CQM هو نظرة مختلفة في التعلم العميق لتحسين عمليات البحث في اللغة الطبيعية
وصف قصير: شبكة الكم المُعايرة (CQM) هي الخطوة التالية من RNN / LSTM (الشبكات العصبية المتكررة) / الذاكرة الطويلة المدى (LSTM). هناك خوارزمية جديدة تسمى شبكة الكم المعيارية (CQM) ، والتي تعد بزيادة دقة عمليات البحث عن اللغة الطبيعية دون استخدام بيانات التدريب المصنفة.
تم إنشاء بحث جديد تمامًا عن اللغة الطبيعية (NLS) وخوارزمية فهم اللغة الطبيعية (NLU) ، والتي لا تتجاوز فقط خوارزميات RNN / LSTM التقليدية أو حتى CNN ، ولكنها أيضًا عبارة عن التعلم الذاتي ولا تتطلب بيانات محددة للتدريب.
هذا يبدو جيدًا جدًا بحيث لا يكون صحيحًا ، ولكن النتائج الأولية مثيرة للإعجاب. CQM - تم تطويره بواسطة Praful Krishna وفريقه في Coseer (سان فرانسيسكو).
على الرغم من أن الشركة لا تزال صغيرة ، إلا أنها تعمل مع العديد من شركات Fortune 500 وبدأت في عقد مؤتمرات فنية.
هذا هو المكان الذي يأملون في إثبات أنفسهم فيه:
الدقة: وفقا لكريشنا ، فإن متوسط NLS يعمل في chatbot أقل خطورة ، وكقاعدة عامة ، لديه دقة حوالي 70 ٪ فقط.
حققت تطبيقات Coseer الأولية دقة أكثر من 95 ٪ في إرجاع المعلومات الصحيحة ذات الصلة. الكلمات الأساسية غير مطلوبة.
بيانات التدريب المصنفة غير مطلوبة: نعلم جميعًا أن بيانات التدريب المصنفة هي نفقات مالية ووقتية تحد من دقة روبوتات الدردشة.
منذ بضع سنوات تخلى أندرسون عن تجربته الباهظة وطويلة أعوام مع IBM Watson بسبب الأورام بسبب الدقة.
ما كان يعوق دقة هو الحاجة إلى الباحثين السرطان من ذوي الخبرة للغاية لتعليق الوثائق في العلبة. كان ينبغي عليهم القيام بذلك بدلاً من إجراء أبحاثهم.
سرعة التنفيذ: يقول Coseer إنه بدون بيانات التدريب ، يمكن إطلاق معظم عمليات النشر في غضون 4 إلى 12 أسبوعًا. هذا أقل بكثير من الوقت الذي يبدأ فيه المستخدم في استخدام نظام مُدرَّج مسبقًا ، يبدأ تشغيله بالتحميل الأولي للمستندات المحددة.
بالإضافة إلى ذلك ، بخلاف البائعين الكبار الحاليين الذين يستخدمون خوارزميات التعليم العميق التقليدية ، يفضل Coseer نشرها في كل من السحابة الآمنة والخاصة لضمان أمان البيانات.
يتم تخزين كل "الأدلة" المستخدمة للوصول إلى أي استنتاج في مجلة يمكن استخدامها لإظهار الشفافية والامتثال لقواعد أمان البيانات مثل الناتج المحلي الإجمالي.
كيف يعمل؟
يتحدث Coseer عن المبادئ الثلاثة التي تحدد CQM:
1. الكلمات (المتغيرات) لها معان مختلفة.
النظر في كلمة "الفرن" ، والتي قد تكون اسما أو فعل. على سبيل المثال ، "الآية" ، والتي قد تعني "قصيدة" أو الفعل "آية الرياح" - هذه هي الكلمات المترادفة.
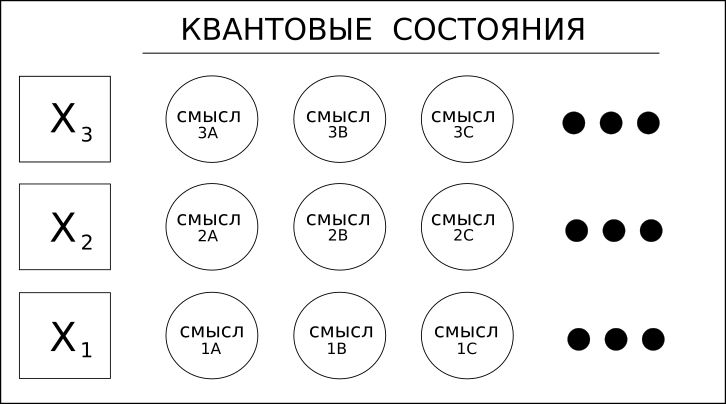
لا يمكن أن تتطلع حلول التعلم العميق ، بما في ذلك RNN / LSTM أو حتى CNN للنص ، إلا إلى الأمام أو الخلف لتحديد "سياق" الكلمة وبالتالي تحديد معناها.
يأخذ Coseer في الاعتبار جميع المعاني الممكنة للكلمة ويطبق الاحتمال الإحصائي على كل منها على أساس المستند أو المجموعة بأكملها.
يشير استخدام مصطلح "الكم" في هذه الحالة فقط إلى إمكانية وجود قيم متعددة ، وليس إلى تراكب أكثر غرابة للحوسبة الكمومية.
