نظرت
المقالة السابقة في بنية شبكة افتراضية ، طبقة أساس متراكبة ، مسار الحزمة بين VMs والمزيد.
كانت مستوحاة
رومان جورج من قبلها وقررت أن تكتب مشكلة مراجعة حول الافتراضية بشكل عام.
في هذه المقالة ، سنتناول (أو نحاول أن نتناول) الأسئلة: كيف تحدث ظاهرية وظائف الشبكة فعليًا ، وكيف يتم تطبيق الواجهة الخلفية للمنتجات الرئيسية لتشغيل وإدارة VMs ، وكيف يعمل التبديل الظاهري (OVS و Linux bridge).
موضوع المحاكاة الافتراضية واسع وعميق ، من المستحيل شرح جميع تفاصيل عمل برنامج Hypervisor (وليس ضروريًا). سنقتصر على الحد الأدنى من المعرفة اللازمة لفهم عمل أي حل افتراضي ، وليس بالضرورة Telco.

محتوى
- مقدمة وتاريخ موجز للمحاكاة الافتراضية
- أنواع الموارد الافتراضية - حساب ، تخزين ، شبكة
- التبديل الظاهري
- أدوات المحاكاة الافتراضية - libvirt ، virsh والمزيد
- استنتاج
مقدمة وتاريخ موجز للمحاكاة الافتراضية
يعود تاريخ تقنيات المحاكاة الافتراضية الحديثة إلى عام 1999 ، عندما أصدرت الشركة الناشئة VMware منتجًا يسمى VMware Workstation. كان هذا منتجًا افتراضيًا لتطبيقات سطح المكتب / العميل. جاءت المحاكاة الافتراضية من جانب الخادم في وقت لاحق قليلاً في شكل منتج ESX Server ، والذي تطور لاحقًا إلى ESXi (يعني متكاملة) - وهذا هو نفس المنتج المستخدم عالميًا في كل من IT و Telco كمشرف تطبيق خادم.
على الجانب المفتوح المصدر ، هناك مشروعان رئيسيان جلبا الافتراضية إلى Linux:
- KVM (Virtual Machine المستندة إلى Kernel) هي وحدة Linux kernel تتيح kernel العمل كمشرف (ينشئ البنية الأساسية اللازمة لبدء وإدارة VMs). تمت إضافته في kernel الإصدار 2.6.20 في 2007.
- QEMU (Quick Emulator) - يحاكي مباشرة الأجهزة لجهاز ظاهري (وحدة المعالجة المركزية ، القرص ، ذاكرة الوصول العشوائي ، أي شيء بما في ذلك منفذ USB) ويستخدم جنبا إلى جنب مع KVM لتحقيق أداء "أصلي" تقريبا.
في الواقع ، في الوقت الحالي ، تتوفر جميع وظائف KVM في QEMU ، لكن هذا ليس مهمًا ، لأن معظم مستخدمي Linux الظاهري لا يستخدمون KVM / QEMU مباشرةً ، لكنهم يقومون بالوصول إليهم من خلال مستوى واحد على الأقل من التجريد ، لكن المزيد عن ذلك لاحقًا.
اليوم ، يعد VMware ESXi و Linux QEMU / KVM هما المشرفين الرئيسيين اللذين يسيطران على السوق. هم أيضًا ممثلون لنوعين مختلفين من برامج Hypervisor:
- النوع 1 - يعمل برنامج hypervisor مباشرة على الأجهزة (المعدن العاري). هذا هو VMware ESXi و Linux KVM و Hyper-V
- النوع 2 - يتم تشغيل برنامج Hypervisor داخل نظام التشغيل Host (نظام التشغيل). هذا هو VMware Workstation أو Oracle VirtualBox.
مناقشة ما هو أفضل وما هو أسوأ هو خارج نطاق هذا المقال.

كان على منتجي الحديد أيضًا أداء دورهم لضمان الأداء المقبول.
ربما تكون Intel VT (تقنية المحاكاة الافتراضية) هي الأكثر أهمية والأكثر استخدامًا على نطاق واسع - وهي مجموعة من الملحقات التي طورتها Intel لمعالجات x86 الخاصة بها والتي يتم استخدامها للتشغيل الفعال لبرنامج hypervisor (وفي بعض الحالات تكون ضرورية ، على سبيل المثال ، لن تعمل KVM بدون تشغيل VT -x وبدونه ، يضطر برنامج Hypervisor إلى المشاركة في محاكاة البرامج المحضة ، دون تسريع الأجهزة).
من المعروف أن اثنين من هذه الامتدادات - VT-x و VT-d. الأول مهم لتحسين أداء وحدة المعالجة المركزية أثناء المحاكاة الافتراضية ، حيث أنه يوفر دعمًا للأجهزة لبعض وظائفه (مع تنفيذ VT-x 99.9٪ رمز OS Guest مباشرة على المعالج الفعلي ، مما يؤدي إلى إخراج المحاكاة فقط في معظم الحالات الضرورية) ، والثاني هو لتوصيل الأجهزة الفعلية مباشرة إلى جهاز ظاهري (للوظائف الظاهرية الأمامية (VF) SRIOV ، على سبيل المثال ،
يجب تمكين VT-d).
