لقد تغيرت التنمية كثيرا في السنوات الأخيرة. بدلاً من التطبيقات المتجانسة ، جاءت الخدمات الدقيقة والوظائف. تدهورت قواعد البيانات من الوحوش الصناعية العالمية إلى أهداف ضيقة. غير عامل الميناء رأيه بشأن النشر. لكن هل تغيرت فكرتنا عن السجلات؟
كانت إحدى السجلات الكبيرة في Yandex.Verticals هي السجلات - 18 تيرابايت في اليوم و 250،000 في الثانية ، يتم كتابة كل شيء على الملفات. السجلات غير متجانسة نظرًا لوجود العديد من اللغات: Scala و Java و Python و Go. ثم يتم جمعها بواسطة Fluent Bit ، يكتب في Kafka ، يعمل مناولو الآلات على آلة حديد واحدة ، ويتجمعون من Kafka ويكتبون كل شيء على القرص. علاوة على ذلك ، هذه هي النسخة الثانية من السجلات.

نتيجة لذلك ، تنشأ مشكلة بحث طويلة. يتم البحث في هذه السجلات باستخدام grep. في بعض الخدمات ، يمكن أن يصل grep إلى ساعات. إذا كنت تواجه مشكلات في الإنتاج ، فلن تبحث عن سجلاتك لساعات. لحل المشكلة ، قررت ياندكس كتابة دراجة تسليم السجل الخاصة بهم للبحث. ما حدث من هذا ، سوف يخبر
أليكسي دانيلوف (
danevge ) - المطور لفريق البنية التحتية في Yandex.Verticals. تطوير وكتابة ودعم مشاريع auto.ru و Yandex.Real العقارية.
تنويه. يتحدث المقال عن التطوير الحديث ومناسب لهندسة الخدمات الميكروية. يتم عرض المنتجات المختلفة هنا - هذه هي الأدوات التي يتم استخدامها في Yandex.Verticals. في ظل ظروف أخرى ، تكون نظائرها أكثر نجاحًا ، ولكنها تؤدي نفس الوظائف تقريبًا. المذكرة. المقال عبارة عن نسخة موسعة من تقرير Alexey Danilov بعنوان "ليست هناك حاجة لسجلات" في RIT ++ 2019 DevOps Conf ، والذي تم تعديله بطريقة أسلوبية واستكماله بمواد جديدة. يمكنك العثور على تسجيل فيديو لخطاب أليكسي على الرابط على قناتنا على YouTube.
يضم فريق Yandex.Vertical 300 شخص ، حوالي 100 منهم من المطورين. في مجال التطوير ، لا نختلف عن معظم الشركات التي تنشئ حلول منتجاتها الخاصة. تقوم Microservices ، كل شخص يعيش في Docker ، وهي مجموعة متجانسة في PHP بتجميع الغبار في زاوية مظلمة ، يتم نشرها عبر Hashicorp Nomad ونحتفظ بحديقة للحيوانات: Scala و Java و Go و Node.js و Python.
واحدة من مشاكل البنية التحتية الكبيرة في Yandex.Verticals هي سجلات التطبيق. عندما تعاملنا مع هذه المشكلة بجدية ، استخدمنا الإصدار الثالث من التجميع والمعالجة. مبسطة ، عملت مثل هذا:
- كتب التطبيقات إلى الملفات.
- بطلاقة قراءة الملفات وإرسالها سطرا سطرا إلى كافكا filebeat ؛
- على آلة حديد مخصصة ، كان هناك تطبيق يقرأ موضوع كافكا وكتب إلى الملفات الموجودة على القرص.
في الموسم الحار ، كان لدينا 18 تيرابايت من جذوع الأشجار في اليوم ، أو 250 ألف خط في الثانية. هذا هو كمية كبيرة جدا ، مما يعقد العمل مع هذه البيانات. الطريقة الوحيدة لتحليل ذلك هي grep ، حيث يتم تخزين كل شيء في ملفات. للتطبيقات الكبيرة ، قد يستغرق التحليل ساعات. لمشاكل في الإنتاج ، لم يكن لديك هذا الوقت.
