تحتوي جداول الكائنات مثل Pins والمستخدمين واللوحات والتعليقات على معرّف (معرّف محلي ، مع مفتاح أساسي متزايد تلقائيًا) ونقطة تحتوي على JSON مع جميع بيانات الكائن.
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
على سبيل المثال ، تبدو الكائنات الدبوسية كما يلي:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
لإنشاء دبوس جديد ، نجمع كل البيانات وننشئ نقطة JSON. بعد ذلك ، نختار معرّف shard (نفضل اختيار معرّف shard نفسه مثل اللوحة التي وضعت عليه ، لكن هذا ليس ضروريًا). بالنسبة لنوع الدبوس 1. نتصل بقاعدة البيانات هذه وأدخل JSON في جدول الدبوس. سوف الخلية إرجاع معرف محلي زيادة تلقائيا. الآن لدينا مجموعة أحرف ونوع ومعرف محلي جديد ، حتى نتمكن من تجميع معرف 64 بت كامل!
لتحرير الدبوس ، نقرأ ونعدل JSON باستخدام
معاملة MySQL :
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [Modify the json blob] > UPDATE db03429.pins SET blob='<modified blob>' WHERE local_id=7075733 > COMMIT
لإزالة دبوس ، يمكنك حذف صفها في الخلية. ومع ذلك ، من الأفضل إضافة الحقل
"النشط" في JSON وتعيينه على
"false" ، وكذلك تصفية النتائج على جانب العميل.
الجداول رسم الخرائط
يربط جدول التعيين كائنًا بأخرى ، على سبيل المثال لوحة بها مسامير. يحتوي جدول MySQL للتعيينات على ثلاثة أعمدة: 64 بت للمعرف "من" ، 64 بت للمعرف "حيث" ومعرف التسلسل. في هذا الثلاثي (من أين وأين ، تسلسل) هناك مفاتيح الفهرس ، وهم على شظية المعرف "من".
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
تعد جداول التعيين أحادية الاتجاه ، على سبيل المثال ، مثل الجدول
board_has_pins . إذا كنت بحاجة إلى الاتجاه المعاكس ، فستحتاج إلى جدول
pin_owned_by_board منفصل. يحدد معرف التسلسل التسلسل (لا يمكن مقارنة معرفاتنا بين القطع ، لأن المعرفات المحلية الجديدة مختلفة). عادةً ما نقوم بإدخال دبابيس جديدة على لوحة جديدة بمعرف تسلسل مساوٍ للوقت في يونكس (طابع يونيكس الزمني). يمكن أن يكون أي رقم في التسلسل ، ولكن وقت يونكس هو وسيلة جيدة لتخزين المواد الجديدة بشكل متتابع ، لأن هذا المؤشر يزداد رتابة. يمكنك إلقاء نظرة على البيانات في جدول التعيين:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
يمنحك هذا أكثر من 50 pin_id ، والتي يمكنك استخدامها للبحث عن كائنات pin.
ما فعلناه للتو هو صلة طبقة التطبيق (board_id -> pin_id -> كائنات pin). أحد الخصائص المدهشة للاتصالات على مستوى التطبيق هو أنه يمكنك تخزين الصورة بشكل منفصل عن الكائن. نقوم بتخزين pin_id في ذاكرة التخزين المؤقت للكائن pin في كتلة memcache ، ومع ذلك فإننا نحفظ board_id في pin_id في نظام redis. يسمح لنا هذا باختيار التقنية المناسبة التي تناسب الكائن المخزن مؤقتًا بشكل أفضل.
زيادة القدرات
هناك ثلاث طرق رئيسية لزيادة السعة في نظامنا. أسهل طريقة لتحديث الجهاز (لزيادة المساحة ووضع محركات أقراص ثابتة بشكل أسرع ومزيد من ذاكرة الوصول العشوائي).
الطريقة التالية لزيادة السعة هي فتح نطاقات جديدة. في البداية ، أنشأنا ما مجموعه 4096 رأسًا ، على الرغم من حقيقة أن معرّف الحدث يتكون من 16 بت (أي ما مجموعه 64 ألف سهم). لا يمكن إنشاء كائنات جديدة في هذه القطع الأولى 4k. في مرحلة ما ، قررنا إنشاء خوادم MySQL جديدة مع قطع من 4096 إلى 8191 وبدأنا في تعبئتها.