المفهوم المهم التالي هو الفرق بين المحاكاة الافتراضية الكاملة والمحاكاة الافتراضية.
المحاكاة الافتراضية الكاملة جيدة ، فهي تتيح لك تشغيل أي نظام تشغيل على أي معالج ، ومع ذلك ، فإنه غير فعال للغاية وغير ملائم على الإطلاق للأنظمة المحملة للغاية.
المحاكاة الافتراضية ، باختصار ، هي عندما يدرك Guest OS أنه يعمل في بيئة افتراضية ويتعاون مع برنامج Hypervisor لتحقيق كفاءة أكبر. وهذا هو ، تظهر واجهة الضيف المشرف.
توفر الغالبية العظمى من أنظمة التشغيل المستخدمة اليوم دعمًا للفضاء الظاهري - في نواة Linux ، ظهر هذا منذ إصدار kernel 2.6.20.
لكي يعمل الجهاز الظاهري ، ليست هناك حاجة فقط إلى معالج ظاهري (vCPU) وذاكرة افتراضية (RAM) ؛ كما يلزم محاكاة أجهزة PCI. وهذا ، في الواقع ، مطلوب مجموعة من برامج التشغيل لإدارة واجهات الشبكة الافتراضية ، والأقراص ، وما إلى ذلك.
في برنامج Linux KVM hypervisor ، تم حل هذه المهمة من خلال تنفيذ الأمر
الواقع ، وهو إطار لتطوير واستخدام أجهزة الإدخال / الإخراج الافتراضية.
Virtio هو مستوى إضافي من التجريد ، والذي يسمح لك بمحاكاة أجهزة الإدخال / الإخراج المختلفة في برنامج Hypervisor شبه الظاهري ، مما يوفر واجهة موحدة وموحدة إلى جانب الجهاز الظاهري. يتيح لك ذلك إعادة استخدام رمز برنامج التشغيل الفعلي لأجهزة مختلفة بطبيعتها. يتكون Virtio من:
- برنامج التشغيل الأمامي - ما هو في الجهاز الظاهري
- السائق الخلفي - ما هو في برنامج Hypervisor
- سائق النقل - ما يربط الخلفية والواجهة الأمامية
تسمح لك هذه الطريقة بتغيير التقنيات المستخدمة في برنامج Hypervisor دون التأثير على برامج التشغيل في الجهاز الظاهري (هذه النقطة مهمة جدًا لتقنيات تسريع الشبكة وحلول Cloud بشكل عام ، ولكن المزيد حول ذلك لاحقًا).
بمعنى ، هناك اتصال برنامج الضيف الفائق عندما يعلم نظام التشغيل Guest أنه يعمل في بيئة افتراضية.
إذا سبق لك أن كتبت سؤالًا في طلب تقديم العروض أو أجبت على سؤال في طلب تقديم العروض "هل هناك ميزة مدعومة في منتجك؟" كان الأمر يتعلق فقط بدعم برنامج التشغيل الأمامي.
أنواع الموارد الافتراضية - حساب ، تخزين ، شبكة
ماذا يتكون الجهاز الظاهري؟
هناك ثلاثة أنواع رئيسية من الموارد الافتراضية:
- حساب - المعالج وذاكرة الوصول العشوائي
- تخزين - قرص نظام الجهاز الظاهري وتخزين كتلة
- شبكة - بطاقات الشبكة وأجهزة الإدخال / الإخراج
حساب
وحدة المعالجة المركزية
نظريا ، QEMU قادرة على محاكاة أي نوع من المعالج والأعلام والوظائف المقابلة لها ؛ في الممارسة العملية ، يستخدمون إما نموذج المضيف وإيقاف تشغيل الأعلام بشكل عمودي قبل نقلهم إلى Guest OS ، أو أنهم يأخذون نموذجًا مسمىًا ويقومون بإيقاف / تشغيل الإشارات بالإشارة.
بشكل افتراضي ، ستقوم QEMU بمحاكاة المعالج الذي سيتعرف عليه Guest OS كوحدة المعالجة المركزية الافتراضية QEMU. ليس هذا هو أفضل نوع من المعالجات ، خاصةً إذا كان التطبيق الذي يتم تشغيله في جهاز ظاهري يستخدم إشارات وحدة المعالجة المركزية لعمله.
تعرف على المزيد حول نماذج وحدة المعالجة المركزية المختلفة في QEMU .
يسمح لك QEMU / KVM أيضًا بالتحكم في طبولوجيا المعالج ، وعدد الخيوط ، وحجم ذاكرة التخزين المؤقت ، وربط وحدة المعالجة المركزية (VCPU) بالنواة المادية وغير ذلك الكثير.
ما إذا كان هذا ضروريًا لجهاز ظاهري أم لا يعتمد على نوع التطبيق الذي يتم تشغيله على Guest OS. على سبيل المثال ، من الحقائق المعروفة أنه بالنسبة للتطبيقات التي تعالج الحزم ذات PPS العالي ، من المهم أن تقوم
بتثبيت وحدة المعالجة المركزية ، أي عدم السماح بنقل المعالج الفعلي إلى أجهزة افتراضية أخرى.
