مرحبا بالجميع!
لقد تحدثت بالفعل في هذه المدونة عن تنظيم نظام مراقبة معياري لهندسة الخدمات الميكروية وعن الانتقال من الجرافيت + الهمس إلى الجرافيت + ClickHouse لتخزين المقاييس تحت الأحمال العالية. بعد ذلك ، كتب زميلي سيرغي نوسكوف عن الحلقة الأولى من نظام المراقبة لدينا - وهي Bioyino التي طورناها ، وهي أداة تجميع للقياسات قابلة للتوزيع.
حان الوقت لتحديث المعلومات المتعلقة بكيفية إعدادنا للمراقبة في Avito - آخر مقال لدينا كان بالفعل في عام 2018 ، وخلال هذه الفترة كانت هناك العديد من التغييرات المثيرة للاهتمام في بنية المراقبة وإدارة المشغلات والإشعارات وتحسينات البيانات المختلفة في ClickHouse وغيرها من الابتكارات ، الذي أريد فقط أن أخبرك عنه.

ولكن لنبدأ بالترتيب.
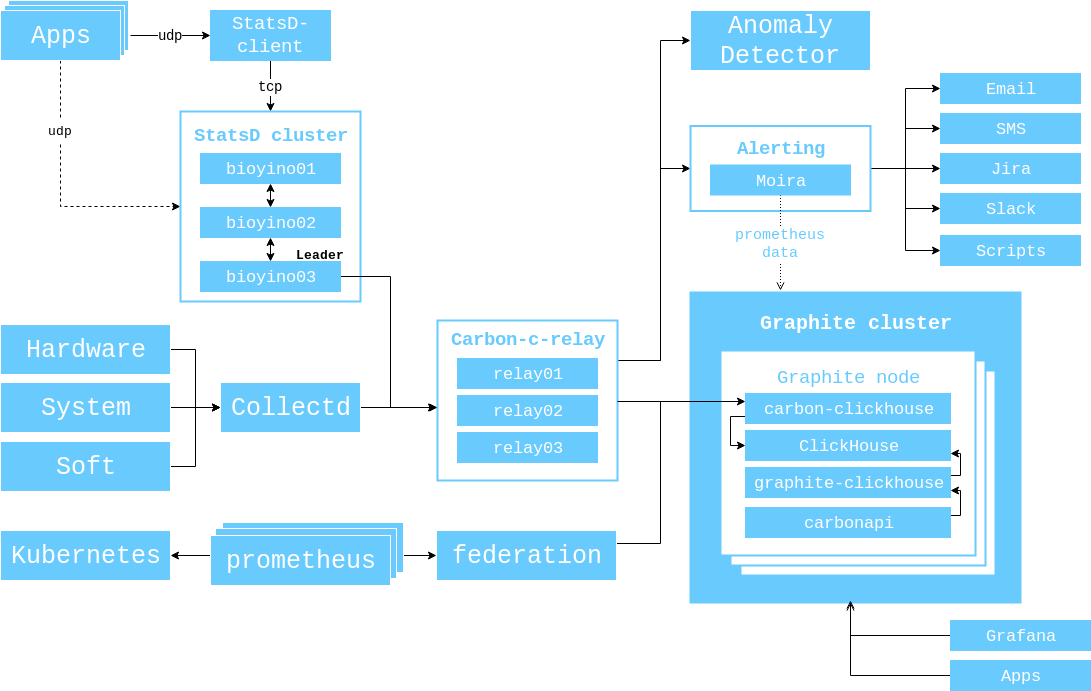
في عام 2017 ، عرضت مخططًا لتفاعل المكونات التي كانت ذات صلة في ذلك الوقت ، وأود أن أوضحها مرة أخرى حتى لا تضطر إلى تبديل علامات التبويب مرة أخرى.

من تلك اللحظة ، حدث ما يلي.
زاد عدد الخوادم في مجموعة الجرافيت من 3 إلى 6.
( 56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net ).
استبدلنا بروبيك بـ bioyino - تطبيقنا الخاص لـ StatsD بـ Rust ، وحتى كتبنا مقالة كاملة حول هذا الموضوع . ومع ذلك ، بعد نشر المقال ، طرحنا دعمًا للعلامات (الجرافيت) ورافت فيه لاختيار قائد.
لقد توصلنا إلى إمكانية استخدام bioyino كعامل StatsD ووضعنا هذه العوامل بجوار مثيلات متراصة ، وكذلك حيث كانت هناك حاجة إليها في k8s.
