منذ حوالي عام ، كلفنا أنا وزملائي بالفرز باستخدام نظام مراقبة البنية التحتية للشبكة الشهير - Zabbix. بعد دراسة الوثائق ، شرعنا فورًا في تحميل الاختبار: لقد أردنا تقييم عدد المعلمات التي يمكن أن تعمل Zabbix دون حدوث انخفاض ملحوظ في الأداء. تم استخدام PostgreSQL فقط كـ DBMS.
أثناء الاختبارات ، تم تحديد بعض السمات المعمارية لتخطيط قاعدة البيانات وسلوك نظام المراقبة نفسه ، والتي لا تسمح لنظام المراقبة بالوصول إلى الحد الأقصى من طاقته افتراضيًا. نتيجة لذلك ، تم تطوير بعض تدابير التحسين وإجرائها واختبارها بشكل أساسي من حيث ضبط قاعدة البيانات.
أريد أن أشارك نتائج العمل المنجز في هذه المقالة. ستكون هذه المقالة مفيدة لكلا مسؤولي Zabbix و PostgreSQL DBA ، وكذلك لكل من يريد فهم وفهم PosgreSQL DBMS الشعبي بشكل أفضل.
مفسد صغير: على جهاز ضعيف مع حمولة 200 ألف معلمة في الدقيقة ، تمكنا من تقليل وحدة المعالجة المركزية iowait من 20 ٪ إلى 2 ٪ ، وتقليل وقت التسجيل في أجزاء لجداول البيانات الأولية بنسبة 250 مرة ، وجداول البيانات المجمعة بنسبة 32 مرة ، والحد من حجم الفهارس 5-10 مرات وتسريع استلام العينات التاريخية في بعض الحالات حتى 18 مرة.
اختبار الحمل
تم إجراء اختبار الحمل وفقًا للمخطط: خادم Zabbix واحد ، وكيل Zabbix نشط ، وكيلان. تم تكوين كل عامل لإعطاء 50 طنًا من الأعداد الصحيحة و 50 طنًا من معلمات السلسلة في الدقيقة (أي ما مجموعه 200 طن من المعلمات في الدقيقة أو 3333 معلمة في الثانية). لإنشاء معلمات عامل ، استخدمنا
مكونًا إضافيًا لبرنامج Zabbix ، وللتحقق من عدد المعلمات التي يمكن أن ينشئها الوكيل ، تحتاج إلى استخدام برنامج
نصي خاص من نفس مؤلف المكون الإضافي zabbix_module_stress . يواجه مسؤول الويب من Zabbix صعوبات في تسجيل القوالب الكبيرة ، لذلك قمنا بتقسيم المعلمات إلى 20 قالبًا مع 5 أطنان من المعلمات (2500 سلسلة رقمية و 2500 سلسلة).
قالب مولد النصي لاختبار الحمل في الثعبانimport argparse """ . 20 5000 ( 2500 : echo, ; ping, ) """ TEMP_HEAD = """ <?xml version="1.0" encoding="UTF-8"?> <zabbix_export> <version>2.0</version> <date>2015-08-17T23:15:01Z</date> <groups> <group> <name>Templates</name> </group> </groups> <templates> <template> <template>Template Zabbix Srv Stress {count} passive {char}</template> <name>Template Zabbix Srv Stress {count} passive {char}</name> <description/> <groups> <group> <name>Templates</name> </group> </groups> <applications/> <items> """ TEMP_END = """</items> <discovery_rules/> <macros/> <templates/> <screens/> </template> </templates> </zabbix_export> """ TEMP_ITEM = """<item> <name>{k}</name> <type>0</type> <snmp_community/> <multiplier>0</multiplier> <snmp_oid/> <key>{k}</key> <delay>1m</delay> <history>3</history> <trends>365</trends> <status>0</status> <value_type>{t}</value_type> <allowed_hosts/> <units/> <delta>0</delta> <snmpv3_contextname/> <snmpv3_securityname/> <snmpv3_securitylevel>0</snmpv3_securitylevel> <snmpv3_authprotocol>0</snmpv3_authprotocol> <snmpv3_authpassphrase/> <snmpv3_privprotocol>0</snmpv3_privprotocol> <snmpv3_privpassphrase/> <formula>1</formula> <delay_flex/> <params/> <ipmi_sensor/> <data_type>0</data_type> <authtype>0</authtype> <username/> <password/> <publickey/> <privatekey/> <port/> <description/> <inventory_link>0</inventory_link> <applications/> <valuemap/> <logtimefmt/> </item> """ TMP_FNAME_DEFAULT = "Template_App_Zabbix_Server_Stress_{count}_passive_{char}.xml" chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" if __name__ == "__main__": parser = argparse.ArgumentParser( description=' zabbix') parser.add_argument('--items', dest='items', type=int, default=1000, help='- (default: 1000)') parser.add_argument('--templates', dest='templates', type=int, default=1, help=f'- [1-{len(chars)}] (default: 1)') args = parser.parse_args() items_count = args.items tmps_count = args.templates if not (tmps_count >= 1 and tmps_count <= len(chars)): sys.exit(f"Templates must be in range 1 - {len(chars)}") for i in range(tmps_count): fname = TMP_FNAME_DEFAULT.format(count=items_count, char=chars[i]) with open(fname, "w") as output: output.write(TEMP_HEAD.format(count=items_count, char=chars[i])) for k,t in [('stress.ping[{}-I-{:06d}]',3), ('stress.echo[{}-S-{:06d}]',4)]: for j in range(int(items_count/2)): output.write(TEMP_ITEM.format(k=k.format(chars[i],j),t=t)) output.write(TEMP_END)
يعد قياس وحدة المعالجة المركزية iostat مؤشرًا جيدًا على أداء Zabbix - فهو يعكس جزء وحدة الوقت الذي ينتظر المعالج من خلاله الوصول إلى القرص. كلما زاد ارتفاعه ، زاد احتلال القرص لعمليات القراءة والكتابة ، مما يؤثر بشكل غير مباشر على تدهور أداء نظام المراقبة ككل. أي هذه علامة أكيدة على وجود خطأ ما في المراقبة. بالمناسبة ، في المساحات المفتوحة للشبكة ، السؤال الأكثر شيوعًا هو "كيفية إزالة مشغل iostat في Zabbix" ، لذلك هذه نقطة حساسة ، لأن هناك العديد من الأسباب لزيادة قيمة مقياس iowait.
