يمكن العثور على الدورة الكاملة باللغة الروسية على هذا الرابط .
دورة اللغة الإنجليزية الأصلية متاحة على هذا الرابط .

محتوى
- مقابلة مع سيباستيان ترون
- مقدمة
- نقل نموذج التعلم
- MobileNet
- CoLab: القطط مقابل الكلاب مع نقل التدريب
- الغوص في الشبكات العصبية التلافيفية
- الجزء العملي: تحديد الألوان مع نقل التدريب
- النتائج
مقابلة مع سيباستيان ترون
- هذا هو الدرس 6 وهو مخصص تمامًا لنقل التعلم. نقل التعلم هو عملية استخدام نموذج موجود مع القليل من التنقيح للمهام الجديدة. يساعد نقل التدريب في تقليل وقت التدريب في النموذج من خلال إعطاء بعض الزيادة في الكفاءة عند التعلم في البداية. سيباستيان ، ما رأيك في نقل التدريب؟ هل سبق لك أن استخدمت منهجية نقل التدريس في عملك وأبحاثك؟
- تم تكريس رسالتي على وجه التحديد لموضوع نقل التدريب وكان يسمى " التفسير على أساس نقل التدريب ". عندما كنا نعمل على أطروحة ، كانت الفكرة أنه من الممكن تعليم كيفية التمييز بين جميع الكائنات الأخرى من هذا النوع على كائن واحد (مجموعة البيانات ، الكيان) في أشكال وأشكال مختلفة. في العمل ، استخدمنا الخوارزمية المتقدمة ، والتي ميزت الخصائص الرئيسية (السمات) للكائن ويمكن مقارنتها بكائن آخر. المكتبات مثل Tensorflow تأتي بالفعل مع نماذج مدربة مسبقا.
- نعم ، في Tensorflow لدينا مجموعة كاملة من النماذج المدربة مسبقًا والتي يمكنك استخدامها لحل المشكلات العملية. سنتحدث عن مجموعات جاهزة في وقت لاحق.
- نعم نعم! إذا كنت تفكر في ذلك ، فإن الناس يشاركون في نقل التدريب طوال الوقت طوال حياتهم.
- هل يمكننا القول أنه بفضل طريقة نقل التدريب ، لن يضطر طلابنا الجدد في مرحلة ما إلى معرفة شيء ما عن التعلم الآلي لأنه سيكفي توصيل نموذج تم إعداده بالفعل واستخدامه؟
- البرمجة تكتب سطرا سطرا ، ونحن نعطي الأوامر إلى الكمبيوتر. هدفنا هو التأكد من أن كل شخص على هذا الكوكب قادر وقادر على البرمجة من خلال تزويد الكمبيوتر بأمثلة فقط من بيانات الإدخال. توافق ، إذا كنت ترغب في تعليم الكمبيوتر لتمييز القطط عن الكلاب ، فإن العثور على 100 ألف صورة مختلفة للقطط و 100 ألف صورة مختلفة للكلاب أمر صعب للغاية ، وبفضل نقل التدريب يمكنك حل هذه المشكلة في عدة أسطر.
- نعم فعلا! شكرا على الإجابات ودعونا ننتقل أخيرا إلى التعلم.
مقدمة
- مرحبا ومرحبا بكم مرة أخرى!
- آخر مرة قمنا بتدريب شبكة عصبية تلافيفية لتصنيف القطط والكلاب في الصورة. تم إعادة تدريب شبكتنا العصبية الأولى ، لذا لم تكن نتيجتها عالية جدًا - حيث بلغت دقة حوالي 70٪. بعد ذلك ، قمنا بتطبيق تمديد البيانات والتسرب (الفصل التعسفي للخلايا العصبية) ، مما سمح لنا بزيادة دقة التنبؤات بنسبة تصل إلى 80 ٪.
- على الرغم من حقيقة أن 80 ٪ قد يبدو مؤشرا ممتازا ، فإن الخطأ 20 ٪ لا يزال كبيرا جدا. أليس كذلك؟ ماذا يمكننا أن نفعل لزيادة دقة التصنيف؟ في هذا الدرس ، سوف نستخدم تقنية نقل المعرفة (نقل نموذج المعرفة) ، والتي سوف تتيح لنا استخدام النموذج الذي طوره الخبراء والمدربون على صفائف البيانات الضخمة. كما سنرى في الممارسة العملية ، من خلال نقل نموذج المعرفة ، يمكننا تحقيق دقة تصنيف 95 ٪. لنبدأ!
نقل نموذج التعلم
في عام 2012 ، أحدثت شبكة AlexNet العصبية ثورة في عالم التعلم الآلي وشاعت استخدام الشبكات العصبية التلافيفية للتصنيف من خلال الفوز بتحدي ImageNet Large Scale Visual.
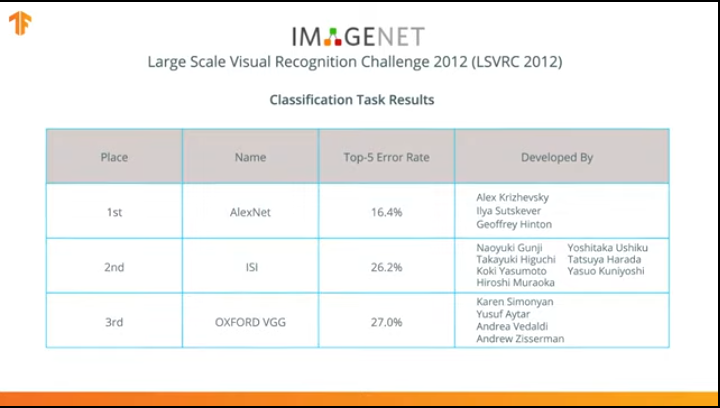
بعد ذلك ، بدأ الصراع في تطوير شبكات عصبية أكثر دقة وكفاءة يمكن أن تتجاوز AlexNet في مهام تصنيف الصور من مجموعة بيانات ImageNet.
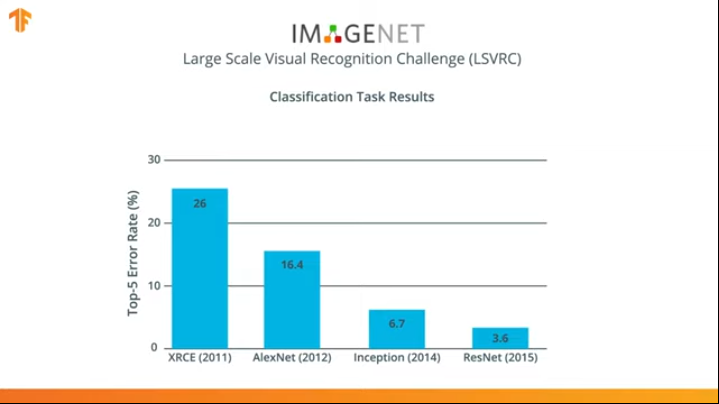
لعدة سنوات ، تم تطوير الشبكات العصبية التي تتعامل مع مهمة التصنيف بشكل أفضل من AlexNet - Inception و ResNet.
توافق على أنه سيكون من الرائع أن تكون قادرًا على الاستفادة من هذه الشبكات العصبية المدربة بالفعل على مجموعات البيانات الضخمة من ImageNet واستخدامها في مصنفك للقطط والكلاب؟
اتضح أننا يمكن أن نفعل ذلك! وتسمى هذه التقنية نقل التعلم. تعتمد الفكرة الأساسية لطريقة نقل نموذج التدريب على حقيقة أنه بعد تدريب شبكة عصبية على مجموعة كبيرة من البيانات ، يمكننا تطبيق النموذج الذي تم الحصول عليه على مجموعة بيانات لم يصادفها هذا النموذج بعد. هذا هو السبب في أن التقنية تسمى نقل التعلم - نقل عملية التعلم من مجموعة بيانات إلى أخرى.
