في الوقت الحاضر ، تعني عبارة "الذكاء الاصطناعي" الكثير من الأنظمة المختلفة - من الشبكة العصبية للتعرف على الصور إلى روبوت لعب الزلزال. تقدم ويكيبيديا تعريفا رائعا للذكاء الاصطناعى - هذا هو "خاصية الأنظمة الذكية لأداء الوظائف الإبداعية التي تعتبر تقليديا من صلاحيات الإنسان." بمعنى أنه يتم رؤيته بوضوح من التعريف - إذا كانت إحدى الوظائف مؤتمتة بنجاح ، فستتحول إلى ذكاء اصطناعي.
ومع ذلك ، عندما تم تعيين مهمة "إنشاء ذكاء اصطناعي" لأول مرة ، كان الذكاء الاصطناعي يعني شيئًا مختلفًا. يسمى هذا الهدف الآن منظمة العفو الدولية قوية أو الغرض العام منظمة العفو الدولية.
بيان المشكلة
الآن هناك صياغتان معروفتان للمشكلة. الأول هو الذكاء الاصطناعى القوي. والثاني هو AI للأغراض العامة (ويعرف أيضا باسم الذكاء العام الاصطناعي ، مختصر AGI).
محدث. في التعليقات ، أخبروني أن هذا الاختلاف هو الأرجح على مستوى اللغة. في اللغة الروسية ، كلمة "استخبارات" لا تعني بالضبط كلمة "استخبارات" باللغة الإنجليزية
الذكاء الاصطناعى القوى هو
الذكاء الاصطناعى الإفتراضى الذى يمكنه القيام بكل ما يستطيع الشخص فعله. يذكر عادة أنه يجب عليه اجتياز اختبار تورينج في الإعداد الأولي (هل ، هل يجتازه الناس؟) ، كن على دراية بنفسه كشخص منفصل ويكون قادرًا على تحقيق أهدافه.
وهذا هو ، أنه شيء مثل شخص مصطنع. في رأيي ، فإن فائدة مثل هذه الذكاء الاصطناعي هي أساسًا البحث ، لأن تعريفات الذكاء الاصطناعي القوي لا توضح في أي مكان ما ستكون أهدافه.
AGI أو AI للأغراض العامة هو "آلة النتائج". إنها تتلقى إعدادًا معينًا للهدف عند الإدخال - وتعطي بعض إجراءات التحكم في المحركات / الليزر / بطاقة الشبكة / الشاشات. والهدف يتحقق. في الوقت نفسه ، لا تملك AGI في البداية معرفة بالبيئة - فقط أجهزة الاستشعار والمحركات والقناة التي تحدد الأهداف من خلالها. سيتم اعتبار نظام الإدارة AGI إذا كان يمكنه تحقيق أي أهداف في أي بيئة. وضعناها لقيادة سيارة وتجنب الحوادث - سوف تتعامل معها. وضعناها في السيطرة على مفاعل نووي بحيث يكون هناك المزيد من الطاقة ، ولكن لا تنفجر - يمكنها التعامل معها. سنقدم صندوق بريد ونعلمك بيع المكانس الكهربائية - سوف نتعامل معها أيضًا. AGI هو حل "المشاكل العكسية". للتحقق من عدد المكانس الكهربائية التي تباع هي مسألة بسيطة. لكن معرفة كيفية إقناع أي شخص بشراء مكنسة كهربائية هي بالفعل مهمة للفكر.
في هذه المقالة سأتحدث عن AGI. لا اختبارات تورينج ، لا الوعي الذاتي ، لا شخصيات مصطنعة - الذكاء الاصطناعى الواقعي بشكل استثنائي وليس المشغلين العمليين.
الوضع الحالي
الآن هناك فئة من النظم مثل التعلم المعزز ، أو التعلم المعزز. هذا شيء مثل AGI ، فقط دون براعة. إنهم قادرون على التعلم ، ونتيجة لذلك ، تحقيق الأهداف في مجموعة متنوعة من البيئات. ولكن لا يزالون بعيدون عن تحقيق الأهداف في أي بيئة.