ذاكرة
التالي في الخط هو RAM. من وجهة نظر Host OS ، لا يختلف الجهاز الظاهري الذي تم تشغيله باستخدام QEMU / KVM عن أي عملية أخرى يتم تشغيلها في مساحة المستخدم لنظام التشغيل. وفقًا لذلك ، يتم تنفيذ عملية تخصيص الذاكرة لجهاز ظاهري بواسطة نفس المكالمات في kernel Host OS ، كما لو كنت قد أطلقت ، على سبيل المثال ، متصفح Chrome.
قبل متابعة قصة ذاكرة الوصول العشوائي (RAM) في الأجهزة الظاهرية ، يلزمك استنباط وشرح مصطلح NUMA - الوصول غير الموحد للذاكرة.
تتضمن بنية الخوادم الفعلية الحديثة وجود معالجين أو أكثر (CPU) وترتبط به ذاكرة الوصول العشوائي (RAM). تسمى هذه المجموعة من ذاكرة المعالج + العقدة أو العقدة. يتم التواصل بين مختلف عقد NUMA من خلال حافلة خاصة - QPI (QuickPath Interconnect)
يتم تخصيص عقدة NUMA المحلية - عندما تستخدم العملية قيد التشغيل في نظام التشغيل المعالج وذاكرة الوصول العشوائي الموجودة في نفس عقدة NUMA ، وعقدة NUMA البعيدة - عندما تستخدم العملية قيد التشغيل في نظام التشغيل المعالج وذاكرة الوصول العشوائي الموجودة في عقد NUMA مختلفة ، وهذا هو ، لتفاعل المعالج والذاكرة ، ونقل البيانات عبر ناقل QPI مطلوب.
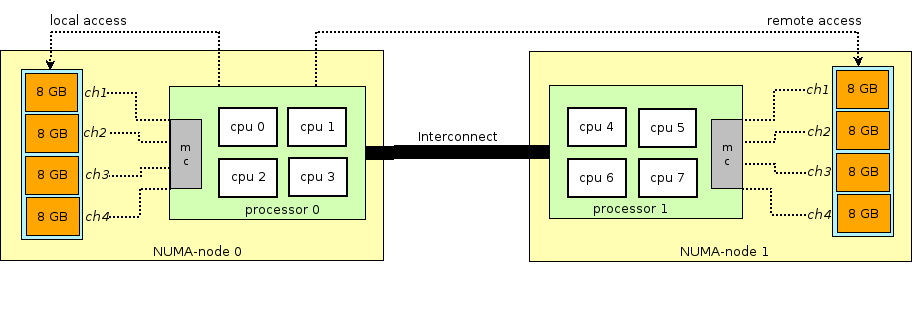
من وجهة نظر الجهاز الظاهري ، كانت الذاكرة قد تم تخصيصها لها بالفعل في وقت إطلاقها ، ولكن في الواقع ليست كذلك ، ويخصص kernel Host OS أقسامًا جديدة من الذاكرة لعملية QEMU / KVM حيث أن التطبيق في Guest OS يطلب ذاكرة إضافية (على الرغم من أنه قد يكون هناك استثناء إذا قمت بتحديد QEMU / KVM مباشرة لتخصيص كل الذاكرة إلى الجهاز الظاهري مباشرة عند بدء التشغيل).
لا يتم تخصيص الذاكرة بايت ، ولكن حسب حجم معين -
الصفحة . حجم الصفحة قابل للتكوين ومن الناحية النظرية يمكن أن يكون أيًا ، لكن في الممارسة العملية ، يكون الحجم هو ٤ كيلوبايت (افتراضي) و ٢ ميغابايت و ١ غيغابايت. تسمى أحجام آخر اثنين
HugePages وغالبا ما تستخدم لتخصيص الذاكرة للأجهزة الظاهرية التي تتطلب الذاكرة. سبب استخدام HugePages في عملية البحث عن تطابق بين العنوان الظاهري للصفحة والذاكرة الفعلية في
Translation Lookaside Buffer (
TLB ) ، والذي بدوره محدود ويخزن المعلومات فقط عن آخر الصفحات المستخدمة. إذا لم تكن هناك معلومات حول الصفحة المطلوبة في TLB ، فستحدث عملية تسمى
TL TL ، وتحتاج إلى استخدام معالج Host OS للعثور على خلية الذاكرة الفعلية المقابلة للصفحة المطلوبة.
هذه العملية غير فعالة وبطيئة ، لذلك يتم استخدام عدد أقل من الصفحات ذات الحجم الأكبر.
يسمح لك QEMU / KVM أيضًا بمضاهاة طبولوجيا NUMA المختلفة لنظام التشغيل Guest ، وتخزين الذاكرة لجهاز ظاهري فقط من نظام مضيف عقدة NUMA معين ، وهكذا. الممارسة الأكثر شيوعًا هي أخذ الذاكرة لجهاز ظاهري من عقدة NUMA محلية إلى المعالجات المخصصة للجهاز الظاهري. السبب هو الرغبة في تجنب التحميل غير الضروري على ناقل
QPI الذي يصل مآخذ توصيل وحدة المعالجة المركزية للخادم الفعلي (بالطبع ، هذا منطقي إذا كان الخادم الخاص بك يحتوي على مآخذ توصيل أو أكثر).