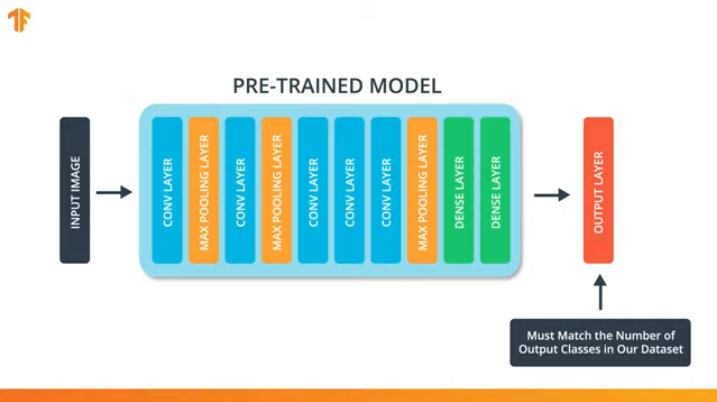
من أجل تطبيق منهجية نقل نموذج التدريب ، نحتاج إلى تغيير الطبقة الأخيرة من شبكتنا العصبية التلافيفية:
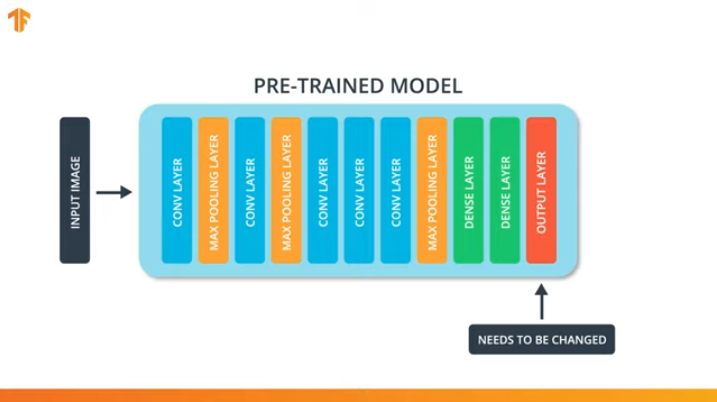
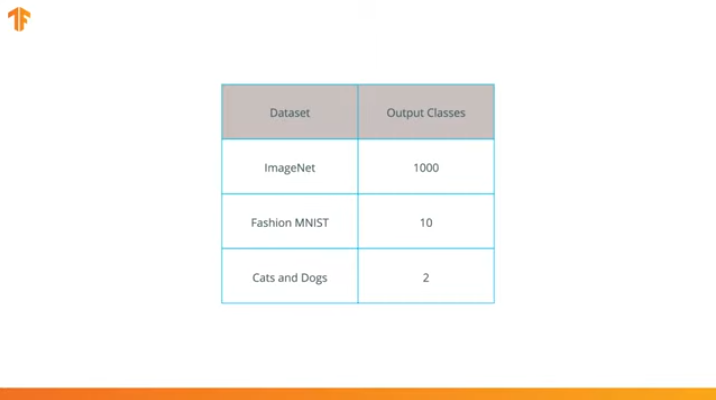
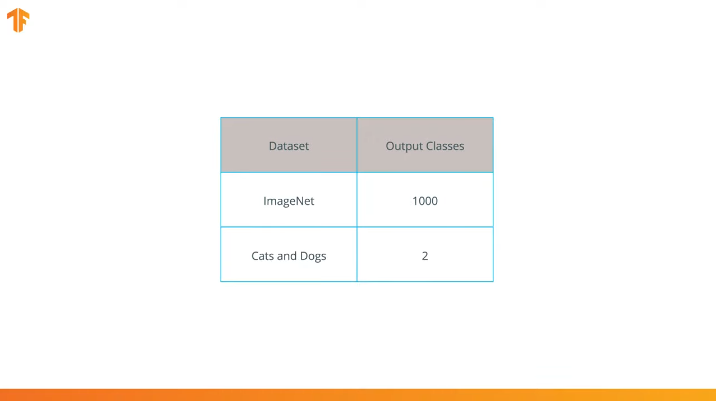
نحن نقوم بهذه العملية لأن كل مجموعة بيانات تتكون من عدد مختلف من فئات الإخراج. على سبيل المثال ، تحتوي مجموعات البيانات في ImageNet على 1000 فئة مخرجات مختلفة. FashionMNIST يحتوي على 10 فصول. تتكون مجموعة بيانات التصنيف الخاصة بنا من فصلين فقط - القطط والكلاب.
هذا هو السبب في أنه من الضروري تغيير الطبقة الأخيرة من شبكتنا العصبية التلافيفية بحيث تحتوي على عدد المخرجات التي تتوافق مع عدد الطبقات في المجموعة الجديدة.
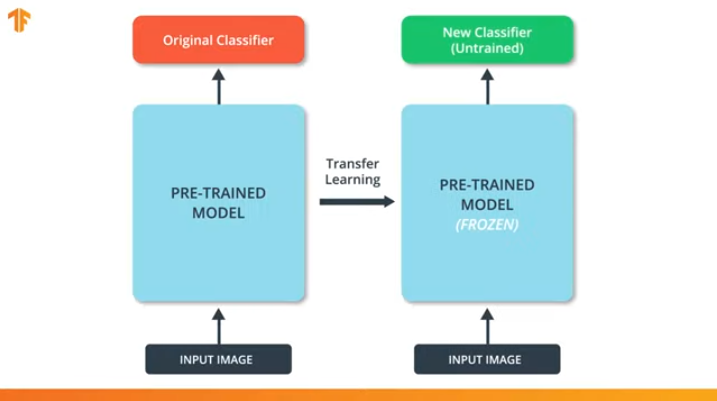
نحتاج أيضًا إلى التأكد من أننا لا نغير النموذج المُدرَّج مسبقًا أثناء عملية التدريب. يتمثل الحل في إيقاف تشغيل متغيرات النموذج الذي تم تدريبه مسبقًا - فنحن ببساطة نمنع الخوارزمية من تحديث القيم أثناء الانتشار للأمام وللخلف لتغييرها.
وتسمى هذه العملية "تجميد النموذج".
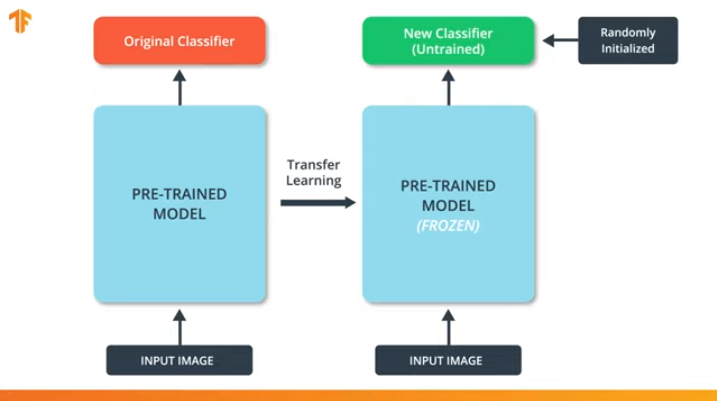
من خلال "تجميد" معلمات النموذج المُدرَّب مسبقًا ، نسمح لنا بمعرفة الطبقة الأخيرة فقط من شبكة التصنيف ، وتبقى قيم متغيرات النموذج المدرّب مسبقًا على حالها.
ومن المزايا الأخرى التي لا جدال فيها للنماذج التي تم تدريبها مسبقًا تقليل وقت التدريب من خلال تدريب الطبقة الأخيرة فقط مع عدد أقل بكثير من المتغيرات ، وليس النموذج بأكمله.
إذا لم "نقوم بتجميد" متغيرات النموذج المُدرَّب مسبقًا ، فعند عملية التدريب ، ستتغير قيم المتغيرات في مجموعة البيانات الجديدة. وذلك لأن قيم المتغيرات في الطبقة الأخيرة من التصنيف سيتم ملؤها بقيم عشوائية. بسبب القيم العشوائية في الطبقة الأخيرة ، سوف يرتكب نموذجنا أخطاء كبيرة في التصنيف ، الأمر الذي يستلزم بدوره تغييرات قوية في الأوزان الأولية في النموذج المُدرَّب مسبقًا ، وهو أمر غير مرغوب فيه للغاية بالنسبة لنا.
لهذا السبب يجب أن نتذكر دائمًا أنه عند استخدام النماذج الحالية ، يجب "تجميد" قيم المتغيرات ويجب إيقاف تشغيل الحاجة إلى تدريب نموذج تم تدريبه مسبقًا.
الآن بعد أن عرفنا كيف يعمل نقل نموذج التدريب ، علينا فقط اختيار شبكة عصبية مدربة مسبقًا لاستخدامها في المصنف الخاص بنا! هذا سنفعله في الجزء التالي.
