منذ عام تقريبًا أستخدم خدمة Yandex Music وكل شيء يناسبني. ولكن هناك صفحة واحدة مثيرة للاهتمام في هذه الخدمة - التاريخ. يخزن جميع المسارات التي تم الاستماع إليها في الترتيب الزمني. وبالطبع ، أردت تنزيله وتحليل ما سمعته هناك طوال الوقت.

المحاولات الأولى
بدأت في التعامل مع هذه الصفحة ، واجهت مشكلة على الفور. لا تقوم الخدمة بتنزيل جميع المسارات مرة واحدة ، ولكن فقط أثناء التمرير. لم أكن أرغب في تنزيل الشم وفهم حركة المرور ، ولم يكن لدي أي مهارات في هذا الأمر في ذلك الوقت. لذلك ، قررت أن أذهب ببساطة أكثر عن طريق محاكاة المتصفح باستخدام السيلينيوم.
تم كتابة السيناريو. لكنه عمل غير مستقر للغاية ولفترة طويلة. لكنه نجح في تحميل القصة. بعد تحليل بسيط ، تركت النص بدون تعديلات ، حتى بعد مرور بعض الوقت لم أكن أرغب في تنزيل القصة. على أمل الأفضل ، أطلقته. وبالطبع أخطأ. ثم أدركت أن الوقت قد حان للقيام بكل شيء إنسانيًا.
خيار العمل
لتحليل حركة المرور ، اخترت Fiddler لنفسي بسبب وجود واجهة أكثر قوة لحركة المرور http ، على عكس wireshark. تشغيل الشم ، كنت أتوقع أن أرى طلبات api مع رمز. لكن لا. كان هدفنا في music.yandex.ru/handlers/library.jsx . ويطلب إليها الحصول على إذن كامل على الموقع. سنبدأ معها.
ترخيص
لا شيء معقد هنا. نذهب إلى passport.yandex.ru/auth ، ونعثر على معلمات الطلبات ونقدم طلبين للحصول على إذن.
auth_page = self.get('/auth').text csrf_token, process_uuid = self.find_auth_data(auth_page) auth_login = self.post( '/registration-validations/auth/multi_step/start', data={'csrf_token': csrf_token, 'process_uuid': process_uuid, 'login': self.login} ).json() auth_password = self.post( '/registration-validations/auth/multi_step/commit_password', data={'csrf_token': csrf_token, 'track_id': auth_login['track_id'], 'password': self.password} ).json()
وهكذا قمنا بتسجيل الدخول.
تحميل التاريخ
بعد ذلك نذهب إلى music.yandex.ru/user/<user>/history ، حيث نلتقط أيضًا معلمتين مفيدتين لنا عند تلقي معلومات حول المقطوعات الموسيقية. الآن يمكنك تحميل القصة. نحصل على music.yandex.ru/handlers/library.jsx في music.yandex.ru/handlers/library.jsx مع المعلمات {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'} . كنت مهتما في المعلمة ncrnd هنا. عند تقديم الطلبات ، تقوم Yandex دائمًا بتعيين قيم مختلفة لهذه المعلمة ، ولكن كل شيء يعمل بنفس الطريقة. مرة أخرى نحصل على السجل في شكل مسارات معرف ومعلومات تفصيلية حول أفضل عشرة مسارات. من معلومات المسار التفصيلية ، يمكنك حفظ الكثير من البيانات المثيرة للاهتمام لتحليلها لاحقًا. على سبيل المثال ، سنة الإصدار ، مدة التتبع والنوع. يتم الحصول على معلومات عن بقية المسارات من music.yandex.ru/handlers/track-entries.jsx . نحن نحفظ كل هذا العمل في ملف CSV وننتقل إلى التحليل.
تحليل
للتحليل ، نستخدم الأدوات القياسية في شكل الباندا و matplotlib.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('statistics.csv') df.head(3)
تغيير لا شيء الثعبان ل NaN ورميهم بعيدا.
df = df.replace('None', pd.np.nan).dropna()
لنبدأ مع واحد بسيط. دعونا نرى الوقت الذي قضيناه في الاستماع إلى جميع المسارات
duration_sec = df['duration_sec'].astype('int64').sum() ss = duration_sec % 60 m = duration_sec // 60 mm = m % 60 h = m // 60 hh = h % 60 f'{h // 24} {hh}:{mm}:{ss}'
'15 15:30:14'
ولكن هنا يمكنك الجدال حول دقة هذا الرقم ، لأنه ليس من الواضح أي جزء من المسار تحتاج إلى الاستماع إليه ، أضافه ياندكس إلى القصة.
الآن دعونا نلقي نظرة على توزيع المسارات حسب سنة الإصدار.
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
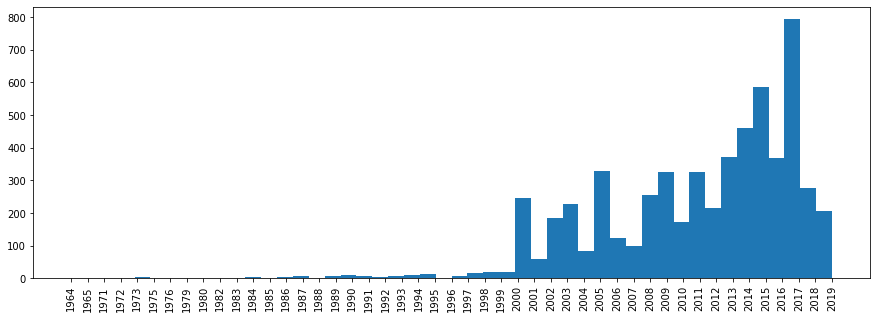
هنا ، الأمر نفسه ليس بهذه البساطة ، حيث أن المجموعات المتنوعة من "Best Hits" سيكون لها عام لاحق.
سيتم بناء إحصائيات أخرى على مبدأ مشابه جدًا. سأقدم مثالاً على أكثر المسارات استمعًا
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()
ومعظم المسارات لعبت للفنان
artist_name = 'Coldplay' df.groupby([ 'artist_id', 'track_id', 'artist', 'track' ])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)
يمكن العثور على الرمز الكامل هنا.