تخزين
كما تعلم ، فإن ذاكرة الوصول العشوائي تسمى الذاكرة التشغيلية لأن محتوياتها تختفي عند إيقاف تشغيل الطاقة أو إعادة تشغيل نظام التشغيل. لتخزين المعلومات ، تحتاج إلى جهاز تخزين ثابت (ROM) أو
تخزين ثابت .
هناك نوعان رئيسيان من التخزين الثابت:
- كتلة التخزين - كتلة من مساحة القرص التي يمكن استخدامها لتثبيت نظام الملفات وإنشاء أقسام. إذا كان وقحا ، فيمكنك اعتباره كقرص عادي.
- تخزين الكائنات - يمكن حفظ المعلومات فقط ككائن (ملف) ، يمكن الوصول إليها عبر HTTP / HTTPS. الأمثلة النموذجية لتخزين الكائنات هي AWS S3 أو Dropbox.
يحتاج الجهاز الظاهري إلى
تخزين مستمر ، ومع ذلك ، كيف يمكن القيام بذلك إذا كان الجهاز الافتراضي "يعيش" في مضيف OS RAM؟ باختصار ، يتم اعتراض QEMU / KVM أي استدعاء لنظام التشغيل الضيف إلى وحدة تحكم القرص الظاهري وتحويله إلى سجل على القرص الفعلي لنظام التشغيل المضيف. هذه الطريقة غير فعالة ، وبالتالي ، هنا ، وكذلك لأجهزة الشبكة ، يتم استخدام برنامج التشغيل الفعلي بدلاً من محاكاة جهاز IDE أو iSCSI بالكامل. اقرأ المزيد عن هذا
هنا . وبالتالي ، يصل الجهاز الظاهري إلى القرص الظاهري الخاص به من خلال برنامج تشغيل فائق ، ثم يقوم QEMU / KVM بإجراء المعلومات المنقولة المكتوبة على القرص الفعلي. من المهم أن نفهم أنه في Host OS ، يمكن تنفيذ الواجهة الخلفية للقرص كرف CEPH أو NFS أو iSCSI.
تتمثل أسهل طريقة لمحاكاة التخزين الثابت في استخدام الملف في بعض دليل Host OS كمساحة قرص لجهاز ظاهري. يدعم QEMU / KVM العديد من التنسيقات المختلفة لهذا النوع من الملفات - raw ، vdi ، vmdk وغيرها. ومع ذلك ، فإن التنسيق الأكثر استخدامًا هو
qcow2 (الإصدار 2 من QEMU للنسخ على الكتابة). بشكل عام ، qcow2 هو ملف منظم بطريقة معينة دون أي نظام تشغيل. يتم توزيع عدد كبير من الأجهزة الافتراضية في صورة qcow2-images (صور) وهي نسخة من قرص النظام الخاص بجهاز ظاهري ، ومعبأة بتنسيق qcow2. هذا له العديد من المزايا - تشفير qcow2 يشغل مساحة أقل بكثير من نسخة أولية من قرص بايت إلى بايت ، QEMU / KVM يمكنه تغيير حجم ملف qcow2 ، مما يعني أنه من الممكن تغيير حجم قرص الجهاز الظاهري ، كما يتم دعم تشفير AES qcow2 (هذا منطقي ، نظرًا لأن صورة الجهاز الظاهري قد تحتوي على ملكية فكرية).
علاوة على ذلك ، عند بدء تشغيل الجهاز الظاهري ، يستخدم QEMU / KVM ملف qcow2 كقرص نظام (أغفل عملية تحميل الجهاز الظاهري هنا ، على الرغم من أن هذه مهمة مهمة أيضًا) ، وللجهاز الظاهري القدرة على قراءة / كتابة البيانات إلى ملف qcow2 عبر التطبيق الفعلي السائق. وبالتالي ، فإن عملية التقاط صور الأجهزة الظاهرية تعمل ، لأنه في أي وقت يحتوي ملف qcow2 على نسخة كاملة من قرص النظام الخاص بالجهاز الظاهري ، ويمكن استخدام الصورة للنسخ الاحتياطي ، ونقلها إلى مضيف آخر ، إلخ.
بشكل عام ، سيتم تعريف ملف qcow2 في Guest OS كجهاز
/ dev / vda ، وسيقوم Guest OS بتقسيم مساحة القرص إلى أقسام وتثبيت نظام الملفات. وبالمثل ، يمكن استخدام ملفات qcow2 التالية المتصلة بواسطة أجهزة QEMU / KVM كأجهزة
/ dev / vdX كتخزين كتلة في جهاز ظاهري لتخزين المعلومات (وهذا هو بالضبط كيفية عمل مكون Openstack Cinder).