لم تكن الحلول الجاهزة مناسبة للسعر أو الموارد أو السرعة. لم يتمكنوا من التعامل مع تدفقنا بشكل مقبول. من الصعب حتى حساب عدد محاولات طهي Elasticsearch. أفترض أننا لا نعرف كيف نطبخها. ولكن هذا ليس هو ما نحتاج إليه ، إذا كنا نستخدمه كمستودع للسجلات ، فنحن نحتاج إلى قدرات خاصة (مهارات).
في هذه الحالة ، قررنا تطبيق نظامنا الخاص لجمع السجلات وتحليلها.
دراجة هوائية
 ملاحظة: إذا لم تكن الدراجة التالية مثيرة للاهتمام ، فتابع فورًا إلى قسم "الكتابة".
ملاحظة: إذا لم تكن الدراجة التالية مثيرة للاهتمام ، فتابع فورًا إلى قسم "الكتابة".شكل
نحن نستخدم العديد من الثابتة والمتنقلة والحب microservices. للعمل مع السجلات ، شكلنا شكل JSON الخاص بنا بشكل موحد. ويغطي معظم الاحتياجات لمزيد من العمل مع سجلات.
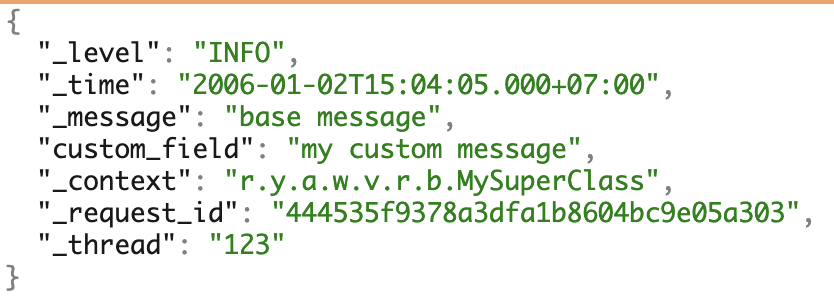 مثال على السجلات مع جميع الحقول الممكنة.
مثال على السجلات مع جميع الحقول الممكنة.سائق سجل عامل الميناء
لجمع السجلات ، كتبنا
برنامج تشغيل سجل عامل ميناء خاص بنا - تطبيق على Go. يتم تجميعها بطريقة خاصة ، يتم تسليمها بواسطة أوامر المكون الإضافي docker ، المخزنة في السجل ، ويتم تشغيلها في مثيل واحد يعمل Docker.
نظرًا لأن أي مشاكل في برنامج تشغيل السجل يمكن أن تؤثر سلبًا على كل العمل ، فقد حاولنا كتابة تطبيق بسيط. يستمع برنامج التشغيل الخاص بنا إلى stdout من الحاوية ويمرر السجلات على الفور إلى التطبيق القريب. إنه يتعامل بالفعل مع الجزء الأكثر تعقيدًا من التسليم.
المشاكل
سأذكر بشكل منفصل مشاكل تحديث إصدار برنامج تشغيل سجل عامل ميناء.
 لقطة شاشة من جرافانا الداخلية.
لقطة شاشة من جرافانا الداخلية.على اليسار هي نسبة الإصدارات المثبتة إلى الأجهزة. الآن يتم تثبيت ثلاثة إصدارات على جميع الأجهزة - لا تضيع أي سيارات في أي مكان ولا توجد عمليات تثبيت غير ضرورية. على اليمين هو عدد الحاويات التي تستخدم هذا أو ذاك الإصدار.
لا يمكن لبرنامج تشغيل عامل ميناء الذهاب والتحديث على الفور. للقيام بذلك ، سيكون عليك إعادة تشغيل جميع الحاويات وجميع الخدمات ، مما قد يؤدي إلى حدوث مشاكل. لذلك ، لتثبيت الإصدار الجديد ، ننتظر حتى تقوم جميع الحاويات بتحديث نفسها.
