محتوى
في بعض الأحيان تجد الحشرات نفسها. لذلك قمنا بدفع صف كبير من البيانات - وتم تعليق النظام. هل بسبب 1 مليون حرف سقطت؟ أم أنها لا تحب واحدة معينة؟
أو تم تحميل الملف إلى النظام وتحطمت. لماذا؟ بسبب الاسم ، التمديد ، البيانات داخل أو الأحجام؟ يمكنك دفع التعريب إلى المطور ، دعه يفكر بما هو سيء في الملف. ولكن في كثير من الأحيان يمكنك العثور على السبب بنفسك ، ثم وصف المشكلة بدقة أكبر.
إذا وجدت الحد الأدنى من البيانات المطلوب تشغيلها ، فقم بما يلي:
- ستوفر الوقت للمطور - لن يضطر إلى الاتصال بحامل الاختبار ، وتحميل الملف بنفسه وأول مرة
- سيكون المدير قادراً على تقييم أولوية المهمة بسهولة - هل هناك حاجة ماسة لإصلاحها ، أو هل يمكن أن تنتظر الأخطاء؟ بينما يكون اسم "بعض الملفات يسقط ، لماذا xs" يصعب القيام به ...
- وصف الخطأ من فهم سبب سقوط سوف تستفيد أيضا.
كيفية العثور على الحد الأدنى من البيانات للعب علة؟ إذا كان هناك أي تلميحات في السجلات ، فقم بتطبيقها. إذا لم تكن هناك أدلة ، فإن أفضل طريقة هي طريقة التقسيم الثنائي (تعرف أيضًا باسم طريقة "bisection" أو "dichotomy").
وصف الطريقة
يتم استخدام الطريقة للعثور على المكان الدقيق للسقوط:
- خذ حزمة من البيانات السقوط.
- كسر في النصف.
- تحقق نصف 1
- إذا سقطت ، فالمشكلة موجودة. نحن نعمل معها أكثر.
- إذا لم تسقط → تحقق من النصف 2.
- كرر الخطوات من 1-3 حتى تظل قيمة السقوط واحدة.

تسمح لك الطريقة بتحديد مكان المشكلة بسرعة ، خاصةً إذا تم تنفيذها برمجيًا. يقوم المطورون بدمج هذه الآليات في معالجة البيانات. وإذا لم يبنوا ذلك ، فإنهم يعانون في وقت لاحق ، عندما يأتي الاختبار إليهم ويقولون: "إنه يقع على هذا الملف ، لكنني لم أستطع العثور على السبب الدقيق".
تطبيق من قبل اختبار
صف البيانات
تحميل خط من 1 مليون البيانات - يتجمد النظام.
نحاول 500 ألف (مقسم إلى نصفين) - لا يزال معلقًا.
نحاول 250 ألف - لا يتعطل ، كل شيء على ما يرام.
↓
ومن هنا استنتجنا أن المشكلة تتراوح بين 250 و 500 ألف مرة أخرى.
نحن نجرب 350 ألفًا (تقسيمها "بالعين" - إنه مسموح به تمامًا ، فلا يجب عليك الركض إلى أرقام دقيقة عند التشغيل يدويًا) - كل شيء على ما يرام
نحن نحاول 450 ألف - إنه أمر سيء.
نحن نحاول 400 ألف - إنه أمر سيء.
↓
بشكل عام ، يمكنك بالفعل الحصول على خطأ. نادراً ما يطلب من المختبر الإبلاغ عن أن الحدود أو الأخطاء بشكل واضح في الرقم 286 586. يكفي توطينها تقريبًا - 290 ألفًا.
إنه أمر واحد فقط للتحقق من "10" وعلى الفور "300 ألف" ، ويختلف تمامًا عن تقديم المزيد من المعلومات الكاملة: "ما يصل إلى 10 آلاف كل شيء على ما يرام ، من 10 إلى 280 ألف الفرامل تبدأ ، إنه بالفعل يصل إلى 290 ألف".
من الواضح أنه عندما يتم قياس الكمية بالآلاف ، سيستغرق البحث عن وجه معين وقتًا طويلاً جدًا. نعم ، المطور لا يحتاج إلى هذا. حسنًا ، لا أحد يريد تضييع الوقت دون جدوى.