شبكة
آخر قائمة الموارد الافتراضية لدينا هي بطاقات الشبكة وأجهزة الإدخال / الإخراج. يحتاج الجهاز الظاهري ، مثل المضيف الفعلي ، إلى
ناقل PCI / PCIe لتوصيل أجهزة الإدخال / الإخراج. QEMU / KVM قادر على محاكاة أنواع مختلفة من الشرائح - q35 أو i440fx (الأول يدعم PCIe ، والثاني يدعم PCI القديم) ، بالإضافة إلى طبولوجيا PCI المختلفة ، على سبيل المثال ، إنشاء ناقل PCI منفصل (ناقل موسع PCI) لنظام NUMA Guest Guest.
بعد إنشاء ناقل PCI / PCIe ، يجب عليك توصيل جهاز إدخال / إخراج به. بشكل عام ، يمكن أن يكون أي شيء من بطاقة الشبكة إلى وحدة معالجة الرسومات الفعلية. وبطبيعة الحال ، بطاقة شبكة ، كلاهما ظاهري بالكامل (واجهة e1000 افتراضية بالكامل ، على سبيل المثال) ، وشبه ظاهري (عملي ، على سبيل المثال) أو بطاقة NIC مادية. يتم استخدام الخيار الأخير للأجهزة الافتراضية لطائرة البيانات حيث تحتاج إلى الحصول على معدلات حزم معدل الخط - أجهزة التوجيه وجدران الحماية ، إلخ.
هناك طريقتان رئيسيتان هنا -
PCI passthrough و
SR-IOV . الفرق الرئيسي بينهما هو أنه بالنسبة لـ PCI-PT ، يتم استخدام برنامج التشغيل فقط داخل نظام التشغيل Guest OS ، وبالنسبة إلى SRIOV ، يتم استخدام برنامج تشغيل Host OS (لإنشاء
VF - وظائف ظاهرية ) وبرنامج التشغيل Guest OS للتحكم في SR-IOV VF.
كتب جونيبر تفاصيل ممتازة حول PCI-PT و SRIOV.

للتوضيح ، تجدر الإشارة إلى أن لعبور PCI و SR-IOV هما تقنيتان متكاملتان. يعمل SR-IOV على تقطيع الوظيفة المادية إلى وظائف افتراضية. يتم ذلك على مستوى نظام التشغيل المضيف. في الوقت نفسه ، يرى Host OS وظائف ظاهرية كجهاز PCI / PCIe آخر. ما يفعله بعدهم ليس مهماً.
يعد PCI-PT آلية لإعادة توجيه أي جهاز Host OS PCI في Guest OS ، بما في ذلك الوظيفة الافتراضية التي أنشأها جهاز SR-IOV
وبالتالي ، قمنا بفحص الأنواع الرئيسية للموارد الافتراضية والخطوة التالية هي فهم كيفية اتصال الجهاز الظاهري بالعالم الخارجي من خلال شبكة.
التبديل الظاهري
إذا كان هناك جهاز افتراضي ، وكانت هناك واجهة افتراضية فيه ، فمن الواضح أن المشكلة تكمن في نقل حزمة من VM إلى أخرى. في برامج Hypervisor المستندة إلى Linux (KVM ، على سبيل المثال) ، يمكن حل هذه المشكلة باستخدام جسر Linux ، ومع ذلك ، فإن مشروع
Open vSwitch (OVS) قد حظي بقبول واسع النطاق.
هناك العديد من الوظائف الأساسية التي مكّنت OVS من الانتشار على نطاق واسع وتصبح طريقة تبديل الحزم الأساسية الفعلية التي تستخدمها العديد من منصات الحوسبة السحابية (مثل Openstack) والحلول الافتراضية.
- نقل حالة الشبكة - عند ترحيل VM بين برامج Hypervisor ، تنشأ المهمة من نقل قوائم ACL و QoSs وجداول إعادة التوجيه L2 / L3 والمزيد. و OVS يمكن أن تفعل ذلك.
- تنفيذ آلية نقل الرزم (datapath) في كل من مساحة النواة والمستخدم
- هندسة CUPS (التحكم / فصل الطائرة) - تسمح لك بنقل وظيفة معالجة الحزمة إلى شرائح متخصصة (يمكن لشرائح Broadcom و Marvell ، على سبيل المثال ، القيام بذلك) ، والتحكم فيها من خلال OVS- طائرة التحكم.
- دعم أساليب التحكم في حركة المرور عن بعد - بروتوكول OpenFlow (مرحبًا ، SDN).
تبدو بنية OVS للوهلة الأولى مخيفة للغاية ، لكنها فقط للوهلة الأولى.