لقد تخلصنا أخيرًا من نظام مراقبة Munin القديم (رسميًا ، لا يزال لدينا ، لكن بياناته لم تعد مستخدمة).
تم تنظيم جمع البيانات من مجموعات Kubernetes من خلال Prometheus / Federations ، حيث لم يتم دعم Heapster في الإصدارات الجديدة من Kubernetes.
مراقبة
على مدار العامين الماضيين ، زاد عدد المقاييس المقبولة والمعالجة بحوالي 9 مرات.
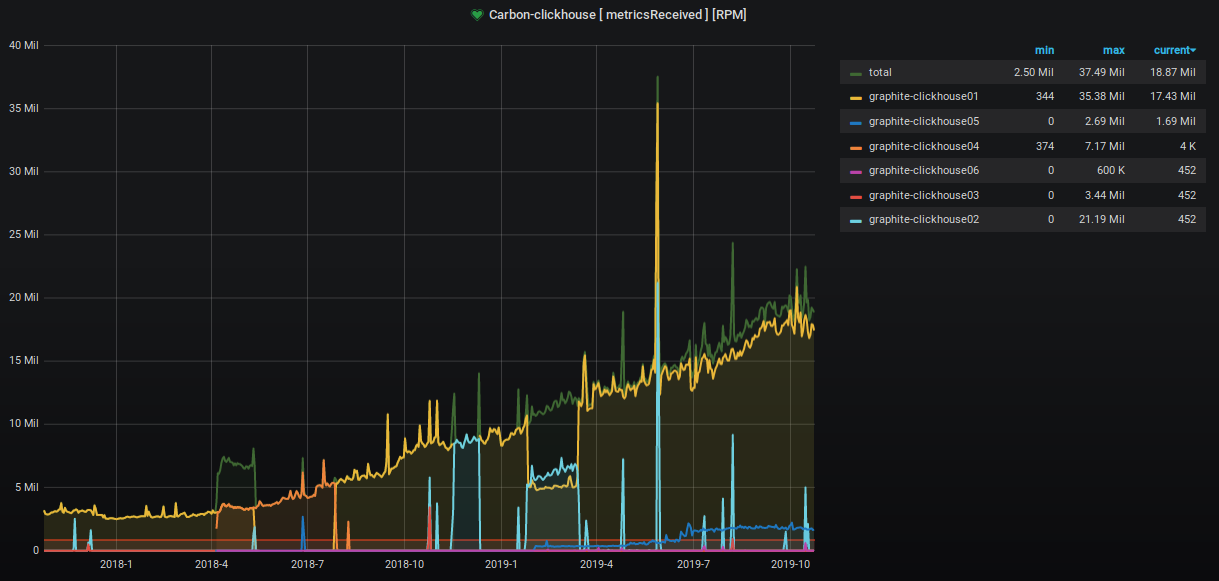
تزداد نسبة مساحة الخادم المشغولة أيضًا ، ونحن نتخذ خطوات مختلفة لخفضها. هذا واضح للعيان على الرسم البياني.
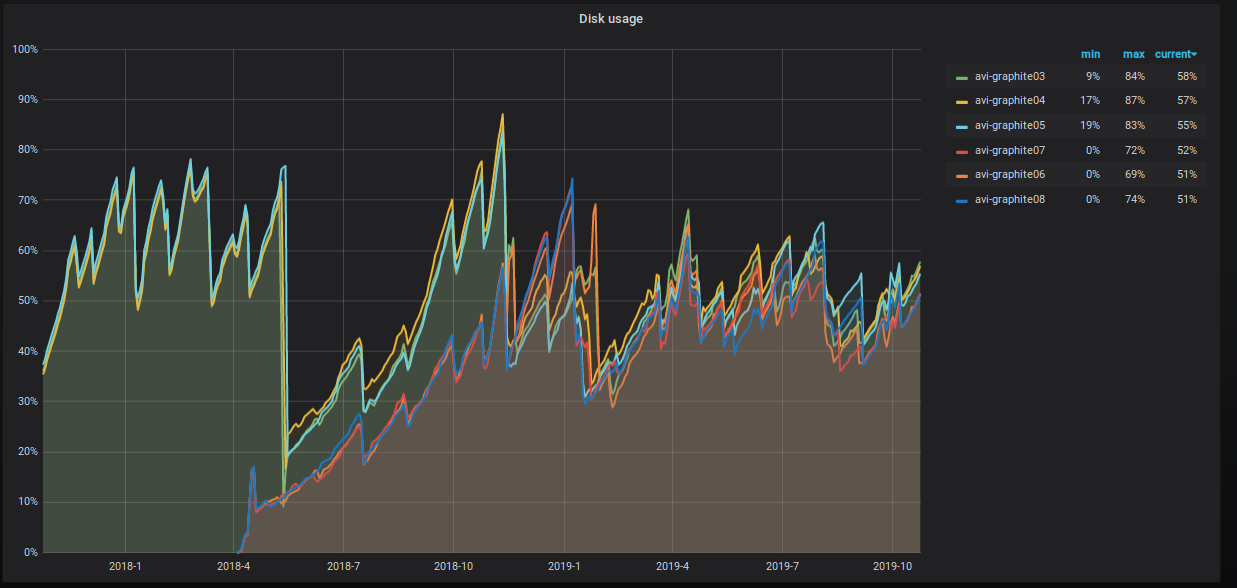
ماذا نفعل بالضبط؟
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
- شاركنا جداول البيانات. الآن لدينا ثلاثة شظايا مع نسختين متماثلتين لكل منهما مفتاح مشاركة التجزئة نيابة عن المقياس. يمنحنا هذا الأسلوب فرصة لتنفيذ إجراءات مجموعة التحديثات ، نظرًا لأن كل القيم الخاصة بمقياس معين موجودة في نفس الأداة ، ويتم استخدام مساحة القرص على جميع القطع بشكل موحد.
مخطط الجدول الموزع كما يلي.
CREATE TABLE graphite.data_all ( `Path` String, `Value` Float64, `Time` UInt32, `Date` Date, `Timestamp` UInt32 ) ENGINE = Distributed ( 'graphite_cluster', 'graphite', 'data', jumpConsistentHash(cityHash64(Path), 3) )
كما خصصنا حقوق المستخدم "الافتراضية" للقراءة فقط systemXXX تنفيذ إجراءات الكتابة على الجداول على نظام مستخدم منفصل systemXXX .
