
مشاكل في بيئة العمل هي دائما كارثة. يحدث ذلك عندما تذهب إلى المنزل ، والسبب دائمًا يبدو غبيًا. في الآونة الأخيرة ، نفدت الذاكرة على العقد في نظام Kubernetes ، على الرغم من أن العقدة استعادت على الفور ، دون انقطاع واضح. اليوم سوف نتحدث عن هذه الحالة ، حول الضرر الذي لحق بنا وكيف نعتزم تجنب مشكلة مماثلة في المستقبل.
حالة واحدة
السبت 15 يونيو ، 2019 5:12 مساءً
Blue Matador (نعم ، نحن نراقب أنفسنا!) ينشئ تنبيهًا: حدث على إحدى العقد في مجموعة إنتاج Kubernetes - SystemOOM.
17:16
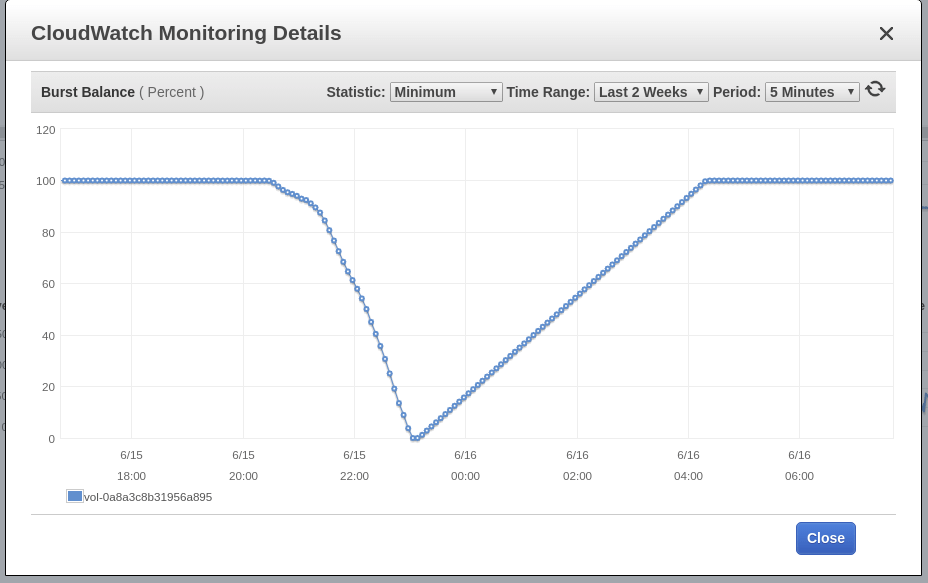
ينشئ Blue Matador تحذيرًا: Low EBS Burst Balance في حجم الجذر للعقدة - حيث حدث الحدث SystemOOM. على الرغم من أن هناك تحذيرًا حول "توازن الاندفاع" جاء بعد إشعار حول SystemOOM ، إلا أن بيانات CloudWatch الفعلية تظهر أن "ميزان الاندفاع" قد وصل إلى المستوى الأدنى في الساعة 17:02. سبب التأخير هو أن مقاييس EBS تتأخر باستمرار عن 10-15 دقيقة ، وأن نظامنا لا يستوعب جميع الأحداث في الوقت الفعلي.
17:18
الآن رأيت تنبيهًا وتحذيرًا. أقوم بسرعة بتشغيل kubectl للحصول على القرون لمعرفة الضرر الذي عانينا منه ، وأنا مندهش لأنني وجدت أن القرون في التطبيق قد ماتت تمامًا 0. أقوم بإجراء العقد العليا kubectl ، لكن هذا الفحص يظهر أيضًا أن العقدة المشتبه بها لديها مشكلة في الذاكرة ؛ صحيح ، لقد تعافى بالفعل ويستخدم ما يقرب من 60 ٪ من ذاكرته. الساعة 5 مساءً ، وتشتد البيرة الحرفية بالفعل. بعد التأكد من أن العقدة كانت قيد التشغيل وأنه لم يكن هناك تلف في جراب واحد ، فقد قررت وقوع حادث. إذا كان هناك أي شيء ، فسوف أقوم بها يوم الاثنين.