2. كل شيء مترابط في شبكة من القيم:
والمبدأ الثاني هو استخراج كل الكلمات (المتغيرات) المتاحة من جميع علاقاتها الممكنة.
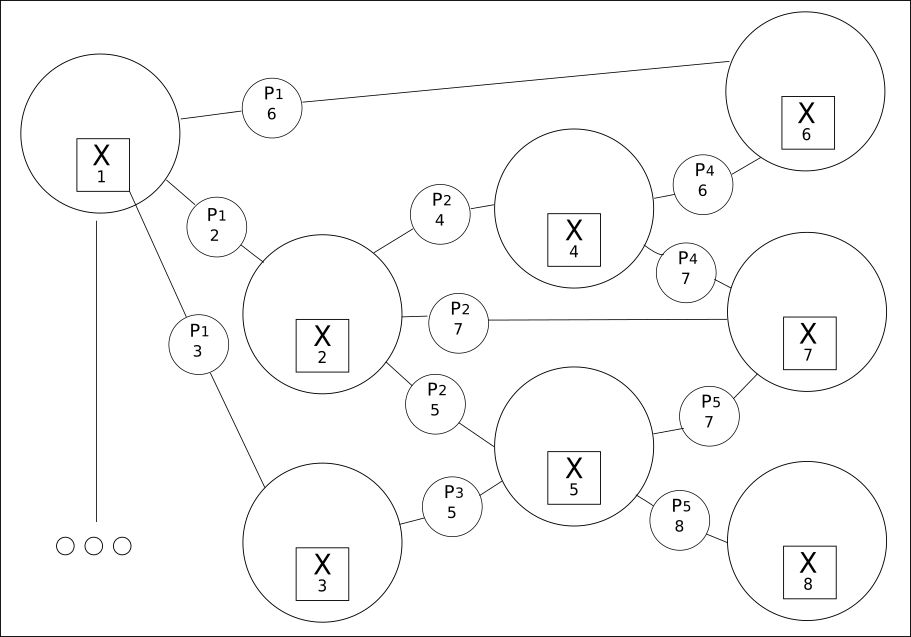
ينشئ CQM شبكة من القيم الممكنة ، من بينها قيمة حقيقية. باستخدام هذا النهج يكشف عن وجود علاقة أوسع بكثير بين العبارات السابقة أو اللاحقة مما يمكن أن يوفره التعلم العميق التقليدي.
على الرغم من أن عدد الكلمات يمكن أن يكون محدودا ، إلا أن علاقاتهم يمكن أن تكون بمئات الآلاف.
3. يتم استخدام جميع المعلومات المتاحة بالتتابع لدمج الشبكة في قيمة واحدة. تحدد عملية المعايرة هذه الكلمات أو المفاهيم المفقودة بسرعة وتوفر تدريبًا سريعًا ودقيقًا للغاية.
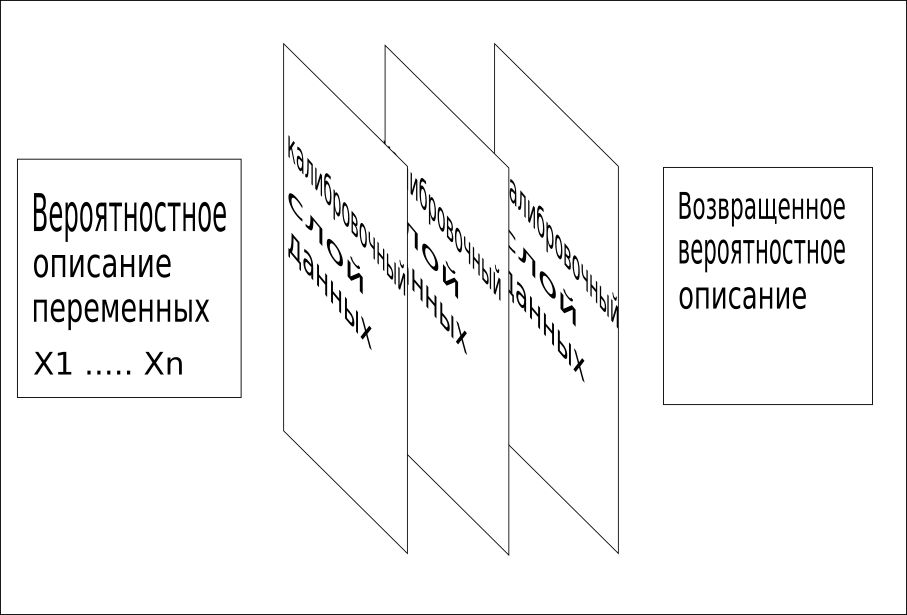
تستخدم نماذج CQM بيانات التدريب والبيانات السياقية والبيانات المرجعية وغيرها من الحقائق المعروفة حول المشكلة لتحديد طبقات بيانات المعايرة هذه.
لسوء الحظ ، لم ينشر Coseer سوى القليل جدًا في المجال العام لشرح الجوانب التقنية للخوارزمية.
يجب الترحيب بأي طفرة في إزالة البيانات المحددة أثناء التدريب ، وبطبيعة الحال ، سيؤدي تحسين الدقة إلى حقيقة أن العملاء الأكثر رضاء سيستخدمون برنامج الدردشة الخاص بك.