MobileNet
كما ذكرنا سابقًا ، تم تطوير شبكات عصبية فعالة للغاية أظهرت نتائج عالية على مجموعات بيانات ImageNet - AlexNet ، Inception ، Resonant. هذه الشبكات العصبية هي شبكات عميقة للغاية وتحتوي على آلاف وحتى ملايين المعلمات. يتيح عدد كبير من المعلمات للشبكة معرفة أنماط أكثر تعقيدًا وبالتالي تحقيق دقة تصنيف متزايدة. يؤثر عدد كبير من معلمات التدريب في الشبكة العصبية على سرعة التعلم وكمية الذاكرة المطلوبة لتخزين الشبكة وتعقيد العمليات الحسابية.
في هذا الدرس ، سوف نستخدم شبكة العصبية التلافيفية الحديثة MobileNet. MobileNet هو بنية شبكة عصبية تلافيفية فعالة تقلل من مقدار الذاكرة المستخدمة للحوسبة مع الحفاظ على دقة عالية للتنبؤات. هذا هو السبب في أن MobileNet مثالي للاستخدام على الأجهزة المحمولة مع قدر محدود من الذاكرة وموارد الحوسبة.
تم تطوير MobileNet بواسطة Google وتم تدريبه على مجموعة بيانات ImageNet.
نظرًا لتدريبات MobileNet على 1000 فصل من مجموعة بيانات ImageNet ، فإن MobileNet يحتوي على 1000 فئة مخرجات ، بدلاً من الفصلين اللذين نحتاجهما - قطة وكلب.
لإكمال نقل التدريب ، يتم تحميل متجه المعالم مسبقًا بدون طبقة تصنيف:

في Tensorflow ، يمكن استخدام متجه المعالم المحملة كطبقة Keras عادية مع إدخال البيانات بحجم معين.
نظرًا لتدريب MobileNet على مجموعة بيانات ImageNet ، فسوف نحتاج إلى نقل حجم بيانات الإدخال إلى تلك التي تم استخدامها في عملية التدريب. في حالتنا ، تم تدريب MobileNet على صور RGB ثابتة بحجم 224 × 224 بكسل.
يحتوي TensorFlow على مستودع تم تدريبه مسبقًا يسمى TensorFlow Hub.
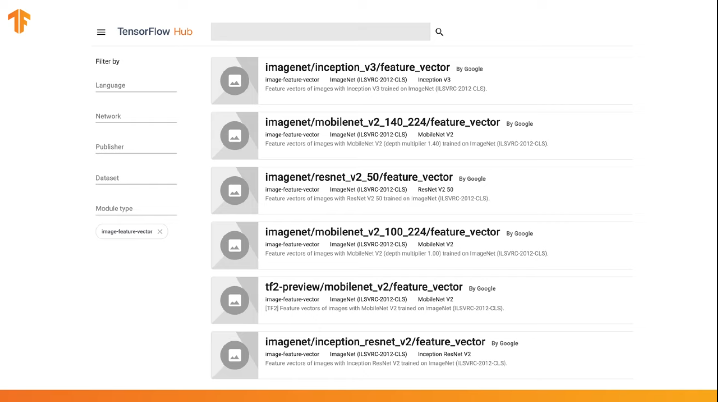
يحتوي TensorFlow Hub على بعض النماذج المدربة مسبقًا والتي تم فيها استبعاد طبقة التصنيف الأخيرة من بنية الشبكة العصبية لإعادة استخدامها لاحقًا.
يمكنك استخدام TensorFlow Hub في التعليمات البرمجية في عدة أسطر:

يكفي تحديد عنوان URL الخاص بمتجه الميزة في نموذج التدريب المرغوب فيه ، ثم تضمين النموذج في مصنفنا مع الطبقة الأخيرة مع العدد المطلوب من فئات المخرجات. إنها الطبقة الأخيرة التي ستخضع للتدريب وتغيير قيم المعلمات. يتم تجميع وتدريب نموذجنا الجديد بنفس الطريقة التي اتبعناها من قبل:
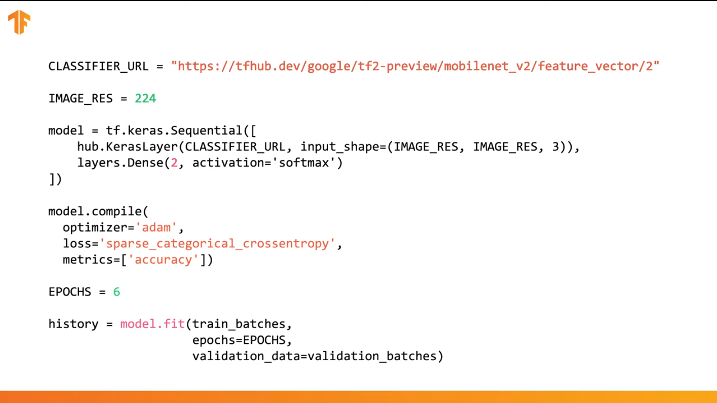
دعونا نرى كيف ستعمل في الواقع وكتابة التعليمات البرمجية المناسبة.
CoLab: القطط مقابل الكلاب مع نقل التدريب
رابط CoLab باللغة الروسية و CoLab باللغة الإنجليزية .
TensorFlow Hub عبارة عن مستودع به نماذج تم تدريبها مسبقًا يمكننا استخدامها.
نقل التعلم هو عملية نأخذ فيها نموذجًا تم تدريبه مسبقًا ونوسعه لأداء مهمة محددة. في الوقت نفسه ، نترك جزء النموذج المُدرَّب مسبقًا والذي ندمجه في الشبكة العصبية دون مساس ، ولكن فقط ندرب طبقات الإخراج الأخيرة للحصول على النتيجة المرجوة.
في هذا الجزء العملي ، سنختبر كلا الخيارين.
يتيح لك هذا الرابط استكشاف القائمة الكاملة للطرز المتوفرة.
في هذا الجزء من كولاب
- سوف نستخدم نموذج TensorFlow Hub للتنبؤات ؛
- سوف نستخدم نموذج TensorFlow Hub لمجموعة بيانات القطط والكلاب ؛
- دعنا ننقل التدريب باستخدام النموذج من TensorFlow Hub.
قبل الشروع في تنفيذ الجزء العملي الحالي ، نوصي بإعادة تعيين Runtime -> Reset all runtimes...
واردات المكتبة
في هذا الجزء العملي ، سوف نستخدم عددًا من ميزات مكتبة TensorFlow التي لم تصدر بعد في الإصدار الرسمي. هذا هو السبب في أننا سنقوم أولاً بتثبيت إصدار TensorFlow و TensorFlow Hub للمطورين.
يؤدي تثبيت إصدار dev من TensorFlow إلى تنشيط أحدث إصدار مثبت تلقائيًا. بعد الانتهاء من التعامل مع هذا الجزء العملي ، نوصي باستعادة إعدادات TensorFlow والعودة إلى الإصدار الثابت عبر عنصر القائمة Runtime -> Reset all runtimes... سيؤدي تنفيذ هذا الأمر إلى إعادة تعيين جميع إعدادات البيئة إلى الإعدادات الأصلية.
