مرحبا بالجميع! سأخبرك في هذا المنشور عن الطرق التي نستخدمها في Mail.ru Search لمقارنة النصوص. ما هذا؟ بمجرد أن نتعلم كيفية مقارنة النصوص المختلفة جيدًا مع بعضها البعض ، سيكون محرك البحث قادرًا على فهم طلبات المستخدم بشكل أفضل.
ماذا نحتاج لهذا؟ بادئ ذي بدء ، تعيين المهمة بدقة. يلزمك تحديد النصوص التي نعتبرها متشابهة والتي لا نعتبرها ، ثم صياغة استراتيجية لتحديد التشابه تلقائيًا. في حالتنا ، ستتم مقارنة نصوص استعلامات المستخدم بنصوص المستندات.
تتكون مهمة تحديد مدى ملاءمة النص من ثلاث مراحل. أولاً ، الأبسط: ابحث عن مطابقة الكلمات في نصين واستخلص استنتاجات حول التشابه بناءً على النتائج. المهمة التالية الأصعب هي البحث عن العلاقة بين الكلمات المختلفة وفهم المرادفات. وأخيراً ، المرحلة الثالثة: تحليل الجملة / النص بالكامل ، وعزل المعنى ومقارنة الجمل / النصوص بالمعاني.

طريقة واحدة لحل هذه المشكلة هي العثور على بعض التعيين من مساحة النص إلى بعض أبسط. على سبيل المثال ، يمكنك ترجمة النصوص إلى مساحة متجه ومقارنة المتجهات.
دعنا نعود إلى البداية وننظر في أبسط الطرق: العثور على مطابقة الكلمات في الاستعلامات والمستندات. مثل هذه المهمة في حد ذاتها معقدة بالفعل: للقيام بهذا بشكل جيد ، نحتاج إلى تعلم كيفية الحصول على الشكل العادي للكلمات ، وهو بحد ذاته غير تافه.
نموذج رسم الخرائط المباشر يمكن تحسينه بشكل كبير. حل واحد هو مطابقة المرادفات الشرطية. على سبيل المثال ، يمكنك إدخال افتراضات احتمالية حول توزيع الكلمات في النصوص. يمكنك العمل مع تمثيلات المتجهات وعزل الارتباطات ضمنيًا بين الكلمات غير متطابقة ، والقيام بذلك تلقائيًا.
نظرًا لأننا نشارك في البحث ، لدينا الكثير من البيانات حول سلوك المستخدمين عند تلقي مستندات معينة استجابةً لبعض الاستعلامات. بناءً على هذه البيانات ، يمكننا استخلاص استنتاجات حول العلاقة بين الكلمات المختلفة.
لنأخذ جملتين:

عيّن كل زوج من الكلمات من الاستعلام ومن العنوان بعض الوزن ، مما يعني مدى ارتباط الكلمة الأولى بالكلمة الثانية. سوف نتوقع أن تكون النقرة بمثابة تحول سيغمي لمجموع هذه الأوزان. بمعنى أننا حددنا مهمة الانحدار اللوجستي ، حيث يتم تمثيل السمات بمجموعة من أزواج النموذج (كلمة من الاستعلام ، كلمة من عنوان / نص المستند). إذا استطعنا تدريب مثل هذا النموذج ، فسوف نفهم الكلمات التي هي مرادفات ، وبشكل أكثر دقة ، يمكن أن تكون مرتبطة ، وأي منها على الأرجح لا تستطيع.
textbfClickprobability= sigma left( sum varphii right) textbf،حيث varphii textbf−وزنكلمتين(كلمةالاستعلام،كلمةالمستند)
الآن تحتاج إلى إنشاء مجموعة بيانات جيدة. اتضح أنه يكفي أخذ سجل نقرات المستخدمين ، وإضافة أمثلة سلبية. كيف تخلط في الأمثلة السلبية؟ من الأفضل إضافتها إلى مجموعة البيانات بنسبة 1: 1. علاوة على ذلك ، يمكن إجراء الأمثلة نفسها في المرحلة الأولى من التدريب بشكل عشوائي: بالنسبة لزوج وثيقة الاستعلام ، نجد وثيقة عشوائية أخرى ، ونحن نعتبر هذا الزوج سالبًا. في المراحل اللاحقة من التدريب ، من المفيد إعطاء أمثلة أكثر تعقيدًا: تلك التي لها التقاطعات ، وكذلك الأمثلة العشوائية التي يعتبرها النموذج مماثلة (التعدين السلبي الصعب).
مثال: مرادفات لكلمة "مثلث".
