
مع ظهور الهواتف المحمولة ذات الكاميرات عالية الجودة ، بدأنا في إنتاج المزيد والمزيد من الصور ومقاطع الفيديو من لحظات مشرقة لا تنسى في حياتنا. لدى الكثير منا أرشيف صور يمتد إلى الوراء على مدار عقود ويشتمل على آلاف الصور مما يجعل من الصعب عليهم التنقل بشكل متزايد. فقط تذكر المدة التي استغرقتها للعثور على صورة مثيرة للاهتمام قبل بضع سنوات فقط.
أحد أهداف Mail.ru Cloud هو توفير الوسائل الأكثر سهولة للوصول إلى ملفات الصور والفيديو الخاصة بك والبحث فيها. لهذا الغرض ، أنشأنا في Mail.ru Computer Vision Team ونفذنا أنظمة لمعالجة الصور الذكية: البحث حسب الكائن ، حسب المشهد ، عن طريق الوجه ، إلخ. تقنية أخرى مذهلة هي التعرف على المعالم. اليوم ، سوف أخبرك كيف جعلنا هذا حقيقة واقعة باستخدام التعلم العميق.
تخيل الموقف: يمكنك العودة من عطلتك مع مجموعة من الصور. التحدث إلى أصدقائك ، يُطلب منك إظهار صورة لمكان يستحق المشاهدة ، مثل القصر والقلعة والهرم والمعبد والبحيرة والشلال والجبل وما إلى ذلك. تتعجل لتمرير مجلد معرض الصور الخاص بك في محاولة للعثور على مجلد جيد حقًا. على الأرجح ، يتم فقدها بين مئات الصور ، وستقول أنك ستظهرها لاحقًا.
نحن نحل هذه المشكلة من خلال تجميع صور المستخدمين في ألبومات. سيتيح لك ذلك العثور على الصور التي تحتاج إليها بمجرد نقرات قليلة. الآن لدينا ألبومات تم تجميعها بالوجه والجسم والمشهد وأيضًا المعالم.
تعد الصور ذات المعالم الأساسية ضرورية لأنها غالبًا ما تبرز أحداث حياتنا (مثل الرحلات). يمكن أن تكون هذه الصور مع بعض العمارة أو البرية في الخلفية. هذا هو السبب في أننا نسعى إلى تحديد موقع هذه الصور وجعلها متاحة للمستخدمين بسهولة.
خصوصيات الاعتراف البارز
هناك فارق بسيط هنا: لا يعلم المرء مجرد نموذج ويتسبب في التعرف على المعالم على الفور - هناك عدد من التحديات.
أولاً ، لا يمكننا أن نقول بوضوح ما هو "معلم" حقًا. لا يمكننا معرفة سبب كون المبنى علامة فارقة ، في حين أن المبنى الآخر بجانبه ليس كذلك. إنه ليس مفهومًا رسميًا ، مما يجعل الأمر أكثر تعقيدًا لتوضيح مهمة الاعتراف.
ثانيا ، المعالم متنوعة بشكل لا يصدق. يمكن أن تكون هذه المباني ذات قيمة تاريخية أو ثقافية ، مثل المعبد أو القصر أو القلعة. بدلا من ذلك ، قد تكون هذه جميع أنواع الآثار. أو الميزات الطبيعية: البحيرات ، الأخاديد ، الشلالات وهلم جرا. أيضا ، هناك نموذج واحد ينبغي أن يكون قادرا على العثور على كل تلك المعالم.
ثالثًا ، الصور ذات المعالم القليلة للغاية. وفقًا لتقديراتنا ، فهي تمثل 1 إلى 3 في المائة فقط من صور المستخدم. هذا هو السبب في أننا لا نستطيع تحمل ارتكاب أخطاء في الاعتراف لأننا إذا عرضنا على شخص ما صورة بدون معلم ، فسيكون ذلك واضحًا تمامًا وسيحدث رد فعل سلبي. أو ، على العكس من ذلك ، تخيل أنك تظهر صورة ذات مكان اهتمام في نيويورك لشخص لم يزر الولايات المتحدة مطلقًا. وبالتالي ، يجب أن يكون نموذج التعرف منخفض FPR (معدل إيجابي كاذب).
الرابعة ، حوالي 50 ٪ من المستخدمين أو حتى أكثر عادة تعطيل حفظ البيانات الجغرافية. نحتاج إلى أخذ هذا في الاعتبار واستخدام الصورة نفسها فقط لتحديد الموقع. اليوم ، تستخدم معظم الخدمات القادرة على التعامل مع المعالم بطريقة ما البيانات الجغرافية من خصائص الصورة. ومع ذلك ، كانت متطلباتنا الأولية أكثر صرامة.
الآن اسمحوا لي أن أريك بعض الأمثلة.
فيما يلي ثلاثة أشياء متشابهة ، ثلاثة كاتدرائيات قوطية في فرنسا. على اليسار توجد كاتدرائية Amiens ، والكاتدرائية الموجودة في الوسط هي كاتدرائية Reims ، وتقع كاتدرائية Notre-Dame de Paris على اليمين.

حتى الإنسان يحتاج إلى بعض الوقت للنظر عن كثب ويرى أن هذه كاتدرائيات مختلفة ، لكن يجب أن يكون المحرك قادرًا على فعل الشيء نفسه ، وحتى أسرع من الإنسان.
إليكم تحدٍ آخر: كل الصور الثلاث هنا تعرض فيلم Notre-Dame de Paris من زوايا مختلفة. الصور مختلفة تمامًا ، لكنها لا تزال بحاجة إلى التعرف عليها واستردادها.

الميزات الطبيعية مختلفة تماما عن الهندسة المعمارية. على اليسار توجد قيصرية في إسرائيل ، وعلى اليمين يوجد Englischer Garten في ميونيخ.

هذه الصور تعطي النموذج القليل من الأدلة لتخمينها.
طريقتنا
تعتمد طريقة عملنا تمامًا على الشبكات العصبية التلافيفية العميقة. كانت إستراتيجية التدريب التي اخترناها تسمى تعلم المناهج مما يعني التعلم في عدة خطوات. لتحقيق قدر أكبر من الكفاءة مع وجود أو عدم توفر بيانات جغرافية ، حققنا استنتاجًا محددًا. دعني أخبرك عن كل خطوة بمزيد من التفصيل.