!pip install tf-nightly-gpu !pip install "tensorflow_hub==0.4.0" !pip install -U tensorflow_datasets
الاستنتاج:
Requirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.7.1) Requirement already satisfied: google-pasta>=0.1.6 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.1.7) Collecting tf-estimator-nightly (from tf-nightly-gpu) Downloading https://files.pythonhosted.org/packages/ea/72/f092fc631ef2602fd0c296dcc4ef6ef638a6a773cb9fdc6757fecbfffd33/tf_estimator_nightly-1.14.0.dev2019092201-py2.py3-none-any.whl (450kB) |████████████████████████████████| 450kB 45.9MB/s Requirement already satisfied: numpy<2.0,>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.16.5) Requirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.11.2) Requirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.0.1) Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.33.6) Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from keras-applications>=1.0.8->tf-nightly-gpu) (2.8.0) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (3.1.1) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (41.2.0) Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (0.15.6) Installing collected packages: tb-nightly, tf-estimator-nightly, tf-nightly-gpu Successfully installed tb-nightly-1.15.0a20190911 tf-estimator-nightly-1.14.0.dev2019092201 tf-nightly-gpu-1.15.0.dev20190821 Collecting tensorflow_hub==0.4.0 Downloading https://files.pythonhosted.org/packages/10/5c/6f3698513cf1cd730a5ea66aec665d213adf9de59b34f362f270e0bd126f/tensorflow_hub-0.4.0-py2.py3-none-any.whl (75kB) |████████████████████████████████| 81kB 5.0MB/s Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (3.7.1) Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.16.5) Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.12.0) Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.4.0->tensorflow_hub==0.4.0) (41.2.0) Installing collected packages: tensorflow-hub Found existing installation: tensorflow-hub 0.6.0 Uninstalling tensorflow-hub-0.6.0: Successfully uninstalled tensorflow-hub-0.6.0 Successfully installed tensorflow-hub-0.4.0 Collecting tensorflow_datasets Downloading https://files.pythonhosted.org/packages/6c/34/ff424223ed4331006aaa929efc8360b6459d427063dc59fc7b75d7e4bab3/tensorflow_datasets-1.2.0-py3-none-any.whl (2.3MB) |████████████████████████████████| 2.3MB 4.9MB/s Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.16.0) Requirement already satisfied, skipping upgrade: wrapt in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.11.2) Requirement already satisfied, skipping upgrade: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.3.0) Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.16.5) Requirement already satisfied, skipping upgrade: requests>=2.19.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.21.0) Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (4.28.1) Requirement already satisfied, skipping upgrade: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (3.7.1) Requirement already satisfied, skipping upgrade: psutil in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (5.4.8) Requirement already satisfied, skipping upgrade: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.2.1) Requirement already satisfied, skipping upgrade: absl-py in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.8.0) Requirement already satisfied, skipping upgrade: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.14.0) Requirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.12.0) Requirement already satisfied, skipping upgrade: termcolor in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.1.0) Requirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (19.1.0) Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2.8) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2019.6.16) Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (3.0.4) Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (1.24.3) Requirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.6.1->tensorflow_datasets) (41.2.0) Requirement already satisfied, skipping upgrade: googleapis-common-protos in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow_datasets) (1.6.0) Installing collected packages: tensorflow-datasets Successfully installed tensorflow-datasets-1.2.0
لقد رأينا بالفعل واستخدمنا بعض الواردات من قبل. من الجديد - استيراد tensorflow_hub ، الذي قمنا بتثبيته والذي tensorflow_hub في هذا الجزء العملي.
from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
الاستنتاج:
WARNING:tensorflow: TensorFlow's `tf-nightly` package will soon be updated to TensorFlow 2.0. Please upgrade your code to TensorFlow 2.0: * https://www.tensorflow.org/beta/guide/migration_guide Or install the latest stable TensorFlow 1.X release: * `pip install -U "tensorflow==1.*"` Otherwise your code may be broken by the change.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
الجزء 1: استخدام TensorFlow Hub MobileNet للتنبؤات
في هذا الجزء من CoLab ، سوف نأخذ نموذجًا مُدرَّب مسبقًا ، ونقوم بتحميله إلى Keras واختباره.
النموذج الذي نستخدمه هو MobileNet v2 (بدلاً من MobileNet ، يمكن استخدام أي نموذج تصنيف صور متوافق مع tf2 مع tfhub.dev).
تحميل المصنف
قم بتنزيل نموذج MobileNet وإنشاء نموذج Keras منه. تتوقع MobileNet عند الإدخال تلقي صورة بحجم 224 × 216 بكسل مع 3 قنوات ملونة (RGB).
CLASSIFIER_URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" IMAGE_RES = 224 model = tf.keras.Sequential([ hub.KerasLayer(CLASSIFIER_URL, input_shape=(IMAGE_RES, IMAGE_RES, 3)) ])
قم بتشغيل المصنف على صورة واحدة
تم تدريب MobileNet على مجموعة بيانات ImageNet. ImageNet يحتوي على 1000 فئة الإخراج واحدة من هذه الفئات هو الزي العسكري. دعونا نجد الصورة التي سيتم وضع الزي العسكري عليها والتي لن تكون جزءًا من مجموعة أدوات تدريب ImageNet للتحقق من دقة التصنيف.
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize((IMAGE_RES, IMAGE_RES)) grace_hopper
الاستنتاج:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg 65536/61306 [================================] - 0s 0us/step

grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape
الاستنتاج:
(224, 224, 3)
ضع في اعتبارك أن النماذج تتلقى دائمًا مجموعة (كتلة) من الصور للمعالجة عند الإدخال. في الكود أدناه ، نضيف بعدًا جديدًا - حجم الكتلة.
result = model.predict(grace_hopper[np.newaxis, ...]) result.shape
الاستنتاج:
(1, 1001)
كانت نتيجة التنبؤ عبارة عن متجه بحجم 1001 عنصرًا ، حيث تمثل كل قيمة احتمال أن ينتمي الكائن في الصورة إلى فئة معينة.
يمكن العثور على موضع الحد الأقصى لقيمة الاحتمال باستخدام دالة argmax . ومع ذلك ، هناك سؤال ما زلنا لم نجيب عليه بعد - كيف يمكننا تحديد الفئة التي ينتمي إليها العنصر مع أقصى الاحتمالات؟
predicted_class = np.argmax(result[0], axis=-1) predicted_class
الاستنتاج:
653
فك رموز التوقعات
لكي نتمكن من تحديد الفئة التي تتعلق بها التوقعات ، نقوم بتحميل قائمة علامات ImageNet ومن خلال الفهرس بأقصى درجات الدقة ، نقوم بتحديد الفئة التي يرتبط بها التوقع.
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines()) plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
الاستنتاج:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt 16384/10484 [==============================================] - 0s 0us/step

البنغو! حدد نموذجنا الزي العسكري بشكل صحيح.
الجزء 2: استخدام نموذج TensorFlow Hub لمجموعة بيانات القط والكلب
الآن سوف نستخدم النسخة الكاملة من نموذج MobileNet ونرى كيف سيتعامل مع مجموعة بيانات القطط والكلاب.
مجموعة البيانات
يمكننا استخدام TensorFlow Datasets لتنزيل مجموعة بيانات القط والكلب.
splits = tfds.Split.ALL.subsplit(weighted=(80, 20)) splits, info = tfds.load('cats_vs_dogs', with_info=True, as_supervised=True, split = splits) (train_examples, validation_examples) = splits num_examples = info.splits['train'].num_examples num_classes = info.features['label'].num_classes
الاستنتاج:
Downloading and preparing dataset cats_vs_dogs (786.68 MiB) to /root/tensorflow_datasets/cats_vs_dogs/2.0.1... /usr/local/lib/python3.6/dist-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) WARNING:absl:1738 images were corrupted and were skipped Dataset cats_vs_dogs downloaded and prepared to /root/tensorflow_datasets/cats_vs_dogs/2.0.1. Subsequent calls will reuse this data.
ليست كل الصور في مجموعة بيانات القط والكلب بنفس الحجم.
for i, example_image in enumerate(train_examples.take(3)): print("Image {} shape: {}".format(i+1, example_image[0].shape))
الاستنتاج:
Image 1 shape: (500, 343, 3) Image 2 shape: (375, 500, 3) Image 3 shape: (375, 500, 3)
لذلك ، تتطلب الصور من مجموعة البيانات التي تم الحصول عليها تقليل الحجم إلى حجم واحد ، والذي يتوقعه طراز MobileNet عند الإدخال - 224 × 224.
وظيفة .repeat() و steps_per_epoch غير مطلوبة هنا ، لكنها تتيح لك توفير حوالي 15 ثانية لكل تكرار تدريب ، لأن يجب تهيئة المخزن المؤقت المؤقت مرة واحدة فقط في بداية عملية التعلم.
def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES)) / 255.0 return image, label BATCH_SIZE = 32 train_batches = train_examples.shuffle(num_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_examples.map(format_image).batch(BATCH_SIZE).prefetch(1)
قم بتشغيل المصنف على مجموعات الصور
اسمحوا لي أن أذكرك بأنه في هذه المرحلة ، لا تزال هناك نسخة كاملة من شبكة MobileNet المدربة مسبقًا ، والتي تحتوي على 1000 فئة مخرجات ممكنة. يحتوي ImageNet على عدد كبير من الصور للكلاب والقطط ، لذلك دعونا نحاول إدخال واحدة من صور الاختبار من مجموعة البيانات الخاصة بنا ومعرفة التنبؤ الذي سوف يقدمه لنا النموذج.
image_batch, label_batch = next(iter(train_batches.take(1))) image_batch = image_batch.numpy() label_batch = label_batch.numpy() result_batch = model.predict(image_batch) predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names
الاستنتاج:
array(['Persian cat', 'mink', 'Siamese cat', 'tabby', 'Bouvier des Flandres', 'dishwasher', 'Yorkshire terrier', 'tiger cat', 'tabby', 'Egyptian cat', 'Egyptian cat', 'tabby', 'dalmatian', 'Persian cat', 'Border collie', 'Newfoundland', 'tiger cat', 'Siamese cat', 'Persian cat', 'Egyptian cat', 'tabby', 'tiger cat', 'Labrador retriever', 'German shepherd', 'Eskimo dog', 'kelpie', 'mink', 'Norwegian elkhound', 'Labrador retriever', 'Egyptian cat', 'computer keyboard', 'boxer'], dtype='<U30')
التسميات تشبه أسماء سلالات القطط والكلاب. دعونا الآن نعرض بعض الصور من مجموعة بيانات القطط والكلاب لدينا ونضع ملصقًا متوقعًا على كل منها.