إليكم صورة مقياس وحدة المعالجة المركزية iowait الذي حصلنا عليه في البداية بعد ثلاثة أيام:
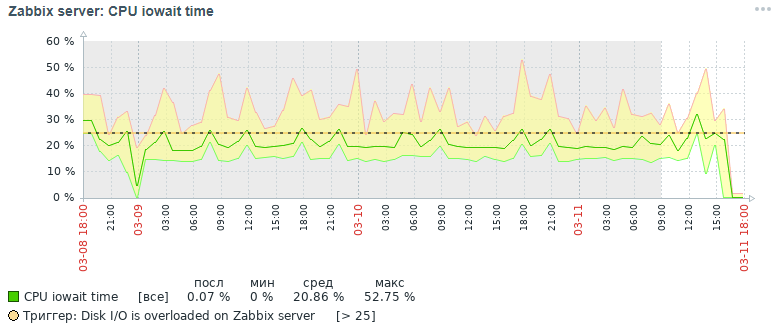
ولكن ما هي الصورة لنفس المقياس الذي حصلنا عليه أيضًا في غضون ثلاثة أيام في النهاية بعد كل إجراءات التحسين التي تم تنفيذها ، والتي سيتم مناقشتها أدناه:
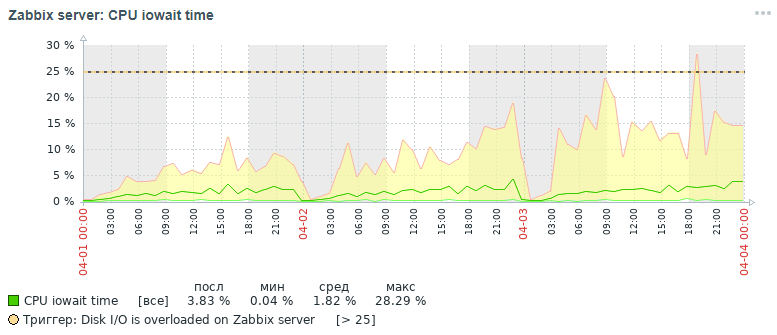
كما يتضح من الرسوم البيانية ، انخفض مؤشر وحدة المعالجة المركزية iowait من ما يقرب من 20 ٪ إلى 2 ٪ ، مما سرع بشكل غير مباشر في وقت التنفيذ لجميع طلبات إضافة وقراءة البيانات. الآن دعنا نرى لماذا ، مع إعدادات قاعدة البيانات القياسية ، ينخفض الأداء العام لنظام المراقبة وكيفية إصلاحه.
أسباب انخفاض الأداء Zabbix
مع تراكم أكثر من 10 ملايين قيمة معلمة في كل جدول من البيانات الأولية ، لوحظ أن أداء نظام المراقبة ينخفض بشكل حاد ، وذلك للأسباب التالية:
- يتم زيادة قياس iowait لوحدة المعالجة المركزية للخادم بأكثر من 20٪ ، مما يشير إلى زيادة في الوقت الذي تتوقع فيه وحدة المعالجة المركزية الوصول إلى عمليات القراءة والكتابة على القرص
- فهارس الجداول التي يتم فيها تضخيم بيانات المراقبة إلى حد كبير
- زيادة قياس الاستخدام إلى 100٪ للقرص الذي يحتوي على بيانات المراقبة ، مما يشير إلى الحمل الكامل للقرص مع عمليات القراءة والكتابة
- لا تملك القيم القديمة وقتًا يجب حذفه من جداول المحفوظات عند التنظيف وفقًا لجدول مدبرة المنزل
يتفاقم الموقف في بداية كل ساعة ، عندما تحسب بالإضافة إلى ذلك ، إحصائيات كل ساعة مجمعة - أثناء قراءة وكتابة صفحات الفهرس من القرص ، وحذف البيانات القديمة من السجل ، مما يؤدي إلى نفس النتيجة - انخفاض في أداء قاعدة البيانات وزيادة وقت التنفيذ طلبات (في الحد ، تم تسجيل طلب يدوم حتى 5 دقائق!).
القليل من المساعدة في تنظيم مستودع بيانات الرصد في Zabbix. إنه يخزن البيانات الأولية والبيانات المجمعة في جداول مختلفة ، علاوة على ذلك ، مع فصل أنواع المعلمات. يخزن كل جدول حقل itemid (مرجع ضمني لعنصر بيانات مسجّل في النظام) ، طابع زمني لتسجيل قيمة الساعة بتنسيق الطابع الزمني لليونيكس (مللي ثانية في عمود منفصل) وقيمة في عمود منفصل (الاستثناء هو جدول السجل ، يحتوي على المزيد من الحقول - يشبه سجل الأحداث ):
أنشطة التحسين
لتحسين أداء قاعدة بيانات PostgreSQL ، تم تنفيذ العديد من مقاييس التحسين ، وأهمها تقسيم الفهارس وتغييرها. ومع ذلك ، تجدر الإشارة إلى بضع كلمات حول بعض التدابير الهامة والمفيدة التي يمكن أن تسرع عمل أي قاعدة بيانات في ظل نظام إدارة قاعدة بيانات PostgreSQL.
ملاحظة مهمة. في وقت جمع مواد المقالة ، استخدمنا Zabbix الإصدار 4.0 ، على الرغم من أن الإصدار 4.2 قد تم إصداره بالفعل وأن الإصدار 4.4 يتم إعداده للنشر. لماذا من المهم أن أذكر هذا؟ نظرًا بدءًا من الإصدار 4.2 ، بدأ Zabbix في دعم امتداد قوي خاص للعمل مع سلاسل TimescaleDB الزمنية ، ولكن حتى الآن في الوضع التجريبي: لجميع مزايا استخدام هذا الملحق ، يُعتقد أن بعض الطلبات بدأت تعمل بشكل أبطأ وما زالت هناك مشاكل في الأداء لم يتم حلها (ستكون هناك حل في الإصدار 4.4) -
قراءة هذا المقال .