إليكم مراسلاتنا مع محطة الخدمة في سلاك في ذلك المساء:

الحالة الثانية
السبت 16 يونيو ، 2019 6:02 مساءً
ينشئ Blue Matador تنبيهًا: الحدث موجود بالفعل على عقدة أخرى ، وكذلك SystemOOM. لا بد أن محطة الخدمة في تلك اللحظة كانت تنظر فقط إلى شاشة الهاتف الذكي ، لأنها كتبت لي وجعلتني أتناول الحدث على الفور ، وأنا شخصياً لا أستطيع تشغيل الكمبيوتر (هل حان الوقت لإعادة تثبيت Windows مرة أخرى؟). ومرة أخرى ، يبدو أن كل شيء طبيعي. لا يتم قتل جراب واحد ، ولا يكاد يستهلك العقدة 70٪ من الذاكرة.
18:06
ينشئ Matador الأزرق تحذيرًا مرة أخرى: EBS Burst Balance. المرة الثانية في اليوم ، مما يعني أنه لا يمكنني إصدار هذه المشكلة على الفرامل. مع CloudWatch دون تغيير ، انحرف توازن الرصيد عن القاعدة قبل أكثر من ساعتين من تحديد المشكلة.
18:11
أذهب إلى Datalog وإلقاء نظرة على البيانات المتعلقة باستهلاك الذاكرة. أرى ذلك قبل الحدث SystemOOM ، واستغرقت العقدة المشتبه بها الكثير من الذاكرة. درب يؤدي إلى قرون لدينا fluologd-sumologic.

يمكنك بوضوح رؤية انحراف حاد في استهلاك الذاكرة ، في نفس الوقت الذي وقعت فيه أحداث SystemOOM تقريبًا. استنتاجي: كانت هذه القرون هي التي أخذت كل الذاكرة ، وعندما حدث SystemOOM ، أدركت Kubernetes أنه يمكن قتل هذه القرون وإعادة تشغيلها لإرجاع الذاكرة الضرورية دون التأثير على القرون الأخرى. أحسنت ، Kubernetes!
فلماذا لم أر هذا يوم السبت عندما اكتشفت أي القرون التي أعيد تشغيلها؟ والحقيقة هي أنني أجري قرونًا بطلاقة في مساحة منفصلة وأسرع لم أفكر في النظر فيها.
الاستنتاج 1: عند البحث عن القرون التي تم إعادة تشغيلها ، تحقق من كل مساحات الأسماء.
بعد تلقي هذه البيانات ، حسبت أنه في اليوم التالي ، لن تنتهي الذاكرة الموجودة على العقد الأخرى ، ومع ذلك ، فقد تقدمت وأعدت تشغيل جميع برامج السومولوجي بحيث بدأوا العمل مع انخفاض استهلاك الذاكرة. في صباح اليوم التالي ، أخطط لتوضيح كيفية دمج العمل بشأن المشكلة في خطة للأسبوع وعدم تحميل مساء الأحد كثيرًا.
23:00
نظرت إلى السلسلة التالية من "المرآة السوداء" (بالمناسبة ، أعجبتني مايلي) وقررت أن أنظر في كيفية عمل المجموعة. استهلاك الذاكرة أمر طبيعي ، لذا لا تتردد في ترك كل شيء كما هو أثناء الليل.
اصلاح
يوم الاثنين ، لقد جعلت الوقت لهذه المشكلة. لا يصب أن نتجول معها كل ليلة. ما أعرفه في الوقت الحالي:
- حاويات فلومينت-سومولوجيك التهمت طن من الذاكرة.
- يسبق حدث SystemOOM نشاط القرص العالي ، لكنني لا أعرف أي نشاط.
في البداية اعتقدت أن حاويات السوائل السميكة مقبولة لأكل الذاكرة عند تدفق مفاجئ للسجلات. ومع ذلك ، بعد التحقق من Sumologic ، رأيت أن السجلات كانت تستخدم بشكل ثابت ، وفي الوقت نفسه عندما كانت هناك مشاكل ، لم تكن هناك زيادة في هذه السجلات.