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")

الجزء 3: تنفيذ نقل التعلم مع TensorFlow Hub
الآن دعنا نستخدم TensorFlow Hub لنقل التعلم من نموذج إلى آخر.
في عملية نقل التدريب ، نعيد استخدام نموذج واحد مُدرَّب مسبقًا عن طريق تغيير آخر طبقة أو عدة طبقات ، ثم نبدأ عملية التدريب مرة أخرى على مجموعة بيانات جديدة.
في TensorFlow Hub ، لا يمكنك العثور على نماذج كاملة مُدرَّبة مسبقًا (مع الطبقة الأخيرة) فحسب ، بل يمكنك أيضًا العثور على نماذج دون طبقة التصنيف الأخيرة. هذا الأخير يمكن استخدامها بسهولة لنقل التدريب. سنستمر في استخدام MobileNet v2 لسبب بسيط هو أننا في الأجزاء التالية من الدورة التدريبية الخاصة بنا سنقوم بنقل هذا النموذج وإطلاقه على جهاز محمول باستخدام TensorFlow Lite.
سنستمر أيضًا في استخدام مجموعة بيانات القطط والكلاب ، وبالتالي سنكون لدينا الفرصة لمقارنة أداء هذا النموذج مع تلك التي قمنا بتنفيذها من البداية.
لاحظ أننا أطلقنا على النموذج الجزئي باستخدام TensorFlow Hub (بدون طبقة التصنيف الأخيرة) feature_extractor . يتم تفسير هذا الاسم من خلال حقيقة أن النموذج يقبل البيانات كمدخلات ويحولها إلى مجموعة محدودة من الخصائص المحددة (الخصائص). وهكذا ، قام نموذجنا بمهمة تحديد محتويات الصورة ، لكنه لم ينتج توزيع الاحتمال النهائي على فئات الإخراج. استخراج النموذج مجموعة من الخصائص من الصورة.
URL = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2' feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
لنقم بتشغيل مجموعة من الصور من خلال feature_extractor وإلقاء نظرة على النموذج الناتج (تنسيق الإخراج). 32 - عدد الصور ، 1280 - عدد الخلايا العصبية في الطبقة الأخيرة من النموذج المدرّب مسبقًا مع TensorFlow Hub.
feature_batch = feature_extractor(image_batch) print(feature_batch.shape)
الاستنتاج:
(32, 1280)
نقوم "بتجميد" المتغيرات في طبقة استخراج الخاصية حتى تتغير فقط قيم متغيرات طبقة التصنيف أثناء عملية التدريب.
feature_extractor.trainable = False
إضافة طبقة التصنيف
الآن قم بلف الطبقة من TensorFlow Hub في نموذج tf.keras.Sequential وأضف طبقة تصنيف.
model = tf.keras.Sequential([ feature_extractor, layers.Dense(2, activation='softmax') ]) model.summary()
الاستنتاج:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 2) 2562 ================================================================= Total params: 2,260,546 Trainable params: 2,562 Non-trainable params: 2,257,984 _________________________________________________________________
نموذج القطار
الآن نقوم بتدريب النموذج الناتج بالطريقة التي فعلناها قبل استدعاء compile يليه التدريب fit .
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
الاستنتاج:
Epoch 1/6 582/582 [==============================] - 77s 133ms/step - loss: 0.2381 - acc: 0.9346 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 582/582 [==============================] - 70s 120ms/step - loss: 0.1827 - acc: 0.9618 - val_loss: 0.1629 - val_acc: 0.9670 Epoch 3/6 582/582 [==============================] - 69s 119ms/step - loss: 0.1733 - acc: 0.9660 - val_loss: 0.1623 - val_acc: 0.9666 Epoch 4/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1677 - acc: 0.9676 - val_loss: 0.1627 - val_acc: 0.9677 Epoch 5/6 582/582 [==============================] - 68s 118ms/step - loss: 0.1636 - acc: 0.9689 - val_loss: 0.1634 - val_acc: 0.9675 Epoch 6/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1604 - acc: 0.9701 - val_loss: 0.1643 - val_acc: 0.9668
كما لاحظت على الأرجح ، تمكنا من تحقيق ~ 97 ٪ دقة التنبؤات على مجموعة بيانات التحقق من الصحة. رائع! لقد أدى النهج الحالي إلى زيادة دقة التصنيف بشكل كبير مقارنةً بالنموذج الأول الذي قمنا بتدريب أنفسنا عليه وحصلنا على دقة تصنيف تصل إلى 87٪ تقريبًا. والسبب هو أن MobileNet صممه خبراء وتم تطويره بعناية على مدار فترة زمنية طويلة ، ثم تدريبهم على مجموعة بيانات ImageNet كبيرة بشكل لا يصدق.
يمكنك معرفة كيفية إنشاء MobileNet الخاص بك في Keras على هذا الرابط .
لنقم ببناء رسوم بيانية للتغيرات في قيم الدقة والخسارة في مجموعات بيانات التدريب والتحقق.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.show()
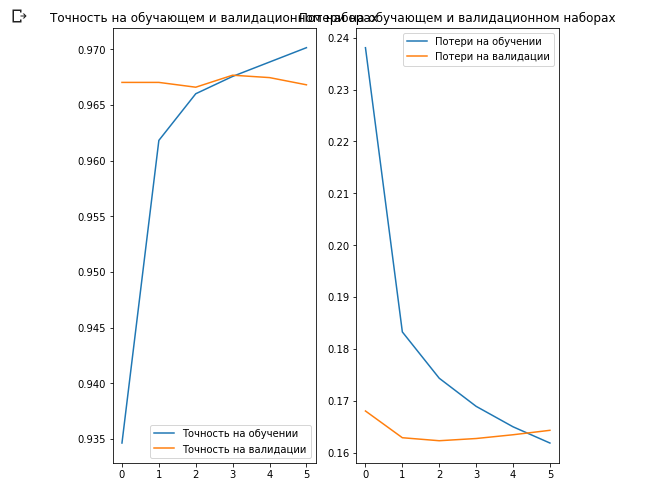
ما يثير الاهتمام هنا هو أن النتائج في مجموعة بيانات التحقق من الصحة أفضل من النتائج الموجودة في مجموعة بيانات التدريب من البداية إلى نهاية عملية التعلم.
أحد أسباب هذا السلوك هو أن الدقة في مجموعة بيانات التحقق من الصحة يتم قياسها في نهاية التكرار التدريبي ، كما أن الدقة في مجموعة بيانات التدريب تعتبر القيمة المتوسطة بين جميع التكرارات التدريبية.
السبب الأكبر لهذا السلوك هو استخدام شبكة MobileNet الفرعية المدربة مسبقًا ، والتي تم تدريبها مسبقًا على مجموعة كبيرة من البيانات من القطط والكلاب. في عملية التعلم ، تواصل شبكتنا توسيع مجموعة بيانات تدريب المدخلات (نفس التعزيز) ، ولكن ليس مجموعة التحقق من الصحة. هذا يعني أن الصور التي تم إنشاؤها على مجموعة بيانات التدريب أكثر صعوبة في التصنيف من الصور العادية من مجموعة البيانات التي تم التحقق منها.