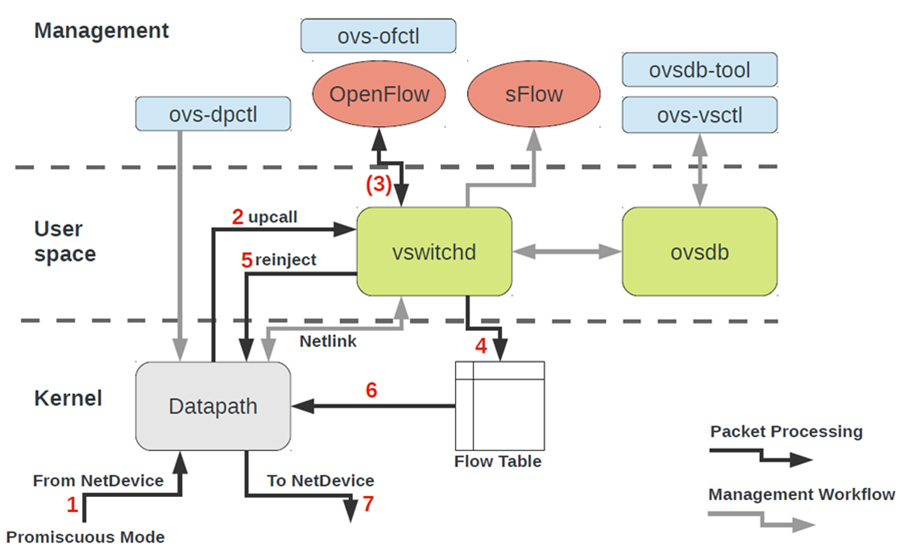
للعمل مع OVS ، تحتاج إلى فهم ما يلي:
- Datapath - تتم معالجة الحزم هنا. التشبيه هو نسيج التبديل لمفتاح الحديد. يتضمن Datapath تلقي الحزم ومعالجة الرؤوس ومطابقات التطابق في جدول التدفق ، والتي تمت برمجتها بالفعل في Datapath. إذا تم تشغيل OVS في kernel ، يتم تطبيقه كوحدة نمطية kernel. إذا تم تشغيل OVS في مساحة المستخدم ، فهذه عملية في Linux مساحة المستخدم.
- vswitchd و ovsdb هما شياطين في مساحة المستخدم ، وهما يطبقان مباشرة وظيفة المحول ، ويخزن التكوين ، ويضبط التدفق على datapath ويبرمجهما.
- إعداد OVS واستكشاف الأخطاء وإصلاحها - ovs-vsctl ، ovs-dpctl ، ovs-ofctl ، ovs-appctl . كل ما هو مطلوب لتسجيل تكوين المنفذ في ovsdb ، قم بتسجيل التدفق الذي يجب التبديل إليه ، وجمع الإحصاءات وما إلى ذلك. أهل الخير كتبوا مقالا عن هذا.
كيف ينتهي الجهاز الشبكي لجهاز افتراضي في OVS؟لحل هذه المشكلة ، نحتاج إلى ربط الواجهة الافتراضية الموجودة في مساحة المستخدم لنظام التشغيل بطريقة أو بأخرى مع datapath OVS الموجود في kernel.
في نظام التشغيل Linux ، يتم نقل الحزم بين عمليات kernel ومساحة المستخدم من خلال واجهتين خاصتين.
تستخدم كلتا الواجهتين كتابة / قراءة حزمة من / إلى ملف خاص لنقل الحزم من عملية مساحة المستخدم إلى kernel والعكس - واصف الملف (FD) (هذا أحد أسباب ضعف أداء التبديل الظاهري إذا كان datapath OVS في kernel - كل حزمة بحاجة إلى الكتابة / القراءة من خلال FD)- TUN (نفق) - جهاز يعمل في وضع L3 ويسمح لك بكتابة / قراءة حزم IP فقط من / إلى FD.
- TAP ( نقرة الشبكة) - نفس واجهة tun + يمكن أن تؤدي عمليات مع إطارات Ethernet ، أي العمل في وضع L2.
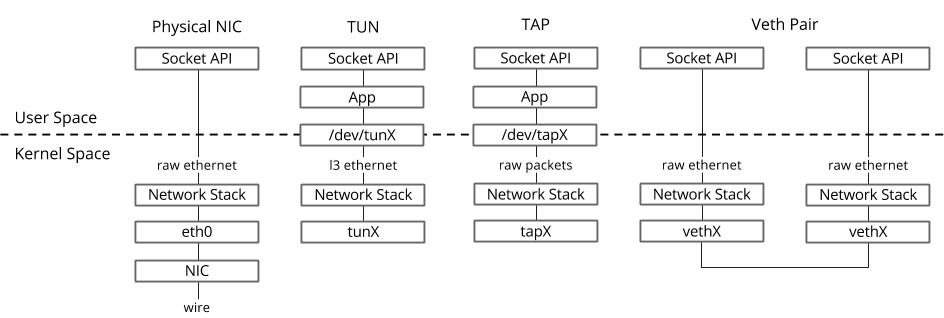 لهذا السبب عند تشغيل جهاز ظاهري في Host OS ، يمكنك رؤية واجهات TAP التي تم إنشاؤها باستخدام رابط ip أو أمر ifconfig - هذا هو الجزء "استجابة" من الأمر ، والذي يكون "مرئيًا" في kernel Host OS. تجدر الإشارة أيضًا إلى أن واجهة TAP لها نفس عنوان MAC مثل الواجهة الفعلية في الجهاز الظاهري.يمكن إضافة واجهة TAP إلى OVS باستخدام أوامر ovs-vsctl - ثم سيتم نقل أي حزمة يتم تبديلها بواسطة OVS إلى واجهة TAP إلى الجهاز الظاهري عبر واصف الملف.