بشكل عام ، كيف يتم ترتيب أنظمة تعزيز التعلم وما هي مشكلاتهم؟
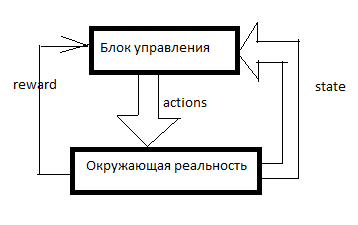
يتم ترتيب أي RL مثل هذا. هناك نظام تحكم ، بعض الإشارات حول الواقع المحيط تدخله من خلال أجهزة الاستشعار (الدولة) ومن خلال الهيئات الحاكمة (الإجراءات) التي تعمل على الواقع المحيط. المكافأة هي إشارة إلى التعزيز. في أنظمة RL ، يتكون التعزيز من خارج وحدة التحكم ويشير إلى مدى توافق الذكاء الاصطناعي مع تحقيق الهدف. كم عدد المكانس الكهربائية المباعة في اللحظة الأخيرة ، على سبيل المثال.
ثم يتكون الجدول من شيء مثل هذا (سأطلق عليه جدول SAR):

يتم توجيه محور الزمن نحو الأسفل. يوضح الجدول كل ما فعله AI ، وكل ما رآه وجميع إشارات التعزيز. عادةً ، لكي يقوم RL بعمل شيء ذي معنى ، يجب عليه أولاً إجراء تحركات عشوائية لفترة من الوقت ، أو النظر في تحركات شخص آخر. بشكل عام ، يبدأ RL عندما يكون هناك بالفعل بضعة خطوط على الأقل في جدول SAR.
ماذا يحدث بعد ذلك؟
سارسا
أبسط شكل من أشكال التعلم التعزيز.
نأخذ نوعًا من نموذج التعلم الآلي ، وباستخدام مزيج من S و A (الحالة والعمل) ، نتوقع إجمالي R للدورات القليلة القادمة على مدار الساعة. على سبيل المثال ، سنرى ذلك (بناءً على ذلك الجدول أعلاه) إذا أخبرت امرأة "كن رجلاً ، وشراء مكنسة كهربائية!" ، فستكون المكافأة منخفضة ، وإذا قلت نفس الشيء للرجل ، فستكون مرتفعة.
ما هي النماذج المحددة التي يمكن استخدامها - سأصفها لاحقًا ، في الوقت الحالي سأقول فقط إن هذه ليست شبكات عصبية فقط. يمكنك استخدام الأشجار القرار أو حتى تحديد وظيفة في نموذج الجدول.
ثم يحدث ما يلي. تتلقى منظمة العفو الدولية رسالة أخرى أو رابط إلى عميل آخر. يتم إدخال جميع بيانات العميل في AI من الخارج - سننظر في قاعدة العملاء وعداد الرسائل كجزء من نظام الاستشعار. بمعنى أنه يبقى تعيين بعض الإجراءات (A) وانتظار التعزيزات. تتخذ منظمة العفو الدولية جميع الإجراءات الممكنة وتتنبأ بدورها (باستخدام نفس نموذج التعلم الآلي) - ماذا سيحدث إذا قمت بذلك؟ ماذا لو كان؟ وكم سيكون التعزيز لهذا؟ ثم RL ينفذ الإجراء الذي من المتوقع أن يحصل على أقصى مكافأة.
أدخلت مثل هذا النظام البسيط والخرقاء في إحدى ألعابي. SARSA يستأجر وحدات في اللعبة ، ويتكيف في حال حدوث تغيير في قواعد اللعبة.
بالإضافة إلى ذلك ، في جميع أنواع التدريب المعزز ، هناك خصم من المكافآت ومعضلة استكشاف / استغلال.
تعتبر جوائز التخفيض بمثابة نهج عندما تحاول RL تعظيم مبلغ المكافأة عن تحركات N التالية ، ولكن المبلغ المرجح وفقًا لمبدأ "100 روبل الآن أفضل من 110 روبية في السنة". على سبيل المثال ، إذا كان عامل الخصم هو 0.9 ، وكان أفق التخطيط هو 3 ، فسوف نقوم بتدريب النموذج ليس على إجمالي R للدورات الثلاث القادمة على مدار الساعة ، ولكن على R1 * 0.9 + R2 * 0.81 + R3 * 0.729. لماذا هذا ضروري؟ إذن ، هذا الذكاء الاصطناعى ، وخلق ربح في مكان ما عند اللانهاية ، لسنا بحاجة. نحن بحاجة إلى الذكاء الاصطناعي الذي يحقق ربحًا هنا والآن.
