ما هو التعرف على الكلام End2End ، ولماذا هو مطلوب؟ ما هو الاختلاف عن النهج الكلاسيكي؟ ولماذا ، من أجل تدريب نموذج جيد يعتمد على End2End ، نحتاج إلى كمية هائلة من البيانات - في منشورنا اليوم.
النهج الكلاسيكي في التعرف على الكلام
قبل التحدث عن نهج End2End ، يجب أن تتحدث أولاً عن الطريقة الكلاسيكية للتعرف على الكلام. ما هو مثل؟

استخراج الميزة
في الواقع ، هذا ليس تسلسل خطي بالكامل من كتل العمل. دعونا نتطرق إلى كل كتلة بمزيد من التفاصيل. لدينا نوعًا من خطاب الإدخال ، فهو يقع في المجموعة الأولى - استخراج الميزات. هذه كتلة تسحب العلامات من الكلام. يجب أن يؤخذ في الاعتبار أن الكلام نفسه شيء معقد إلى حد ما. يجب أن تكون قادرًا على التعامل معها بطريقة أو بأخرى ، لذلك هناك طرق قياسية لعزل الميزات من نظرية معالجة الإشارات. على سبيل المثال ، معاملات ميل cepstral (MFCC) وهلم جرا.
نموذج صوتي
المكون التالي هو النموذج الصوتي. يمكن أن تعتمد على شبكات عصبية عميقة ، أو على أساس مزيج من توزيعات غوسية ونماذج ماركوف المخفية. الهدف الرئيسي منه هو الحصول من توزيعات الإشارة الصوتية على التوزيعات الاحتمالية للأصوات الصوتية المختلفة في هذا القسم.
التالي يأتي وحدة فك الترميز ، والتي تبحث عن المسار الأكثر ترجيحًا في الرسم البياني بناءً على نتيجة الخطوة الأخيرة. الاستعادة هي اللمسات الأخيرة في التقدير ، وتتمثل مهمتها الرئيسية في إعادة تقييم الفرضيات وتحقيق النتيجة النهائية.
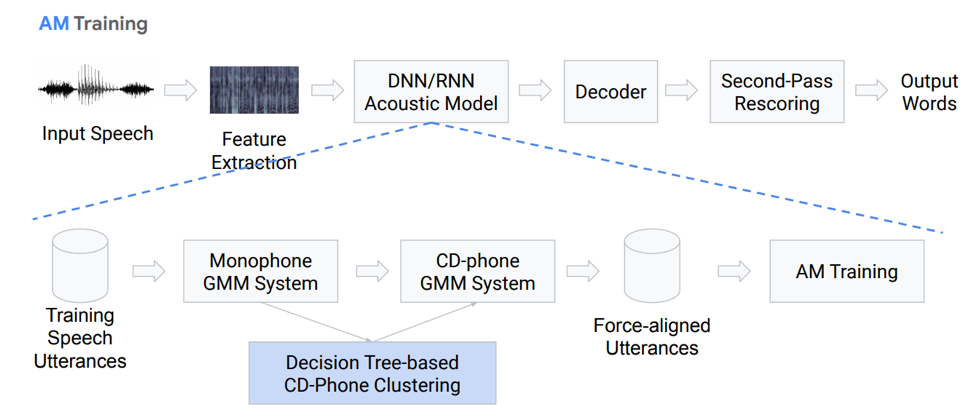
دعنا نتحدث بمزيد من التفاصيل عن النموذج الصوتي. ما هي تحب؟ لدينا بعض التسجيلات الصوتية التي تدخل نظامًا معينًا يستند إلى GMM (مزيج Gausovy أحادي) أو HMM. وهذا هو ، لدينا تمثيل في شكل صوتيات ، ونحن نستخدم monophones ، وهذا هو ، phonemes مستقلة عن السياق. علاوة على ذلك ، نصنع مزيجًا من توزيعات غوسية استنادًا إلى أصوات صوتية حساسة للسياق. ويستخدم التجميع على أساس الأشجار القرار.