تكوين كتلة الجرافيت في ClickHouse كالتالي.
<remote_servers> <graphite_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse01</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse04</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse02</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse05</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse03</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse06</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> </graphite_cluster> </remote_servers>
بالإضافة إلى تحميل الكتابة ، زاد عدد طلبات قراءة البيانات من الجرافيت. تستخدم هذه البيانات من أجل:
- تجهيز الزناد وتنبيه الجيل ؛
- عرض الرسوم البيانية على الشاشات في المكتب وأجهزة الكمبيوتر المحمول وشاشات الكمبيوتر لعدد متزايد من موظفي الشركة.
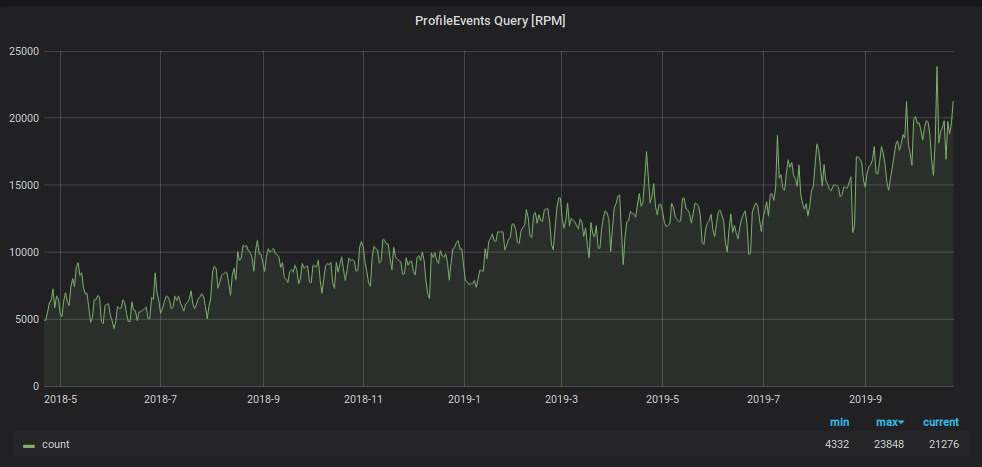
لمنع المراقبة من الغرق تحت هذا الحمل ، استخدمنا اختراقًا آخر: نقوم بتخزين البيانات لليومين الأخيرين في لوحة "صغيرة" منفصلة ، ونرسل جميع طلبات القراءة لليومين الأخيرين هناك ، مما يقلل من الحمل على طاولة القشرة الرئيسية. أيضًا بالنسبة لهذا الجهاز اللوحي "الصغير" ، استخدمنا نظام تخزين متري عكسي ، مما أدى إلى تسريع عملية البحث عن البيانات الموجودة فيه وتنظيم قسم يومي لها بشكل كبير. مخطط هذه اللوحة هو على النحو التالي.