استكشاف / استغلال المعضلة. إذا قام RL بما يعتبره النموذج الأمثل ، فلن يعرف أبدًا ما إذا كانت هناك أي إستراتيجيات أفضل. Exploit هي استراتيجية يقوم فيها RL بعمل ما يعد بأقصى مكافآت. Explore هي استراتيجية يقوم RL فيها بعمل شيء لاستكشاف البيئة بحثًا عن استراتيجيات أفضل. كيفية تنفيذ الذكاء الفعال؟ على سبيل المثال ، يمكنك القيام بعمل عشوائي كل بضعة تدابير. أو لا يمكنك إنشاء نموذج تنبؤي واحد ، ولكن يمكنك إنشاء العديد من الإعدادات المختلفة قليلاً. سوف ينتجون نتائج مختلفة. كلما زاد الفرق ، زادت درجة عدم اليقين في هذا الخيار. يمكنك اتخاذ الإجراء بحيث يكون له الحد الأقصى للقيمة: M + k * std ، حيث M هي متوسط التوقعات لجميع الطرز ، std هي الانحراف المعياري للتنبؤات ، و k هي معامل الفضول.
ما هي العيوب؟دعنا نقول لدينا خيارات. انتقل إلى الهدف (الذي يبعد 10 كم منا ، والطريق إلى ذلك جيد) بالسيارة أو سيرا على الأقدام. ثم ، بعد هذا الاختيار ، لدينا خيارات - التحرك بعناية أو محاولة الاصطدام بكل عمود.
سيقول الشخص على الفور أنه من الأفضل عادة قيادة السيارة والتصرف بعناية.
لكن سارسا ... سوف ينظر في قرار قيادة السيارة قبل ذلك. لكنها أدت إلى هذا. في مرحلة المجموعة الأولية للإحصاءات ، قاد الذكاء الاصطناعي بتهور وتحطمت في مكان ما في نصف الحالات. نعم ، يمكنه القيادة جيدًا. لكن عندما يختار ما إذا كان سيذهب بالسيارة ، فهو لا يعرف ما سيختار الخطوة التالية. لديه إحصاءات - ثم في نصف الحالات ، اختار الخيار المناسب ، وفي النصف - انتحار. لذلك ، في المتوسط ، من الأفضل المشي.
يعتقد SARSA أن الوكيل سوف يلتزم بنفس الاستراتيجية التي تم استخدامها لملء الطاولة. ويعمل على هذا الأساس. ولكن ماذا لو افترضنا خلاف ذلك - أن العميل سوف يلتزم بأفضل استراتيجية في التحركات القادمة؟
Q-التعلم
يحسب هذا النموذج لكل ولاية الحد الأقصى للمكافأة الكلية الممكن تحقيقها منه. ويكتبها في عمود خاص Q. أي أنه إذا حصلت من الحالة S على نقطتين أو 1 ، حسب الحركة ، فإن Q (S) تساوي 2 (بعمق تنبؤ 1). ما المكافأة التي يمكن الحصول عليها من الحالة S ، نتعلم من النموذج التنبؤي Y (S ، A). (S - الدولة ، A - العمل).
بعد ذلك ، نقوم بإنشاء نموذج تنبؤي Q (S ، A) - أي الحالة التي سوف تنتقل إليها Q إذا نفذنا الإجراء A من S. وإنشاء العمود التالي في الجدول - Q2. وهذا هو ، الحد الأقصى ل Q الذي يمكن الحصول عليه من الدولة S (نحن فرز من خلال كل ممكن A).
ثم نقوم بإنشاء نموذج انحدار Q3 (S ، A) - أي للحالة التي سنذهب بها Q2 إذا قمنا بتنفيذ الإجراء A من S.
و هكذا. وبالتالي ، يمكننا تحقيق عمق غير محدود للتنبؤ.
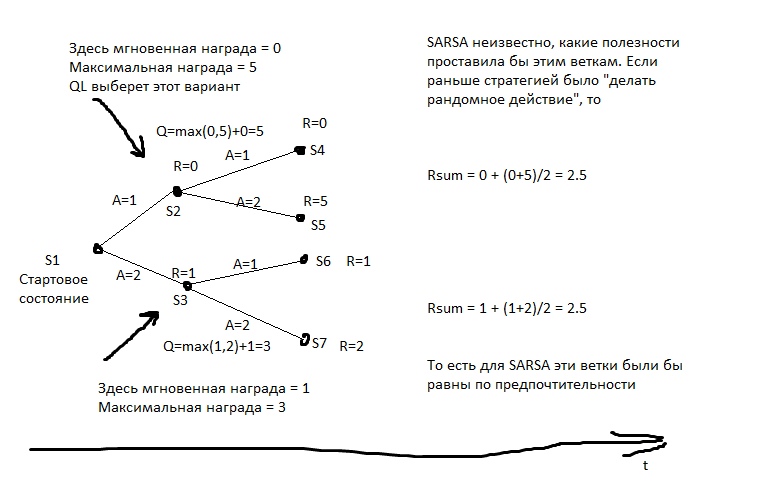
في الصورة ، R هو التعزيز.