مجموعة البيانات
البيانات هي وقود التعلم الآلي. بادئ ذي بدء ، كان علينا الجمع بين مجموعة البيانات لتعليم النموذج.
قسمنا العالم إلى 4 مناطق ، يتم استخدام كل منها في خطوة محددة في عملية التعلم. بعد ذلك ، اخترنا البلدان في كل منطقة ، واخترنا قائمة بالمدن لكل بلد ، وجمعنا مجموعة من الصور. فيما يلي بعض الأمثلة.

أولاً ، حاولنا جعل نموذجنا يتعلم من قاعدة البيانات التي تم الحصول عليها. النتائج كانت سيئة. أظهر تحليلنا أن البيانات كانت قذرة. كان هناك الكثير من الضوضاء تتداخل مع الاعتراف بكل معلم. ماذا كنا نفعل؟ سيكون من المكلف والمرهق وليس من الحكمة مراجعة جميع البيانات يدوياً. لذلك ، ابتكرنا عملية لتنظيف قاعدة البيانات تلقائيًا حيث يتم استخدام المناولة اليدوية في خطوة واحدة فقط: اخترنا 3 إلى 5 صور مرجعية لكل معلم والتي أظهرت بالتأكيد الكائن المطلوب بزاوية أكثر أو أقل مناسبة. يعمل بسرعة كافية لأن كمية البيانات المرجعية هذه صغيرة بالمقارنة مع قاعدة البيانات بأكملها. ثم يتم إجراء التنظيف التلقائي بناءً على الشبكات العصبية التلافيفية العميقة.
علاوة على ذلك ، سأستخدم مصطلح "التضمين" الذي أعني به ما يلي. لدينا شبكة عصبية تلافيفية. لقد قمنا بتدريبه على تصنيف الكائنات ، ثم قمنا بقطع آخر طبقة تصنيف ، واخترنا بعض الصور ، وقمنا بتحليلها بواسطة الشبكة ، وحصلنا على ناقل رقمي عند الإخراج. هذا هو ما سوف اسمي التضمين.
كما قلت من قبل ، رتبنا عملية التعلم الخاصة بنا في عدة خطوات تقابل أجزاء من قاعدة البيانات الخاصة بنا. لذلك ، أولاً ، نأخذ إما الشبكة العصبية من الخطوة السابقة أو الشبكة التهيئة.
لدينا صور مرجعية لأحد المعالم ، ونقوم بمعالجتها بواسطة الشبكة والحصول على العديد من الزينة. الآن يمكننا المضي قدما في تنظيف البيانات. نلتقط جميع الصور من مجموعة البيانات للمعالم ونعالج كل صورة بواسطة الشبكة أيضًا. نحصل على بعض حفلات الزفاف وتحديد المسافة إلى مرجع حفلات الزفاف لكل واحد. بعد ذلك ، نحدد متوسط المسافة ، وإذا تجاوز بعض العتبة التي تعتبر معلمة للخوارزمية ، نتعامل مع الكائن على أنه غير معلم. إذا كان متوسط المسافة أقل من العتبة ، فإننا نحتفظ بالصورة.
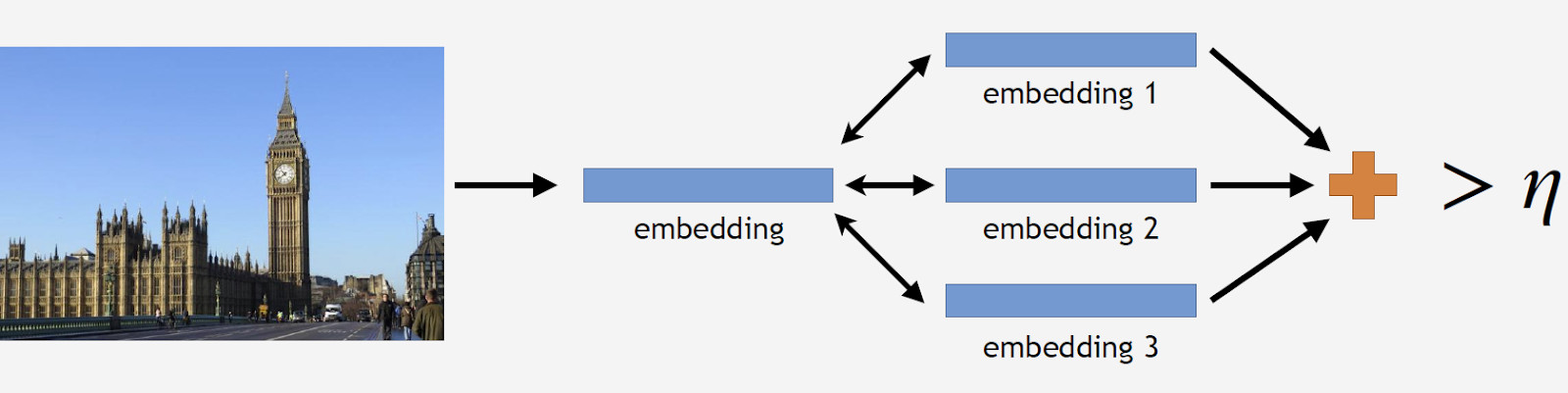
نتيجة لذلك ، كان لدينا قاعدة بيانات تحتوي على أكثر من 11 ألف معلم من أكثر من 500 مدينة في 70 دولة ، وأكثر من 2.3 مليون صورة. تذكر أن الجزء الرئيسي من الصور لا يحتوي على علامات على الإطلاق. نحتاج أن نقول ذلك لنماذجنا بطريقة أو بأخرى. لهذا السبب ، أضفنا 900 ألف صورة بدون معالم إلى قاعدة البيانات الخاصة بنا وقمنا بتدريب نموذجنا باستخدام مجموعة البيانات الناتجة.