CREATE TABLE graphite.data_reverse ( `Path` String, `Value` Float64, `Time` UInt32 CODEC(Delta(4), ZSTD(1)), `Date` Date, `Timestamp` UInt32 ) ENGINE = ReplicatedGraphiteMergeTree ( '/clickhouse/tables/{cluster}/data_reverse', '{replica}', 'graphite_rollup' ) PARTITION BY Date ORDER BY (Path, Time) SETTINGS index_granularity = 4096
لتوجيه البيانات إليها ، أضفنا قسمًا جديدًا إلى ملف تكوين تطبيق click-carbon .
[upload.graphite_reverse] type = "points-reverse" table = "graphite.data_reverse" threads = 2 url = "http://systemXXX:XXXXXXX@localhost:8123/" timeout = "60s" cache-ttl = "6h0m0s" zero-timestamp = true
لحذف الأقسام التي مضى عليها أكثر من يومين ، كتبنا مهمة cron. يبدو شيء من هذا القبيل.
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";done
لقراءة البيانات من الجدول ، في ملف تكوين الجرافيت - clickhouse ، تمت إضافة قسم:
[[data-table]] table = "graphite.data_reverse" max-age = "48h" reverse = true
نتيجةً لذلك ، لدينا جدول يحتوي على 100٪ من البيانات التي يتم نسخها نسخًا متماثلاً إلى الخوادم الستة جميعها التي تعالج عبء القراءة بالكامل من الطلبات التي تقل مدة عرضها عن يومين (ولدينا 95٪ منها). ولدينا أيضًا جدول مظلل يحتوي على 1/3 من البيانات الموجودة على كل قشرة ، والتي توفر قراءة جميع البيانات التاريخية. وحتى لو كانت هذه الطلبات أصغر بكثير ، فإن الحمل منها أعلى من ذلك بكثير.
ما يحدث مع وحدة المعالجة المركزية؟! كنتيجة للزيادة في حجم البيانات المسجلة والقراءة في مجموعة الجرافيت ، زاد إجمالي تحميل وحدة المعالجة المركزية على الخوادم أيضًا. يبدو شيء من هذا القبيل.
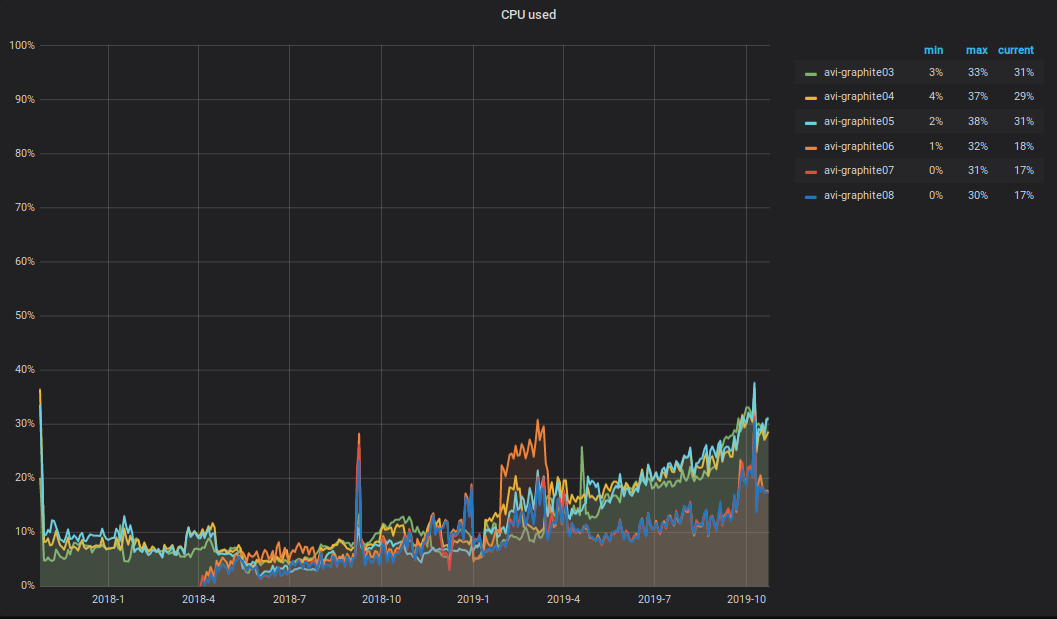
أود أن ألفت الانتباه إلى الفروق الدقيقة التالية: يذهب نصف وحدة المعالجة المركزية إلى التحليل والمعالجة الأولية للمقاييس في ترحيل الكربون (الإصدار 2.3 من 2018-09-05 ، وهو المسؤول عن نقل المقاييس) ، والذي يقع على ثلاثة من أصل ستة خوادم. كما ترون من الرسم البياني ، فهذه الخوادم الثلاثة الموجودة في الجزء العلوي.