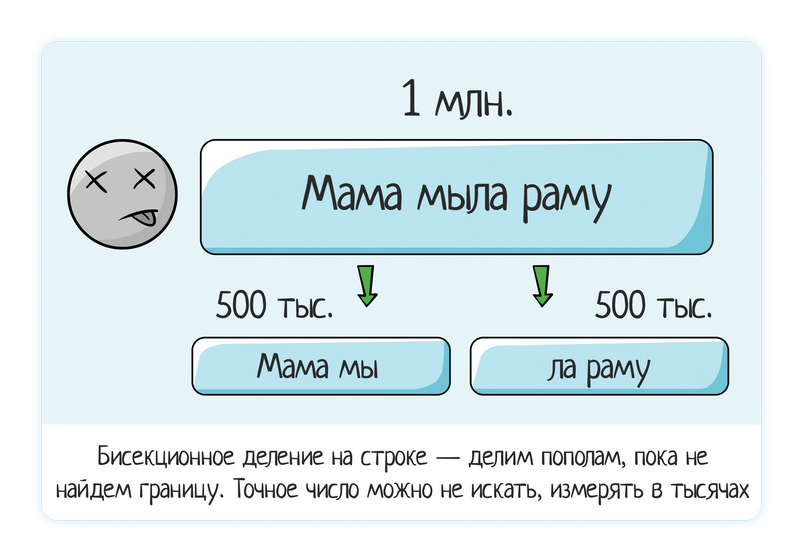
بالطبع ، إذا كانت المشكلة الأصلية على خط بطول يتراوح من 10 إلى 30 حرفًا ، يمكنك العثور على الحد الدقيق. كل شيء في علاقة معقولة بالوقت - إذا كنت تستخدم التخمين أو التقسيم المزدوج ، فيمكنك العثور بسرعة على القيمة الدقيقة وهي صغيرة (حتى 100 عادةً) - نحن نبحث بالتأكيد. إذا كانت المشكلات في خط كبير ، فابحث عن أكثر من 1000 → تقريبًا.
ملف
تم رفع ملف - تحطمت! كيف ولماذا أولاً ، نحاول أن نحلل بأنفسنا ما الذي يمكن أن يؤثر على اختبارنا؟ هذه هي القاعدة الرئيسية "الإيجابية الأولى ، ثم السلبية". إذا كنت لا تحاول وضع كل شيء في اختبار واحد في وقت واحد:
- فحص ملف عينة صغيرة
- لقد فحصنا ملفًا ضخمًا بسعة 2 غيغابايت ، مع مجموعة من الأعمدة ، ومجموعة من الأعمدة ، بالإضافة إلى أشكال مختلفة من البيانات الداخلية
سيكون من الصعب التوطين هنا. وإذا قمت بفصل الشيكات:
- الكثير من الخطوط (لكن البيانات إيجابية ويتم التحقق منها سابقًا)
- العديد من الأعمدة
- الوزن الثقيل
- ...
هذا بالفعل مفهوم تقريبا ، ما هو السبب. على سبيل المثال ، يقع على عدد كبير من الخطوط - من 100 ألف. حسنًا ، نحن نبحث عن حدود أكثر دقة باستخدام التقسيم الثنائي:
- قمنا بتقسيم الملف إلى قسمين بمقدار 50 ألفًا ، وتم فحص الملف الأول.
- إذا وقعت ، قسّمها
- وهكذا ، حتى نجد مكانًا محددًا للسقوط
إذا كان الهبوط يعتمد على عدد الخطوط ، فنحن نبحث عن حد تقريبي: "بعد سقوط 5000 ، لا يوجد 4000 ألف". البحث عن مكان محدد (4589) ليس ضروريًا. طويل جدًا ولا يستحق الوقت.
تم العثور على هذا الخطأ من قبل الطلاب في دادات . يمكن تحميل ملفات البيانات هناك ، سيقوم النظام بمعالجة هذه البيانات وتوحيدها: الأخطاء المطبعية الصحيحة وتحديد المعلومات المفقودة من الأدلة (كود KLADR ، FIAS ، الإحداثيات الجغرافية ، حي المدينة ، الرمز البريدي ...).
حاولت الفتاة تنزيل ملف كبير وحصلت على النتيجة: يعرض النظام شريط تقدم بنسبة تحميل 100٪ وتوقف لمدة تزيد عن 30 دقيقة.
ذهب التعريب إلى أبعد من ذلك - متى يبدأ التجميد؟ هذا مهم لأنه يؤثر على أولوية المهمة. ما هو حجم التحميل النموذجي؟ كم مرة يقوم المستخدمون بشحن LOTS مباشرة؟
ربما تم تصميم النظام لمعالجة الآلاف من الخطوط ، ثم يتم تكديس هذا الخطأ في "إصلاح المشكلة يومًا ما". أو التنزيلات المعتادة - من 10 إلى 50 ألف سطر تتم معالجتها بشكل طبيعي ، وهذا يعني أن الخطأ لا يتم حرقه ، وسوف نقوم بإصلاحه لاحقًا.