قدمنا اختبار متواجد حاليا لقياس جودة التعلم. نظرًا لأن المعالم لا تحدث إلا في 1 إلى 3٪ من جميع الصور ، فقد جمعنا يدويًا مجموعة من 290 صورة أظهرت علامة بارزة. كانت تلك الصور متنوعة ومعقدة للغاية ، حيث تم تصوير عدد كبير من الكائنات من زوايا مختلفة لجعل الاختبار أكثر صعوبة بالنسبة للنموذج. باتباع نفس النمط ، اخترنا 11 ألف صورة بدون معالم ، معقدًا أيضًا ، وحاولنا العثور على كائنات تشبه المعالم في قاعدة بياناتنا.
لتقييم جودة التعلم ، نقيس دقة نموذجنا باستخدام الصور مع المعالم وبدونها. هذه هي مقاييسنا الرئيسية.
النهج الحالية
هناك القليل من المعلومات حول التعرف على المعالم في الأدبيات. تعتمد معظم الحلول على الميزات المحلية. الفكرة الرئيسية هي أن لدينا بعض الصور الاستعلام وصورة من قاعدة البيانات. تم العثور على الميزات المحلية - النقاط الرئيسية - ثم مطابقتها. إذا كان عدد التطابقات كبيرًا بما يكفي ، فإننا نستنتج أننا وجدنا معلمًا بارزًا.
حاليا ، فإن أفضل طريقة هي DELF (الميزات المحلية العميقة) التي تقدمها Google ، والتي تجمع بين الميزات المحلية المطابقة والتعلم العميق. من خلال الحصول على صورة إدخال تتم معالجتها بواسطة الشبكة التلافيفية ، نحصل على بعض ميزات DELF.
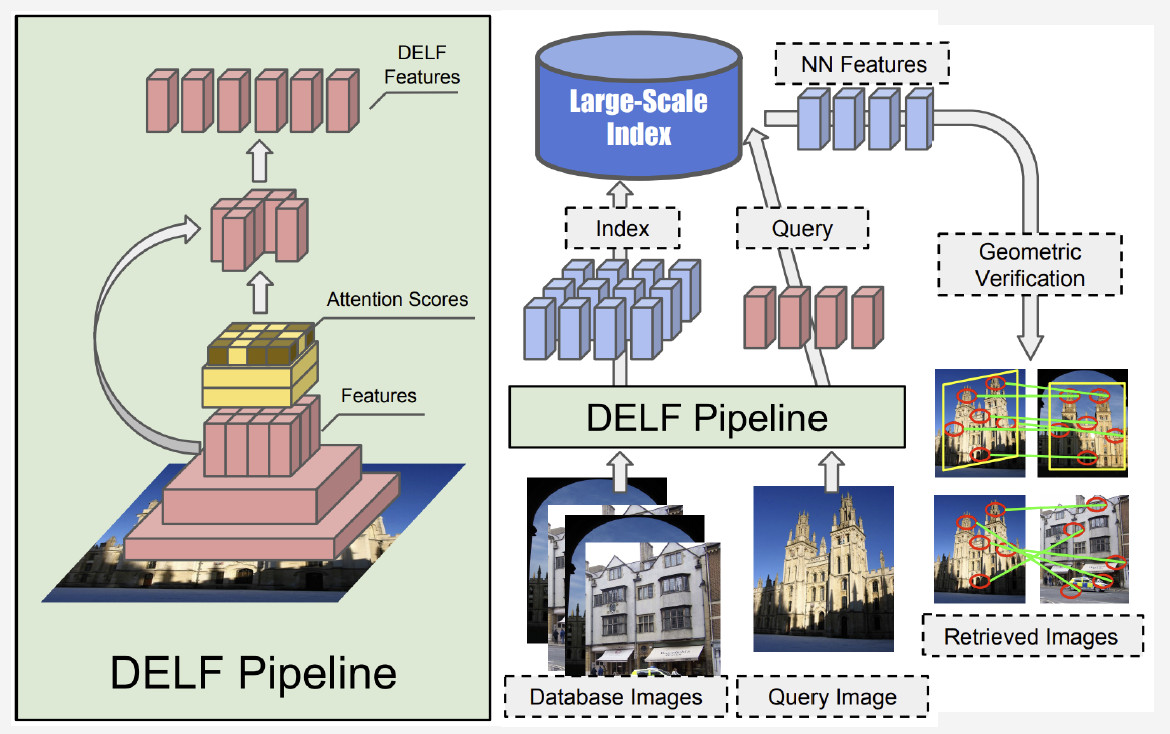
كيف يعمل التعرف على المعالم؟ لدينا بنك للصور وصورة إدخال ، ونريد أن نعرف ما إذا كان يعرض علامة فارقة أم لا. من خلال تشغيل شبكة DELF لجميع الصور ، يمكن الحصول على ميزات مقابلة لقاعدة البيانات وصورة الإدخال. بعد ذلك ، نقوم بإجراء بحث عن طريق أقرب أسلوب جوار والحصول على صور مرشح مع ميزات في الإخراج. نحن نستخدم التحقق الهندسي لمطابقة الميزات: إذا نجح ، فإننا نستنتج أن الصورة تظهر علامة بارزة.
شبكة عصبية تلافيفية
ما قبل التدريب أمر بالغ الأهمية للتعلم العميق. لذلك استخدمنا قاعدة بيانات للمشاهد لتدريب شبكتنا العصبية مسبقًا. لماذا بهذه الطريقة؟ المشهد هو كائن متعدد يتكون من عدد كبير من الكائنات الأخرى. لاندمارك هو مثال للمشهد. من خلال التدريب المسبق على النموذج باستخدام قاعدة البيانات هذه ، يمكننا إعطائها فكرة عن بعض الميزات ذات المستوى المنخفض والتي يمكن تعميمها بعد ذلك من أجل التعرف على معلم ناجح.
استخدمنا شبكة عصبية من عائلة الشبكة المتبقية كنموذج. الفرق الحاسم في هذه الشبكات هو أنها تستخدم كتلة متبقية تتضمن اتصالًا تخطيًا يسمح للإشارة بالقفز فوق الطبقات ذات الأوزان والانتقال بحرية. هذه البنية تجعل من الممكن تدريب شبكات عميقة ذات مستوى عالٍ من الجودة والتحكم في تأثير التدرج اللانهائي ، وهو أمر ضروري للتدريب.
