مقدمة
قبل بضع سنوات ، قررنا أن الوقت قد حان لدعم رمز SIMD في .NET . قدمنا مساحة الاسم System.Numerics بأنواع Vector2 و Vector3 و Vector4 و Vector<T> . تمثل هذه الأنواع واجهة برمجة تطبيقات للأغراض العامة لإنشاء تعليمات المتجهات والوصول إليها ومعالجتها كلما أمكن ذلك. كما أنها توفر توافق البرامج لتلك الحالات التي لا يدعم الجهاز فيها الإرشادات المناسبة. سمح هذا ، مع الحد الأدنى من إعادة البناء ، بتوجيه عدد من الخوارزميات. بصرف النظر عن ذلك ، فإن عمومية هذا النهج تجعل من الصعب تطبيقه من أجل الاستفادة الكاملة من كل ما هو متاح ، على الأجهزة الحديثة ، تعليمات المتجهات. بالإضافة إلى ذلك ، توفر الأجهزة الحديثة عددًا من الإرشادات المتخصصة غير الموجهة التي يمكنها تحسين الأداء بشكل كبير. في هذه المقالة ، سأتحدث عن كيفية التحايل على هذه القيود في .NET Core 3.0.

ملاحظة: لا يوجد مصطلح محدد لترجمة Intrisics حتى الآن . في نهاية المقال ، هناك تصويت لخيار الترجمة. إذا اخترنا خيارًا جيدًا ، فسنغير المقالة
ما هي وظائف المدمج في
في .NET Core 3.0 ، أضفنا وظائف جديدة تسمى وظائف مضمّنة خاصة بالأجهزة (أقصى WF). توفر هذه الوظيفة الوصول إلى العديد من إرشادات الأجهزة المحددة التي لا يمكن تمثيلها ببساطة عن طريق آليات متعددة الأغراض العامة. وهي تختلف عن إرشادات SIMD الحالية من حيث أنها لا تملك غرضًا عامًا ( WFs الجديدة ليست مشتركة بين الأنظمة الأساسية وهندستها المعمارية لا توفر توافق البرامج). بدلاً من ذلك ، فإنها توفر مباشرة وظائف النظام الأساسي والأجهزة الخاصة لمطوري .NET. توفر وظائف SIMD الحالية ، على سبيل المثال ، عبر النظام الأساسي ، توافق البرامج ، وهي مستخرجة قليلاً من الأجهزة الأساسية. قد يكون هذا التجريد باهظًا ، بالإضافة إلى أنه يمكن أن يمنع الكشف عن بعض الوظائف (على سبيل المثال ، في حالة عدم وجود وظيفة أو يصعب محاكاتها على جميع الأنظمة الأساسية المستهدفة).
توجد وظائف مدمجة جديدة وأنواع مدعومة ضمن System.Runtime.Intrinsics . بالنسبة إلى .NET Core 3.0 ، يوجد حاليًا System.Runtime.Intrinsics.X86 . نحن نعمل على دعم الوظائف المدمجة System.Runtime.Intrinsics.Arm الأساسية الأخرى مثل System.Runtime.Intrinsics.Arm .
تحت مساحات الأسماء الخاصة بالنظام الأساسي ، يتم تجميع WFs في فئات تمثل مجموعات من إرشادات الأجهزة المتكاملة منطقياً (تُسمى غالبًا هندسة مجموعة التعليمات (ISA)). يوفر كل فئة خاصية IsSupported تشير إلى ما إذا كانت الأجهزة التي يعمل عليها الرمز تدعم مجموعة التعليمات هذه. علاوة على ذلك ، يحتوي كل فئة من هذه الفئات على مجموعة من الطرق المعينة لمجموعة من التعليمات المقابلة. في بعض الأحيان ، توجد فئة فرعية إضافية تتوافق مع جزء من مجموعة التعليمات نفسها ، والتي قد تكون محدودة (مدعومة) بواسطة أجهزة معينة. على سبيل المثال ، توفر فئة Lzcnt الوصول إلى تعليمات لحساب الأصفار البادئة . لديه فئة فرعية تسمى X64 ، والتي تحتوي على شكل هذه التعليمات المستخدمة فقط على الأجهزة ذات العمارة 64 بت.