مخطط عام
النظر في المخطط العام لنظام جديد لجمع وتسليم السجلات. تفاصيل أخرى ليست مثيرة للاهتمام للغاية.
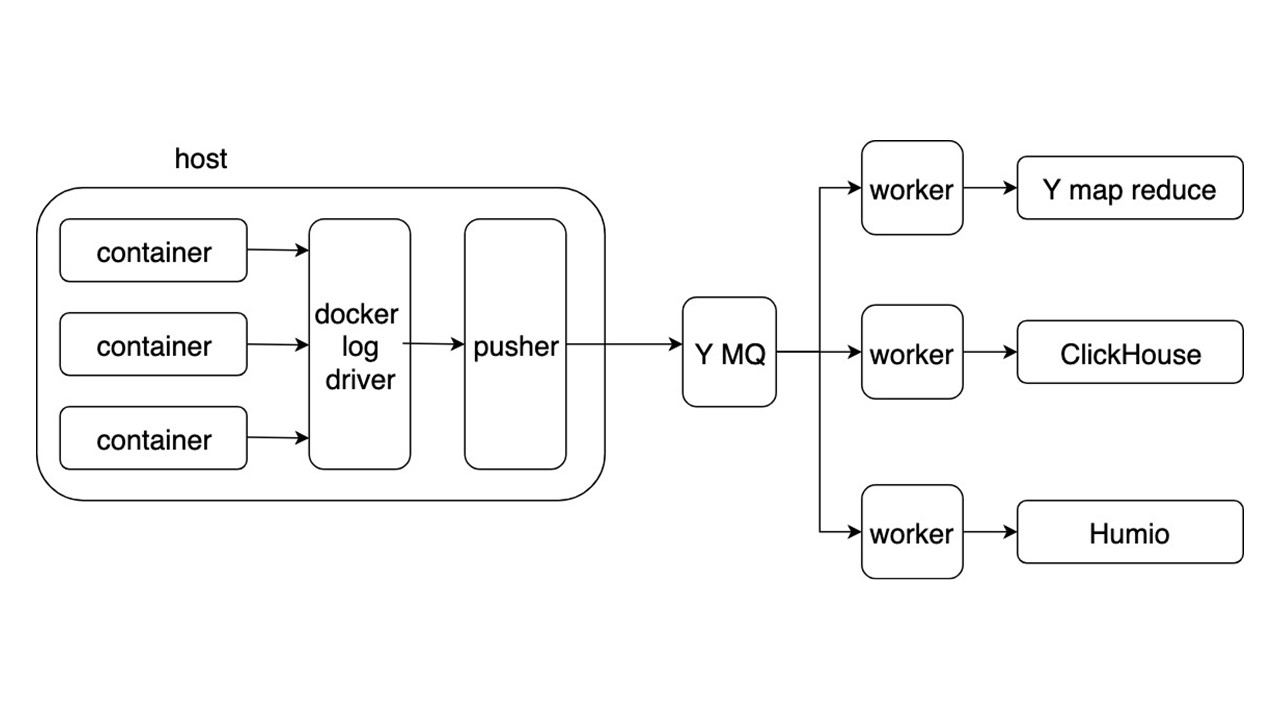
تطبيقات كتابة السجلات في شكل JSON في stdout. Docker يستمع إلى توجيه الإخراج من الحاوية ويعيد توجيهه إلى برنامج التشغيل Docker. يقوم برنامج التشغيل Docker بقراءة وإعادة تذويب كل شيء في Pusher بشكل غير متزامن.
تاجر مخدرات يقف على كل سيارة حديدية. إنه يستعد ويشبع ويقلب ويدفع سجلات الدخول إلى قائمة انتظار الرسائل في ياندكس. يتم تحليل دفق السجل من MQ بواسطة ثلاثة أنواع من العمال ويتم كتابته إلى المستودعات.
هناك ثلاثة مستودعات لتسجيل السجلات.
- ياندكس mapReduce لتخزين وتحليل سجلات على مدى فترة طويلة من الزمن. هذا هو التناظرية Hadoop.
- ClickHouse لتخزين السجلات خلال اليوم الأخير.