نموذجنا هو Wide ResNet-50-2 ، وهو إصدار من ResNet-50 حيث يتضاعف عدد التلفيفات في كتلة عنق الزجاجة الداخلية.

الشبكة تعمل بشكل جيد جدا. لقد اختبرناها باستخدام قاعدة بيانات المشهد الخاصة بنا ، وهنا النتائج:
عملت شبكة ResNet عريضة مرتين تقريبًا بأسرع خدمة ResNet-200. بعد كل شيء ، هو تشغيل سرعة أمر بالغ الأهمية للإنتاج. بالنظر إلى كل هذه الاعتبارات ، اخترنا Wide ResNet-50-2 كشبكة عصبية رئيسية لدينا.
تدريب
نحن بحاجة إلى وظيفة الخسارة لتدريب شبكتنا. قررنا استخدام منهج التعلم المتري لاختياره: يتم تدريب شبكة عصبية بحيث تتدفق عناصر من نفس الفصل إلى مجموعة واحدة ، في حين أن مجموعات الفئات المختلفة يجب أن تكون متباعدة قدر الإمكان. بالنسبة للمعالم ، استخدمنا خسارة المركز التي تسحب عناصر من فئة واحدة نحو بعض المراكز. من السمات المهمة لهذا النهج أنه لا يتطلب أخذ عينات سلبية ، الأمر الذي يصبح شيئًا صعبًا إلى حد ما في العصور اللاحقة.
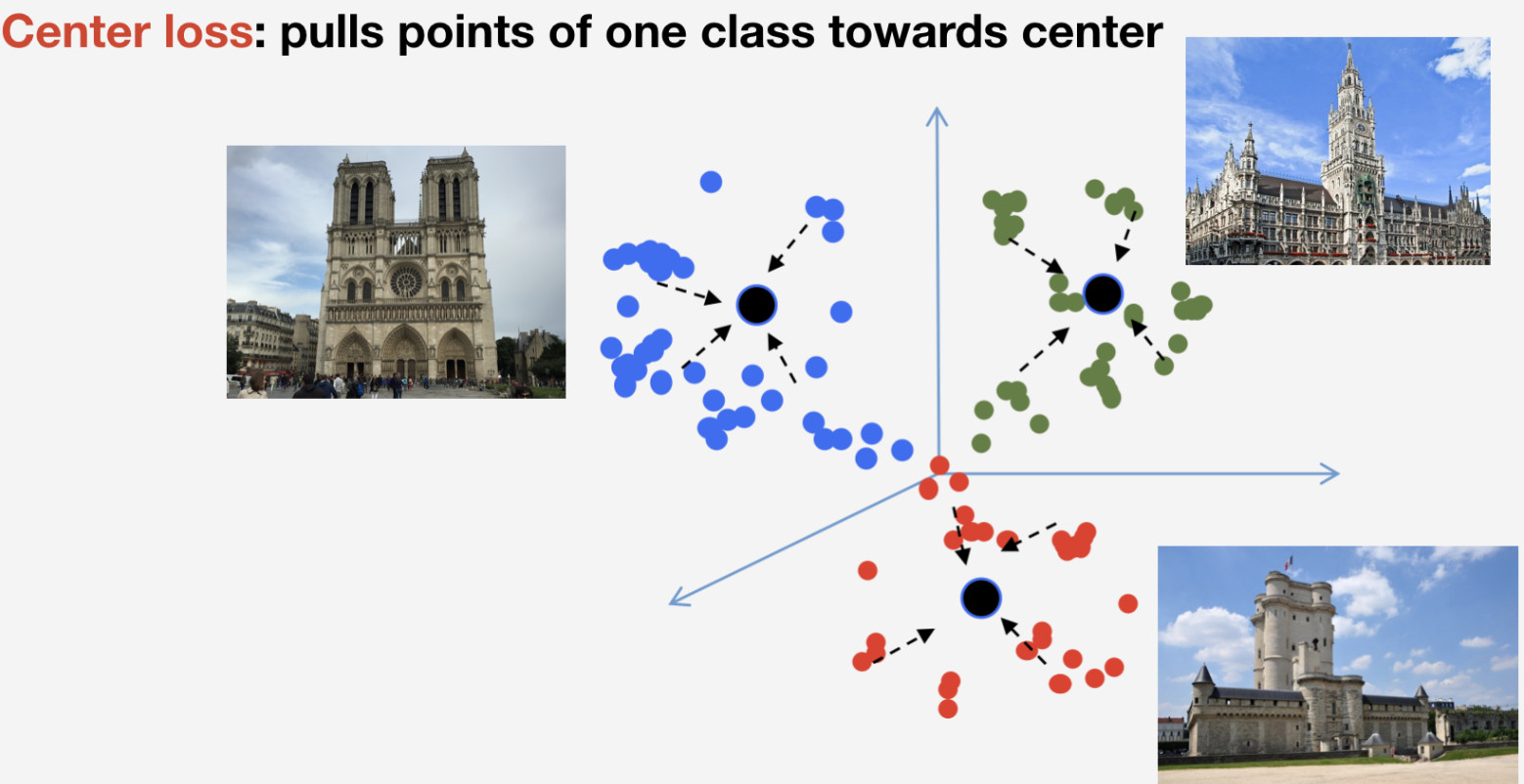
تذكر أن لدينا فئات n من المعالم وفئة أخرى "غير مميزة" لا يتم استخدام خسارة المركز لها. نحن نعتبر أن المعلم هو كائن واحد ونفس الشيء ، وله هيكل ، لذلك فمن المنطقي تحديد مركزه. بالنسبة لغير المعالم ، يمكن أن يشير إلى أي شيء ، لذلك لا معنى لتحديد مركز له.
ثم قمنا بتجميع كل هذا ، وهناك نموذجنا للتدريب. تضم ثلاثة أجزاء رئيسية:
- Wide ResNet 50-2 شبكة عصبية تلافيفية مدربة مسبقًا على قاعدة بيانات للمشاهد ؛
- تضمين جزء يضم طبقة متصلة بالكامل وطبقة القاعدة الدفعية ؛
- المصنف عبارة عن طبقة متصلة بالكامل ، يتبعه زوج يتكون من خسارة Softmax وفقدان المركز.