وبعد ذلك نختار كل حركة الإجراء الذي يعد بأعظم Qn. إذا طبقنا هذه الخوارزمية على لعبة الشطرنج ، فسنحصل على شيء مثل الحد الأدنى المثالي. هناك شيء مكافئ تقريبًا ينتقل إلى الحسابات الخاطئة.
مثال شائع لسلوك تعلم q. الصياد لديه رمح ، ويذهب معه إلى الدب ، بمبادرة منه. إنه يعلم أن الغالبية العظمى من تحركاته المستقبلية لها مكافأة سلبية كبيرة جدًا (هناك طرق أكثر بكثير للخسارة من طرق الفوز) ، وهو يعلم أن هناك تحركات بمكافأة إيجابية. يعتقد الصياد أنه في المستقبل سوف يتخذ أفضل الحركات (وليس من المعروف أي منها كما في SARSA) ، وإذا قام بأفضل الحركات ، فسوف يهزم الدب. وهذا يعني ، لكي يذهب إلى الدب ، يكفي أن يكون قادرًا على صنع كل عنصر ضروري للصيد ، لكن ليس من الضروري أن يكون لديه خبرة بالنجاح الفوري.
إذا تصرف الصياد بأسلوب السارسا ، فسيفترض أن تصرفاته في المستقبل ستكون هي نفسها كما كان من قبل (على الرغم من أن لديه الآن أمتعة مختلفة من المعرفة) ، وسوف يذهب فقط إلى الدب إذا ذهب بالفعل إلى وفاز ، على سبيل المثال ، في أكثر من 50 ٪ من الحالات (حسناً ، أو إذا فاز صيادون آخرون في أكثر من نصف الحالات ، إذا تعلم من تجربتهم).
ما هي العيوب؟- النموذج لا يتكيف مع الواقع المتغير. إذا كانت حياتنا بأكملها قد مُنحت لنا للضغط على الزر الأحمر ، والآن يعاقبوننا ، ولم تحدث أي تغييرات مرئية ... سوف تتولى QL إتقان هذا النمط لفترة طويلة جدًا.
- Qn يمكن أن تكون وظيفة معقدة للغاية. على سبيل المثال ، لحسابها ، تحتاج إلى التمرير لدورة من التكرارات N - ولن تعمل بشكل أسرع. عادةً ما يكون للنموذج التنبئي تعقيد محدود - فحتى الشبكة العصبية الكبيرة بها حد تعقيد ، ولا يستطيع أي نموذج للتعلم الآلي تدوير الدورات.
- الواقع عادة ما يكون متغيرات خفية. على سبيل المثال ، ما الوقت الآن؟ من السهل معرفة ما إذا كنا ننظر إلى الساعة ، ولكن بمجرد أن ننظر بعيدًا ، يعد هذا بالفعل متغيرًا مخفيًا. لأخذ هذه القيم التي لا يمكن مراعاتها في الاعتبار ، من الضروري أن يأخذ النموذج في الاعتبار ليس فقط الحالة الحالية ، ولكن أيضًا نوع من التاريخ. في QL ، يمكنك القيام بذلك - على سبيل المثال ، لتغذية ليس فقط S الحالي ، ولكن أيضًا العديد من سابقاتها في الخلية العصبية أو ما لدينا. يتم ذلك في RL ، الذي يلعب ألعاب أتاري. بالإضافة إلى ذلك ، يمكنك استخدام شبكة عصبية متكررة للتنبؤ - دعها تعمل بالتتابع على عدة إطارات من التاريخ وحساب Qn.
النظم القائمة على النموذج
ولكن ماذا لو توقعنا ليس فقط R أو Q ، ولكن بشكل عام جميع البيانات الحسية؟ سيكون لدينا باستمرار نسخة جيب من الواقع وسنكون قادرين على التحقق من خططنا على ذلك. في هذه الحالة ، نحن أقل قلقًا بشأن صعوبة حساب وظيفة Q-. نعم ، يتطلب الأمر الكثير من الساعات لحسابها - حسنًا ، لذلك على أي حال ، لكل خطة ، سنقوم بتشغيل نموذج التنبؤ بشكل متكرر. التخطيط 10 يتحرك إلى الأمام؟ نطلق النموذج 10 مرات ، وفي كل مرة نقوم بتغذية مخرجاته إلى مدخلاته.