ثم نحاول بناء المحاذاة. تسمح لنا هذه الطريقة غير التافهة تمامًا بالحصول على نموذج صوتي. لا يبدو الأمر بسيطًا جدًا ، بل إنه في الواقع أكثر تعقيدًا ، فهناك العديد من الفروق الدقيقة والميزات. ولكن كنتيجة لذلك ، فإن النموذج المدرب على مئات الساعات قادر على محاكاة الصوتيات.

فك
ما هو جهاز فك التشفير؟ هذه هي الوحدة التي تحدد مسار الانتقال الأكثر احتمالًا وفقًا للرسم البياني HCLG ، والذي يتكون من 4 أجزاء:
وحدة H على أساس HMM
C وحدة تبعية السياق
وحدة النطق ل
وحدة نموذج اللغة G
نحن نبني رسم بياني على هذه المكونات الأربعة ، والتي على أساسها سوف نقوم بفك تشفير ميزاتنا الصوتية في بعض الإنشاءات اللفظية.
زائد أو ناقص ، من الواضح أن النهج الكلاسيكي مرهق وصعب إلى حد ما ، ومن الصعب التدريب ، لأنه يتكون من عدد كبير من الأجزاء المنفصلة ، ولكل منها تحتاج إلى إعداد بياناتك الخاصة للتدريب.
الثاني End2End النهج
فما هو التعرف على الكلام End2End ولماذا هو مطلوب؟ هذا هو نظام معين ، والذي تم تصميمه ليعكس مباشرة تسلسل العلامات الصوتية في تسلسل الحروف (الحروف) أو الكلمات. يمكنك أيضًا القول إن هذا النظام يعمل على تحسين المعايير التي تؤثر بشكل مباشر على المقياس النهائي لتقييم الجودة. على سبيل المثال ، مهمتنا هي على وجه التحديد معدل خطأ الكلمة. كما قلت ، هناك حافز واحد فقط - لتقديم هذه المكونات المعقدة متعددة المراحل باعتبارها مكونًا بسيطًا من شأنه أن يعرض مباشرة أو يخرج الكلمات أو الرسومات من خطاب الإدخال.
مشكلة المحاكاة
هنا لدينا مشكلة على الفور: الكلام الصوتي هو تسلسل ، وفي الخرج نحتاج أيضًا إلى إعطاء تسلسل. وحتى عام 2006 ، لم تكن هناك طريقة مناسبة لتصميم هذا. ما هي مشكلة النمذجة؟ كانت هناك حاجة لكل سجل لإنشاء ترميز معقد ، مما يعني في أي ثانية نطق صوت أو حرف معين. هذا مخطط معقد للغاية وبالتالي لم يتم إجراء عدد كبير من الدراسات حول هذا الموضوع. في عام 2006 ، تم نشر مقالة مثيرة للاهتمام من قبل Alex Graves بعنوان "التصنيف الزمني للاتصال" (CTC) ، حيث تم حل هذه المشكلة من حيث المبدأ. ولكن تم نشر المقال ، ولم يكن هناك ما يكفي من القوة الحاسوبية في ذلك الوقت. وظهرت خوارزميات التعرف على الكلام الحقيقية في وقت لاحق.
بشكل إجمالي ، لدينا: تم اقتراح خوارزمية CTC بواسطة Alex Graves قبل ثلاثة عشر عامًا ، كأداة تسمح لك بتدريب / تدريب النماذج الصوتية دون الحاجة إلى هذا الترميز المعقد - محاذاة إطارات تسلسل الإدخال والإخراج. استنادًا إلى هذه الخوارزمية ، بدا العمل في البداية لم يكن مكتملًا نهاية 2 ؛ تم إصدار الصوتيات كنتيجة لذلك. تجدر الإشارة إلى أن الصوتيات الحساسة للسياق القائمة على STS تحقق بعضًا من أفضل النتائج في التعرف على حرية التعبير. ولكن تجدر الإشارة أيضًا إلى أن هذه الخوارزمية ، المطبقة مباشرةً على الكلمات ، تظل في مكان ما في الوقت الحالي.