في هذه المرحلة ، يمكننا بالفعل التمييز بين الوظيفة الجيدة التي تتطابق مع الكلمات ، ولكن هذا ليس هو ما نسعى إليه ، فهذه الوظيفة تتيح لنا القيام بمطابقة غير مباشرة للكلمات ، ونريد مقارنة الجمل بأكملها.
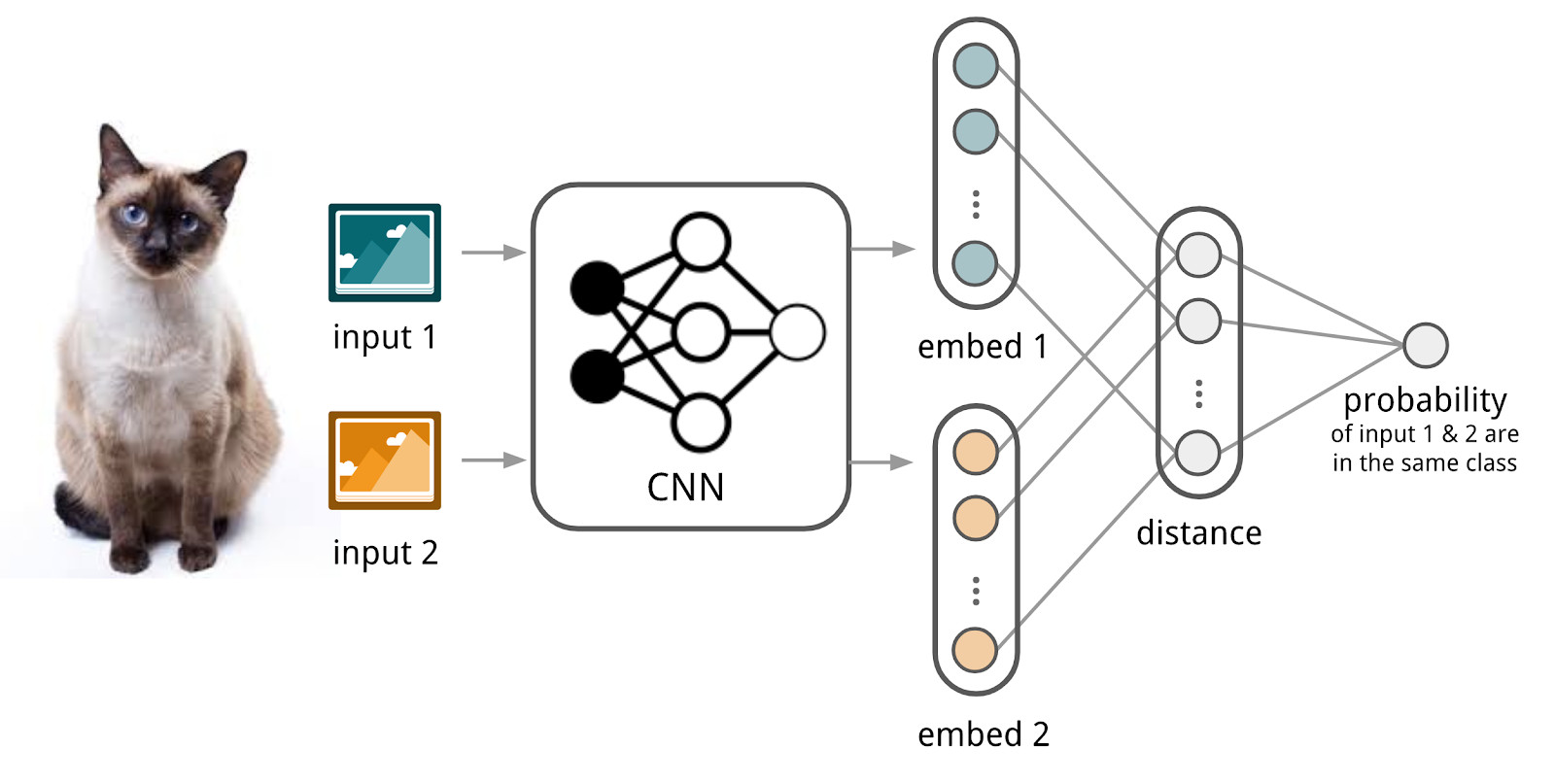
هنا الشبكات العصبية سوف تساعدنا. دعنا نجعل مشفرًا يقبل النص (طلب أو مستند) وينتج تمثيلًا متجهًا بحيث تحتوي النصوص المشابهة على متجهات قريبة وبعيدة. على سبيل المثال ، يمكنك استخدام مسافة جيب التمام كمقياس للتشابه.