غوغل قليلاً ، لقد وجدت هذه المهمة على جيثب ، والتي تقترح ضبط بعض إعدادات روبي - لتقليل استهلاك الذاكرة. قررت أن أجربها ، وأضف متغير بيئة إلى مواصفات pod وأعده:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
من خلال النظر إلى البيان السومولوجي الرائع ، لاحظت أنني لم أحدد طلبات الموارد والقيود. لقد بدأت أشك في أن إصلاح RUBY_GCP_HEAP سيؤدي إلى نوع من المعجزة ، لذا فمن المنطقي الآن تعيين حدود استهلاك الذاكرة. حتى لو لم أقوم بإصلاح مشكلة الذاكرة ، فسيكون من الممكن على الأقل قصر استهلاكها على مجموعة القرون هذه. باستخدام القرون kubectl أعلى | grep fluentd-sumologic ، أنا أعرف بالفعل كم من الموارد تطلب:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
الاستنتاج 2: تعيين حدود الموارد ، خاصة بالنسبة لتطبيقات الطرف الثالث.
التحقق من التنفيذ
بعد بضعة أيام ، أؤكد أن الطريقة المذكورة أعلاه تعمل. كان استهلاك الذاكرة مستقراً ، ولا توجد مشاكل مع أي مكون من مكونات Kubernetes و EC2 و EBS. أصبح من الواضح الآن مدى أهمية تحديد طلبات الموارد والقيود المفروضة على جميع البرامج التي أديرها ، وإليك ما يجب القيام به: تطبيق مزيج من حدود الموارد الافتراضية وحصص الموارد .
آخر سر لم يحل هو EBS Burst Balance ، والذي تزامن مع حدث SystemOOM. أعلم أنه عندما يكون هناك القليل من الذاكرة ، يستخدم نظام التشغيل مساحة المبادلة حتى لا تترك بالكامل بدون ذاكرة. لكنني لم يولد بالأمس وأدرك أن Kubernetes لن يبدأ حتى على الخوادم حيث يتم تنشيط ملف الصفحة. فقط الرغبة في التأكد ، تسلقت إلى عقدتي عبر SSH - للتحقق مما إذا كان ملف الصفحة قد تم تنشيطه ؛ لقد استخدمت كلاً من الذاكرة المجانية والذاكرة الموجودة في منطقة المبادلة. لم يتم تنشيط الملف.
ونظرًا لأن المقايضة لا تعمل ، لدي المزيد من الأدلة حول سبب تدفقات I / O ، وهذا هو السبب في نفاد العقدة تقريبًا من الذاكرة ، لا. بشكل عام ، لديّ حدس: قرنة فلوميد نفسها كانت تكتب الكثير من رسائل السجل في هذا الوقت ، وربما حتى رسالة سجل متعلقة بإعداد Ruby GC. من الممكن أيضًا وجود مصادر أخرى لرسائل Kubernetes أو دفتر اليومية التي تصبح منتجة بشكل مفرط عندما تنفد الذاكرة ، وقمت بإزالتها أثناء إعدادها بطلاقة. لسوء الحظ ، لم يعد بإمكاني الوصول إلى ملفات السجل التي تم تسجيلها مباشرة قبل حدوث أي عطل ، والآن لا يمكنني الحفر أكثر.
الاستنتاج 3: في حين أن هناك فرصة ، قم بحفر أعمق عند تحليل الأسباب الجذرية ، مهما كانت المشكلة.
استنتاج
وعلى الرغم من أنني لم أصل إلى جذور الأسباب ، إلا أنني متأكد من أنها ليست ضرورية لمنع نفس الأعطال في المستقبل. الوقت هو المال ، لكنني كنت مشغولاً لفترة طويلة ، وبعد ذلك كتبت هذا المنشور نيابةً عنك. وبما أننا نستخدم Blue Matador ، يتم التعامل مع هذه الأعطال بتفصيل كبير ، لذلك أسمح لنفسي بالإفراج عن شيء ما على الفرامل ، دون أن يصرف انتباهي عن المشروع الرئيسي.