في المقالة التالية أخطط للكتابة عن نتائج اختبار الحمل باستخدام ملحق TimescaleDB بالفعل مقارنةً بحالة الحل هذه. تم استخدام إصدار PostgreSQL 10 ، ولكن كل المعلومات المقدمة ذات صلة بالإصدارات 11 و 12 (نحن في انتظار!).
لذلك ، أول الأشياء أولاً:
- إعداد ملف التكوين باستخدام الأداة المساعدة pgtune
- وضع قاعدة البيانات إلى قرص فعلي منفصل
- تقسيم الجداول التاريخ مع pg_pathman
- تغيير أنواع فهرس جداول المحفوظات إلى brin (ساعة) و btree-gin (itemid)
- جمع وتحليل إحصائيات تنفيذ الاستعلام pg_stat_statements
- وضع المعلمات رصد القرص الفعلي
- تحسين أداء الأجهزة
- إنشاء مجموعة موزعة (مواد خارج نطاق هذه المقالة)
تكوين ملف التكوين باستخدام الأداة المساعدة pgtune
في الواقع ، PostgreSQL هو نظام إدارة قواعد البيانات خفيف الوزن إلى حد ما. تم تكوين ملف التكوين الافتراضي الخاص به بحيث ، كما يقول زميلي ، "حتى العمل على آلة القهوة" ، أي على الحديد متواضعة جدا. لذلك ، من الضروري تكوين PostgreSQL لتكوين الخادم ، مع مراعاة مقدار الذاكرة وعدد المعالجات ونوع الاستخدام المقصود لقاعدة البيانات ونوع القرص (HDD أو SSD) وعدد الاتصالات.
للأسف ، لا توجد صيغة واحدة لضبط جميع نظم إدارة قواعد البيانات ، ولكن هناك قواعد وأنماط معينة مناسبة لمعظم التكوينات (الضبط الدقيق هو بالفعل عمل خبير). لتبسيط حياة DBA ، تمت كتابة الأداة المساعدة
pgtune ، والتي تم استكمالها بواسطة
إصدار الويب بواسطة
le0pard ، مؤلف كتاب مثير للاهتمام ومفيد عن إدارة PostgreSQL.
مثال على تشغيل الأداة المساعدة في وحدة التحكم مع 100 اتصال (Zabbix لديه مسؤول ويب مطالبين) لنوع التطبيق "مستودعات البيانات":
pgtune -i postgresql.conf -o new_postgresql.conf -T DW -c 100
معلمات التكوين التي تتغير الأداة المساعدة pgtune مع وصف الغرض (يتم إعطاء القيم كمثال) # DB الإصدار: 11
نوع نظام التشغيل: لينكس
# DB نوع: الويب
# إجمالي الذاكرة (RAM): 8 جيجابايت
# وحدات المعالجة المركزية الأسطوانات: 1
# اتصالات الأسطوانات: 100
# تخزين البيانات: الأقراص الصلبة
max_connections = 100 # الحد الأقصى لعدد اتصالات قاعدة البيانات المتزامنة
Shared_buffers = 2GB # حجم الذاكرة لمختلف المخازن المؤقتة (ذاكرة التخزين المؤقت بشكل رئيسي من كتل الجدول وكتل الفهرس) في الذاكرة المشتركة
effect_cache_size = 6GB # الحد الأقصى لحجم الذاكرة المطلوبة لتنفيذ الاستعلام باستخدام الفهارس
maintenance_work_mem = 512 ميجابايت # يؤثر على سرعة العمليات VACUUM ، ANALYZE ، CREATE INDEX
checkpoint_completion_target = 0.7 # الوقت المستهدف لإكمال إجراءات نقاط التفتيش
wal_buffers = 16 ميغابايت # مقدار الذاكرة المستخدمة من قبل الذاكرة المشتركة للحفاظ على سجلات المعاملات
default_statistics_target = 100 # كمية الإحصائيات التي يتم جمعها بواسطة أمر ANALYZE - عند الزيادة ، يبني المحسن الاستعلامات ببطء أكثر ، لكن أفضل
random_page_cost = 4 # التكلفة الشرطية للوصول إلى الفهرس إلى صفحات البيانات - تؤثر على قرار استخدام الفهرس
effect_io_concurrency = 2 # عدد عمليات الإدخال / الإخراج غير المتزامنة التي سيحاول DBMS تنفيذها في جلسة منفصلة
work_mem = 10485 كيلو بايت # مقدار الذاكرة المستخدمة للفرز وجداول التجزئة قبل استخدام الملفات المؤقتة على القرص
min_wal_size = 1GB # حدود أقل من عدد ملفات WAL التي سيتم إعادة تدويرها للاستخدام في المستقبل
max_wal_size = حدود 2GB # على رأس عدد ملفات WAL التي سيتم إعادة تدويرها للاستخدام في المستقبل
بعض خيارات التكوين postgresql المفيدة # إدارة معالجات الطلب المتزامنة
max_worker_processes = 8 # الحد الأقصى لعدد عمليات الخلفية - واحد على الأقل لكل قاعدة بيانات
max_parallel_workers_per_gather = 4 # الحد الأقصى لعدد العمليات المتوازية ضمن طلب واحد
max_parallel_workers = 8 # الحد الأقصى لعدد عمليات العمل التي يمكن للنظام دعمها للعمليات المتوازية
# إعدادات التسجيل (طريقة سهلة للتعرف على وقت تنفيذ الطلبات دون استخدام ملحق pg_stat_statements)
log_min_duration_statement = 3000 # اكتب إلى السجلات مدة تنفيذ جميع الأوامر التي يكون وقت تشغيلها> = من القيمة المحددة بالمللي ثانية
log_duration = إيقاف # تسجيل مدة كل أمر مكتمل
log_statement = 'none' # التي أوامر SQL الكتابة إلى السجل ، والقيم: بلا (تعطيل) ، ddl ، وزارة الدفاع وجميع (جميع الأوامر)
debug_print_plan = إيقاف # إخراج شجرة خطة الاستعلام لمزيد من التحليل
# ضغط الحد الأقصى للخروج من قاعدة البيانات وكن جاهزًا للحصول عليه لأي عطل (للأكثر قمعًا ، الذين يتجاهلون وجود SSD ومجموعة نظامية موزعة)
#fsync = off # الكتابة الفعلية على قرص التغييرات ، يؤدي تعطيل fsync إلى زيادة السرعة ، ولكن يمكن أن يؤدي إلى فشل دائم
#synchronous_commit = off # يسمح لك بالرد على العميل حتى قبل أن تكون معلومات المعاملة في WAL - بديل آمن تقريبًا لتعطيل fsync
#full_page_writes = off # shutdown يسرع العمليات العادية ، لكن يمكن أن يؤدي إلى تلف البيانات أو تلف البيانات إذا تعطل النظام
سرد قاعدة بيانات على قرص فعلي منفصل
هذا العنصر اختياري ويعد حلاً انتقاليًا لمجموعة موزعة بالكامل ، لكن سيكون من المفيد معرفة هذا الاحتمال. لتسريع قاعدة البيانات ، يمكنك وضعها على قرص منفصل. لقد قمنا بتركيب القرص بأكمله في الدليل الأساسي ، حيث يتم تخزين جميع قواعد بيانات PostgreSQL ، ولكن بشكل عام يمكن القيام بذلك بشكل مختلف: إنشاء قاعدة جداول جديدة ونقل قاعدة البيانات (أو حتى جزء منها فقط - جداول بيانات المراقبة الأساسية والمجمعة) إلى قاعدة الجداول هذه على قرص منفصل.