- Humio (كتجربة) لتخزين سجلات اليوم الأخير.
ربح
يسمح لك التنسيق العام بكتابة السجلات ومعالجتها بنفس الطريقة. جمع السجل تلقائي ، دون استخدام قرص ، ويكون التسليم في منطقة ثانيتين. عمليات البحث الرئيسية من 2 ثانية إلى 5 ثوان. التخزين والاسترجاع على مدى فترة طويلة من الزمن.
بالنسبة للمجلدات الأصغر حجمًا ، فكر في بدائل: Humio و Splunk و مرنة. آخر اثنين من السائقين عامل الميناء الرسمي. إذا كنت تعيش في AWS ، فهذا هو Amazon CloudWatch.
سحابة الأمازون
يتعامل Amazon CloudWatch مع المقاييس والأحداث والسجلات. إنه لا يبحث عن الأخير ، ولا يعطي عناصر بحث فائقة ولا يعالجها بالشكل المعتاد. تقوم Amazon CloudWatch بمعالجة السجلات والتحليلات والمرشحات والعروض على الرسوم البيانية.
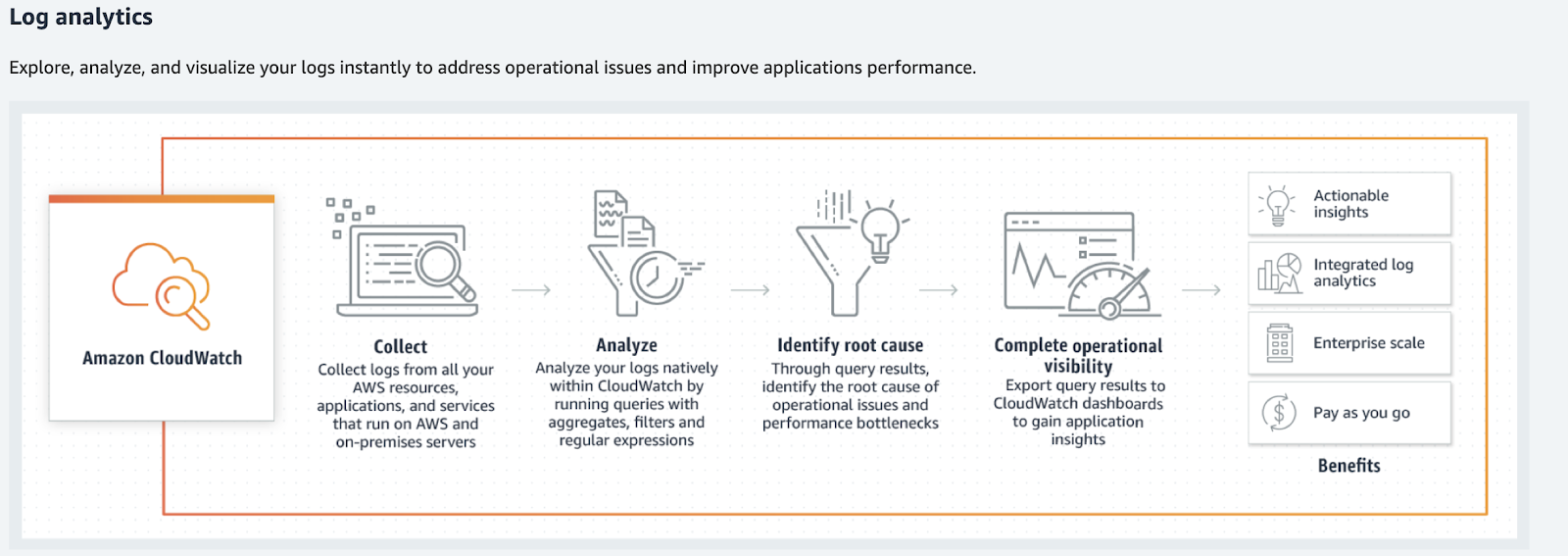 تقوم Amazon CloudWatch بتحويل السجلات إلى مقاييس ورسومات.