بعض هذه الفئات ذات طبيعة هرمية بشكل طبيعي. على سبيل المثال ، إذا كانت Lzcnt.X64.IsSupported ترجع إلى true ، فعندئذٍ يجب أن ترجع Lzcnt.IsSupported true ، لأن هذه فئة فرعية صريحة. أو ، على سبيل المثال ، إذا كانت Sse2.IsSupported تُرجع إلى true ، فعندئذ يجب أن ترجع Sse.IsSupported true ، لأن Sse2 يرث بشكل صريح من Sse . ومع ذلك ، تجدر الإشارة إلى أن تشابه أسماء الفئات ليس مؤشراً على انتمائهم إلى نفس التسلسل الهرمي للميراث. على سبيل المثال ، لا Bmi2 توريث Bmi2 ، لذلك ستكون القيم التي يتم إرجاعها بواسطة IsSupported لهاتين المجموعتين من التعليمات مختلفة. كان المبدأ الأساسي في تطوير هذه الفئات هو العرض الواضح لمواصفات ISA. يتطلب SSE2 دعم SSE1 ، لذلك ترتبط الفئات التي تمثلها بالميراث. في الوقت نفسه ، لا يحتاج BMI2 إلى دعم BMI1 ، لذلك لم نستخدم الوراثة. فيما يلي مثال لواجهة برمجة التطبيقات أعلاه.
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
يمكنك رؤية المزيد في الكود المصدري على الروابط التالية source.dot.net أو dotnet / coreclr على جيثب
IsSupported معالجة الشيكات IsSupported بواسطة برنامج التحويل البرمجي JIT على أنها ثوابت وقت التشغيل (عند تمكين التحسين) ، لذلك لا تحتاج إلى ترجمة مشتركة لدعم عدة ISA ، أو أنظمة أساسية ، أو بنى. بدلاً من ذلك ، تحتاج فقط إلى كتابة الكود باستخدام تعبيرات if ، نتيجة لذلك سيتم تجاهل فروع الشفرة غير المستخدمة (أي تلك الفروع التي لا يمكن الوصول إليها بسبب قيمة المتغير في العبارة الشرطية) عند إنشاء الكود الأصلي.
من المهم أن يسبق التحقق من IsSupported المطابق استخدام أوامر الأجهزة المدمجة. إذا لم يكن هناك تحقق من هذا القبيل ، فإن الكود الذي يستخدم الأوامر الخاصة بالنظام الأساسي والتي تعمل على الأنظمة الأساسية / البنى حيث لا تكون هذه الأوامر مدعومة سيؤدي إلى استثناء وقت تشغيل PlatformNotSupportedException .
ما هي الفوائد التي يقدمونها؟
بطبيعة الحال ، فإن الوظائف المدمجة الخاصة بالأجهزة ليست مخصصة للجميع ، ولكن يمكن استخدامها لتحسين الأداء في العمليات المحملة بالحسابات. تستخدم ML.NET CoreFX و ML.NET هذه الطرق لتسريع العمليات مثل النسخ في الذاكرة ، أو البحث عن فهرس عنصر في صفيف أو سلسلة ، أو تغيير حجم صورة ، أو العمل مع المتجهات / المصفوفات / التنسورات. يمكن أن يكون الاتجاه اليدوي لبعض الأكواد التي تحولت إلى عنق الزجاجة أبسط مما يبدو. في الواقع ، فإن تحويل الشفرة هو تنفيذ العديد من العمليات في وقت واحد ، بشكل عام ، باستخدام تعليمات SIMD (دفق تعليمي واحد ، دفق بيانات متعددة).
قبل أن تقرر توجيه بعض التعليمات البرمجية ، تحتاج إلى تنفيذ تشكيل جانبي للتأكد من أن هذا الرمز جزء من "النقطة الفعالة" (وبالتالي ، فإن التحسين الخاص بك سيعطي دفعة قوية للأداء). من المهم أيضًا إجراء التوصيف في كل مرحلة من مراحل التوازي ، حيث أن تغيّر الكود ليس كله يؤدي إلى زيادة الإنتاجية.
تحويل خوارزمية بسيطة
لتوضيح استخدام الدوال المضمّنة ، نأخذ الخوارزمية لتجميع جميع عناصر الصفيف أو النطاق. هذا النوع من الكود هو المرشح المثالي للتوجه ، لأن في كل تكرار ، يتم تنفيذ نفس العملية التافهة.
مثال تنفيذ مثل هذه الخوارزمية قد تبدو كما يلي:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
هذا الكود بسيط للغاية ومباشر ، ولكنه بطيء في الوقت نفسه بدرجة كافية للحصول على بيانات الإدخال الكبيرة ، مثل يقوم بعملية تافهة واحدة فقط لكل تكرار.