جبل سبيل المثالتحتاج أولاً إلى تهيئة القرص باستخدام نظام الملفات ext4 وتوصيله بالخادم. تحميل القرص لقاعدة البيانات مع التسمية وقت الظهيرة:
mount / dev / sdc1 / var / lib / pgsql / 10 / data / base -o noatime
للتثبيت الدائم ، أضف السطر إلى ملف / etc / fstab:
# حيث UUID هو معرف القرص ، يمكنك رؤيته باستخدام الأداة المساعدة blkid
UUID = 121efe29-70bf-410b-bc71-90704568ce3b / var / lib / pgsql / 10 / data / base ext4 defaults، noatime 0 0
تقسيم الجداول التاريخ مع pg_pathman
إحدى المشكلات التي واجهناها أثناء اختبار الضغط في Zabbix - PostgreSQL لا يمكنها حذف البيانات القديمة من قاعدة البيانات. باستخدام التقسيم ، يمكنك تقسيم الجدول إلى الأجزاء المكونة له ، وبالتالي تقليل حجم الفهارس والأجزاء المكونة للجدول الفائق ، مما يؤثر بشكل إيجابي على سرعة قاعدة البيانات ككل.
التقسيم يحل مشكلتين في وقت واحد:
1. تسريع إزالة البيانات القديمة عن طريق حذف الجداول بأكملها
2. تقسيم المؤشرات لكل جدول مركب
هناك أربع آليات للتقسيم في PostgreSQL:
1. معيار التقييد
2. تمديد pg_partman (
لا تخلط مع pg_pathman )
3. تمديد
pg_pathman4. يدويا إنشاء وصيانة أقسام من قبل أنفسنا
حل التقسيم الأكثر ملاءمة وموثوقية
ومحسّنة ، في رأينا ، هو امتداد
pg_pathman . باستخدام طريقة التقسيم هذه ، يحدد مخطط الاستعلام بمرونة الأقسام التي تبحث عن البيانات.
تقول الشائعات أنه في الإصدار الثاني عشر من PostgreSQL سيكون هناك قسم ممتاز بالفعل خارج الصندوق.وبالتالي ، بدأنا في كتابة بيانات المراقبة لكل يوم في جدول منفصل موروث عن الجدول الأعلى ، وبدأت إزالة قيم المعلمات المتقادمة تحدث من خلال إزالة جميع الجداول المتقادمة في آن واحد ، وهو أمر أسهل بكثير بالنسبة لنظام إدارة قواعد البيانات بتكاليف العمالة. تم الحذف عن طريق استدعاء وظيفة مستخدم قاعدة البيانات كمعلمة مراقبة لخادم Zabbix في الساعة 2 صباحًا مع الإشارة إلى النطاق المقبول لتخزين الإحصاءات.
تثبيت وتكوين التقسيم ل PostgreSQL 10قم بتثبيت ملحق
pg_pathman وتكوينه من مستودع OS القياسي (للحصول على إرشادات حول إنشاء أحدث إصدار من الملحق من المصادر ، انظر في نفس مستودع التخزين على github):
يم تثبيت pg_pathman10
nano /var/pgsqldb/postgresql.conf
Shared_preload_libraries = 'pg_pathman' # مهم - هنا اكتب pg_pathman آخر مرة في القائمة
نقوم بإعادة تشغيل نظام إدارة قواعد البيانات (DBMS) ، وإنشاء ملحق لقاعدة البيانات وتكوين التقسيم (يوم واحد لبيانات المراقبة الأساسية و 3 أيام لبيانات المراقبة المجمعة - يمكن القيام بذلك ليوم واحد):
systemctl إعادة تشغيل postgresql-10.service
psql -d zabbix -U postgres
إنشاء تمدد pg_pathman ؛
# تكوين يوم واحد لجداول بيانات الرصد الأساسية
# 1552424400 - العد التنازلي كما الطابع الزمني يونيكس ، 86400 - ثانية في أيام
حدد create_range_partitions ('history'، 'clock'، 1552424400، 86400)؛
حدد create_range_partitions ('history_uint'، 'clock'، 1552424400، 86400)؛
حدد create_range_partitions ('history_text' ، 'clock' ، 1552424400 ، 86400) ؛
حدد create_range_partitions ('history_str' ، 'clock' ، 1552424400 ، 86400) ؛
حدد create_range_partitions ('history_log' ، 'clock' ، 1552424400 ، 86400) ؛
# تكوين لمدة ثلاثة أيام لجداول بيانات المراقبة المجمعة
# 1552424400 - العد التنازلي كما الطابع الزمني يونيكس ، 259200 - ثانية في ثلاثة أيام
حدد create_range_partitions ("الاتجاهات" ، "الساعة" ، 1545771600 ، 259200) ؛
حدد create_range_partitions ('trends_uint'، 'clock'، 1545771600، 259200)؛
إذا لم تكن هناك بيانات في أي من الجداول بعد ، فعند استدعاء دالة create_range_partitions ، يجب تمرير وسيطة إضافية واحدة p_count = 0_.استعلامات مفيدة لمراقبة الأقسام وإدارتها:
# قائمة عامة بالجداول المقسمة وتخزين التكوين الرئيسي:
حدد * من pathman_config ؛
# تمثيل مع جميع الأقسام الحالية ، وكذلك والديهم وحدود النطاق:
حدد * من pathman_partition_list ؛
# معلمات إضافية تتجاوز سلوك pg_pathman القياسي:
حدد * من pathman_config_params ؛
# نسخ المحتويات مرة أخرى إلى الجدول الأصل وحذف الأقسام:
حدد drop_partitions ('table_name' :: regclass، false) ؛
برنامج نصي مفيد لعرض الإحصاءات حول عدد الأقسام وحجمها:
SELECT nspname AS schemaname, relname, relkind, cast (reltuples as int), pg_size_pretty(pg_relation_size(C.oid)) AS "size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') and (relname like 'history%' or relname like 'trends%') and relkind = 'r'
الضبط التلقائي لحذف الأقسام القديمة (ahtung - دالة SQL كبيرة)لتكوين الحذف التلقائي للأقسام ، تحتاج إلى إنشاء وظيفة في قاعدة البيانات