الطريقة الأخيرة لزيادة السعة هي نقل بعض القطع إلى آلات جديدة. إذا كنا نريد زيادة سعة MySQL001A (مع القطع من 0 إلى 511) ، فإننا ننشئ زوجًا رئيسيًا جديدًا باستخدام الأسماء المحتملة التالية (قل MySQL009A و B) وبدء النسخ المتماثل من MySQL001A.
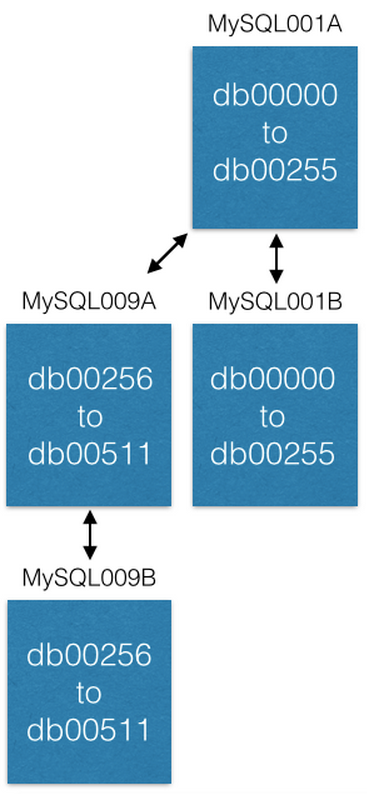
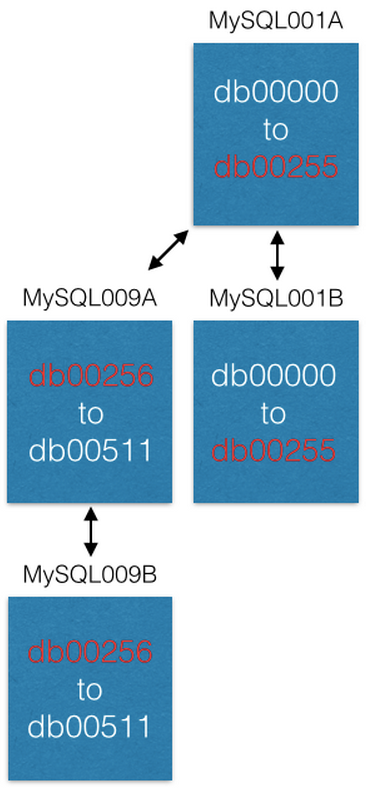
بمجرد اكتمال النسخ المتماثل ، نقوم بتغيير التكوين الخاص بنا بحيث لا يوجد في MySQL001A سوى القطع من 0 إلى 255 ، وفي MySQL009A من 256 إلى 511. الآن يجب على كل خادم معالجة نصف القطع التي تمت معالجتها من قبل.
بعض الميزات الرائعة
أولئك الذين لديهم بالفعل أنظمة لإنشاء
UUID جديدة سوف يفهمون أننا في هذا النظام نحصل عليها بدون تكلفة! عندما تقوم بإنشاء كائن جديد وإدراجه في جدول الكائنات ، فإنها تُرجع معرفًا محليًا جديدًا. يمنحك هذا المعرّف المحلي ، بالإضافة إلى معرّف shard ومعرف النوع ، UUID.
أولئك الذين قاموا بأداء ALTERs لإضافة المزيد من الأعمدة إلى جداول MySQL يعرفون أن بإمكانهم العمل ببطء شديد ويصبحون مشكلة كبيرة. لا يتطلب منهجنا أي تغييرات على مستوى MySQL. في Pinterest ، ربما قمنا بإنشاء ALTER واحد فقط في السنوات الثلاث الأخيرة. لإضافة حقول جديدة إلى الكائنات ، أخبر خدماتك أن هناك العديد من الحقول الجديدة في مخطط JSON. يمكنك تغيير القيمة الافتراضية بحيث تحصل على القيمة الافتراضية عند إلغاء تسلسل JSON من كائن بدون حقل جديد. إذا كنت بحاجة إلى جدول تعيين ، فقم بإنشاء جدول تعيين جديد وابدأ نشره وقتما تشاء. وعند الانتهاء ، يمكنك إرسال!