كما تتذكر ، يتم تقسيم قاعدة البيانات الخاصة بنا إلى 4 أجزاء حسب المنطقة. نستخدم هذه الأجزاء الأربعة في نموذج لتعلم المناهج. لدينا مجموعة بيانات حالية ، وفي كل مرحلة من مراحل التعلم ، نضيف جزءًا آخر من العالم للحصول على مجموعة بيانات جديدة للتدريب.
يتكون النموذج من ثلاثة أجزاء ، ونحن نستخدم معدل تعليمي محدد لكل جزء في عملية التدريب. هذا مطلوب حتى تتمكن الشبكة من معرفة المعالم من جزء بيانات جديد قمنا بإضافته وتذكر البيانات التي تعلمناها بالفعل. أثبتت العديد من التجارب أن هذا النهج هو الأكثر كفاءة.
لذلك ، قمنا بتدريب نموذجنا. الآن نحن بحاجة إلى أن ندرك كيف يعمل. دعونا نستخدم خريطة تنشيط الفصل للعثور على جزء الصورة الذي تتفاعل معه شبكتنا العصبية بسهولة أكبر. تُظهر الصورة أدناه الصور المدخلة في الصف الأول ، ويتم عرض نفس الصور المغطاة بخريطة تنشيط الفصل من الشبكة التي قمنا بتدريبها في الخطوة السابقة في الصف الثاني.

تُظهر الخريطة الحرارية الأجزاء التي تحضرها الشبكة بشكل أكبر. كما هو موضح في خريطة تنشيط الفصل ، لقد تعلمت شبكتنا العصبية مفهوم المعالم بنجاح.
استدلال
الآن نحن بحاجة إلى استخدام هذه المعرفة بطريقة أو بأخرى لإنجاز الأمور. نظرًا لأننا استخدمنا خسارة المركز للتدريب ، في حالة الاستدلال ، يبدو أنه من المنطقي جدًا تحديد النقط الوسطى للمعالم أيضًا.
للقيام بذلك ، نأخذ جزءًا من الصور من مجموعة التدريب لبعض المعالم البارزة ، على سبيل المثال ، الفارس البرونزي في سانت بطرسبرغ. ثم نقوم بمعالجتها بواسطة الشبكة ، والحصول على حفلات الزفاف ، وحساب متوسط ، واستخلاص centroid.
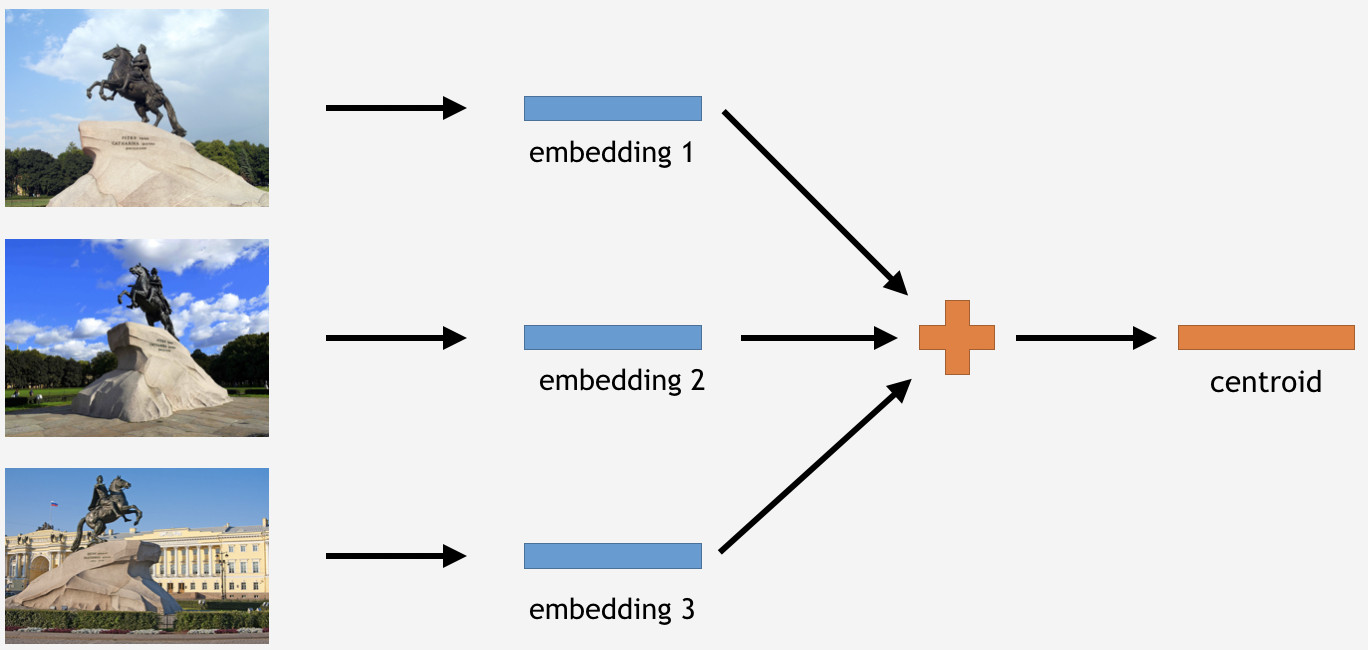
ومع ذلك ، إليك سؤال: كم عدد الأقطار الوسطى لكل معلم من المنطقي اشتقاقه؟ في البداية ، بدا واضحا ومنطقيا القول: واحد centroid. ليس بالضبط ، كما اتضح. قررنا في البداية صنع centroid واحد أيضا ، وكانت النتيجة ليست سيئة. فلماذا عدة centroids؟
أولاً ، البيانات التي لدينا ليست نظيفة للغاية. على الرغم من أننا قمنا بتنظيف مجموعة البيانات ، فقد أزلنا بيانات النفايات الواضحة فقط. ومع ذلك ، لا تزال هناك صور لا تضيع بوضوح ولكن تؤثر سلبًا على النتيجة.