(نص عريض ، لذلك اضطررت إلى إزالة تمييز بناء الجملة):
إنشاء أو استبدال وظيفة public.delete_old_partitions (history_days عدد صحيح ، اتجاهات عدد صحيح ، عدد صحيح str_days)
عوائد النص
اللغة plpgsql
كما $ وظيفة $
/ *
تحذف الدالة جميع الأقسام الأقدم من عدد الأيام المحدد:
history_days - للأقسام history_x ، history_uint_x
trends_days - بالنسبة للجدران trends_x ، trends_uint_x
str_days - للأقسام history_str_x ، history_text_x ، history_log_x
* /
إعلان clock_today_start int؛
إعلان clock_delete_less_history int = 0 ؛
إعلان clock_delete_less_trends int = 0 ؛
إعلان clock_delete_less_strings int = 0 ؛
clock_delete_less int = 0؛
أعلن التكرار int = 0 ؛
قم بتعريف result_str text = ''؛
إعلان النص buf_table_size ؛
إعلان نص buf_table_len ؛
يعلن النص_الفصل النص ؛
إعلان النص clock_max ؛
إعلان عن خطأ في كتابة النص ؛
قم بتعريف t_start timestamp = clock_timestamp ()؛
أعلن t_end الطابع الزمني ؛
بدأ
إذا كان $ 1 <= 0 ثم إرجاع "ups" ، فهذا خطأ: يجب أن تكون الوسيطة history_days قيمة عدد صحيح موجب "؛ نهاية إذا ؛
إذا كان $ 2 <= 0 ثم إرجاع "ups" ، هناك خطأ ما: يجب أن تكون وسيطة trends_days قيمة عدد صحيح موجب "؛ نهاية إذا ؛
إذا كان $ 3 <= 0 ثم عاود عمليات ، فهذا خطأ: يجب أن تكون الوسيطة str_days قيمة عدد صحيح موجب ؛ نهاية إذا ؛
clock_today_start = extract (epoch from date_trunc ('day'، now ()) :: :: int؛
clock_delete_less_history = extract (epoch from date_trunc ('day'، now ()) - ($ 1 :: text || 'days') :: interval) :: int؛
clock_delete_less_trends = extract (epoch from date_trunc ('day'، now ()) - ($ 2 :: text || 'days') :: interval) :: int؛
clock_delete_less_strings = extract (epoch from date_trunc ('day'، now ()) - ($ 3 :: text || 'days') :: interval) :: int؛
clock_delete_less = الأقل (clock_delete_less_history، clock_delete_less_trends، clock_delete_less_strings)؛
- لاحظ إشعار "clock_today_start٪ (٪)" ، to_timestamp (clock_today_start) ، clock_today_start؛
- لاحظ الإشعار "clock_delete_less_history٪ (٪)٪ أيام" ، to_timestamp (clock_delete_less_history) ، clock_delete_less_history ، $ 1 ؛
- لاحظ الإشعار "clock_delete_less_trends٪ (٪)٪ أيام" ، to_timestamp (clock_delete_less_trends) ، clock_delete_less_trends ، $ 2 ؛
- لاحظ إشعار "clock_delete_less_strings٪ (٪)٪ أيام" ، to_timestamp (clock_delete_less_strings) ، clock_delete_less_strings ، $ 3 ؛
بالنسبة لـ partition_name ، clock_max في قسم محدد ، range_max من pathman_partition_list حيث
range_max :: int <= الأعظم (clock_delete_less_history و clock_delete_less_trends و clock_delete_less_strings) و
(قسم :: نص مثل "السجل٪" أو القسم :: نص مثل "الاتجاهات٪") حسب القسم تصاعدي
أنشوطة
if (partition_name ~ 'history_uint_ \ d' و clock_max :: int <= clock_delete_less_history)
أو (partition_name ~ 'history_ \ d' و clock_max :: int <= clock_delete_less_history)
أو (partition_name ~ 'trends_ \ d' و clock_max :: int <= clock_delete_less_trends)
أو (partition_name ~ 'history_log_ \ d' و clock_max :: int <= clock_delete_less_strings)
أو (partition_name ~ 'history_str_ \ d' و clock_max :: int <= clock_delete_less_strings)
أو (partition_name ~ 'history_text_ \ d' و clock_max :: int <= clock_delete_less_strings)
ثم
التكرار = التكرار + 1 ؛
رفع إشعار '٪' ، تنسيق ('!!! حذف٪ s٪ s' ، partition_name ، clock_max) ؛
حدد max (reltuples :: int) ، pg_size_pretty (sum (pg_relation_size (pg_class.oid))) كـ "size" من pg_class حيث يعيد تسمية مثل partition_name || '٪' إلى buf_table_len صارمة ، buf_table_size ؛
إذا result_str! = '' ثم result_str = result_str || ''؛ نهاية إذا ؛
result_str = result_str || format ('٪ s (dt <٪ s، len٪ s،٪ s)'، partition_name، to_char (to_timestamp (clock_max :: int)، 'YYYY-MM-DD')، buf_table_len، buf_table_size)؛
تنفيذ التنسيق ('جدول الإفلات إذا كان موجودًا٪ s' ، partition_name) ؛
نهاية إذا ؛
حلقة النهاية ؛
إذا كان iterator = 0 ، ثم result_str = format ('لا توجد أقسام لحذفها أقدم ، ثم٪ s date' ، to_char (to_timestamp (clock_delete_less) ، 'YYYY-MM-DD')) ؛
else result_str = format ('أقسام٪ s المحذوفة في٪ s ثانية:' ، مكرر ، trunc (استخراج (بالثواني من (clock_timestamp () - t_start)) :: numeric، 3)) || result_str.