توطين المهام:
- لملف يحتوي على 50 ألف سطر ، يتعطل 15 ثانية ،
- للحصول على ملف به 100 ألف سطر ، يتعطل 30 ثانية ،
- للحصول على ملف مع 150 ألف خطوط ، 1 دقيقة معلقة ،
- لملف مع 165 ألف خطوط معلقة 4 دقائق ،
- بالنسبة لملف 172 ألف سطر يتجمد شريط التقدم الكامل بنسبة 100٪ لأكثر من نصف ساعة
هذا هو المكان الذي يتم فيه عمل المختبر بالفعل من الناحية النوعية. يتم توفير معلومات كاملة حول تشغيل النظام ، على أساسها يمكن للمدير بالفعل أن يستنتج مدى الضرورة الملحة لإصلاح الخلل.
لا يستغرق التحقق الكثير من الوقت أيضًا. يمكنك الانتقال أو من النهاية - لقد قمنا بتنزيل 200 ألف خط ، ومتى تبدأ المشكلة؟ نحن نستخدم طريقة تقسيم bisectional!
أو ابدأ برقم صغير نسبيًا - 50 ألفًا ، يزداد تدريجيًا (بمقدار النصف ، طريقة الانقسام الثنائي ، العكس تمامًا). مع العلم أن كل شيء سيكون سيئًا عند 200 ألف ، نحن نفهم أنه لن يكون هناك العديد من الاختبارات. فحصنا 50 ، 100 ، 150 - لمدة ثلاثة اختبارات وجدنا حدودًا تقريبية. ثم الحفر لم يعد ضروريا.
لكن تذكر أنك تحتاج أيضًا إلى اختبار نظريتك. هل صحيح أن المشكلة تكمن في عدد الأسطر وليس البيانات الموجودة داخل الملف؟ يعد التحقق من ذلك أمرًا سهلاً للغاية - قم بإنشاء ملف 5000 سطر ذو قيمة "إيجابية" واحدة. تلك القيمة التي تعمل بالضبط والتي قمت بالفعل التحقق في وقت سابق. إذا لم يكن هناك سقوط ، فالمسألة نجسة =)) يبدو أن نظرية عدد الصفوف كانت خاطئة وأن الأمر موجود في البيانات نفسها.
على الرغم من أنه يمكنك تجربة 10 آلاف سطر ذات قيمة موجبة تمامًا. من الممكن أن يحدث السقوط مرة أخرى. فقط ملف المصدر الخاص بك كان على عدة أعمدة. أو كانت هناك أحرف بداخلها استغرقت أكثر من بايت قيمة موجبة ... بشكل عام ، لا ترفض على الفور نظرية حجم الملف أو عدد الأسطر. حاول تقسيم الانقسام على العكس - مضاعفة الملف.
ولكن ، على أي حال ، تذكر أنه كلما تم خلط الشيكات بشكل أكثر ، كلما زاد صعوبة توطين هذا الخطأ. لذلك ، من الأفضل اختبار عدد الصفوف أو الأعمدة فورًا على قيمة موجبة واحدة. بحيث تكون متأكدًا من أنك تختبر كمية البيانات ، وليس البيانات نفسها. تحليل الاختبار وكل ذلك =)
ولكن ماذا لو لم تكن المشكلة في عدد الصفوف ، ولكن في البيانات نفسها؟ وأنت لا تعرف أين بالضبط. ربما قمت بتعبئة بيانات من "الحرب والسلام" إلى ملف اختبار ، أو قمت بتنزيل جدول بيانات كبير من مكان ما على الإنترنت ... أو وجد المستخدم مشكلة على الإطلاق - لقد حمّل ملفه وسقط كل شيء. لقد جاء لدعم ، وجاء لك الدعم: الملف موجود عليك ، قم بتشغيله.
مزيد من العمل يعتمد على الوضع. إذا كانت المواعيد النهائية للمستخدم قيد التشغيل أو تم خصم المال منه ، ثم انخفضت معالجة الملف ، فهذا خطأ من مانع. وليس هناك وقت لتدريب اختبار التوطين. من الأسهل إعطاء الملف الدقيق للمطور ، والسماح له بالحرية وإيجاد السبب نفسه.
لكن إذا وجدت نفسك خطأً ، فهذا هو الوقت المناسب لحفره بنفسك. مرة أخرى ، لا ننسى الحس السليم ، كما هو الحال دائما مع الترجمة. في البداية حاولنا استخلاص النتائج بأنفسنا ، ثم طلبنا المساعدة. لتقديم استنتاج نفسك ، تحتاج إلى:
- التحقق من السجلات ، قد يكون هناك الجواب الصحيح ؛
- عرض محتويات الملف: شيء ما قد يلفت انتباهك ، هذه هي النظرية الأولى ؛
- استخدام طريقة تقسيم bisectional.