ما هو STS
سوف نتحدث الآن بالتفصيل أكثر قليلاً عن ماهية STS ولماذا هي مطلوبة وما هي الوظيفة التي تؤديها. STS ضروري من أجل تدريب النموذج الصوتي دون الحاجة إلى محاذاة الإطار بالإطار بين الصوت والنسخ. تكون محاذاة الإطار حسب الإطار عندما نقول أن إطارًا معينًا من الصوت يتوافق مع هذا الإطار من النسخ. لدينا برنامج تشفير تقليدي يقبل العلامات الصوتية كمدخل - فهو يعطي نوعًا من إخفاء الحالة ، على أساسها نحصل على احتمالات مشروطة باستخدام softmax. يتكون التشفير عادة من عدة طبقات من LSTMs أو أشكال أخرى من RNNs. تجدر الإشارة إلى أن STS تعمل بالإضافة إلى أحرف عادية ذات طابع خاص يسمى حرفًا فارغًا أو رمزًا فارغًا. من أجل حل المشكلة التي تنشأ بسبب حقيقة أن ليس لكل إطار صوتي إطار في النسخ والعكس (أي ، لدينا حروف أو أصوات تبدو أطول من ذلك بكثير وهناك أصوات قصيرة ، أصوات متكررة) ، وهناك هذا الرمز فارغ.
يهدف STS نفسه إلى زيادة الاحتمال النهائي لتسلسل الأحرف وتعميم المحاذاة المحتملة. نظرًا لأننا نريد استخدام هذه الخوارزمية في الشبكات العصبية ، فمن المفهوم أنه يجب علينا أن نفهم كيف تعمل أوضاع التشغيل الأمامية والخلفية. لن نتناول التبرير والميزات الرياضية لتشغيل هذه الخوارزمية ، وإلا فسوف يستغرق الأمر وقتًا طويلاً للغاية.
ماذا لدينا: يظهر أول ASR استنادًا إلى خوارزمية STS في عام 2014. مرة أخرى ، قدم Alex Graves منشورًا استنادًا إلى STS حرفيًا يعرض خطاب الإدخال مباشرةً في سلسلة من الكلمات. أحد التعليقات التي قدموها في هذه المقالة هو أن استخدام نموذج صوت خارجي أمر مهم للحصول على نتيجة جيدة.
5 طرق لتحسين الخوارزمية
هناك العديد من الاختلافات والتحسينات المختلفة للخوارزمية أعلاه. هنا ، على سبيل المثال ، الخمسة الأكثر شعبية في الآونة الأخيرة.
• يتم تضمين نموذج اللغة في فك التشفير خلال التمريرة الأولى
o [Hannun et al.، 2014] [Maas et al.، 2015]: فك تشفير البطاقة المباشرة المباشرة مع LM بدلاً من الإنقاذ كما في [Graves & Jaitly، 2014]
o [Miao et al. ، 2015]: إطار EESEN لفك التشفير مع WFSTs ، مجموعة أدوات مفتوحة المصدر
• تدريب واسع النطاق على GPU ؛ زيادة البيانات عدة لغات
حنون وآخرون ، 2014 ؛ DeepSpeech] [Amodei et al.، 2015؛ DeepSpeech2]: تدريب GPU واسع النطاق ؛ زيادة البيانات ؛ لغة الماندرين والإنجليزية
• استخدام وحدات طويلة: الكلمات بدلا من الشخصيات
o [Soltau et al. ، 2017]: أهداف CTC على مستوى الكلمات ، تم تدريبها على 125000 ساعة من الكلام. أداء قريب من النظام التقليدي أو أفضل منه ، حتى بدون استخدام LM!
o [Audhkhasi et al.، 2017]: نماذج الصوتيات المباشرة إلى Word على لوحة التبديل
يجدر الانتباه إلى تطبيق DeepSpeach كمثال جيد على حل CTC end2end وإلى اختلاف يستخدم المستوى اللفظي. ولكن هناك تحذير واحد: لتدريب مثل هذا النموذج ، تحتاج إلى 125 ألف ساعة من البيانات التي تحمل علامات ، والتي هي في الواقع كثيرة للغاية في الواقع القاسي.