نهاية إذا ؛
- رفع إشعار '٪' ، result_str ؛
return result_str؛
استثناء عند الآخرين ثم
الحصول على تشخيص مكدس err_detail = PG_EXCEPTION_CONTEXT ؛
صيغة الإرجاع (عمليات الإغلاق ، خطأ ما:٪ s [err code٪ s] ،٪ s '، sqlerrm ، sqlstate ، err_detail) ؛
ينتهي.
وظيفة $ $ ؛
للاتصال تلقائيًا بوظيفة التقسيم التلقائي ، تحتاج إلى إنشاء عنصر بيانات واحد لمضيف خادم zabbix من نوع "مراقب قاعدة البيانات" بالإعدادات التالية:
- النوع: رصد قاعدة البيانات
- الاسم: delete_old_history_partitions
- المفتاح: db.odbc.select [delete_old_history_partitions، zabbix]
- تعبير sql: حدد delete_old_partitions (3 ، 30 ، 30) ؛
# هنا ، تشير معلمات استدعاء دالة delete_old_partitions إلى وقت التخزين بالأيام
# للقيم الرقمية والقيم الرقمية المجمعة وقيم السلسلة
- نوع البيانات: نص
- تحديث الفاصل الزمني: 0
- الفاصل الزمني للمستخدم: المقرر في h2
- فترة التخزين التاريخ: 90 يوما
- مجموعة عناصر البيانات: قاعدة البيانات
نتيجةً لذلك ، سوف نحصل على إحصائيات حول تنظيف الأجزاء من هذا النوع تقريبًا:
2019-09-16 02:00:00 ، تم حذف 3 أقسام في 0.024 ثانية: trends_78 (dt <2019-08-17 ، لين 1 ، 48 كيلو بايت) ، history_193 (dt <2019-09-13 ، لين 85343 ، 9448 كيلو بايت ) ، history_uint_186 (dt <2019-09-13 ، لين 27969 ، 3480 كيلو بايت)
! المهم بعد إعداد الحذف التلقائي للأقسام عبر عنصر البيانات ووظيفة المستخدم ، تحتاج إلى إيقاف تشغيل السجل والتنظيف في برنامج جدولة المهام Zabbix مدبرة: من
خلال عنصر القائمة zabbix ، حدد "الإدارة" -> "عام" -> حدد "محو السجل" من القائمة في الزاوية -> تعطيل جميع خانات الاختيار في قسم "التاريخ" و "ديناميات التغييرات". تغيير أنواع فهرس جداول المحفوظات إلى brin (ساعة) و btree-gin (itemid)
شكر خاص ل
erogov لسلسلة ممتازة من المقالات نظرة عامة على فهارس PostgreSQL .
وبالفعل فريق PostgresPRO بأكمله. .
, btree(itemid, clock) — , , «» , — 10 .
, , .أثناء اختبار مؤشرات مختلفة ، تم الكشف عن أنجح مزيج من المؤشرات: مؤشر برين في حقل الساعة ومؤشر btree-gin في حقل itemid لجميع جداول بيانات الرصد.يعد مؤشر brin مثاليًا لزيادة البيانات رتابة ، مثل الطابع الزمني لحقيقة حدث ما ، أي لسلسلة زمنية. ومؤشر btree-gin هو في الأساس مؤشر gin على أنواع البيانات القياسية ، والتي عادة ما تكون أسرع بكثير من مؤشر btree الكلاسيكي لأن لا يتم إعادة بناء مؤشر الجن أثناء إضافة قيم جديدة ، ولكن يتم تكميلها فقط. يتم وضع مؤشر btree-gin كملحق لـ PostgreSQL.فيما يلي مقارنة لسرعة أخذ العينات لاستراتيجية الفهرسة هذه والفهارس الموجودة في قاعدة بيانات Zabbix افتراضيًا. خلال اختبارات الحمل ، جمعنا البيانات لمدة ثلاثة أيام لثلاثة أقسام:لتقييم النتائج ، تم إجراء ثلاثة أنواع من الاستعلامات:- بالنسبة لعنصر معلمة محدد واحد ، بيانات الشهر الماضي ، في الواقع الأيام الثلاثة الأخيرة (إجمالي 1660 سجل)
شرح تحليل حدد * من history_uint حيث itemid = 313300
و clock> = extract (epoch from '2019-03-09 00:00:00' :: timestamp) :: int
وعلى مدار الساعة <= extract (epoch from '2019-04-09 12:00:00' :: timestamp) :: int؛
- لبيانات معلمة واحدة محددة لمدة 12 ساعة من يوم واحد (649 إدخالات في المجموع)
شرح تحليل حدد * من history_text حيث itemid = 310650
وعلى مدار الساعة> = استخراج (فترة من '2019-04-09 00:00:00' :: الطابع الزمني) :: int
وعلى مدار الساعة <= extract (epoch from '2019-04-09 12:00:00' :: timestamp) :: int؛
- لبيانات معلمة واحدة محددة لمدة ساعة واحدة (61 سجل في المجموع):
شرح تحليل عدد التحديد (*) من history_text حيث itemid = 336540
وعلى مدار الساعة> = استخراج (عصر من '2019-04-08 11:00:00' :: الطابع الزمني) :: int
وعلى مدار الساعة <= extract (epoch from '2019-04-08 12:00:00' :: timestamp) :: int؛
تم جدولة نتائج الاختبار أدناه:* يشار إلى الحجم بالميغابايت في ثلاثة أقسام** طلب من النوع الأول - بيانات لمدة 3 أيام ، طلب من النوع 2 - بيانات لمدة 12 ساعة ، من النوع 3 طلب - بيانات لمدة ساعةمن جدول المقارنة ، يمكن ملاحظة أنه بالنسبة لجداول البيانات الكبيرة مع عدد السجلات أكثر من 100 مليون ، يُرى بوضوح أن تغيير مؤشر btree القياسي المركب إلى مؤشرين هما brin و btree-gin له تأثير مفيد على تقليل حجم الفهارس وتسريع وقت تنفيذ الاستعلام.يتم عرض كفاءة الفهرسة والتقسيم أدناه في مثال طلب لإضافة سجلات جديدة إلى الجداول history_uint و trends_uint (تحدث الإضافات في متوسط قيم 2000 لكل استعلام).بتلخيص نتائج اختبارات التكوينات المختلفة للفهارس لجداول بيانات مراقبة نظام zabbix ، يمكننا القول إن التغيير المماثل في الفهرس القياسي لجداول بيانات مراقبة zabbix يؤثر بشكل إيجابي على الأداء الكلي للنظام ، وهو ما يحدث بشكل أكبر عند تجميع وحدات تخزين البيانات التي تزيد عن 10 ملايين. يجب أن تنسى التأثير غير المباشر لـ "تورم" فهرس btree القياسي افتراضيًا - تؤدي عمليات إعادة البناء المتكررة لمؤشر متعدد الجيجابايت إلى تحميل كبير للقرص الثابت (استخدام المتري ation) ، مما يؤدي في النهاية إلى زيادة وقت عمليات القرص ووقت انتظار الوصول إلى القرص من وحدة المعالجة المركزية (iowait metric).ومع ذلك، لكي يعمل فهرس btree-gin مع نوع بيانات bigint (in8) ، وهو عمود itemid ، تحتاج إلى تسجيل مجموعة من مشغلي bigint لمؤشر btree-gin.تسجيل عائلة مشغل bigint لمؤشر btree-gin/*
gin biginteger integer .