تحقق نتائج التنبؤ
لتكرار الرسم البياني من القسم السابق ، تحتاج أولاً إلى الحصول على قائمة مرتبة بأسماء الفصول الدراسية:
class_names = np.array(info.features['label'].names) class_names
الاستنتاج:
array(['cat', 'dog'], dtype='<U3')
مرر الكتلة مع الصور من خلال النموذج وقم بتحويل الفهارس الناتجة إلى أسماء الفئات:
predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] predicted_class_names
الاستنتاج:
array(['cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog'], dtype='<U3')
دعنا نلقي نظرة على العلامات الحقيقية وتوقعنا:
print(": ", label_batch) print(": ", predicted_ids)
الاستنتاج:
: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1] : [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle(" (: , : )")

الغوص في الشبكات العصبية التلافيفية
باستخدام الشبكات العصبية التلافيفية ، تمكنا من التأكد من أنها تتعامل بشكل جيد مع مهمة تصنيف الصور. ومع ذلك ، في الوقت الحالي ، لا يمكننا أن نتخيل بالكاد كيف تعمل حقًا. إذا تمكنا من فهم كيفية حدوث عملية التعلم ، فيمكننا ، من حيث المبدأ ، تحسين عمل التصنيف بدرجة أكبر. تتمثل إحدى الطرق لفهم كيفية عمل الشبكات العصبية التلافيفية في تصور الطبقات ونتائج عملها. نوصي بشدة أن تدرس المواد هنا لفهم أفضل لكيفية تصور نتائج الطبقات التلافيفية.

شهد مجال رؤية الكمبيوتر الضوء في نهاية النفق وحقق تقدمًا كبيرًا منذ ظهور الشبكات العصبية التلافيفية. أعطت السرعة المذهلة التي يتم بها إجراء البحوث في هذا المجال والمصفوفات الضخمة من الصور المنشورة على الإنترنت نتائج مذهلة خلال السنوات القليلة الماضية. بدأ ظهور الشبكات العصبية التلافيفية مع AlexNet في عام 2012 ، والذي تم إنشاؤه بواسطة Alex Krizhevsky ، و Ilya Sutskever و Jeffrey Hinton ، وفاز بتحدي ImageNet على نطاق واسع للتمييز المرئي. منذ ذلك الحين ، لم يكن هناك شك في المستقبل المشرق باستخدام الشبكات العصبية التلافيفية ، ومجال رؤية الكمبيوتر ونتائج العمل فيه أكدت هذه الحقيقة فقط. بدءًا من التعرف على وجهك على الهاتف المحمول وانتهاءً بالاعتراف بالأشياء الموجودة في السيارات المستقلة ، تمكنت الشبكات العصبية التلافيفية بالفعل من إظهار وإثبات قوتها وحل العديد من المشكلات من العالم الواقعي.
على الرغم من العدد الهائل من مجموعات البيانات الضخمة والنماذج المدربة مسبقًا للشبكات العصبية التلافيفية ، يصعب أحيانًا فهم كيفية عمل الشبكة وما يتم تدريب هذه الشبكة بالضبط ، وخاصة للأشخاص الذين ليس لديهم معرفة كافية في مجال التعلم الآلي. , , , Inception, . . , , , , .
" Python"
François Chollet. , . Keras, , " " TensorFlow, MXNET Theano. , , . , .
, , .
(training accuracy) . , , , , Inception, .
, , . Inception v3 ( ImageNet) , Kaggle. Inception, , Inception v3 .
10 () 32 , 2292293. 0.3195, — 0.6377. ImageDataGenerator , . GitHub .
, "" , . .
, Inception v3 , .

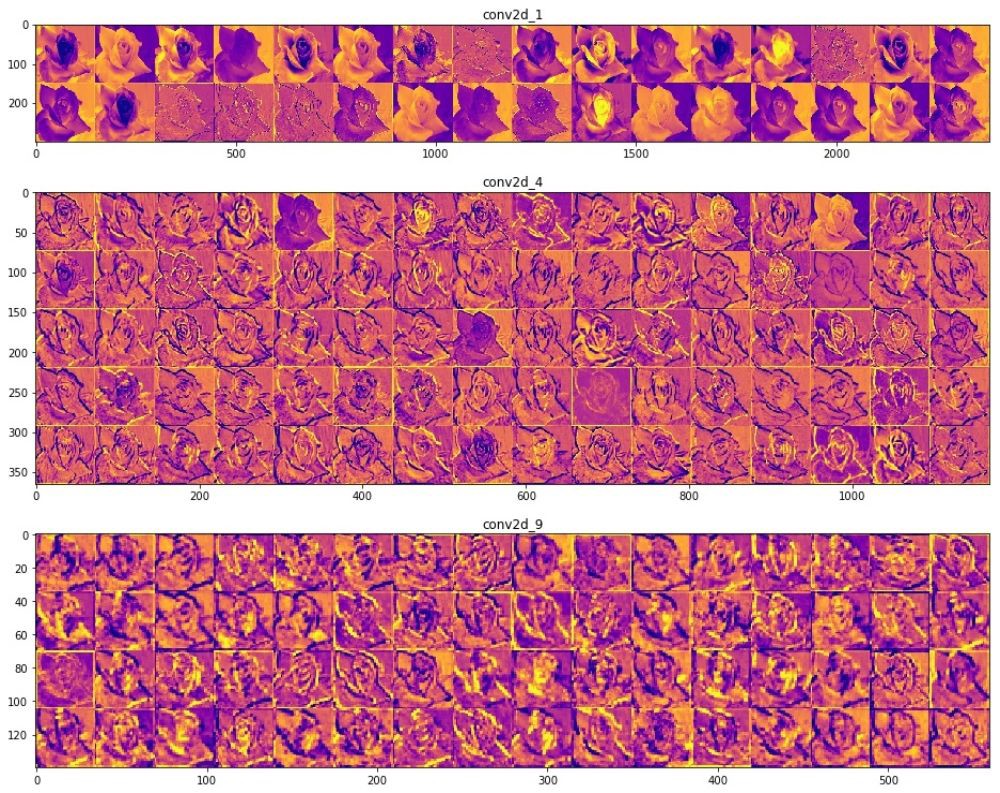
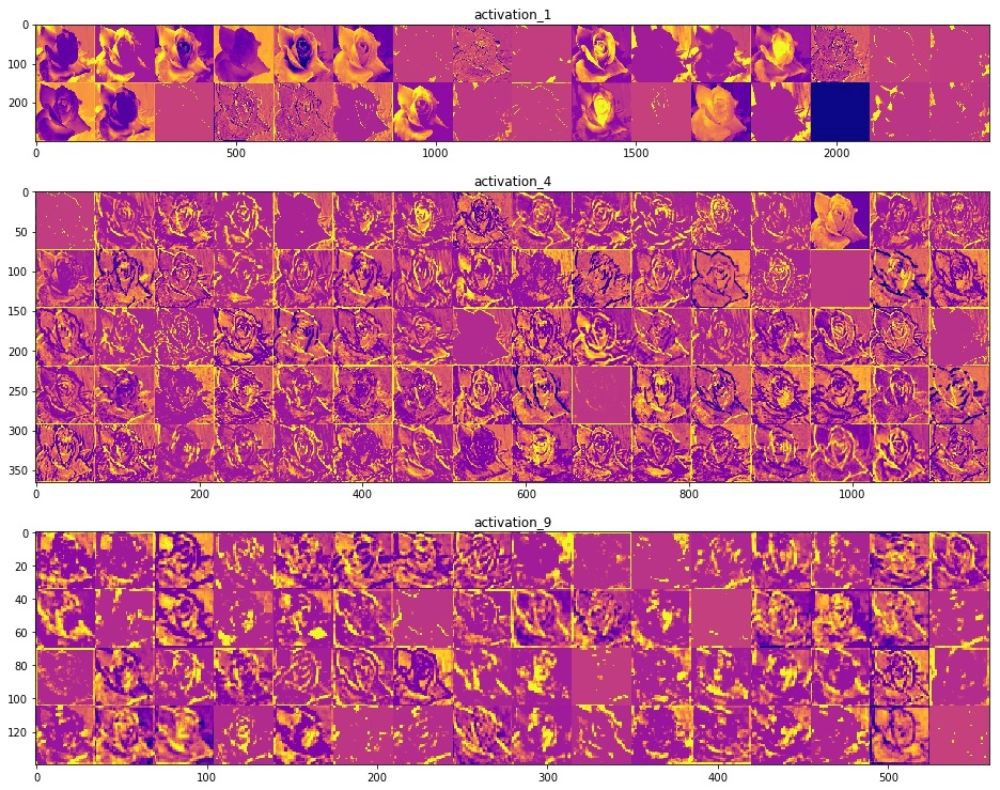
— . .
, () . (), , , , . , , , , .