تنبيه
كنظام تنبيه ، لا يزال لدينا Moira و moira-client مكتوبًا لذلك. من أجل الإدارة المرنة للمشغلات والإشعارات والتصعيدات ، نستخدم وصفًا تعريفيًا يسمى alert.yaml. يتم إنشاؤه تلقائيًا عندما يتم إنشاء خدمة عبر PaaS (يمكن العثور على المزيد حول هذا الموضوع في مقال Vadim Madison "ما نعرفه عن الخدمات المصغرة" ) ويتم وضعها في مستودعها. للعمل مع alert.yaml ، قطعنا ارتباطًا على moira-client و أطلقنا عليه alert-autoconf (نحن نخطط لفتح). هناك خطوة في تجميع الخدمة في TeamCity مع تصدير المشغلات والإشعارات إلى Moira عبر التنبيه التلقائي. عند تنفيذ التغييرات على alert.yaml ، يتم تشغيل اختبارات تلقائية تحقق من صحة ملف yaml ، كما تقدم طلبات إلى الجرافيت لكل قالب متري للتحقق من صحتها.
بالنسبة لفرق البنية التحتية التي لا تستخدم PaaS ، قمنا بتنظيم مستودع منفصل يسمى التنبيه. جعل هيكل النموذج: Team / Project / alert.yaml. بالنسبة لكل alert.yaml ، نقوم بإنشاء مجموعة منفصلة في TeamCity ، والتي تجري الاختبارات وتدفع محتويات alert.yaml في Moira.
وبالتالي ، يمكن لجميع موظفينا إدارة المشغلات والإخطارات والتصعيد باستخدام نهج واحد.
لأنه قبل أن يكون لدينا بالفعل مشغلات تم تشغيلها من خلال واجهة المستخدم الرسومية ، قمنا بتطبيق القدرة على تحميلها بتنسيق yaml. يمكن إدراج محتويات مستند yaml المستلم في alert.yaml بدون أي تحويلات إضافية عملياً ، ثم دفع التغييرات إلى المعالج. أثناء الإنشاء ، ستفهم التنبيه التلقائي أن مثل هذا المشغل موجود بالفعل وسيسجله في سجلنا في Redis.
ومنذ وقت ليس ببعيد ، حصلنا على واجب مناوبة المهندسين 24 × 7. من أجل نقل المشغلات إليهم للخدمة ، يكفي في التنبيه الخاص بك. يامل لملء وصف "ما يجب فعله إذا رأيت" بشكل صحيح ، ووضع العلامة [24 × 7] ودفع التغييرات إلى المعالج. بعد تنبيه alert.yaml ، ستقع جميع المشغلات الموضحة فيه تلقائيًا تحت مراقبة التحول على مدار 24 ساعة طوال اليوم وعلى مدار الأسبوع. يو - تبسيط! الجمال!
جمع مقاييس العمل
منذ آخر مقالة حول جمع ومعالجة مقاييس العمل ، أصبح لدينا bioyino أفضل.
- بدلاً من اختيار قائد من خلال القنصل ، يتم استخدام الطوافة المدمجة.
- تتم معالجة العلامات بشكل صحيح في شكل الجرافيت .
- الآن يمكنك استخدام bioyino (StatsD خادم) كعامل.
- لحساب القيم الفريدة ، يتم دعم تنسيق "set".
- يمكن إجراء التجميع النهائي للمقاييس في عدة سلاسل.
- يمكن إرسال البيانات إلى قطع الجرافيت في اتصالات متوازية متعددة.