- gin int2, int4, int8,
bigint , bigint (<= 2147483647)
intger_ops, :
create index on tablename using gin(columnname int8_family_ops) with (fastupdate = false);
*/
-- btree_gin
CREATE EXTENSION btree_gin;
CREATE OPERATOR FAMILY integer_ops using gin;
CREATE OPERATOR CLASS int4_family_ops
FOR TYPE int4 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint4cmp(int4,int4),
FUNCTION 2 gin_extract_value_int4(int4, internal),
FUNCTION 3 gin_extract_query_int4(int4, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int4(int4,int4,int2, internal),
STORAGE int4;
CREATE OPERATOR CLASS int8_family_ops
FOR TYPE int8 USING gin FAMILY integer_ops
AS
OPERATOR 1 <,
OPERATOR 2 <=,
OPERATOR 3 =,
OPERATOR 4 >=,
OPERATOR 5 >,
FUNCTION 1 btint8cmp(int8,int8),
FUNCTION 2 gin_extract_value_int8(int8, internal),
FUNCTION 3 gin_extract_query_int8(int8, internal, int2, internal, internal),
FUNCTION 4 gin_btree_consistent(internal, int2, anyelement, int4, internal, internal),
FUNCTION 5 gin_compare_prefix_int8(int8,int8,int2, internal),
STORAGE int8;
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int4,int8),
OPERATOR 2 <=(int4,int8),
OPERATOR 3 =(int4,int8),
OPERATOR 4 >=(int4,int8),
OPERATOR 5 >(int4,int8);
ALTER OPERATOR FAMILY integer_ops USING gin add
OPERATOR 1 <(int8,int4),
OPERATOR 2 <=(int8,int4),
OPERATOR 3 =(int8,int4),
OPERATOR 4 >=(int8,int4),
OPERATOR 5 >(int8,int4);
يعيد هذا البرنامج النصي توزيع جميع الفهارس في قاعدة بيانات PostgreSQL لـ Zabbix من التكوين الافتراضي إلى التكوين الأمثل الموضح أعلاه./*
*/
--
drop index history_1;
drop index history_uint_1;
drop index history_str_1;
drop index history_text_1;
drop index history_log_1;
-- PK
-- ( , )
alter table trends drop constraint trends_pk;
alter table trends_uint drop constraint trends_uint_pk;
-- bree-gin itemid
-- btree-gin bigint
-- https://habr.com/ru/company/postgrespro/blog/340978/#comment_10545932
-- create extension btree_gin;
create index on history using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_uint using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_str using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_text using gin(itemid int8_family_ops) with (fastupdate = false);
create index on history_log using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends using gin(itemid int8_family_ops) with (fastupdate = false);
create index on trends_uint using gin(itemid int8_family_ops) with (fastupdate = false);
-- bree-gin itemid
-- brin 128 ,
-- ,
-- https://habr.com/ru/company/postgrespro/blog/346460/
create index on history using brin(clock) with (pages_per_range = 128);
create index on history_uint using brin(clock) with (pages_per_range = 128);
create index on history_str using brin(clock) with (pages_per_range = 128);
create index on history_text using brin(clock) with (pages_per_range = 128);
create index on history_log using brin(clock) with (pages_per_range = 128);
create index on trends using brin(clock) with (pages_per_range = 128);
create index on trends_uint using brin(clock) with (pages_per_range = 128);
بالنسبة لمؤشر برين لحجم البيانات الخاص بنا بكثافة 100 طن من المعلمات في الدقيقة (100 طن في التاريخ و 100 طن في history_uint) ، لوحظ أن الفهرس يعمل على جداول بيانات المراقبة الأولية بحجم منطقة يبلغ 512 صفحة ضعف سرعة من حجم قياسي من 128 صفحة ، ولكن هذا هو فردي ويعتمد على حجم الجداول وتكوين الخادم. في أي حال ، يشغل مؤشر brin مساحة صغيرة جدًا ، ولكن يمكن زيادة سرعته قليلاً عن طريق ضبط حجم المنطقة ، ولكن بشرط ألا يتغير معدل تدفق البيانات كثيرًا.نتيجة لذلك ، تجدر الإشارة إلى وجود قيود مرتبطة بهندسة Zabbix نفسها: في علامة التبويب "البيانات الحديثة" ، يتم جمع القيمتين الأخيرتين لكل معلمة مع مراعاة التصفية. لكل معلمة ، يتم طلب القيم في قاعدة البيانات بشكل منفصل. لذلك ، كلما تم تحديد هذه المعلمات ، سيتم تشغيل الاستعلام لفترة أطول. يتم البحث عن أحدث البيانات عندما يتم تعيين فهرس btree (itemid ، تنازلي الساعة) على جداول المحفوظات مع الفرز العكسي حسب الوقت ، لكن الفهرس نفسه بالطبع "يتضخم" على القرص ويبطئ بشكل غير مباشر قاعدة البيانات بشكل عام ، مما يسبب مشكلة ، المذكورة أعلاه.لذلك ، هناك ثلاث طرق:- « » 100 (.. , « » )
- Zabbix , , « »
- اترك الفهارس كما هي افتراضيًا ، ونقصر أنفسنا على التقسيم فقط للحصول على تحديدات كبيرة جدًا في علامة التبويب البيانات الحديثة في نفس الوقت لمجموعة متنوعة من المعلمات (ومع ذلك ، فقد لوحظ أن خادم الويب Zabbix لا يزال لديه حد لعدد قيم المعلمات المعروضة في وقت واحد في علامة التبويب "البيانات الحديثة" - لذلك ، عندما أحاول عرض 5000 قيمة ، حسبت قاعدة البيانات النتيجة ، لكن تعذر على الخادم إعداد صفحة الويب وعرض مثل هذه الكمية الكبيرة من البيانات).