ما هي العيوب؟- كثافة الموارد. لنفترض أننا بحاجة إلى اختيار بديلين في كل قياس. ثم لمدة 10 دورات على مدار الساعة ، سيكون لدينا 2 ^ 10 = 1024 خطة ممكنة. كل خطة هي 10 إطلاق النموذج. إذا كنا السيطرة على طائرة مع العشرات من الهيئات الحاكمة؟ وهل نحن محاكاة الواقع مع فترة 0.1 ثانية؟ هل ترغب في الحصول على أفق تخطيط لبضع دقائق على الأقل؟ سيتعين علينا تشغيل النموذج عدة مرات ، وهناك الكثير من دورات ساعة المعالج لحل واحد. حتى إذا قمت بتحسين تعداد الخطط بطريقة أو بأخرى ، ومع ذلك ، فهناك أوامر بحجم أكبر من الحسابات في QL.
- مشكلة الفوضى. تم تصميم بعض الأنظمة بحيث يؤدي عدم الدقة في محاكاة الإدخال إلى حدوث خطأ كبير في الإخراج. لمواجهة هذا ، يمكنك تشغيل العديد من عمليات محاكاة الواقع - مختلفة قليلاً. سوف ينتجون نتائج مختلفة للغاية ، ومن هذا سيكون من الممكن أن نفهم أننا في منطقة عدم الاستقرار هذه.
طريقة تعداد الإستراتيجية
إذا تمكنا من الوصول إلى بيئة اختبار الذكاء الاصطناعي ، وإذا لم نقم بتشغيلها في الواقع ، ولكن في محاكاة ، يمكننا إذن كتابة استراتيجية سلوك وكيلنا بشكل ما. ثم اختر - مع التطور أو أي شيء آخر - استراتيجية تؤدي إلى أقصى ربح.
يعني مصطلح "اختيار استراتيجية" أننا نحتاج أولاً إلى معرفة كيفية كتابة استراتيجية بطريقة يمكن دفعها إلى خوارزمية التطور. أي أنه يمكننا كتابة الإستراتيجية برمز البرنامج ، لكن في بعض الأماكن تترك المعاملات ، وتدع التطور يأخذها. أو يمكننا كتابة استراتيجية مع شبكة عصبية - والسماح للتطور بالتقاط أوزان اتصالاتها.
وهذا هو ، ليس هناك توقعات هنا. لا يوجد جدول SAR. نحن ببساطة اختيار استراتيجية ، وعلى الفور يعطي خارج الإجراءات.
هذه طريقة قوية وفعالة ، إذا كنت ترغب في تجربة RL ولا تعرف من أين تبدأ ، فإنني أوصي به. هذه هي وسيلة رخيصة للغاية "لرؤية معجزة".
ما هي العيوب؟- القدرة على تشغيل التجارب نفسها مرات عديدة مطلوبة. بمعنى ، يجب أن نكون قادرين على إرجاع الواقع إلى نقطة البداية - عشرات الآلاف من المرات. لمحاولة استراتيجية جديدة.
نادرا ما توفر الحياة مثل هذه الفرص. عادة ، إذا كان لدينا نموذج للعملية التي نهتم بها ، لا يمكننا إنشاء استراتيجية الماكرة - يمكننا ببساطة وضع خطة ، كما هو الحال في النهج القائم على النموذج ، حتى مع القوة الغاشمة الفظة. - التعصب لتجربة. هل لدينا جدول SAR لسنوات من الخبرة؟ يمكننا أن ننسى ذلك ، لا تنسجم مع المفهوم.
طريقة لتعداد الاستراتيجيات ، ولكن "العيش"
نفس التعداد من الاستراتيجيات ، ولكن على واقع الحياة. نحن نحاول 10 تدابير من استراتيجية واحدة. ثم 10 تدابير أخرى. ثم 10 تدابير للثالث. ثم نختار واحدة حيث كان هناك المزيد من التعزيز.
تم الحصول على أفضل النتائج للمشي البشرى بهذه الطريقة.