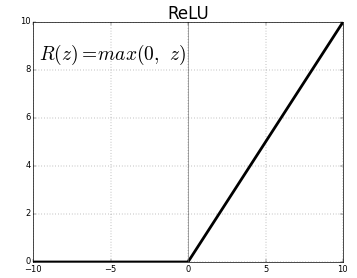
ReLU- . , ReLU(z) = max(0, z) .
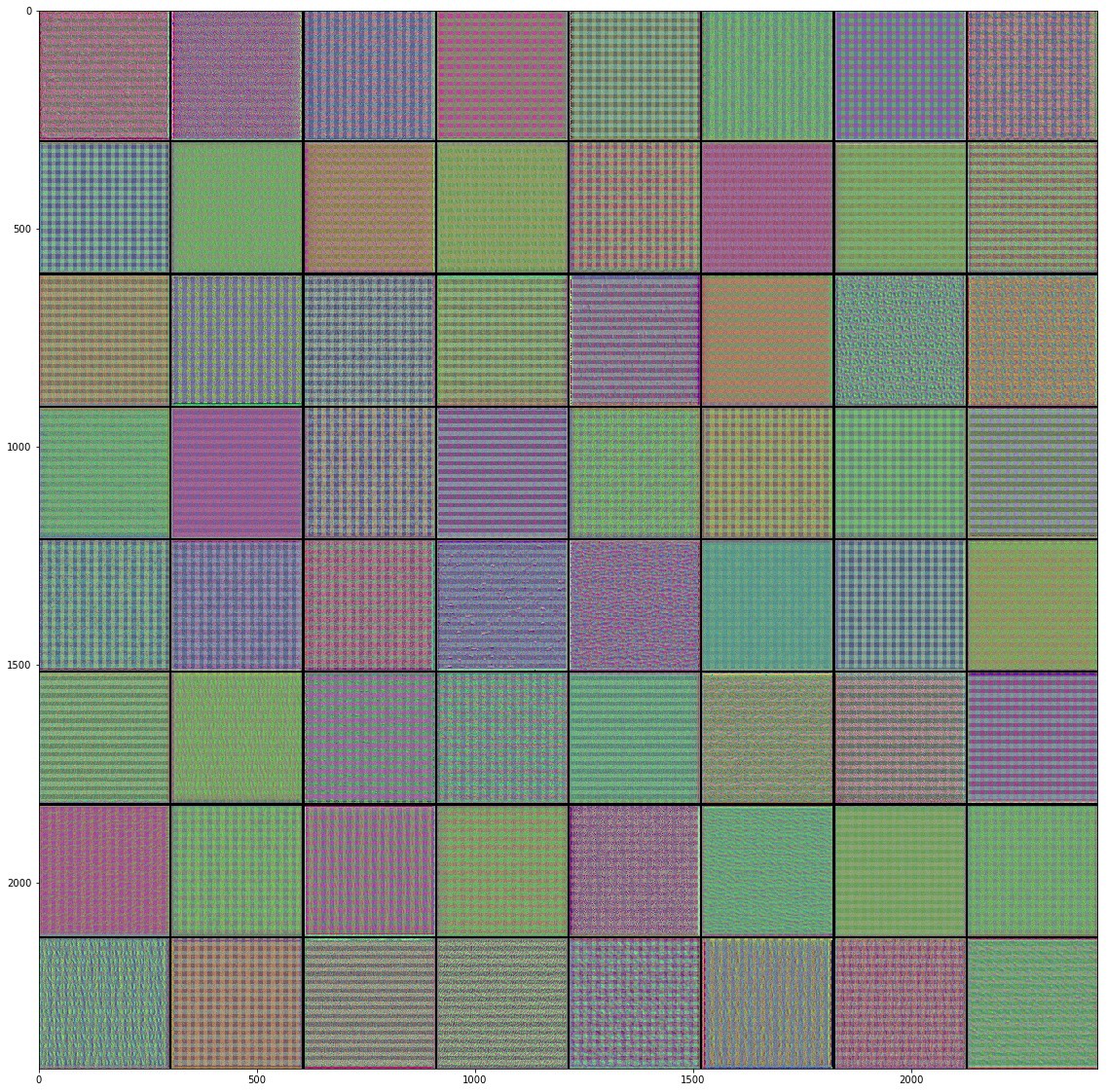
, , , , , , , , .. , . "" () , , , .
"" . .
, Inveption V3 :
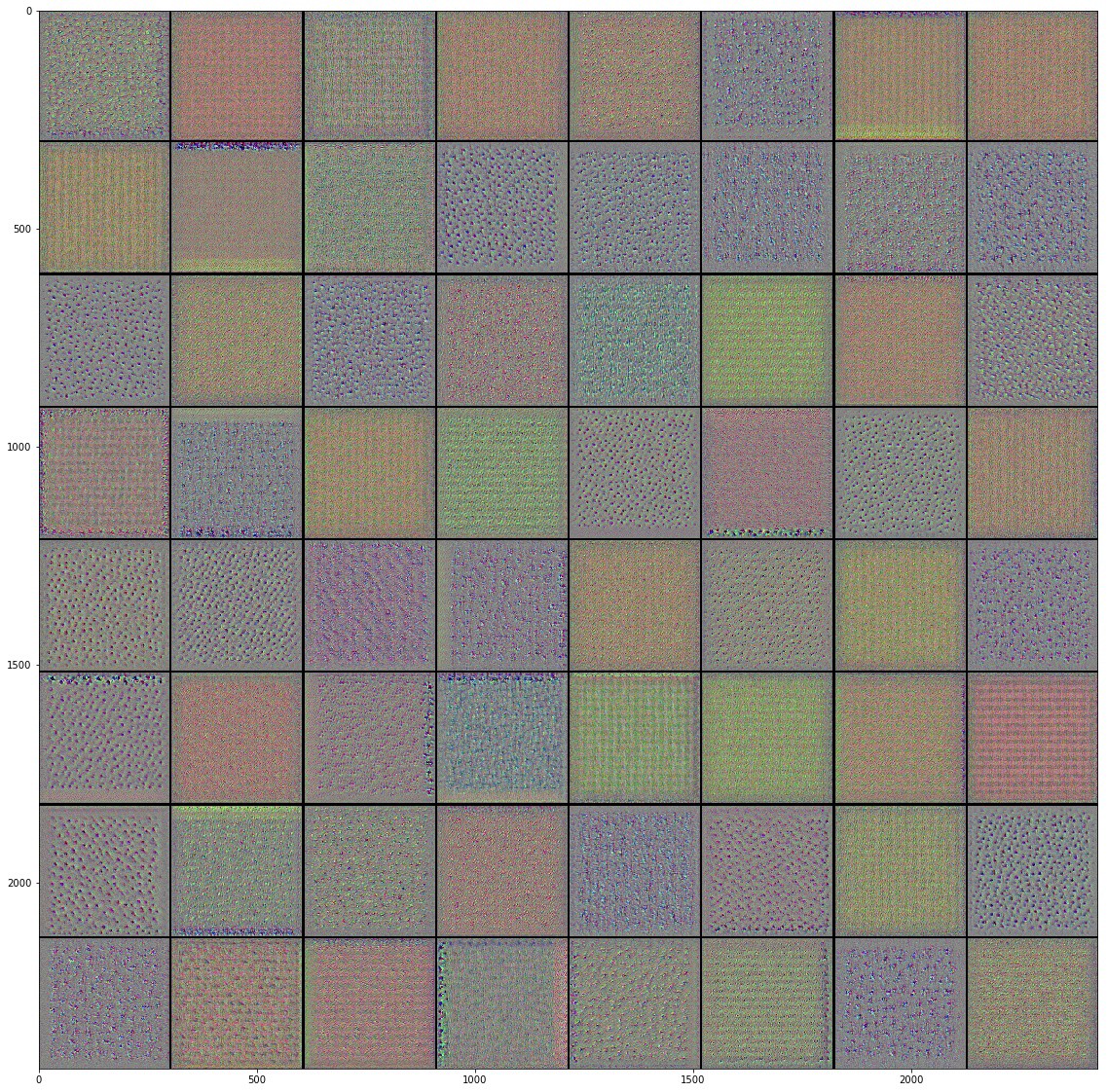

, . , , , , .. , , . , , , "" ( , ).
, , , . , .
Class Activation Map ( ). CAM . 2D , .