جمع وتحليل إحصائيات تنفيذ الاستعلام pg_stat_statements
Pg_stat_statements هو امتداد لجمع الإحصاءات حول أداء الاستعلام عبر الخادم بأكمله. تتمثل ميزة هذا الامتداد في أنه لا يحتاج إلى جمع سجلات PostgreSQL وتحليلها.باستخدام ملحق pg_stat_statementspsql:
CREATE EXTENSION pg_stat_statements;
postgresql.conf:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000 # sql , ( );
pg_stat_statements.track = all # all - ( ), top - /, none -
pg_stat_statements.save = true #
:
SELECT pg_stat_statements_reset();
:
select substring(query from '[^(]*') as query_sub, sum(calls) as calls, avg(mean_time) as mean_time from pg_stat_statements where query ~ 'insert into' or query ~ 'update trends' group by substring(query from '[^(]*') order by calls desc
لمراقبة محركات الأقراص الثابتة في Zabbix ، يتم توفير المعلمتين vfs.dev.read و vfs.dev.write فقط. لا توفر هذه الخيارات معلومات حول استخدام القرص. المعايير المفيدة لإيجاد مشاكل مع أداء محركات الأقراص الصلبة هي عامل الاستخدام ، وانتظار وقت الاستعلام ، وتحميل قائمة انتظار تحميل القرص.وكقاعدة عامة ، يرتبط التحميل على القرص العالي بميزة iowait عالية لوحدة المعالجة المركزية نفسها ومع زيادة وقت تنفيذ استعلامات sql ، والتي تم العثور عليها أثناء اختبار التحمل لخادم zabbix بتكوين قياسي دون التقسيم وبدون إعداد فهارس بديلة. يمكنك إضافة هذه المعلمات لرصد محركات الأقراص الصلبة باستخدام الخطوات التالية ، التي تم عرضها في مقال من صديقlesovsky ومحسّنة: يتم الآن تجميع معلمات iostat بشكل منفصل لكل قرص في معلمة وقت json ، حيث ، وفقًا لإعدادات ما بعد المعالجة ، يتم تحليلها بالفعل في معلمات المراقبة النهائية.أثناء تعليق طلب السحب ، يمكنك محاولة توسيع مراقبة معلمات القرص وفقًا للتعليمات المفصلة من خلال مفترقي .بعد كل الخطوات الموضحة ، يمكنك إضافة رسم بياني مخصص مع iowait cpu ومعلمات الاستفادة من قرص النظام والقرص من قاعدة البيانات (إذا كانت مختلفة) إلى لوحة مراقبة خادم Zabbix الرئيسية. قد تبدو النتيجة هكذا (sda هو القرص الرئيسي ، sdc هو القرص مع قاعدة البيانات):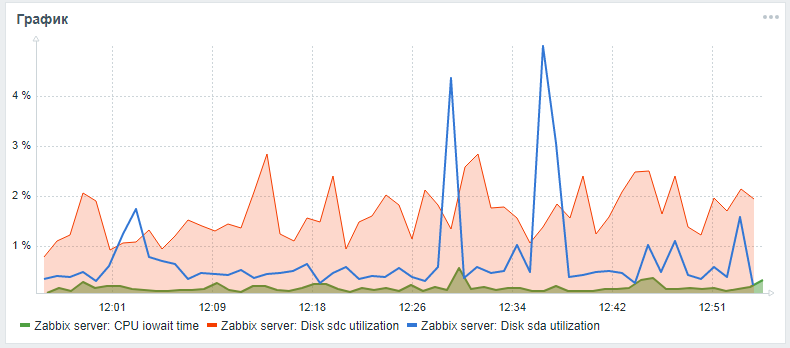
تحسين أداء الأجهزة
بعد إعداد نظم إدارة قواعد البيانات والفهرسة والتقسيم ، يمكنك المتابعة إلى التدرج الرأسي - لتحسين خصائص أجهزة الخادم: إضافة ذاكرة الوصول العشوائي وتغيير محركات الأقراص إلى الحالة الصلبة وإضافة مراكز المعالج. هذه زيادة مضمونة في الأداء ، لكن من الأفضل القيام بذلك فقط بعد تحسين البرنامج.إنشاء الكتلة الموزعة
بعد التدرج الرأسي المعتدل ، تحتاج إلى بدء أفقي - إنشاء كتلة موزعة: إما حادة أو تكرار العبد الرئيسي. ولكن هذا موضوع منفصل ومقال لمقال منفصل (كيفية تشكيل مجموعة من القرف والعصي) ، بالإضافة إلى مقارنة تقنية تحسين قاعدة البيانات Zabbix الموصوفة أعلاه باستخدام pg_pathman والفهرسة باستخدام تقنية تطبيق ملحق TimescaleDB.في هذه الأثناء ، يمكن للمرء أن يأمل فقط في أن تكون المادة الواردة في هذه المقالة مفيدة وغنية بالمعلومات!