وزارة الدفاع شارد
انها تقريبا مثل
فرقة وزارة الدفاع ، فقط مختلفة تماما.
بعض الأشياء تحتاج إلى العثور عليها بدون معرف. على سبيل المثال ، إذا قام المستخدم بتسجيل الدخول باستخدام حساب Facebook ، فسنحتاج إلى تعيين من معرف Facebook إلى Pinterest ID. بالنسبة لنا ، فإن معرفات Facebook هي مجرد وحدات بت ، لذلك نقوم بتخزينها في نظام منفصل من قشرة يسمى mod shard.
وتشمل الأمثلة الأخرى عناوين IP واسم المستخدم وعنوان البريد الإلكتروني.
يعد Mod Shard مشابهًا جدًا لنظام المشاركة الموضح في القسم السابق ، مع وجود الفرق الوحيد في أنه يمكنك البحث عن البيانات باستخدام بيانات الإدخال التعسفي. يتم تجزئة هذا الإدخال وتعديله وفقًا لإجمالي عدد القطع الموجودة في النظام. نتيجة لذلك ، سيتم الحصول على قشرة تكون البيانات موجودة أو موجودة بالفعل. على سبيل المثال:
shard = md5(“1.2.3.4") % 4096
في هذه الحالة ، ستكون الحصة مساوية لـ 1524. نقوم بمعالجة ملف التكوين المطابق لمعرف القطع:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”}, {“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”}, {“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”}, …]
وبالتالي ، من أجل العثور على بيانات حول عنوان IP 1.2.3.4 ، سنحتاج إلى القيام بما يلي:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
أنت تفقد بعض الخصائص الجيدة لمعرف القشرة ، مثل المكان المكاني. يجب أن تبدأ بكل القطع التي تم إنشاؤها في البداية وإنشاء المفتاح بنفسك (لن يتم إنشاؤه تلقائيًا). من الأفضل دائمًا تمثيل الكائنات على نظامك بمعرفات غير قابلة للتغيير. وبالتالي ، لن تحتاج إلى تحديث العديد من الروابط عندما يقوم المستخدم ، على سبيل المثال ، بتغيير "اسم المستخدم" الخاص به.
الأفكار الأخيرة
يعمل هذا النظام على إنتاج Pinterest منذ 3.5 عام ، ومن المرجح أن يبقى هناك إلى الأبد. كان تطبيقه بسيطًا نسبيًا ، ولكن تشغيله ونقل جميع البيانات من الأجهزة القديمة كان أمرًا صعبًا. إذا واجهت مشكلة عندما قمت للتو بإنشاء شريحة جديدة ، ففكر في إنشاء مجموعة من آلات معالجة البيانات في الخلفية (تلميح: استخدام
pyres ) لنقل البيانات الخاصة بك مع البرامج النصية من قواعد البيانات القديمة إلى قشرة جديدة. أنا أضمن أن يتم فقد جزء من البيانات ، بصرف النظر عن مدى صعوبة المحاولة (كل هذه الأحجار الكريمة ، أقسم) ، لذا كرر نقل البيانات مرارًا وتكرارًا حتى تصبح كمية المعلومات الجديدة في الحشرة صغيرة جدًا أو لا تندرج مطلقًا.
لقد تم بذل كل جهد ممكن لهذا النظام. لكنه لا يوفر الذرية أو العزلة أو التماسك بأي شكل من الأشكال. قف! هذا يبدو سيئا! لكن لا تقلق. بالتأكيد ، سوف تشعر أنك ممتازة بدونها. يمكنك دائمًا بناء هذه الطبقات باستخدام عمليات / أنظمة أخرى ، إذا لزم الأمر ، ولكن بشكل افتراضي وبدون أي تكلفة تحصل بالفعل على الكثير: القدرة على العمل. الموثوقية التي تحققت من خلال البساطة ، وحتى يعمل بسرعة!
ولكن ماذا عن التسامح مع الخطأ؟ أنشأنا خدمة لصيانة MySQL shards ، وحفظ جدول تكوين shard في ZooKeeper. عندما يتعطل الخادم الرئيسي ، نرفع آلة الرقيق ثم نرفع الجهاز الذي سيحل محله (دائمًا ما يكون محدثًا). نحن لا نستخدم معالجة الفشل التلقائي حتى يومنا هذا.