ما هو المهم أن نلاحظ حول STS
- القضايا أو الإغفالات. لتحقيق الكفاءة ، من المهم وضع افتراضات حول الاستقلال. بمعنى ، تفترض STS أن إخراج الشبكة في إطارات مختلفة مستقل شرطيًا ، وهذا غير صحيح بالفعل. لكن هذا الافتراض تم تبسيطه ، وبدونه ، يصبح كل شيء أكثر تعقيدًا.
- لتحقيق أداء جيد من طراز STS ، يلزم استخدام نموذج لغة خارجي ، لأن فك التشفير الجشع المباشر لا يعمل جيدًا.
اهتمام
ما البديل لدينا لهذا STS؟ ربما لا يخفى على أحد أن هناك ما يسمى "الاهتمام" أو "الاهتمام" ، الذي أحدث ثورة إلى حد ما وانتقل مباشرة من مهام الترجمة الآلية. والآن تعتمد قرارات نمذجة التسلسل التسلسلي على هذه الآلية. ما هو مثل؟ دعنا نحاول معرفة ذلك. لأول مرة حول الاهتمام في مهام التعرف على الكلام ، ظهرت المنشورات في عام 2015. أصدر شخص ما تشن وشروفسكي منشورين متشابهين ومختلفين في نفس الوقت.
دعونا نتطرق إلى الأول - يطلق عليه اسمع ، وحضر ، وقم بالتهجئة. في المحاكاة الكلاسيكية لدينا ، في التسلسل حيث يوجد لدينا وحدة فك ترميز وفك تشفير ، يتم إضافة عنصر آخر ، يسمى الاهتمام. سيقوم echnoder بالوظائف التي يستخدمها النموذج الصوتي لأداء. وتتمثل مهمتها في تحويل خطاب الإدخال إلى ميزات صوتية عالية المستوى. سوف يقوم وحدة فك الترميز الخاصة بنا بتنفيذ المهام التي أجريناها سابقًا في نموذج اللغة ونموذج النطق (المعجم) ، وسوف تتنبأ تلقائيًا بكل رمز مميز للمخرجات ، كدالة من الرموز السابقة. وسيقول الاهتمام نفسه مباشرة أي إطار الإدخال هو الأكثر أهمية / مهمة من أجل التنبؤ بهذا الإخراج.
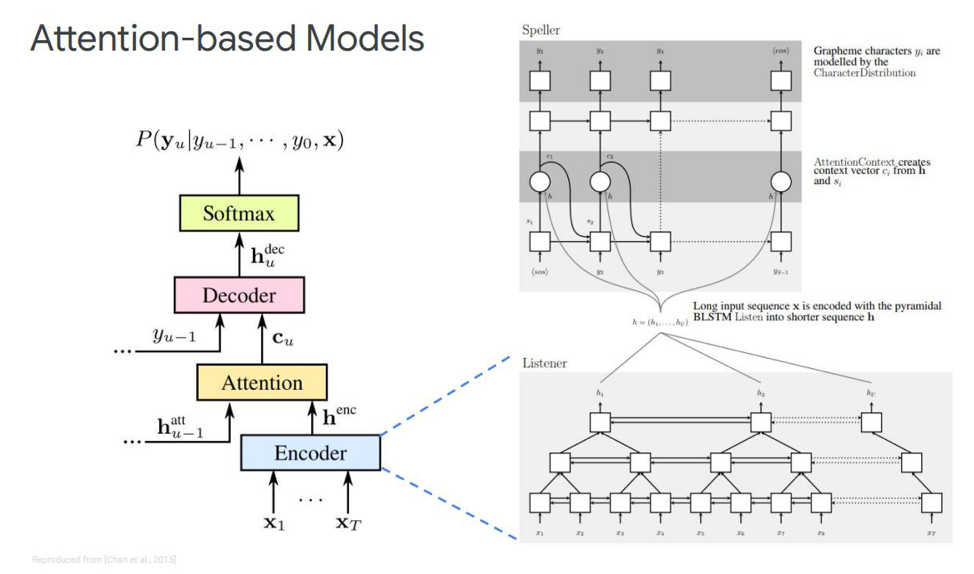
ما هي هذه الكتل؟ يوصف برنامج التشفير البيئي في المقالة بأنه مستمع ، إنه عبارة عن شبكات RNN ثنائية الاتجاه تقوم على LSTMs أو أي شيء آخر. بشكل عام ، لا شيء جديد - يقوم النظام ببساطة بمحاكاة تسلسل الإدخال في ميزات معقدة.