هنا سنستخدم جهاز شبكات Siamese ، لأنها أسهل بكثير في التدريب. تتكون شبكة Siamese من جهاز تشفير يتم تطبيقه على عينات البيانات من عائلتين أو أكثر وعملية المقارنة (على سبيل المثال ، مسافة جيب التمام). عند تطبيق برنامج التشفير على عناصر من عائلات مختلفة ، يتم استخدام نفس الأوزان ؛ هذا في حد ذاته يعطي تنظيم جيد ويقلل إلى حد كبير عدد العوامل اللازمة للتدريب.
ينتج Encoder تمثيلات متجهة من النصوص ويتعلم بحيث يكون جيب التمام بين تمثيلات نصوص مماثلة هو الحد الأقصى ، وبين تمثيلات متباينة تكون ضئيلة.
شبكة من التعقيد الدلالي العميق DSSM مناسب لمهمتنا. نستخدمها مع تغييرات طفيفة ، والتي سأناقشها أدناه.
كيفية عمل DSSM الكلاسيكية: يتم تقديم الاستعلامات والمستندات في شكل حقيبة ثلاثية الأبعاد ، يتم الحصول منها على تمثيل متجه قياسي. يتم تمريره عبر عدة طبقات متصلة تمامًا ، ويتم تدريب الشبكة بطريقة تعظيم الاحتمال الشرطي للمستند عند الطلب ، وهو ما يعادل زيادة المسافة التمامية بين عروض المتجهات التي تم الحصول عليها عبر ممر كامل عبر الشبكة.
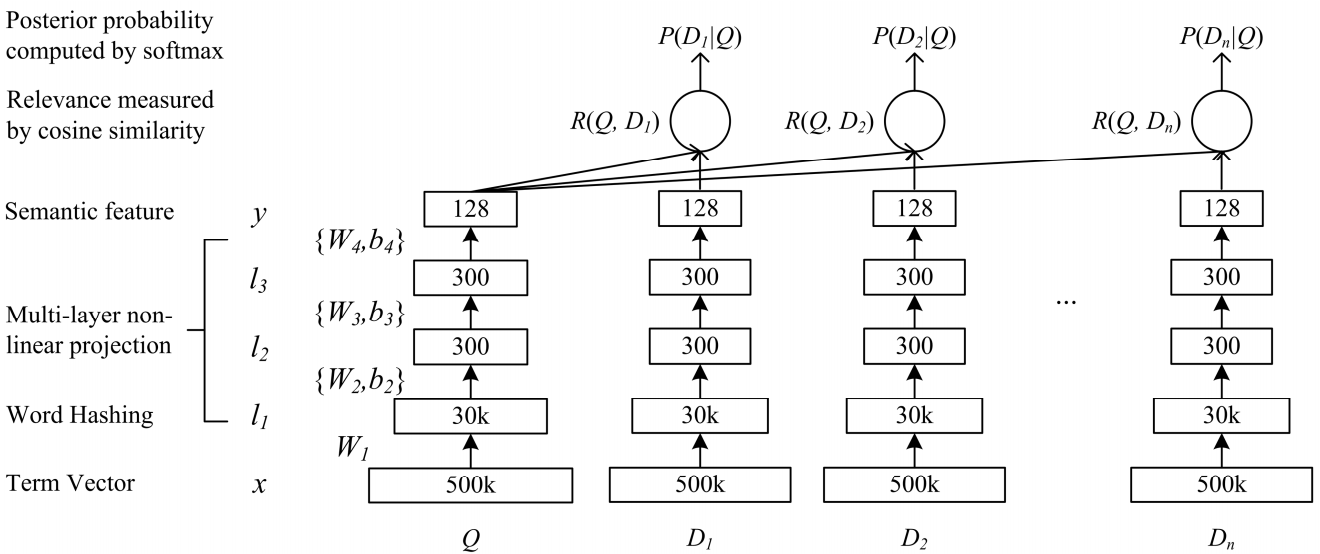 بو سين هوانغ شياو دونغ وجيان فنغ قاو لى دينغ اليكس اسيرو لاري هيك. 2013 تعلم النماذج الدلالية الهيكلية العميقة للبحث على الويب باستخدام بيانات النقر إلى الظهور
بو سين هوانغ شياو دونغ وجيان فنغ قاو لى دينغ اليكس اسيرو لاري هيك. 2013 تعلم النماذج الدلالية الهيكلية العميقة للبحث على الويب باستخدام بيانات النقر إلى الظهورذهبنا بنفس الطريقة تقريبًا. أي ، يتم تمثيل كل كلمة في الاستعلام كمتجه للثلاثي الأبعاد ، والنص كمتجه للكلمات ، وبالتالي يترك معلومات حول أي كلمة تقف. بعد ذلك ، نحن نستخدم مجموعة من الكلمات في أحادية البعد داخل الكلمات ، ونعمل على تجسيد تمثيلها ، وتشغيل الحد الأقصى للسحب الشامل لتجميع المعلومات حول الجملة في تمثيل متجه بسيط.