تقوم Amazon CloudWatch بتحويل السجلات إلى مقاييس ورسومات.ما يجب القيام به مع سجلات؟
العودة إلى دراجتنا - هل تلبي جميع الحالات؟ لا ، يتيح لك حلنا العثور على السجلات ، ولكنها تتطلب تجانسًا أكبر بكثير من المعلومات وأنواعها. تستخدم السجلات في حالات أكثر من ذلك بكثير.
بمجرد قيامك بتجميع السجلات ، ستكون الجملة التالية: "دعنا نحلل شيئًا ، ونعالجه بطريقة ما ، ونكتبه في مكان ما ونبدأ في العرض على المخططات ، على لوحات المعلومات". هذه هي الطريقة إلى الجحيم. خاصة إذا كنا نتحدث عن الأدوات الشائعة.
إذا كنت تتخيل السجلات باعتبارها فوضى معينة أو سجل أحداث لأي بيانات ، فلن تعمل.
ستكون هذه فوضى كبيرة من المعلومات التي لا يمكن معالجتها. ستبدأ اللعبة في إضفاء الطابع الرسمي على السجلات: "دعنا نكتب هذه السطور بتنسيق خاص حتى يكون من المناسب تحليلها لاحقًا!" هذا لا يعمل أيضا. صدقنا ، حاولنا.
الكتابة
إذا قمت بتقسيم السجلات إلى أنواع وقمت بمعالجتها بشكل منفصل ، فيمكنك العثور على أدوات تجعل العمل معها أسهل. العمل لم يعد كما هو الحال مع سجلات ، ولكن كما هو الحال مع البيانات المفيدة - مثل هذا العمل هو أكثر شفافية ومريحة. يمكن طرح بعض أنواع السجلات تمامًا.
فقط في القضية
هذا النوع من سجلات "ليكون" هو المفضل لدي. إذا كان من المستحيل الإجابة بوضوح عن سبب الحاجة إلى هذا الخط أو ذاك ، فعندئذٍ هم. يمكن أيضًا تسمية هذا النوع "سجلات فقط في حالة".
// validate customer func Validate(customer Customer) { // ??? log.debug(“Validate customer %v”, customer) … log.Error(“Customer not valid %v. Reason: %s”, ...) …. }
السجلات ليست تعليقات يمكن حذفها. يعد هذا جزءًا من التعليمات البرمجية الأكثر صعوبة في تعديلها وصيانتها وحذفها.
في أفضل الأحوال ، يمكن أن يتحول مثل هذا السجل إلى تصحيح أو تتبع. هذا النوع
يكتنف الرمز . نظرًا للتسجيل المتسارع ، يمكنني الحصول على بيانات شخصية وكلمات مرور وملفات تعريف ارتباط للمستخدمين.
الطريقة الصحيحة هي
رميهم ونسيانهم . ولكن بعد ذلك نواجه مشكلة جديدة. كيفية تحليل الموقف مع وجود خطأ؟
خطأ فادح / خطير
بادئ ذي بدء ، فإننا نعتبر الأخطاء الحرجة فقط. هذه أخطاء بسبب المستخدمين والمطورين الذين يعانون. الأول - عندما لا يستطيعون إكمال العملية. الثاني - عندما تحتاج إلى إجراء تصحيحات باليد.
لماذا سجلات لا يصلح؟
لا استجابة سريعة . إذا علم فريق التطوير بالخطأ من المستخدمين من خلال الدعم أو من Twitter ، فقد حان الوقت لتغيير شيء ما.
لا يوجد سياق . سطر منفصل من سجل الخطأ لا طائل منه. علينا أن نجمع السياق شيئا فشيئا. ومع ذلك ، قد لا يكون هذا كافياً ، لأن هذا هو سياق العملية ، وليس الخطأ.
