ليست هناك حاجة لتمثيل قاعدة FIAS بشكل محدد:

يمكنك تنزيله من خلال النقر على
الرابط ، قاعدة البيانات هذه مفتوحة وتحتوي على جميع عناوين الكائنات في روسيا (تسجيل العنوان). سبب الاهتمام في قاعدة البيانات هذه هو حقيقة أن الملفات التي تحتويها ضخمة جدًا. لذلك ، على سبيل المثال ، أصغر هو 2.9 غيغابايت. يُقترح التوقف عندها ومعرفة ما إذا كان بإمكان الباندا التعامل معها إذا كنت تعمل على جهاز به ذاكرة وصول عشوائي (RAM) سعة 8 جيجابايت فقط. وإذا لم تتمكن من التعامل ، فما هي الخيارات لتغذية الباندا بهذا الملف.
جنبًا إلى جنب ، لم أصادف هذه القاعدة أبدًا ، وهذه عقبة إضافية ، لأنه تنسيق البيانات المقدمة فيه غير واضح تمامًا.
بعد تنزيل أرشيف fias_xml.rar مع القاعدة ، نحصل على الملف منه - AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML. الملف بتنسيق xml.
للحصول على عمل أكثر ملاءمة في حيوانات الباندا ، يوصى بتحويل ملف XML إلى ملف CSV أو ملف json.
ومع ذلك ، تؤدي جميع محاولات تحويل برامج الجهات الخارجية و python بحد ذاتها إلى حدوث خطأ أو تجميد "MemoryError".
هم. ماذا لو قمت بقص الملف وتحويله إلى أجزاء؟ إنها فكرة جيدة ، لكن جميع "القواطع" يحاولون أيضًا قراءة الملف بالكامل في الذاكرة والتعليق ، فإن الثعبان نفسه ، الذي يتبع مسار "القواطع" ، لا يقطعها. هل من الواضح أن 8 جيجابايت ليست كافية؟ حسنا ، دعنا نرى.
برنامج Vedit
يجب عليك استخدام برنامج vedit تابع لجهة خارجية.
يسمح لك هذا البرنامج بقراءة ملف XML بحجم 2.9 جيجابايت والتعامل معه.
كما يسمح لك بتقسيمه. ولكن هناك خدعة صغيرة.
كما ترون عند قراءة ملف ، فإنه ، من بين أشياء أخرى ، به علامة AddressObjects مفتوحة:

لذلك ، عند إنشاء أجزاء من هذا الملف الكبير ، يجب ألا تنسَ إغلاقها (علامة).
وهذا يعني أن بداية كل ملف xml سيكون كما يلي:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
وتنتهي:
</AddressObjects>
الآن اقطع الجزء الأول من الملف (بالنسبة للأجزاء المتبقية ، الخطوات هي نفسها).
في برنامج vedit:
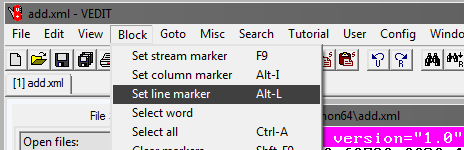
بعد ذلك ، حدد Goto و Line #. في النافذة التي تفتح ، اكتب رقم السطر ، على سبيل المثال ، 1،000،000:

بعد ذلك ، تحتاج إلى ضبط الكتلة المحددة بحيث تلتقط إلى نهاية الكائن في قاعدة البيانات قبل علامة الإغلاق:
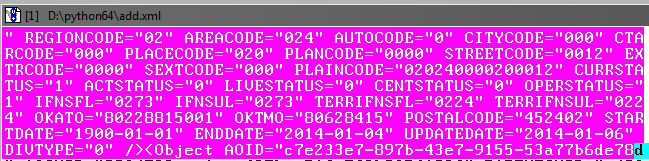
لا بأس إذا كان هناك تداخل بسيط على الكائن اللاحق.
بعد ذلك ، في برنامج vedit ، احفظ الجزء المحدد - ملف ، حفظ باسم.
بنفس الطريقة ، نقوم بإنشاء الأجزاء المتبقية من الملف ، مع تحديد بداية كتلة التحديد والنهاية بزيادات قدرها 1 مليون سطر.
نتيجة لذلك ، يجب أن تحصل على ملف xml الرابع بحجم 610 ميغابايت تقريبًا.
نحن وضع اللمسات الأخيرة على أجزاء XML
أنت الآن بحاجة إلى إضافة علامات في ملفات XML التي تم إنشاؤها حديثًا حتى تتم قراءتها على أنها xml.
افتح الملفات في vedit واحداً تلو الآخر وأضفها في بداية كل ملف:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
وفي النهاية:
</AddressObjects>
وبالتالي ، لدينا الآن 4 أجزاء xml من الملف المصدر المنقسم.
أكس إلى CSV
ترجم الآن xml إلى csv عن طريق كتابة برنامج بيثون.
رمز البرنامج
.
باستخدام البرنامج ، تحتاج إلى تحويل جميع الملفات 4 إلى CSV.
سينخفض حجم الملف ، وسيبلغ حجم كل ملف 236 ميجابايت (مقارنة بـ 610 ميغابايت بتنسيق xml).
من حيث المبدأ ، يمكنك الآن العمل معهم بالفعل ، من خلال برنامج Excel أو notepad ++.
ومع ذلك ، لا تزال الملفات في المرتبة الرابعة بدلاً من واحدة ، ولم نصل إلى الهدف - معالجة الملف في الباندا.
ملفات الغراء في واحد
على نظام Windows ، قد يتحول هذا إلى مهمة صعبة ، لذلك سوف نستخدم الأداة المساعدة لوحدة التحكم في python تسمى csvkit. تم تثبيتها كوحدة بيثون:
pip install csvkit
* في الواقع هذا هو مجموعة كاملة من المرافق ، ولكن ستكون هناك حاجة واحدة من هناك.
بعد إدخال المجلد مع ملفات للالتصاق في وحدة التحكم ، سنقوم بإجراء الإلتصاق في ملف واحد. نظرًا لأن جميع الملفات لا تحتوي على رؤوس ، فسنقوم بتعيين أسماء الأعمدة القياسية عند الإلتصاق: أ ، ب ، ج ، إلخ:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csv
الإخراج هو ملف CSV النهائي.
دعونا نعمل في الباندا لتحسين استخدام الذاكرة
إذا قمت بتحميل الملف على الفور إلى الباندا
import pandas as pd import numpy as np gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a') print (gl.info(memory_usage='deep'))
وتحقق من مقدار الذاكرة التي ستستغرقها ، قد تكون النتيجة مفاجأة غير سارة:

3 غيغابايت! وهذا على الرغم من حقيقة أنه عند قراءة البيانات ، "ذهب" العمود الأول كعمود فهرس * ، وبالتالي فإن وحدة التخزين ستكون أكبر.
* بشكل افتراضي ، يحدد الباندا فهرس الأعمدة الخاص به.
سننفذ التحسين باستخدام طرق من المنشور السابق
والمادة :
- كائن في الفئة ؛
- int64 في uint8 ؛
- float64 في float32.
للقيام بذلك ، عند قراءة الملف ، ستظهر أنواع dtypes وقراءة الأعمدة في الكود كما يلي:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' })
الآن ، عن طريق فتح ملف الباندا ، سيكون استخدام الذاكرة من الحكمة:

يبقى أن تضاف إلى ملف CSV ، إذا رغبت في ذلك ، أسماء الأعمدة الفعلية للصف حتى تصبح البيانات منطقية:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE
* يمكنك استبدال أسماء الأعمدة بهذا السطر ، ولكن عليك تغيير الرمز.
حفظ الأسطر الأولى من الملف من الباندا
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
وانظر ماذا حدث في التفوق:

رمز البرنامج لفتح الأمثل لملف CSV مع قاعدة بيانات:
قانون import os import time import pandas as pd import numpy as np # : object-category, float64-float32, int64-int gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' }) pd.set_option('display.notebook_repr_html', False) pd.set_option('display.max_columns', 8) pd.set_option('display.max_rows', 10) pd.set_option('display.width', 80) #print (gl.head()) print (gl.info(memory_usage='deep')) # def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , , usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} " .format(usage_mb)
في الختام ، دعنا ننظر إلى حجم مجموعة البيانات:
gl.shape
(3348644, 28)
3.3 مليون صف ، 28 عمود.
خلاصة القول: مع حجم ملف CSV الأولي من 890 ميغابايت ، "الأمثل" لأغراض العمل مع الباندا ، فإنه يحتل 1.2 غيغابايت في الذاكرة.
وبالتالي ، مع حساب تقريبي ، يمكن افتراض أنه يمكن فتح ملف بحجم 7.69 غيغابايت في الباندا ، حيث "سبق" تحسينه.