الانتباه ، من ناحية أخرى ، يخلق متجه سياق معين C من هذه المتجهات ، مما سيساعد على فك ترميز وحدة فك الترميز بشكل صحيح مباشرة ، وهو جهاز فك الترميز نفسه ، على سبيل المثال ، أيضًا بعض LSTMs ، التي سيتم فك تشفيرها في تسلسل المدخلات من طبقة الانتباه هذه ، والتي أبرزت بالفعل أهم علامات الحالة ، بعض تسلسل الإخراج من الشخصيات.
هناك أيضًا تمثيلات مختلفة لهذا الاهتمام نفسه - وهو الفرق بين هذين المنشورين اللذين أصدرهما تشن وشاروفسكي. يستخدمون انتباه مختلف. يستخدم تشن الاهتمام بمنتج نقطة ، ويستخدم Charowski الإضافة المضافة.

إلى أين تذهب بعد ذلك؟
هذا هو زائد أو ناقص جميع الإنجازات الرئيسية التي تحققت حتى الآن في مسائل التعرف على الكلام غير عبر الإنترنت. ما هي التحسينات الممكنة هنا؟ إلى أين تذهب بعد ذلك؟ الأكثر وضوحا هو استخدام نموذج على أجزاء من الكلمات بدلا من استخدام الرسوم البيانية مباشرة. يمكن أن يكون بعض morphemes منفصلة أو أي شيء آخر.
ما هو الدافع لاستخدام شرائح الكلمة؟ عادة ، يكون لنماذج اللغة في المستوى اللفظي حيرة أقل مقارنة بمستوى الكتابة على الورق. نمذجة قطع الكلمات يسمح لك ببناء وحدة فك ترميز أقوى لنموذج اللغة. ونمذجة العناصر الأطول يمكن أن يحسن كفاءة الذاكرة في وحدة فك الترميز على أساس LSTMs. كما يسمح لك بتذكر حدوث كلمات التردد المحتملة. تسمح العناصر الأطول بفك التشفير في خطوات أقل ، مما يسرع بشكل مباشر من استنتاج هذا النموذج.
أيضًا ، يسمح لنا النموذج الموجود على أجزاء من الكلمات بحل مشكلة الكلمات التي تظهر في نموذج اللغة (خارج المفردات) التي تظهر في نموذج اللغة ، حيث يمكننا نمذجة أي كلمة باستخدام أجزاء من الكلمات. وتجدر الإشارة إلى أن هذه النماذج مدربة لزيادة احتمالية وجود نموذج لغوي على مجموعة بيانات التدريب. تعتمد هذه النماذج على الموضع ، ويمكننا استخدام الخوارزمية الجشعة لفك التشفير.
ما هي التحسينات الأخرى إلى جانب نموذج الكلمات التي يمكن أن تكون؟ هناك آلية تسمى الاهتمام متعدد الرؤوس. تم وصفه لأول مرة في عام 2017 للترجمة الآلية. يتضمن الاهتمام متعدد الرؤوس آلية تتضمن العديد من الرؤوس المزعومة التي تتيح لك توليد توزيع مختلف لهذا الاهتمام نفسه ، مما يحسن النتائج مباشرة.