لا توجد صورة كبيرة . لا إجابة على الأسئلة:
- عدد مرات حدوث مثل هذا الخطأ ؛
- حدث على النسخ المتماثلة المتبقية من الخدمة ؛
- هل كان من قبل؟
لإصلاح هذه المشكلات ، استخدم أداة مناسبة ، على سبيل المثال ،
sentry.io . يتيح لك العمل مع معلومات الخطأ التمثيلية (السياقية) الكاملة مع
alerting rule القابلة للتخصيص. يصف
موقع الويب sentry الاختلافات في السجلات من استخدام sentry.io.
ليس خطأ فادح
ألقينا الأخطاء القاتلة والحرجة والآن يتم كتابتها في ترقب. ولكن كانت هناك أخطاء داخلية - مكتبات مختلفة أو إجابات من خدمات الجهات الخارجية.
مثال جيد هو محاولة ناجحة. لنفترض أن الخدمة A تحولت إلى الخدمة B ، ولكن نظرًا لمشاكل الشبكة ، لم تتمكن من الحصول على إجابة. بعد الخطأ ، تحولت الخدمة A مرة أخرى إلى الخدمة B وحصلت على استجابة صالحة. هل الخطأ في المكالمة الأولى حرج؟ لا. في هذه الحالة ، تم إكمال العملية بنجاح ، وتمكن المستخدم من استخدام الخدمة.
إذا لم تكن مثل هذه الأخطاء ضرورية لعمل الخدمة ولم تؤثر على المستخدم بتكرار نادر ، فهذه ليست أخطاء على الإطلاق. هذا تدهور في الخدمة ، على الرغم من أن الاستجابة للمستخدم جاءت بعد 50 مللي ثانية. يشير هذا النوع من السجل إلى التحذيرات - تحذير.
تحذير
التنبيهات هي معلومات حول تدهور الخدمة.
سنرى هنا نفس المشكلات المتأصلة في الأخطاء الحرجة ، ولكن مع الحجز. إن رد الفعل على حدث فردي ليس مهمًا - فكميته مهمة بمرور الوقت.
النظر في مثال حيث لا يمكن لخدمة استرداد إدخال ذاكرة التخزين المؤقت والوصول إلى التخزين البارد. إذا حدث هذا مرة واحدة في الدقيقة ، فيمكن أن يؤخذ ذلك من أجل التشغيل العادي للخدمة.
الانبعاثات النادرة ليست مهمة .
ولكن في الوقت نفسه ، تحتاج إلى أداة لعرض الصورة الكبيرة ، تحتاج
إلى تحليل في الوقت الفعلي . لتتبع التغييرات على مدى فترة طويلة من الزمن ، سيكون من الجيد أن يكون لديك
تحليل بأثر رجعي أيضًا. يمكن أن يؤثر التدهور فوق مستوى معين (عتبات) سلبًا على المستخدمين - تحتاج إلى
رد فعل مع تدهور شديد .
نحن لسنا بحاجة إلى سجلات تحمل علامة تحذير ، ولكن في قياسات التدهور.
أداة جمع البيانات المترية الأكثر شيوعًا هي Prometheus ، ويمكنك استخدام Grafana للتصور. إذا كنت بحاجة إلى سياق كبير (مثل الخطأ) ، فستفعل نفس Sentry ، ولكن مع إيقاف تشغيل التنبيهات. ومع ذلك ، في معظم الحالات سيكون هناك سياق كاف. سيتم استخدامه للرسوم البيانية - تسميات بروميثيوس.
أمثلة على ذلك.
وقعت ثلاثة أحداث في
user_service . إنها تؤثر على تشغيل الخدمة: طلب طويل إلى قاعدة البيانات ، والوصول المتكرر إلى
service_b service API ولم يتم العثور على حقوق المستخدم في ذاكرة التخزين المؤقت. سيتم تكوين المخططات والتنبيهات على أنها مهمة لمطوري الخدمة ، وذلك بفضل السياق.
تتبع
هذا هو أول شيء نبدأ به إذا اخترنا المسار الذي تحتاج إلى تحليل السجلات فيه. هذه المعلومات في السجلات بحد ذاتها عديمة الفائدة ، لأنك تحتاج إلى إنشاء سلاسل مكالمات ، راجع البيانات داخل الطلبات ، والأخطاء في سلاسل المكالمات ، وأوقات الاستجابة ، وعدد RPS.