تتزامن مجموعة البيانات التي استخدمناها للتدريب بشكل شبه كامل في جوهرها مع المجموعة المستخدمة في النموذج الخطي.
نحن لم نتوقف عند هذا الحد. أولاً ، توصلوا إلى وضع ما قبل التدريب. نأخذ قائمة من طلبات البحث للمستند ، حيث ندخل المستخدمين الذين يتفاعلون مع هذا المستند ، ونقوم بتدريب الشبكة العصبية لتضمين مثل هذه الأزواج. نظرًا لأن هذه الأزواج تنتمي إلى نفس العائلة ، فمن السهل تعلم هذه الشبكة. بالإضافة إلى ذلك ، فمن الأسهل إعادة ضبطه على الأمثلة القتالية عندما نقارن الطلبات والمستندات.
مثال: يذهب المستخدمون إلى e.mail.ru/login مع الطلبات: البريد الإلكتروني وإدخال البريد الإلكتروني وعنوان البريد الإلكتروني ...وأخيراً ، فإن الجزء الصعب الأخير ، الذي ما زلنا نكافح فيه والذي حققنا فيه نجاحًا تقريبًا ، هو مهمة مقارنة الطلب ببعض المستندات الطويلة. لماذا هذه المهمة أكثر صعوبة؟ هنا ، أصبحت آلات شبكات Siamese مناسبة بالفعل ، لأن الطلب والمستند الطويل ينتميان إلى مجموعات مختلفة من الكائنات. ومع ذلك ، لا يمكننا تحمل تغيير الهيكل. من الضروري فقط إضافة التلفاز أيضًا بالكلمات ، مما سيوفر مزيدًا من المعلومات حول سياق كل كلمة لتمثيل المتجه النهائي للنص.
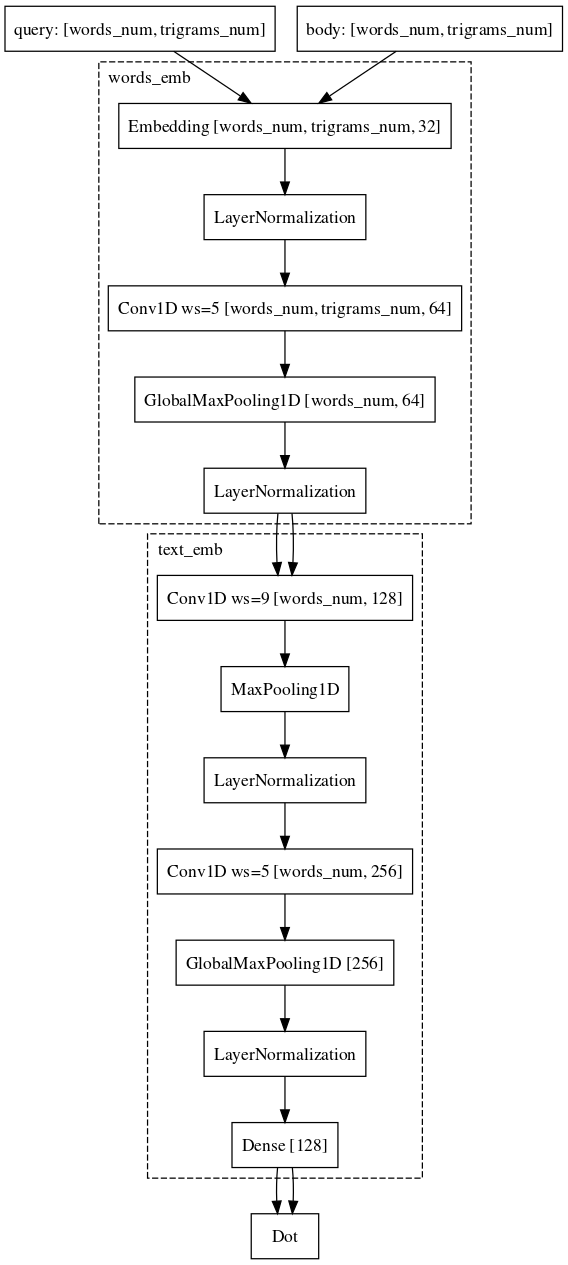
في الوقت الحالي ، نواصل تحسين جودة نماذجنا من خلال تعديل الهياكل وتجربة مصادر البيانات وآليات أخذ العينات.