نماذج على الانترنت
ننتقل إلى الجزء الأكثر إثارة للاهتمام - هذه هي النماذج عبر الإنترنت. من المهم أن نلاحظ أن LAS لا يتدفقون. وهذا يعني أن هذا النموذج لا يمكن أن يعمل في وضع فك التشفير عبر الإنترنت. سننظر في النموذجين الأكثر شعبية على الإنترنت حتى الآن. محول RNN ومحول عصبي.
تم اقتراح RNN Transducer بواسطة Graves في 2012-2017. الفكرة الرئيسية هي تعقيد نموذج STS الخاص بنا قليلاً بمساعدة نموذج تكراري.
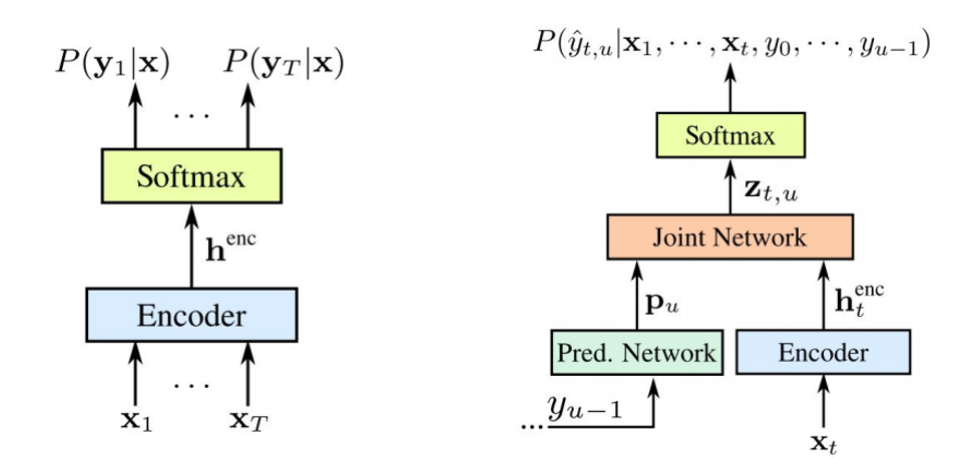
تجدر الإشارة إلى أنه يتم تدريب كلا المكونين معًا على البيانات الصوتية المتاحة. مثل STS ، لا يتطلب هذا النهج محاذاة الإطار في مجموعة بيانات التدريب. كما نرى في الصورة: على اليسار لدينا STS الكلاسيكية ، وعلى اليمين هو محول RNN. ولدينا عنصرين جديدين -
الشبكة المتوقعة والانضمام إلى الشبكة .
تشفير STS هو نفسه تمامًا - هذا هو مستوى الإدخال RNN ، الذي يحدد التوزيع على جميع المحاذاة مع جميع تسلسلات الإخراج التي لا تتجاوز طول تسلسل الإدخال - هذا ما وصفه Graves في عام 2006. ومع ذلك ، فإن مهمة تحويلات تحويل النص إلى كلام هذه مستثناة أيضًا ، حيث لا يمثل تسلسل الإدخال أطول من تسلسل الإدخال في STS نموذجًا للعلاقة بين المخرجات. يوسع Transducer هذا STS بالذات ، ويحدد توزيع تسلسلات الإخراج من جميع الأطوال ونمذجة مشتركة اعتماد المدخلات والمخرجات والمخرجات.
اتضح أن نموذجنا قادر في النهاية على التعامل مع تبعيات الإخراج من المدخلات والإخراج من إخراج الخطوة الأخيرة.
فما هي
شبكة التنبؤ أو شبكة تنبؤية؟ تحاول أن تصمم كل عنصر مع مراعاة العناصر السابقة ، وبالتالي ، فهي تشبه RNN القياسية مع التنبؤ بالخطوة التالية. فقط مع القدرة المضافة على القيام بفرضيات لاغية.
كما نرى في الصورة ، لدينا شبكة متوقعة ، تتلقى القيمة السابقة للإخراج ، وهناك جهاز تشفير ، يستقبل القيمة الحالية للمدخلات. وفي الإخراج نحن مرة أخرى ، هذه لها القيمة الحالية
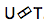
.