لهذا السبب عند تشغيل جهاز ظاهري في Host OS ، يمكنك رؤية واجهات TAP التي تم إنشاؤها باستخدام رابط ip أو أمر ifconfig - هذا هو الجزء "استجابة" من الأمر ، والذي يكون "مرئيًا" في kernel Host OS. تجدر الإشارة أيضًا إلى أن واجهة TAP لها نفس عنوان MAC مثل الواجهة الفعلية في الجهاز الظاهري.يمكن إضافة واجهة TAP إلى OVS باستخدام أوامر ovs-vsctl - ثم سيتم نقل أي حزمة يتم تبديلها بواسطة OVS إلى واجهة TAP إلى الجهاز الظاهري عبر واصف الملف.قد يكون الإجراء الفعلي لإنشاء جهاز ظاهري مختلفًا ، على سبيل المثال أولاً ، يمكنك إنشاء جسر OVS ، ثم إخبار الجهاز الظاهري بإنشاء واجهة متصلة بهذا OVS ، أو العكس.
الآن ، إذا كنا بحاجة إلى أن نكون قادرين على نقل الحزم بين جهازين أو أكثر من الأجهزة الظاهرية التي تعمل على نفس برنامج Hypervisor ، فإننا نحتاج فقط إلى إنشاء جسر OVS وإضافة واجهات TAP إليه باستخدام أوامر ovs-vsctl. ما الفرق اللازمة لهذا يتم غوغل بسهولة.قد يكون هناك العديد من جسور OVS على برنامج hypervisor ، على سبيل المثال ، هذه هي الطريقة التي يعمل بها Openstack Neutron ، أو يمكن أن تكون الأجهزة الظاهرية في مساحة اسم مختلفة لتنفيذ الاستئجار المتعدد.وإذا كانت الأجهزة الافتراضية موجودة في جسور OVS مختلفة؟لحل هذه المشكلة ، هناك أداة أخرى - الزوج الخامس. يمكن تمثيل زوج Veth كزوج من واجهات الشبكة المتصلة بواسطة كبل - كل ما "يطير" في واجهة واحدة ، "يطير" من آخر. يستخدم زوج Veth لتوصيل العديد من جسور OVS أو جسور Linux مع بعضها البعض. نقطة أخرى مهمة هي أن أجزاء من زوج veth يمكن أن تكون في مساحة مختلفة لنظام التشغيل Linux OS ، أي أنه يمكن استخدام زوج veth أيضًا للاتصال بمساحة الاسم مع بعضها البعض على مستوى الشبكة.أدوات المحاكاة الافتراضية - libvirt ، virsh والمزيد
في الفصول السابقة درسنا الأسس النظرية للمحاكاة الافتراضية ، في هذا الفصل سوف نتحدث عن الأدوات المتاحة للمستخدم مباشرة لبدء وتغيير الأجهزة الافتراضية على برنامج KVM hypervisor.دعونا نتناول ثلاثة مكونات رئيسية تغطي 90 في المائة من جميع أنواع العمليات باستخدام الأجهزة الافتراضية:- libvirt
- virsh CLI
- virt-install
, CLI-, , , qemu_system_x86_64 virt manager, . Cloud-, Openstack, , libvirt.
libvirt
libvirt هو مشروع مفتوح المصدر واسع النطاق يقوم بتطوير مجموعة من الأدوات وبرامج التشغيل لإدارة برامج Hypervisor. وهو يدعم ليس فقط QEMU / KVM ، ولكن أيضًا ESXi ، LXC وأكثر من ذلك بكثير.السبب الرئيسي لشعبيته هو واجهة منظمة ومفهومة للتفاعل من خلال مجموعة من ملفات XML ، بالإضافة إلى القدرة على أتمتة من خلال API. تجدر الإشارة إلى أن libvirt لا تصف جميع الوظائف المحتملة لبرنامج hypervisor ، فهي توفر فقط واجهة ملائمة لاستخدام وظائف برنامج hypervisor المفيدة ، من وجهة نظر المشاركين في المشروع.ونعم ، libvirt هو المعيار الفعلي في عالم المحاكاة الافتراضية اليوم. مجرد إلقاء نظرة على قائمة التطبيقات التي تستخدم libvirt. والخبر السار حول libvirt هو أن جميع الحزم الضرورية مثبتة مسبقًا في جميع أنظمة Host Host الأكثر استخدامًا - Ubuntu و CentOS و RHEL ، لذلك على الأرجح لن تضطر إلى تجميع الحزم اللازمة وتجميع libvirt. في أسوأ الحالات ، سيتعين عليك استخدام مثبّت الدُفعات المناسب (apt و yum و ما شابه).عند التثبيت الأولي وبدء التشغيل ، تنشئ libvirt نظام Linux Linux virbr0 وتكوينه الأدنى بشكل افتراضي.