هناك أدوات رائعة للبحث عن المفقودين - Jaeger أو Zipkin. أوصي باستخدام OpenTracing ، اللذين يدعمهما كلاهما.
يمكنك جمع التتبع من ثلاثة مصادر.
- إذا كنت تستخدم الموازنات المشتركة ، فقم بتحليل السجلات منها وأرسلها إلى جايجر.
- الخدمات نفسها ، إذا تلقوا عناوين من خلال خدمة اكتشاف واذهب مباشرة. في هذه الحالة ، يتم إرسال التتبع من الخدمات مباشرة إلى Jaeger.
- شبكة خدمة ذكية. إنه يعرف كيفية جمع التتبع وإرساله ، على سبيل المثال ، Istio.
المعلومات الأولية
هذه المعلومات تتعلق بمكالمات خدمة API أو إطلاق Cron أو استعلامات قاعدة البيانات أو مكالمات إلى خدمات أخرى.
{ "_message": "Request: ...; request_id: ...,... ", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcHandler", "_tread": "785534" }
تنتمي هذه المعلومات إلى كتلة "فقط في حالة" ، لكنها منفصلة لأنها أكثر شيوعًا. هذه المعلومات مطلوبة لتحليل الخطأ
ويمكنك رميها بعيدًا .
إذا كانت المعلومات المتعلقة باستدعاءات الطرق الداخلية مهمة للغاية ولا يمكنك الاستغناء عنها ، حتى مع السياق الذي تم جمعه في حالة حدوث خطأ ، فإن الأمر يستحق إجراء استدعاءات أساليب القياس كتتبع.
وقت التنفيذ
تدور هذه المعلومات حول وقت تنفيذ الطرق ، واجهات برمجة التطبيقات ، واستعلامات قاعدة البيانات أو الخدمات الأخرى.
{ "_message": "Get customer 12ms", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcCustomerRepository", "_tread": "785534" }
لا توجد قيمة في السجلات منه ، لأنك تحتاج إلى تحليل هذه المعلومات ، وعرضها على الرسوم البيانية ، وتكوين الحدود. يجب استبدال هذا النوع من السجلات
بمقاييس ، على سبيل المثال ، في Prometheus.
معلومات العمل
هذه المعلومات مطلوبة لتحليلات الأعمال وتحليل سلوك العملاء والحسابات المالية. في هذا المكان ، استخدمنا تاريخيا النهج المعاكس - سجلات التحليل. ولكن هذا مثال جيد على ما يمكن أن تتحلل به سجلات التطبيق إذا كنت تعمل معهم بهذه الطريقة.
بالنسبة للسجلات التي تحتوي على بيانات العمل ، تم تشكيل اتفاقيات مع الحقول الثابتة بتنسيق TSKV ، والتي تعد ضرورية للتحليلات. كتب التطبيقات سجلات العمل إلى ملف مخصص. ثم تمت قراءة السجلات وإرسالها سطراً سطراً إلى MQ ، وقام تطبيق منفصل بمعالجتها وكتابتها في قاعدة البيانات. هذا مثال على ما يتحول إليه أي تحليل.
لن تعمل على تحليل الدفق الكامل للسجلات على أمل أن تتقارب البيانات.
الاتفاقيات والأشكال والقواعد ومتطلبات الموثوقية آخذة في الظهور. هذا بالفعل يشبه إلى حد ما سجلات التطبيق. في هذه الحالة ، يصبح السجل قائمة انتظار تسليم البيانات مع كافة المتطلبات التالية لـ MQ. من الملاحظ أن الوسيطة في شكل سجل لا لزوم لها هنا.
الحل الجيد هو إرسال هذه البيانات مباشرة إلى MQ. بالفعل ستتم معالجتها وتخزينها في التخزين المناسب واستخدامها من قبل فريق التحليلات. على سبيل المثال ، للعرض نستخدم Tableau.