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
زيادة الإنتاجية من خلال دورات النشر
المعالجات الحديثة لديها خيارات مختلفة لتحسين أداء التعليمات البرمجية. بالنسبة للتطبيقات ذات الخيوط المفردة ، يتمثل أحد هذه الخيارات في تنفيذ العديد من العمليات البدائية في دورة معالج واحد.
يمكن لمعظم المعالجات الحديثة إجراء أربع عمليات إضافية في دورة واحدة على مدار الساعة (في ظل الظروف المثلى) ، ونتيجة لذلك ، مع "التصميم" الصحيح للكود ، يمكنك في بعض الأحيان تحسين الأداء ، حتى في التنفيذ المفرد.
على الرغم من أن JIT يمكنها تنفيذ حلقة إلغاء التمرير من تلقاء نفسها ، إلا أن JIT محافظة في اتخاذ هذا النوع من القرارات ، بسبب حجم الشفرة التي تم إنشاؤها. لذلك ، قد يكون من المفيد نشر حلقة ، في التعليمات البرمجية ، يدويًا.
يمكنك توسيع الحلقة في الكود أعلاه كما يلي:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
هذا الرمز أكثر تعقيدًا بعض الشيء ، لكنه يستخدم ميزات الأجهزة بشكل أفضل.
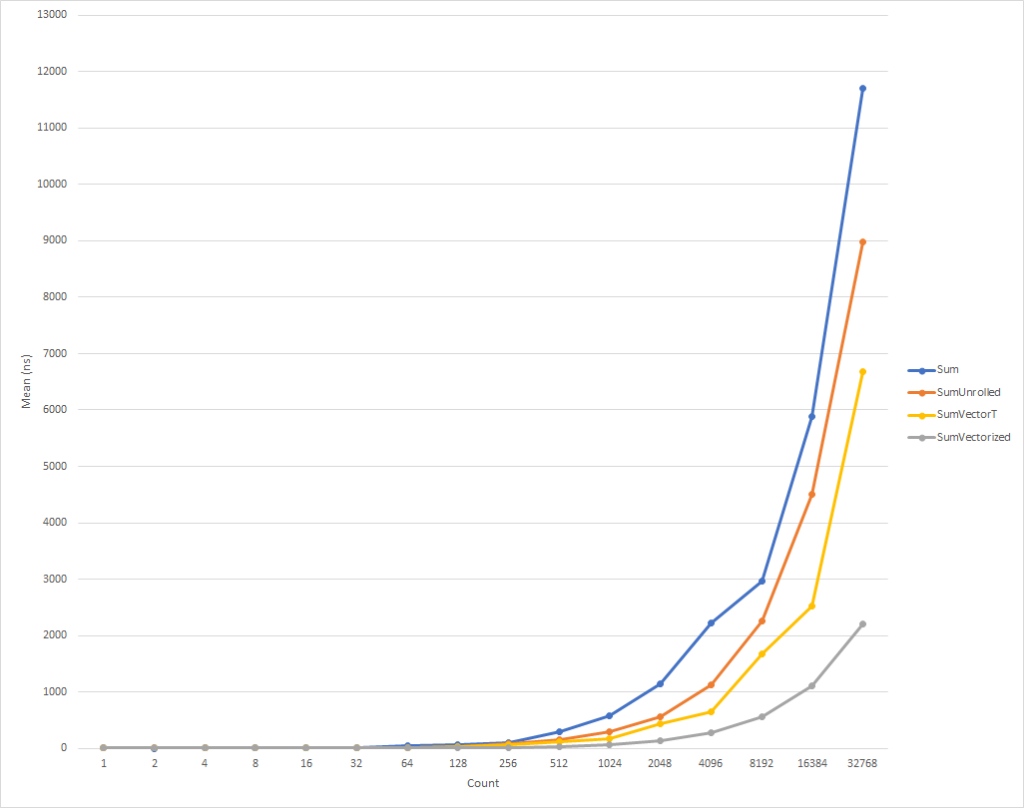
لحلقات صغيرة حقا ، وهذا الرمز يعمل أبطأ قليلا. لكن هذا الاتجاه يتغير بالفعل لبيانات الإدخال المكونة من ثمانية عناصر ، وبعدها تبدأ سرعة التنفيذ في الزيادة (وقت تنفيذ الكود المحسّن ، لـ 32 ألف عنصر ، أقل بنسبة 26٪ من وقت الإصدار الأصلي). تجدر الإشارة إلى أن هذا التحسين لا يؤدي دائمًا إلى زيادة الإنتاجية. على سبيل المثال ، عند العمل مع المجموعات التي تحتوي على عناصر من النوع float للإصدار "المنشور" من الخوارزمية نفس سرعة الإصدار الأصلي تقريبًا. لذلك ، من المهم للغاية تنفيذ التنميط.