والخبر السار حول libvirt هو أن جميع الحزم الضرورية مثبتة مسبقًا في جميع أنظمة Host Host الأكثر استخدامًا - Ubuntu و CentOS و RHEL ، لذلك على الأرجح لن تضطر إلى تجميع الحزم اللازمة وتجميع libvirt. في أسوأ الحالات ، سيتعين عليك استخدام مثبّت الدُفعات المناسب (apt و yum و ما شابه).عند التثبيت الأولي وبدء التشغيل ، تنشئ libvirt نظام Linux Linux virbr0 وتكوينه الأدنى بشكل افتراضي.هذا هو السبب عند تثبيت Ubuntu Server ، على سبيل المثال ، سترى في إخراج الأمر ifconfig Linux bridge virbr0 - وهذا نتيجة تشغيل البرنامج الخفي libvirtd
لن يتم توصيل جسر Linux بأي واجهة مادية ، ومع ذلك ، يمكن استخدامه للاتصال بأجهزة افتراضية داخل برنامج مراقبة واحد. بالتأكيد يمكن استخدام Libvirt مع OVS ، ومع ذلك ، يجب على المستخدم إنشاء جسور OVS بشكل مستقل باستخدام أوامر OVS المناسبة.يتم تمثيل أي مورد ظاهري مطلوب لإنشاء جهاز ظاهري (حساب ، شبكة ، تخزين) ككائن في libvirt. مجموعة من ملفات XML المختلفة مسؤولة عن عملية وصف وإنشاء هذه الكائنات.لا معنى لوصف عملية إنشاء شبكات افتراضية ومخازن افتراضية بالتفصيل ، لأن هذا التطبيق موصوف جيدًا في وثائق libvirt:يسمى الجهاز الظاهري نفسه مع جميع أجهزة PCI المتصلة بالمجال في مصطلحات libvirt. هذا أيضًا كائن داخل libvirt ، موصوف بواسطة ملف XML منفصل.يعد ملف XML هذا ، بالمعنى الدقيق للكلمة ، جهازًا افتراضيًا به جميع الموارد الافتراضية - ذاكرة الوصول العشوائي والمعالج وأجهزة الشبكة والأقراص وغير ذلك الكثير. غالبًا ما يطلق على ملف XML هذا اسم libvirt XML أو XML dump.من غير المحتمل أن يكون هناك شخص يفهم جميع معلمات XML libvirt ، ومع ذلك ، فإن هذا ليس مطلوبًا عند وجود وثائق.بشكل عام ، ستكون XML libvirt لنظام التشغيل Ubuntu Desktop Guest بسيطة جدًا - 40-50 سطرًا. نظرًا لأن جميع تحسينات الأداء موصوفة أيضًا في XML libvirt (طبولوجيا NUMA ، طبولوجيا وحدة المعالجة المركزية ، تثبيت وحدة المعالجة المركزية ، وما إلى ذلك) ، لوظائف الشبكة ، يمكن أن يكون libvirt XML معقدًا للغاية ويحتوي على عدة مئات من الخطوط. أوصت أي شركة مصنعة لأجهزة الشبكة التي تشحن برامجها كآلات افتراضية أمثلة على libvirt XML.virsh CLI
الأداة المساعدة virsh هي سطر أوامر "أصلي" لإدارة libvirt. الغرض الرئيسي منه هو إدارة كائنات libvirt الموصوفة كملفات XML. الأمثلة النموذجية هي البدء والإيقاف والتعريف والتدمير وما إلى ذلك. وهذا هو ، دورة حياة الكائنات - إدارة دورة الحياة.يتوفر أيضًا وصف لجميع أوامر الأعلام والأعلام في وثائق libvirt .virt تثبيت
فائدة أخرى تستخدم للتفاعل مع libvirt. واحدة من المزايا الرئيسية هي أنه لا يتعين عليك التعامل مع تنسيق XML ، ولكن يمكنك الحصول على المعلومات المتوفرة في virsh-install. النقطة المهمة الثانية هي بحر الأمثلة والمعلومات على شبكة الإنترنت.وبالتالي ، بغض النظر عن الأداة المساعدة التي تستخدمها ، في النهاية ستكون أداة التحكم هي التي تتحكم في برنامج hypervisor ، لذلك من المهم فهم بنية ومبادئ تشغيله.
استنتاج
في هذه المقالة ، درسنا الحد الأدنى من المعرفة النظرية اللازمة للعمل مع الأجهزة الافتراضية. لم أقدّم عمداً أمثلة واستنتاجات عملية للأوامر ، حيث يمكن العثور على مثل هذه الأمثلة كما تشاء على الويب ، ولم أحدد نفسي مهمة كتابة "دليل خطوة بخطوة". إذا كنت مهتمًا بموضوع معين أو تقنية معينة ، فاترك تعليقاتك واكتب الأسئلة.
روابط مفيدة
شكرا
- ألكساندر شاليموف ، زميلي وخبير في تطوير الشبكات الافتراضية. للتعليقات والتعديلات.
- يفغيني ياكوفليف ، زميلي وخبير في مجال الافتراضية ، للتعليقات والتصحيحات.