على سبيل المثال ، لديّ فصل الشتاء "قصر الشتاء" في سان بطرسبرغ. أريد أن استخلاص centroid لذلك. ومع ذلك ، تتضمن مجموعة البيانات الخاصة به بعض الصور مع Palace Square و General Headquarters ، لأن هذه الكائنات قريبة من بعضها البعض. إذا تم تحديد النقطه الوسطى لجميع الصور ، فإن النتيجة لن تكون مستقرة. ما نحتاج إلى فعله هو تجميع حفلاتهم المستمدة من الشبكة العصبية بطريقة ما ، وأخذ فقط النقطه الوسطى التي تتعامل مع قصر الشتاء ، ومتوسط باستخدام البيانات الناتجة.

ثانياً ، ربما تم التقاط صور من زوايا مختلفة.
فيما يلي مثال على مثل هذا السلوك الموضح مع Belfry of Bruges. وقد تم اشتقاق اثنين من النقط الوسطى لذلك. في الصف العلوي في الصورة ، هناك تلك الصور الأقرب إلى النقطه الوسطى الأولى ، وفي الصف الثاني - الصور الأقرب إلى النقطه الوسطى الثانية.

يتعامل أول centroid مع المزيد من الصور "الكبرى" التي تم التقاطها في السوق في Bruges على المدى القصير. أما النقطة الثانية فتتناول الصور التي التقطت من مسافة بعيدة في شوارع معينة.
كما اتضح ، من خلال استخلاص العديد من النقط الوسطى لكل فئة من المعالم ، يمكننا التفكير في استنتاج زوايا الكاميرا المختلفة لهذا المعلم.
لذلك ، كيف نحصل على هذه المجموعات لاشتقاق centroids؟ نحن نطبق المجموعات الهرمية (رابط كامل) على مجموعات البيانات لكل معلم. نستخدمها للعثور على مجموعات صالحة يمكن أن تستخلص منها النقط الوسطى. نعني بالمجموعات الصحيحة تلك التي تضم 50 صورة على الأقل نتيجة للتجميع. المجموعات الأخرى مرفوضة. نتيجة لذلك ، حصلنا على حوالي 20 ٪ من المعالم مع أكثر من واحد النقطه الوسطى.
الآن للاستدلال. يتم الحصول عليها في خطوتين: أولاً ، نقوم بتغذية صورة الإدخال إلى شبكتنا العصبية التلافيفية والحصول على التضمين ، ثم نطابق التضمين مع centroids باستخدام نقطة المنتج. إذا كانت الصور تحتوي على بيانات جغرافية ، فنحن نقصر البحث على النقط الوسطى ، والتي تشير إلى المعالم الموجودة في نطاق 1 × 1 كم من موقع الصورة. يتيح ذلك إجراء بحث أكثر دقة وعتبة أقل للمطابقة اللاحقة. إذا تجاوزت المسافة الناتجة الحد الفاصل الذي يمثل معلمة للخوارزمية ، فإننا نستنتج أن الصورة لها علامة بارزة مع الحد الأقصى لقيمة نقطة المنتج. إذا كانت أقل ، فهي صورة غير مميزة.
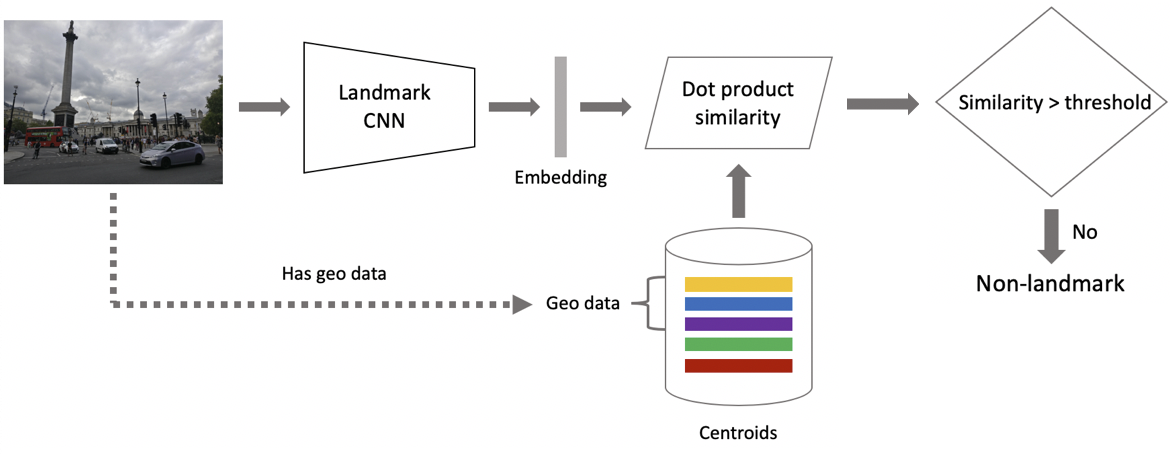
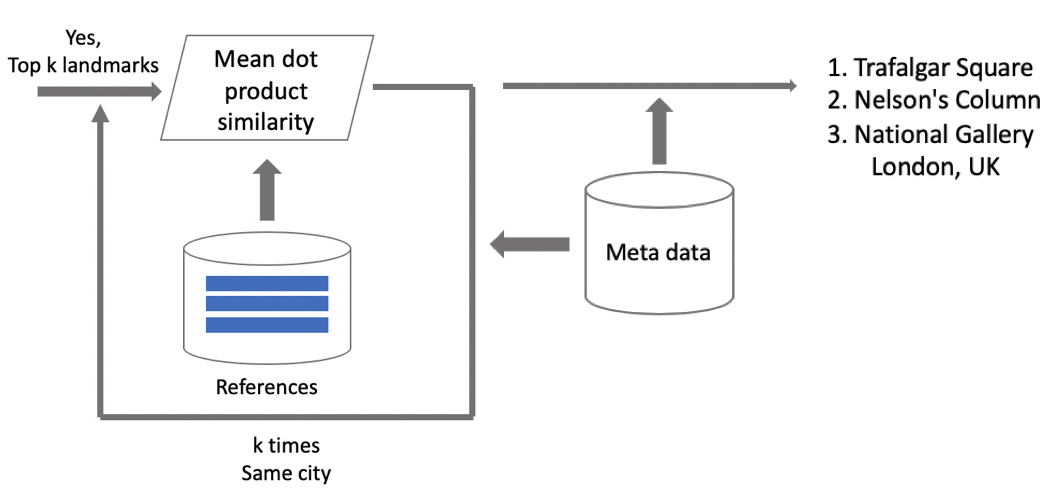
لنفترض أن الصورة لها علامة بارزة. إذا كان لدينا بيانات جغرافية ، فإننا نستخدمها ونستمد إجابة منها. إذا كانت البيانات الجغرافية غير متوفرة ، فإننا نقوم بإجراء فحص إضافي. عندما كنا نقوم بتنظيف مجموعة البيانات ، قمنا بعمل مجموعة من الصور المرجعية لكل فصل. يمكننا تحديد التضمينات الخاصة بهم ، ثم الحصول على مسافة متوسطة منها لتضمين صورة الاستعلام. إذا تجاوز الحد الأدنى ، يتم تمرير التحقق ، ونأتي بالبيانات الوصفية ونتوصل إلى نتيجة. من المهم ملاحظة أنه يمكننا تشغيل هذا الإجراء للعديد من المعالم التي تم العثور عليها في صورة ما.