أداء
نادراً ما يتم العثور على هذا النوع من السجل في سجلات التطبيق ويتم جمعه غالبًا كمقياس. بشكل منفصل ، أضيف أنه لجمع المقاييس الأساسية الخاصة باللغة ، يكفي استخدام مكتبة بروميثيوس. ستقوم افتراضيًا بجمع كل ما تصل إليه. تكلفة إضافة هذه المقاييس صغيرة.

نتيجة الكتابة
بعد فرز السجلات حسب النوع ، يمكننا التقاط أدوات أكثر قوة للعمل معهم. لا توجد أنظمة معقدة أو تقنيات فضائية مثل Amazon ، لا يوجد شيء لا يمكن رفعه غدًا. ربما لديك بالفعل بعض هذه الأنظمة أو نظائرها: يقوم Sentry بجمع الغبار في مكان ما ، يعمل Prometheus في مكان ما.

لا تكمن المشكلة في التكنولوجيا ، ولكن في المصيدة المعرفية عندما نثق بالسجلات كوسيلة لتمثيل موثوق لحالة نظامنا. هذا ليس كذلك ، سجلات هي مجموعة من الأحداث الفوضوية.
هناك استثناء - سجلات التصحيح ، والتي يمكن استخدامها في حالات نادرة.
سجل التصحيح
يجب أن تكون سجلات التصحيح معلومات مفصلة. يجب ألا يكرروا ما يتم إرساله بالفعل إلى الأنظمة التي وصفناها أعلاه. هذا النوع موجود لتحليل الحالات الخاصة. على سبيل المثال ، يحدث خطأ غير مفهوم في الإنتاج ، وفي الوقت الحالي لا يتضح من خلال المقاييس ما يحدث.
قم بتشغيل سجلات تصحيح الأخطاء ساخنًا ، دون إعادة تشغيل الخدمة . بما أننا نتحدث عن العديد من الخدمات ، فلن يكون هناك الكثير منها. ليست هناك حاجة البنية التحتية المتطورة. يكفي كومة ELK دون "إعداد" معقدة. من المنطقي أيضًا إضافة تنبيه إلى Sentry مع كل السياق الضروري.
يمكن استخدام سجلات التصحيح للتطوير . ولكن يتم استبدالها تمامًا بتصحيح الأخطاء.
لتلخيص
لقد كتبنا لدينا تسليم سجل الدراجة للبحث . لم نرضي عملاء الخدمة - لقد أتوا إلينا جميعًا لتحليلهم وجمعهم وتجميعهم في مكان ما. يمكن تجنب ذلك - ليست هناك حاجة لأنظمة معالجة السجل المعقدة.
السجلات الأولية غير مجدية ، ولكن يمكن تحويلها إلى مقاييس مفيدة.
يكفي إنشاء بنية أساسية لتقديم مقاييس وبيانات مفيدة حول الخدمات. نتيجة لذلك ، ستظهر مقاييس مفيدة تتحدث عن الخدمات وتعرض بشفافية كل ما يحدث لها.
يجب أن تحتوي الأخطاء على سياق الخطأ نفسه.
هذا سوف يساعد على التغلب عليه وإصلاحه على الفور.
يجب أن تؤدي الأخطاء والتدهور إلى اتخاذ إجراء ، حتى يتعرف المطورون على الفور على المشكلات وحلها حتى قبل طلبات المستخدم الغاضبة.
ستجعل الأدوات المناسبة العمل مع خدماتك أكثر متعة وشفافية . Debug لديه مكان ليكون ، ولكن عليك أن تكون صارمة مع ذلك.
في HighLoad ++ 2019 في نوفمبر ، سيكون هناك قسم DevOps - 13 تقريرًا عن الأحمال في AWS ، ونظام مراقبة في Lamoda ، وناقلات لتسليم النماذج ، وحياة بدون Kubernetes ، وأكثر من ذلك بكثير. انظر القائمة الكاملة للموضوعات والملخصات في صفحة منفصلة " تقارير ". وسنلتقي في DevOpsConf في فصل الربيع - اشترك في النشرة الإخبارية ، فأخبرنا متى نحدد التواريخ والموقع.