بالنسبة لي ، يبدو هذا غير متوقع إلى حد ما - يبدو أن النهج القائم على نموذج QL + مثالي للرياضيات. ولكن لا شيء من هذا القبيل. تتشابه مزايا النهج مع ميزات النهج السابق تقريبًا - لكنها أقل وضوحًا ، نظرًا لأن الاستراتيجيات لم يتم اختبارها لفترة طويلة جدًا (حسنًا ، ليس لدينا آلاف السنين بشأن التطور) ، مما يعني أن النتائج غير مستقرة. بالإضافة إلى ذلك ، لا يمكن رفع عدد الاختبارات أيضًا إلى ما لا نهاية - مما يعني أنه يجب البحث عن الاستراتيجية في مساحة غير معقدة للغاية من الخيارات. ليس لديها فقط "أقلام" يمكن أن تكون "ملتوية". حسنًا ، لم يتم إلغاء تجربة عدم التسامح. وبالمقارنة مع QL أو المستندة إلى الطراز ، تستخدم هذه النماذج التجربة بشكل غير فعال. إنهم بحاجة إلى تفاعلات أكثر بكثير مع الواقع من الأساليب التي تستخدم التعلم الآلي.
كما ترون ، يجب أن تتضمن أي محاولات لإنشاء AGI من الناحية النظرية إما التعلم الآلي لجوائز التنبؤ ، أو شكل من أشكال تدوين المعلمات لاستراتيجية - بحيث يمكنك التقاط هذه الاستراتيجية مع شيء مثل التطور.
يعد هذا هجومًا قويًا على الأشخاص الذين يعرضون إنشاء الذكاء الاصطناعي استنادًا إلى قواعد البيانات والمنطق والرسوم البيانية المفاهيمية. إذا كنت ، أنصار النهج الرمزي ، اقرأ هذا - مرحبًا بكم في التعليقات ، وسيسعدني أن أعرف ما الذي يمكن أن يفعله AGI بدون الآليات الموصوفة أعلاه.
نماذج التعلم الآلي لـ RL
يمكن استخدام أي نموذج ML تقريبًا في التعلم المعزز. الشبكات العصبية ، بالطبع ، جيدة. ولكن هناك ، على سبيل المثال ، KNN. لكل زوج S و A ، نبحث عن أكثر الأزواج تشابهًا ، ولكن في الماضي. ونحن نبحث عن ماذا سيكون ر. غبي بعد ذلك؟ نعم ، لكنه يعمل. هناك أشجار حاسمة - من الأفضل أن تمشي على الكلمات الرئيسية "تعزيز التدرج" و "الغابة الحاسمة". هل الأشجار فقيرة في التقاط التبعيات المعقدة؟ استخدام ميزة الهندسة. تريد منظمة العفو الدولية الخاصة بك أقرب إلى العام؟ استخدام التلقائي FE! انتقل إلى مجموعة من الصيغ المختلفة ، وقم بتقديمها كميزات لتعزيزك ، وتجاهل الصيغ التي تزيد الخطأ ، واترك الصيغ التي تحسن الدقة. ثم قم بتقديم أفضل الصيغ كوسيطات للصيغ الجديدة ، وهكذا ، تتطور.
يمكنك استخدام الانحدارات الرمزية للتنبؤ - أي مجرد فرز الصيغ في محاولة للحصول على شيء يقارب Q أو R. من الممكن تجربة فرز الخوارزميات - ثم تحصل على شيء يسمى تحريض Solomonov ، وهو أمر مثالي من الناحية النظرية تقريبًا تقريب الوظائف.
لكن الشبكات العصبية عادة ما تكون حلا وسطا بين التعبيرية وتعقيد التعلم. الانحدار الخوارزمي يأخذ بشكل مثالي أي تبعية - لمئات السنين. ستعمل شجرة القرارات بسرعة كبيرة - لكنها لن تكون قادرة على الاستقراء y = a + b. الشبكة العصبية هي شيء بينهما.
آفاق التنمية
ما هي طرق القيام بالضبط AGI الآن؟ على الأقل من الناحية النظرية.
تطور
يمكننا إنشاء العديد من بيئات الاختبار المختلفة وبدء تطور بعض الشبكات العصبية. , .
, .
, - RL, , . , RL — — « - , , !». — .
AIXI
Model-Based , . — , , . — , . , . , , — .
. , — , .
Seed AI
, . . ,
, . … ? .
?
, RL actions RL.
RL - - . RL , , .
— , actions .
Seed AI — . ? , ?
, Google, DeepMind . , .
, =) , « , AGI»!