نتائج الاختبارات
قمنا بمقارنة نموذجنا مع DELF ، والذي أخذنا به معايير من شأنها أن تظهر أفضل أداء في اختبارنا. النتائج متطابقة تقريبا.
ثم قمنا بتصنيف المعالم إلى نوعين: متكرر (أكثر من 100 صورة في قاعدة البيانات) ، والتي تمثل 87 ٪ من جميع المعالم في الاختبار ، ونادرة. نموذجنا يعمل بشكل جيد مع النماذج المتكررة: 85.3 ٪ من الدقة. مع المعالم النادرة ، كان لدينا 46 ٪ والتي لم تكن سيئة على الإطلاق ، وهذا يعني أن نهجنا عملت بشكل جيد إلى حد ما حتى مع وجود القليل من البيانات.
ثم أجرينا اختبار A / B مع صور المستخدم. ونتيجة لذلك ، ارتفع معدل تحويل شراء مساحة في السحاب بنسبة 10 ٪ ، وانخفض معدل تحويل إلغاء تثبيت تطبيقات الجوال بنسبة 3 ٪ ، وزاد عدد مرات مشاهدة الألبوم بنسبة 13 ٪.
دعونا نقارن سرعتنا مع DELF. مع GPU ، يتطلب DELF تشغيل 7 شبكة لأنه يستخدم 7 مقاييس للصور ، بينما يستخدم منهجنا فقط 1. مع وحدة المعالجة المركزية ، يستخدم DELF بحثًا أطول عن طريق أسلوب الجوار والتحقق الهندسي طويل جدًا. في النهاية ، كانت طريقتنا أسرع 15 مرة مع وحدة المعالجة المركزية. يظهر منهجنا سرعة أعلى في كلتا الحالتين ، وهو أمر بالغ الأهمية للإنتاج.
النتائج: ذكريات من عطلة
في بداية هذا المقال ، ذكرت حلاً للتمرير والعثور على الصور المميزة المطلوبة. ها هو ذا.
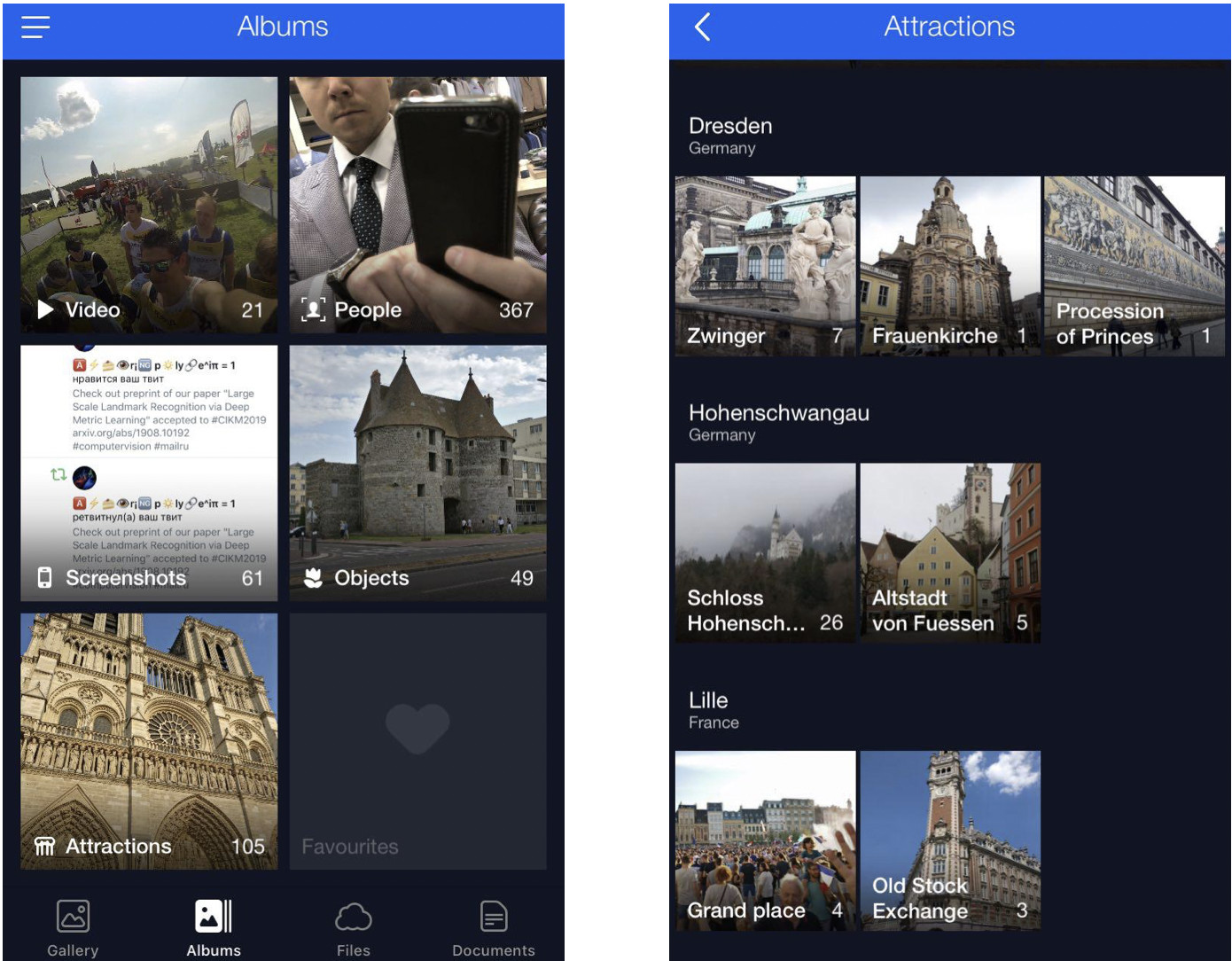
هذه سحابة بلدي حيث يتم تصنيف جميع الصور في ألبومات. هناك ألبومات "People" و "Objects" و "Attractions". في ألبوم مناطق الجذب ، يتم تصنيف المعالم في ألبومات مجمعة حسب المدينة. يؤدي النقر فوق Dresdner Zwinger إلى فتح ألبوم يحتوي على صور لهذه العلامة المميزة فقط.