نتيجة لذلك ، بدلاً من "ملف السقوط ، xs لماذا ، إليك ملف مرفق بحجم 2 غيغابايت" ، يمكنك وضع خطأ مدروس جيدًا ومترجم: "يسقط الملف إذا كان التاريخ هو تاريخ تنسيق DD / MM / YYYYY". ثم لا تحتاج بالفعل إلى ملف 2GB ، فأنت تحتاج فقط إلى ملف واحد لسطر واحد وعمود واحد!

تطبيق من قبل المطورين
في كمية كبيرة من البيانات ، لا يبحث المختبر عن حدود واضحة ، لأنه من غير المعقول القيام بذلك يدويًا. لكن المطورين يستخدمون طريقة التقسيم الثنائي في الكود ويمكنهم دائمًا إيجاد مكان محدد للسقوط. بعد كل شيء ، سوف ينقسم النظام إلى النصر ، وليس الشخص!
على سبيل المثال ، لدينا آلية لتحميل البيانات في النظام. ويمكن تحميل ما يصل إلى 10 ألف ومليون. ولكن هذا لا يهم ، لأن التنزيل في مجموعات من 200 إدخال. إذا حدث خطأ ما ، فإن النظام نفسه يدير الانقسام الثنائي. نفسها. حتى يجد مكانا مشكلة. ثم اقرأ في السجلات:
- حصلت على 1000 الإدخالات
- معالجة 200 السجلات
- معالجة 400 السجلات
- عفوًا ، سقط على حزمة من 200 سجل!
- أحاول معالجة حزمة من الحجم 100
- أحاول معالجة حزمة بحجم 50
- أحاول معالجة حزمة من الحجم 25
...
- خطأ في مثل هذه المعرفات: لم يتم ملء حقل البريد الإلكتروني المطلوب
- معالجة 600 السجلات
...
هنا ، بالطبع ، يعتمد المنطق الإضافي أيضًا على المطور. إما أن تتوقف المعالجة بعد مصادفة خطأ ، أو تذهب أبعد من ذلك. تعثرت على حزمة من 200 إدخالات؟ وصلنا إلى نقطة العثور على عنق الزجاجة ، وتم وضع علامة على الإدخال على أنه خاطئ ، وقمنا بمعالجة الـ 199 المتبقية ، ثم تقدمنا.
ولكن ماذا لو تحطمت الحزمة بأكملها؟ وضعنا علامة على السجل باعتباره خاطئًا ، لكن الـ 199 الباقية لم تتمكن أيضًا من معالجته. لماذا؟ نحن نطبق نفس الطريقة ، نبحث عن مشكلة جديدة. الحيلة هي أنك تحتاج دائما أن تكون قادرة على التوقف في الوقت المحدد.
إذا كان عدد الأخطاء أكثر من 10-50-100 ، فمن الأفضل إيقاف التنزيل. من الممكن أن يحدث خطأ في التحميل في النظام الأصلي وتلقينا مليون "منحنى" البيانات. إذا كان النظام سيقسم كل حزمة من 200 سجل إلى نصفين ، ثم يقسم الـ 199 المتبقية ، وهكذا ، فسيكون ذلك سيئًا للجميع:
- ينمو السجل من 15 ميغابايت إلى 3 غيغابايت ويصبح غير قابل للقراءة ؛
- قد يتعطل النظام عند محاولة إنشاء رسالة خطأ نهائية (تحدثت عن هذا الموقف في قسم BMW Mnemonics ) ؛
- يقضي الكثير من الوقت في البحث عن كل الأخطاء. نعم ، يقوم النظام بذلك أسرع من أي شخص ، ولكن إذا قمت بتقسيم مليون حزمة من 200 سجل ، فسيستغرق الأمر بعض الوقت.
لذلك يجب تضمين الدماغ في كل مكان - سواء في الاختبار اليدوي أو عند كتابة رمز البرنامج. يجب أن تفهم دائمًا متى تتوقف. فقط في حالة الاختبار اليدوي سيكون "على وشك العثور على الحدود" ، وفي التطوير "توقف إذا كان هناك الكثير من السقوط".
ملخص
يتم استخدام طريقة تقسيم bisectional للبحث عن الموقع الدقيق للسقوط وتوطين علة.
ابحث عن الرقم وابدأ بتقسيمه إلى نصفين:
- طول الخط
- حجم الملف
- وزن الملف
- عدد الصفوف / الأعمدة ؛
- مقدار الذاكرة المجانية في الهاتف المحمول ؛
- ...
ولكن تذكر - يومًا ما عليك التوقف! لا حاجة للتوقف والبحث عن الرقم الدقيق إذا كان يتطلب الآلاف من الاختبارات الإضافية. ولكن يمكن إعطاء 5-10 دقائق للترجمة.
PS - ابحث عن المزيد من المقالات المفيدة على مدونتي بواسطة علامة "مفيدة"