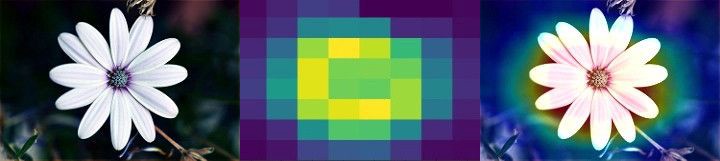

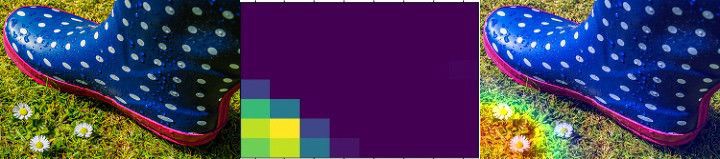
, . , , Mixed- Inception V3-, . () , .
, , . , , . , . , , , , .
, "" - . . .
, , .
:
Colab Colab .
TensorFlow Hub
TensorFlow Hub , .
. , , , .
.
Runtime -> Reset all runtimes...
, :
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import matplotlib.pyplot as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
:
WARNING:tensorflow: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons * https://github.com/tensorflow/io (for I/O related ops) If you depend on functionality not listed there, please file an issue.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
TensorFlow Datasets
TensorFlow Datasets. , — tf_flowers . , . tfds.splits (70%) (30%). tfds.load . tfds.load , , .
splits = tfds.Split.TRAIN.subsplit([70, 30]) (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)
:
Downloading and preparing dataset tf_flowers (218.21 MiB) to /root/tensorflow_datasets/tf_flowers/1.0.0... Dl Completed... 1/|/100% 1/1 [00:07<00:00, 3.67s/ url] Dl Size... 218/|/100% 218/218 [00:07<00:00, 30.69 MiB/s] Extraction completed... 1/|/100% 1/1 [00:07<00:00, 7.05s/ file] Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/1.0.0. Subsequent calls will reuse this data.
, , () , , — .
num_classes = dataset_info.features['label'].num_classes num_training_examples = 0 num_validation_examples = 0 for example in training_set: num_training_examples += 1 for example in validation_set: num_validation_examples += 1 print('Total Number of Classes: {}'.format(num_classes)) print('Total Number of Training Images: {}'.format(num_training_examples)) print('Total Number of Validation Images: {} \n'.format(num_validation_examples))
:
Total Number of Classes: 5 Total Number of Training Images: 2590 Total Number of Validation Images: 1080
— .
for i, example in enumerate(training_set.take(5)): print('Image {} shape: {} label: {}'.format(i+1, example[0].shape, example[1]))
:
Image 1 shape: (226, 240, 3) label: 0 Image 2 shape: (240, 145, 3) label: 2 Image 3 shape: (331, 500, 3) label: 2 Image 4 shape: (240, 320, 3) label: 0 Image 5 shape: (333, 500, 3) label: 1
— , MobilNet v2 — 224224 (grayscale). image () label () .
IMAGE_RES = 224 def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES))/255.0 return image, label BATCH_SIZE = 32 train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)
TensorFlow Hub
TensorFlow Hub . , , .
feature_extractor MobileNet v2. , TensorFlow Hub ( ) . . tf2-preview/mobilenet_v2/feature_vector , URL MobileNet v2 . feature_extractor hub.KerasLayer input_shape .
URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
, :
feature_extractor.trainable = False
, . . .
model = tf.keras.Sequential([ feature_extractor, layers.Dense(num_classes, activation='softmax') ]) model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 5) 6405 ================================================================= Total params: 2,264,389 Trainable params: 6,405 Non-trainable params: 2,257,984
, .
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 17s 216ms/step - loss: 0.7765 - acc: 0.7170 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 12s 147ms/step - loss: 0.3806 - acc: 0.8757 - val_loss: 0.3485 - val_acc: 0.8833 Epoch 3/6 81/81 [==============================] - 12s 146ms/step - loss: 0.3011 - acc: 0.9031 - val_loss: 0.3190 - val_acc: 0.8907 Epoch 4/6 81/81 [==============================] - 12s 147ms/step - loss: 0.2527 - acc: 0.9205 - val_loss: 0.3031 - val_acc: 0.8917 Epoch 5/6 81/81 [==============================] - 12s 148ms/step - loss: 0.2177 - acc: 0.9371 - val_loss: 0.2933 - val_acc: 0.8972 Epoch 6/6 81/81 [==============================] - 12s 146ms/step - loss: 0.1905 - acc: 0.9456 - val_loss: 0.2870 - val_acc: 0.9000
~90% 6 , ! , , ~76% 80 . , MobilNet v2 .
.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
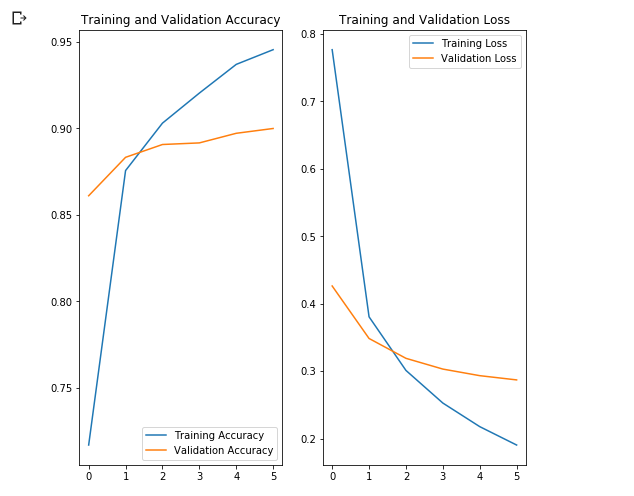
, , .
, , .
- MobileNet, . ( augmentation), . .
NumPy. , .
class_names = np.array(dataset_info.features['label'].names) print(class_names)
:
['dandelion' 'daisy' 'tulips' 'sunflowers' 'roses']
next() image_batch ( ) label_batch ( ). image_batch label_batch NumPy .numpy() . .predict() . np.argmax() . .
image_batch, label_batch = next(iter(train_batches)) image_batch = image_batch.numpy() label_batch = label_batch.numpy() predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] print(predicted_class_names)
:
['sunflowers' 'roses' 'tulips' 'tulips' 'daisy' 'dandelion' 'tulips' 'sunflowers' 'daisy' 'daisy' 'tulips' 'daisy' 'daisy' 'tulips' 'tulips' 'tulips' 'dandelion' 'dandelion' 'tulips' 'tulips' 'dandelion' 'roses' 'daisy' 'daisy' 'dandelion' 'roses' 'daisy' 'tulips' 'dandelion' 'dandelion' 'roses' 'dandelion']
print("Labels: ", label_batch) print("Predicted labels: ", predicted_ids)
:
Labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0] Predicted labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]
plt.figure(figsize=(10,9)) for n in range(30): plt.subplot(6,5,n+1) plt.subplots_adjust(hspace = 0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")

Inception-
TensorFlow Hub tf2-preview/inception_v3/feature_vector . Inception V3 . , Inception V3 . , Inception V3 299299 . Inception V3 MobileNet V2.
IMAGE_RES = 299 (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits) train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1) URL = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3), trainable=False) model_inception = tf.keras.Sequential([ feature_extractor, tf.keras.layers.Dense(num_classes, activation='softmax') ]) model_inception.summary()
:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 2048) 21802784 _________________________________________________________________ dense_1 (Dense) (None, 5) 10245 ================================================================= Total params: 21,813,029 Trainable params: 10,245 Non-trainable params: 21,802,784
model_inception.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model_inception.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 44s 541ms/step - loss: 0.7594 - acc: 0.7309 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3927 - acc: 0.8772 - val_loss: 0.3945 - val_acc: 0.8657 Epoch 3/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3074 - acc: 0.9120 - val_loss: 0.3586 - val_acc: 0.8769 Epoch 4/6 81/81 [==============================] - 35s 434ms/step - loss: 0.2588 - acc: 0.9282 - val_loss: 0.3385 - val_acc: 0.8796 Epoch 5/6 81/81 [==============================] - 35s 436ms/step - loss: 0.2252 - acc: 0.9375 - val_loss: 0.3256 - val_acc: 0.8824 Epoch 6/6 81/81 [==============================] - 35s 435ms/step - loss: 0.1996 - acc: 0.9440 - val_loss: 0.3164 - val_acc: 0.8861
النتائج
. :
- : , . .
- : . "" , , .
- MobileNet: Google, . MobileNet .
MobileNet . . MobileNet .
… call-to-action — , share :)
YouTube
برقية
فكونتاكتي
Ojok .