زيادة الإنتاجية من خلال vectorization حلقة
هذا ما قد يكون ، ولكن لا يزال بإمكاننا تحسين هذا الرمز قليلاً. تعد إرشادات SIMD خيارًا آخر يوفره المعالجات الحديثة لتحسين الأداء. باستخدام تعليمة واحدة ، تسمح لك بإجراء عدة عمليات في دورة ساعة واحدة. قد يكون هذا أفضل من حلقة مباشرة تتكشف ، لأنه في الواقع ، يتم تنفيذ نفس الشيء ، ولكن مع كمية أقل من الشفرة التي تم إنشاؤها.
للتوضيح ، تأخذ كل عملية إضافة ، في دورة منشورة ، 4 بايت. وبالتالي ، نحن بحاجة إلى 16 بايت لأربع عمليات إضافة في النموذج الموسع. في الوقت نفسه ، يقوم تعليمة إضافة SIMD أيضًا بإجراء 4 عمليات إضافة ، ولكنها لا تستغرق سوى 4 بايت. هذا يعني أن لدينا تعليمات أقل لوحدة المعالجة المركزية. بالإضافة إلى ذلك ، في حالة وجود تعليمات SIMD ، يمكن لوحدة المعالجة المركزية افتراضات وتنفيذ عمليات تحسين ، ولكن هذا خارج عن نطاق هذه المقالة. والأفضل من ذلك هو أن المعالجات الحديثة يمكنها تنفيذ أكثر من تعليمة SIMD في وقت واحد ، على سبيل المثال ، في بعض الحالات ، يمكنك تطبيق إستراتيجية مختلطة ، وفي نفس الوقت تقوم بإجراء مسح جزئي للدورة وتوجيهها.
بشكل عام ، يجب أن تبدأ من خلال النظر في فئة Vector<T> للأغراض العامة لمهامك. سيقوم ، مثل WFs الجديد ، بتضمين تعليمات SIMD ، ولكن في نفس الوقت ، نظرًا لتعدد استخدامات هذه الفئة ، يمكنه تقليل عدد الترميز "اليدوي".
قد يبدو الرمز كما يلي:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
يعمل هذا الرمز بشكل أسرع ، لكننا مضطرون إلى الرجوع إلى كل عنصر على حدة عند حساب المبلغ النهائي. أيضًا ، لا يحتوي Vector<T> على حجم محدد بدقة ، وقد يختلف حسب الجهاز الذي يعمل عليه الرمز. توفر الوظائف المدمجة الخاصة بالأجهزة وظائف إضافية يمكنها تحسين هذا الرمز قليلاً وجعله أسرع قليلاً (على حساب متطلبات التعقيد والصيانة الإضافية للشفرة).

ملاحظة بالنسبة لهذه المقالة ، قمت بقوة COMPlus_SIMD16ByteOnly=1 حجم Vector<T> إلى 16 بايت باستخدام معلمة التكوين الداخلي ( COMPlus_SIMD16ByteOnly=1 ). SumVectorT هذا القرص النتائج عند مقارنة SumVectorT مع SumVectorizedSse ، وسمح لنا بالحفاظ على الكود البسيط. على وجه الخصوص ، تجنب كتابة قفزة مشروطة if (Avx2.IsSupported) { } . يشبه هذا الرمز تقريبًا رمز Sse2 ، لكنه يتعامل مع Vector256<T> (32 بايت) ويعالج عناصر أكثر في تكرار واحد للحلقة.
وبالتالي ، باستخدام الوظائف المدمجة الجديدة ، يمكن إعادة كتابة الكود على النحو التالي:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
هذا الرمز ، مرة أخرى ، أكثر تعقيدًا بعض الشيء ، لكنه أسرع بشكل كبير للجميع باستثناء أصغر مجموعات الإدخال. بالنسبة إلى 32 ألف عنصر ، يتم تنفيذ هذا الرمز بنسبة 75٪ أسرع من الدورة الموسعة ، و 81٪ أسرع من شفرة المصدر للمثال.