- إصلاح جميع الخلل وجدت.
الآن يعمل مثل هذا.
بدأنا بنشاط في تقديم وكلاء StatsD بجانب جميع المولدات الكبيرة المترية الكبيرة: في الحاويات التي تحتوي على مثيلات متجانسة ، في حاضنات k8 بجوار الخدمات ، على المضيفين مع مكونات البنية التحتية ، إلخ.
يقع وكيل Statsd بجانب التطبيق. يستغرق الأمر مقاييس من هذا التطبيق متماثلة عبر UDP ، ولكن لم يعد يستخدم النظام الفرعي للشبكة (بسبب التحسينات في نواة Linux). يتم تجميع كل الأحداث مسبقًا ، ويتم إرسال البيانات التي يتم جمعها كل ثانية (يمكن تكوين الفاصل الزمني) إلى المجموعة الرئيسية لخوادم StatsD (bioyino0 [1-3]) بتنسيق Cap'n Proto.
ظلت المعالجة الإضافية وتجميع المقاييس واختيار قائد في مجموعة StatsD وإرسال القياسات من قبل الزعيم إلى الجرافيت دون تغيير عملي. يمكنك أن تقرأ عن هذا بالتفصيل في مقالتنا الأخيرة .
أما بالنسبة للأرقام ، فهي كما يلي.
الرسم البياني للأحداث StatsD الواردة
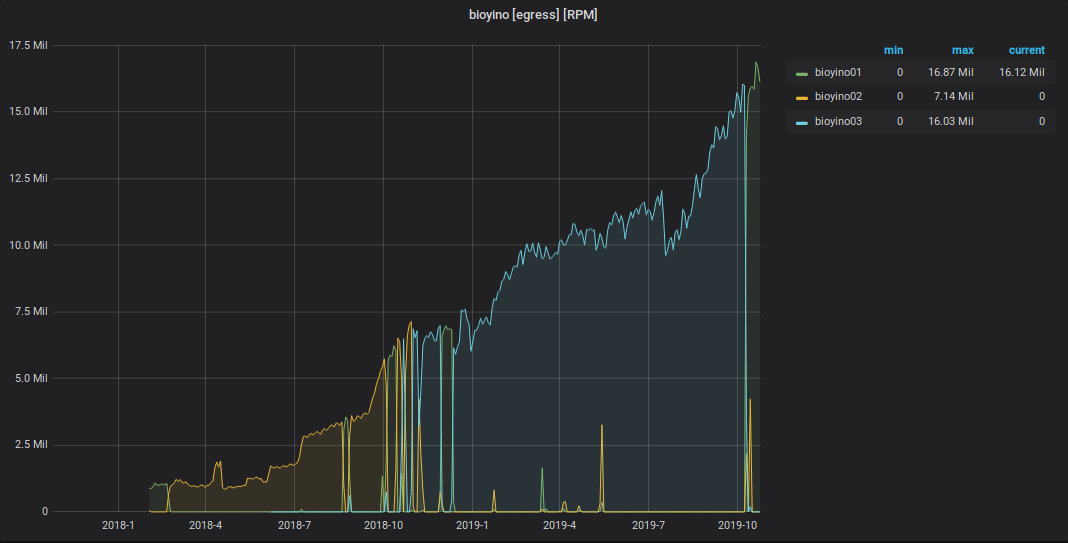

رسم بياني للمقاييس المرسلة من StatsD إلى الجرافيت
في المجموع
يبدو المخطط العام للتفاعل بين مكونات المراقبة في الوقت الحالي هكذا.
إجمالي عدد المقاييس: 2 189 484 898 474.
إجمالي عمق تخزين المقاييس: 3 سنوات.
عدد الأسماء المترية الفريدة: 6 585 413 171.
عدد المشغلات: 1053 ، تعمل من 1 إلى 15 كيلو متر.
خطط للمستقبل القريب:
- البدء في نقل خدمات المنتج إلى نظام تخزين متري موسوم ؛
- إضافة ثلاثة خوادم أخرى إلى مجموعة الجرافيت ؛
- تكوين صداقات مويرا مع الأنسجة الثابتة .
- ابحث عن مطور آخر في فريق المراقبة.
سأكون سعيدًا بالتعليقات والأسئلة هنا - الكتابة. وسأقوم أيضًا بالعرض على Highload ++ في 7 نوفمبر ، إذا كنت هناك ، فيمكننا التحدث.