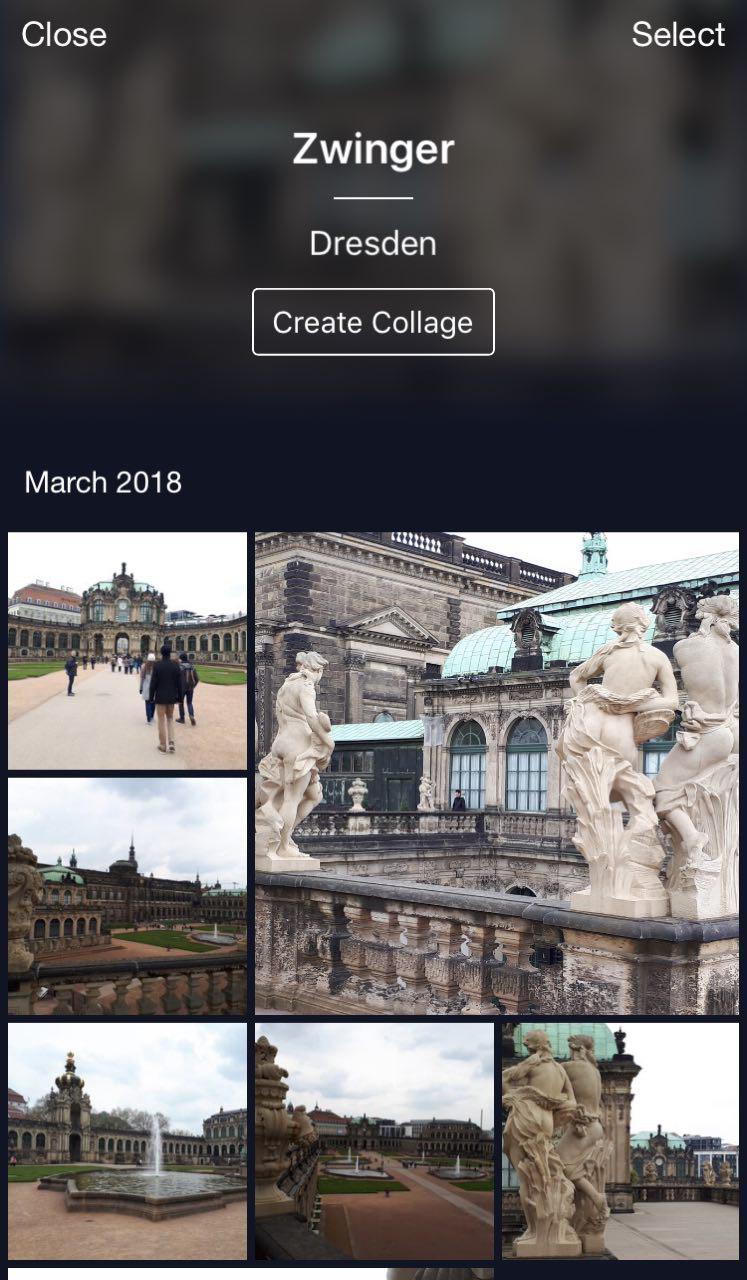
ميزة مفيدة: يمكنك الذهاب في إجازة ، والتقاط بعض الصور وتخزينها في السحابة الخاصة بك. في وقت لاحق ، عندما ترغب في تحميلها على Instagram أو مشاركتها مع الأصدقاء والعائلة ، فلن تضطر إلى البحث واختيار طويل للغاية - الصور المطلوبة ستكون متاحة ببضع نقرات.
الاستنتاجات
اسمحوا لي أن أذكرك بالميزات الرئيسية لحلنا.
- تنظيف قاعدة البيانات شبه التلقائي. مطلوب القليل من العمل اليدوي لرسم الخرائط الأولي ، ومن ثم ستقوم الشبكة العصبية بالباقي. هذا يسمح بتنظيف البيانات الجديدة بسرعة واستخدامها لإعادة تدريب النموذج.
- نحن نستخدم الشبكات العصبية التلافيفية العميقة والتعلم المتري العميق الذي يسمح لنا بتعلم البنية في الفصول بكفاءة.
- لقد استخدمنا تعلم المناهج ، أي التدريب في أجزاء ، كنموذج تدريب. كان هذا النهج مفيدًا للغاية بالنسبة لنا. نحن نستخدم العديد من النقط الوسطى على الاستدلال ، والتي تسمح باستخدام البيانات النظيفة وإيجاد وجهات نظر مختلفة من المعالم.
قد يبدو أن التعرف على الكائنات مهمة تافهة. ومع ذلك ، عند استكشاف احتياجات المستخدم في الحياة الواقعية ، نجد تحديات جديدة مثل التعرف على المعالم. هذه التقنية تجعل من الممكن إخبار الناس بشيء جديد عن العالم باستخدام الشبكات العصبية. انها مشجعة للغاية ومحفزة!