محول عصبي . هذا هو تعقيد النهج seq-2seq الكلاسيكية. تتم معالجة التسلسل الصوتي للمدخلات بواسطة المشفر لإنشاء متجهات حالة مخفية في كل خطوة زمنية. يبدو أن كل شيء كالمعتاد. ولكن هناك عنصر Transducer إضافي يتلقى كتلة إدخال في كل خطوة ويولد ما يصل إلى M-output الرموز المميزة باستخدام نموذج يستند إلى seq-2seq فوق هذا الإدخال. يحافظ Transducer على حالته في كتل باستخدام اتصالات دورية مع الخطوات الزمنية السابقة.
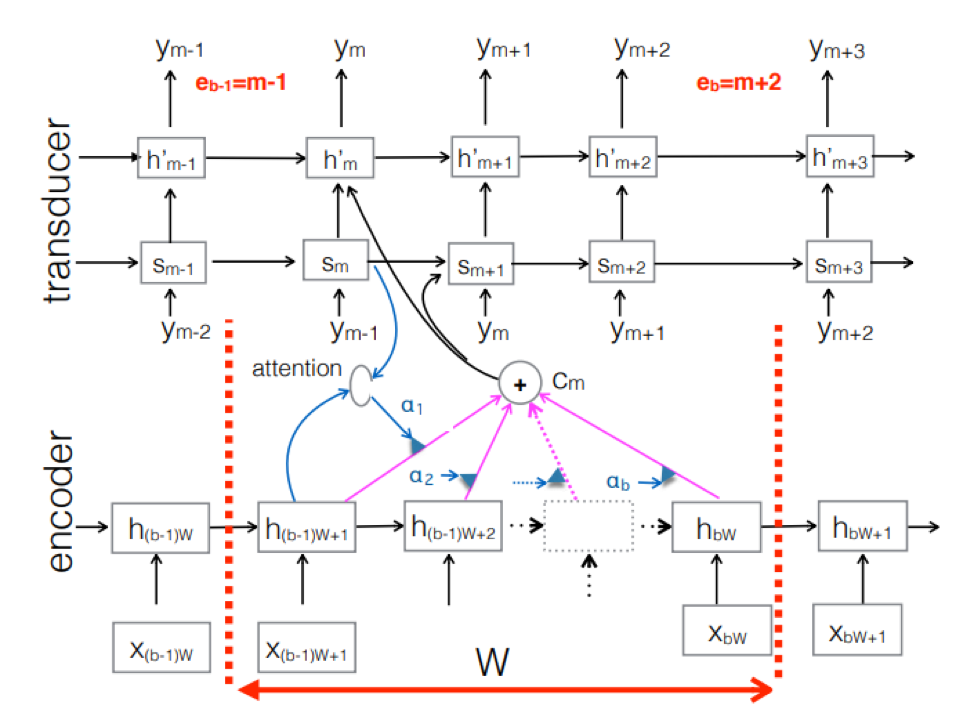 يوضح الشكل محول الطاقة ، حيث يقوم بإنتاج الرموز الخاصة بالكتلة للتسلسل المستخدم في كتلة Ym المقابلة.
يوضح الشكل محول الطاقة ، حيث يقوم بإنتاج الرموز الخاصة بالكتلة للتسلسل المستخدم في كتلة Ym المقابلة.لذلك ، قمنا بفحص الحالة الحالية للتعرف على الكلام على أساس نهج End2End. تجدر الإشارة إلى أنه ، لسوء الحظ ، تتطلب هذه الأساليب اليوم كمية كبيرة من البيانات. والنتائج الحقيقية التي تحققت من خلال النهج الكلاسيكي ، التي تتطلب تسجيلات صوتية تتراوح من 200 إلى 500 ساعة تم ترميزها لتدريب نموذج جيد يعتمد على End2End ، سوف تتطلب بيانات متعددة ، أو ربما عشرات المرات. الآن هذه هي المشكلة الأكبر في هذه الأساليب. ولكن ربما قريباً سيتغير كل شيء.
المطور الرئيسي لمركز AI MTS نيكيتا سيمينوف.