لاحظت أننا كتبنا بعض الشيكات IsSupported . أول واحد يتحقق ما إذا كان الجهاز الحالي يدعم مجموعة الوظائف المدمجة المطلوبة ، إن لم يكن ، ثم يتم تنفيذ التحسين من خلال مجموعة من الاجتياح و Vector<T> . سيتم تحديد الخيار الأخير للأنظمة الأساسية مثل ARM / ARM64 التي لا تدعم مجموعة التعليمات المطلوبة ، أو إذا تم تعطيل المجموعة للنظام الأساسي. يتم IsSupported اختبار IsSupported الثاني ، في طريقة SumVectorizedSse2 ، لتحسين إضافي إذا كان الجهاز يدعم Ssse3 تعليمات Ssse3 .
خلاف ذلك ، فإن معظم المنطق هو في الأساس نفسه بالنسبة للحلقة الموسعة. Vector128<T> هو نوع 128 بت يحتوي على Vector128<T>.Count . في هذه الحالة ، يمكن أن يحتوي uint ، الذي يبلغ 32 بت ، على 4 (128/32) ، هذه هي الطريقة التي أطلقنا بها الحلقة.
استنتاج
تمنحك الوظائف المدمجة الجديدة فرصة للاستفادة من وظائف الأجهزة الخاصة بالجهاز الذي تقوم بتشغيل الشفرة عليه. هناك ما يقرب من 1500 من واجهات برمجة التطبيقات لـ X86 و X64 موزعة على 15 مجموعة ، وهناك الكثير مما يجب وصفه في مقال واحد. من خلال وضع رمز للتوصيف لتحديد الاختناقات ، يمكنك تحديد جزء الكود الذي يستفيد من المتجهات ومراقبة أداء جيد جدًا. هناك العديد من السيناريوهات التي يمكن فيها تطبيق vectorization وحلقة تتكشف مجرد البداية.
يمكن لأي شخص يرغب في رؤية المزيد من الأمثلة البحث عن استخدام الوظائف المدمجة في الإطار (انظر dotnet و aspnet ) ، أو في مقالات المجتمع الأخرى. وعلى الرغم من أن WFs الحالية واسعة ، فلا يزال هناك الكثير من الوظائف التي يجب تقديمها. إذا كانت لديك الوظيفة التي تريد تقديمها ، فلا تتردد في تسجيل طلب API الخاص بك عبر dotnet / corefx على GitHub . يتم وصف عملية مراجعة واجهة برمجة التطبيقات (API) هنا وهناك مثال جيد على قالب طلب واجهة برمجة التطبيقات المحدد في الخطوة 1.
شكر خاص
أود أن أعرب عن امتناني الخاص لأعضاء مجتمعنا Fei Peng (fiigii) و Jacek Blaszczynski (@ 4creators) لمساعدتهم في تنفيذ WF ، وكذلك لجميع أعضاء المجتمع على تعليقاتهم القيمة فيما يتعلق بتطوير هذه الوظيفة وتنفيذها وسهولة استخدامها.
الكلمة الأخيرة للترجمة
أرغب في ملاحظة تطور نظام .NET ، وبشكل خاص لغة C #. كنت قادمًا من عالم C ++ ، ولدي خبرة قليلة في التطوير في Delphi و Java ، وكنت مرتاحًا جدًا لبدء برامج الكتابة في C #. في عام 2006 ، بدا لي أن لغة البرمجة هذه (وهي اللغة) أكثر إيجازًا وعمليًا من Java في عالم جمع القمامة المُدار ومنصة مشتركة. لذلك ، سقطت خياري على C # ، وأنا لست نادما على ذلك. المرحلة الأولى من تطور اللغة كانت ببساطة ظهورها. بحلول عام 2006 ، استوعبت C # أفضل ما كان في ذلك الوقت بأفضل اللغات والأنظمة الأساسية: C ++ / Java / Delphi. في عام 2010 ، أصبحت F # عامة. لقد كانت منصة تجريبية لدراسة النموذج الوظيفي بهدف إدخاله في عالم .NET. كانت نتيجة التجارب هي المرحلة التالية في تطور C # - توسيع قدراتها نحو FP ، من خلال إدخال وظائف مجهولة الهوية ، وتعبيرات lambda ، وفي نهاية المطاف ، LINQ. جعل امتداد اللغة هذا لغة C # الأكثر تقدمًا ، من وجهة نظري ، لغة الأغراض العامة. كانت الخطوة التطورية التالية مرتبطة بدعم التزامن والتزامن. المهمة / المهمة <T> ، مفهوم TPL بالكامل ، تطوير LINQ - PLINQ ، وأخيراً ، التزامن / الانتظار. , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .