
هذا تعليم خطوة بخطوة لتصنيف الصور متعددة الأطياف من قمر لاندسات 5. واليوم ، في عدد من المناطق ، يهيمن التعليم العميق كأداة لحل المشكلات المعقدة ، بما في ذلك المشكلات الجغرافية المكانية. أتمنى أن تكون على دراية بمجموعات بيانات الأقمار الصناعية ، ولا سيما Landsat 5 TM. إذا كنت معتادًا قليلاً على خوارزميات التعلم الآلي ، فسيساعدك ذلك على تعلم هذا الدليل بسرعة. بالنسبة لأولئك الذين لا يفهمون ، سيكون من الكافي معرفة أن التعلم الآلي يتكون في الواقع من إقامة علاقات بين عدة خصائص (مجموعة من السمات X) لكائن ما بخصائصه الأخرى (القيمة أو العلامة ، المتغير Y المستهدف). نقوم بإطعام النموذج بالعديد من الكائنات التي تُعرف بها خصائص وقيمة المؤشر / فئة الهدف للكائن (البيانات المميزة) وتدريبه حتى يتسنى له التنبؤ بقيمة المتغير الهدف Y للبيانات الجديدة (غير المميزة).
ما هي المشكلة الرئيسية في صور الأقمار الصناعية؟
يمكن أن يكون لفئتين أو أكثر من الكائنات (على سبيل المثال ، المباني والكميات الشاغرة وحفر الأساس) في صور الأقمار الصناعية نفس الخصائص الطيفية للقيمة ، وبالتالي ، فقد كان تصنيفها مهمة صعبة في العشرين عامًا الماضية.
لهذا السبب ، من الممكن استخدام نماذج تعلم الآلة الكلاسيكية مع أو بدون معلم ، لكن جودتها ستكون بعيدة عن المثالية. لديهم دائما نفس العيوب. النظر في مثال:

إذا كنت تستخدم خطًا رأسيًا كمصنف وقم بتحريكه على طول المحور X ، فلن يكون تصنيف صور المنازل أمرًا سهلاً. يتم توزيع البيانات بحيث يكون من المستحيل فصلها إلى فئات باستخدام خط عمودي واحد (في مثل هذه الحالات ، يقال إن "كائنات الفئات المختلفة لا يمكن فصلها خطيًا"). لكن هذا لا يعني أنه لا يمكن تصنيف المنازل على الإطلاق!
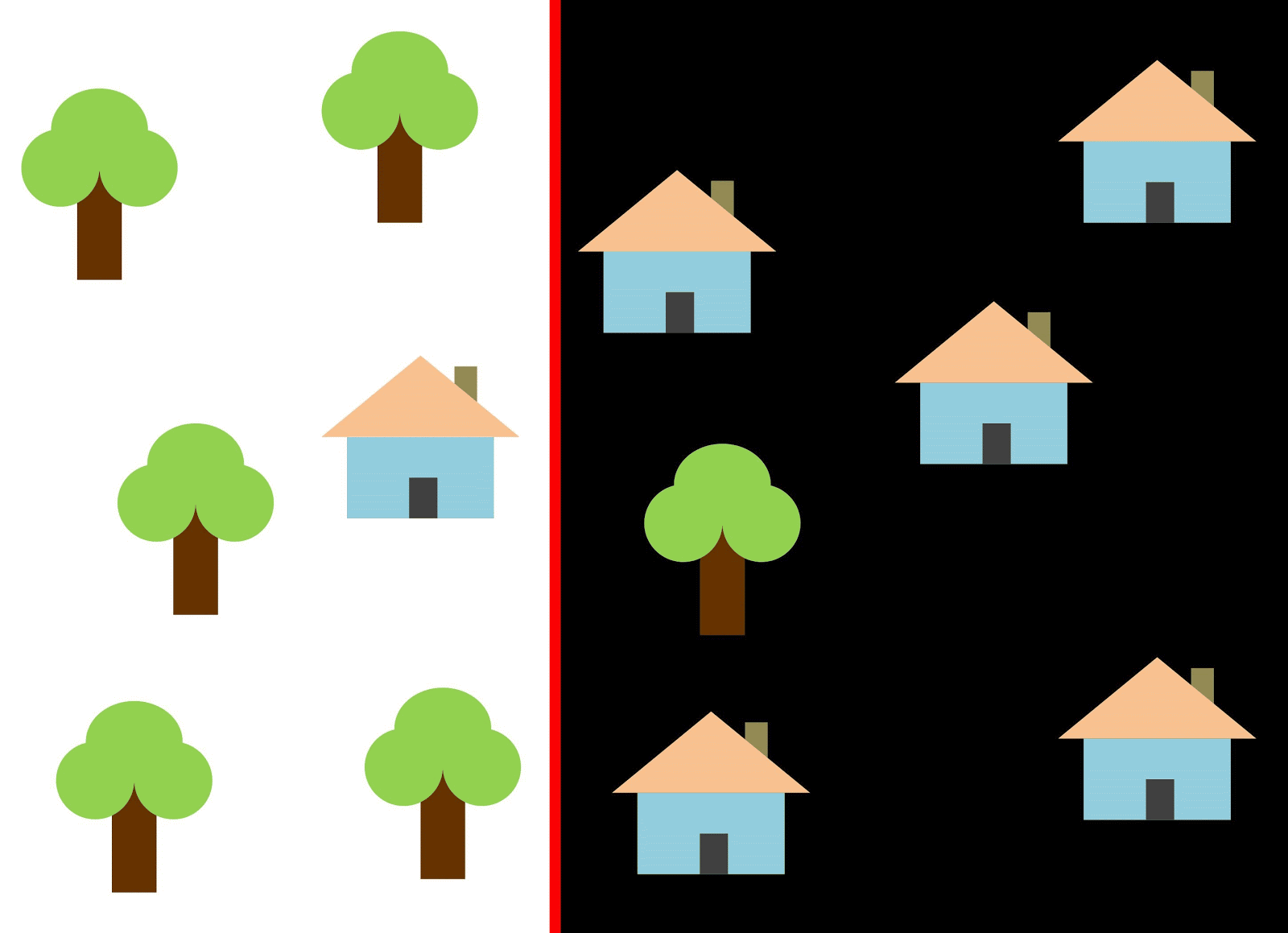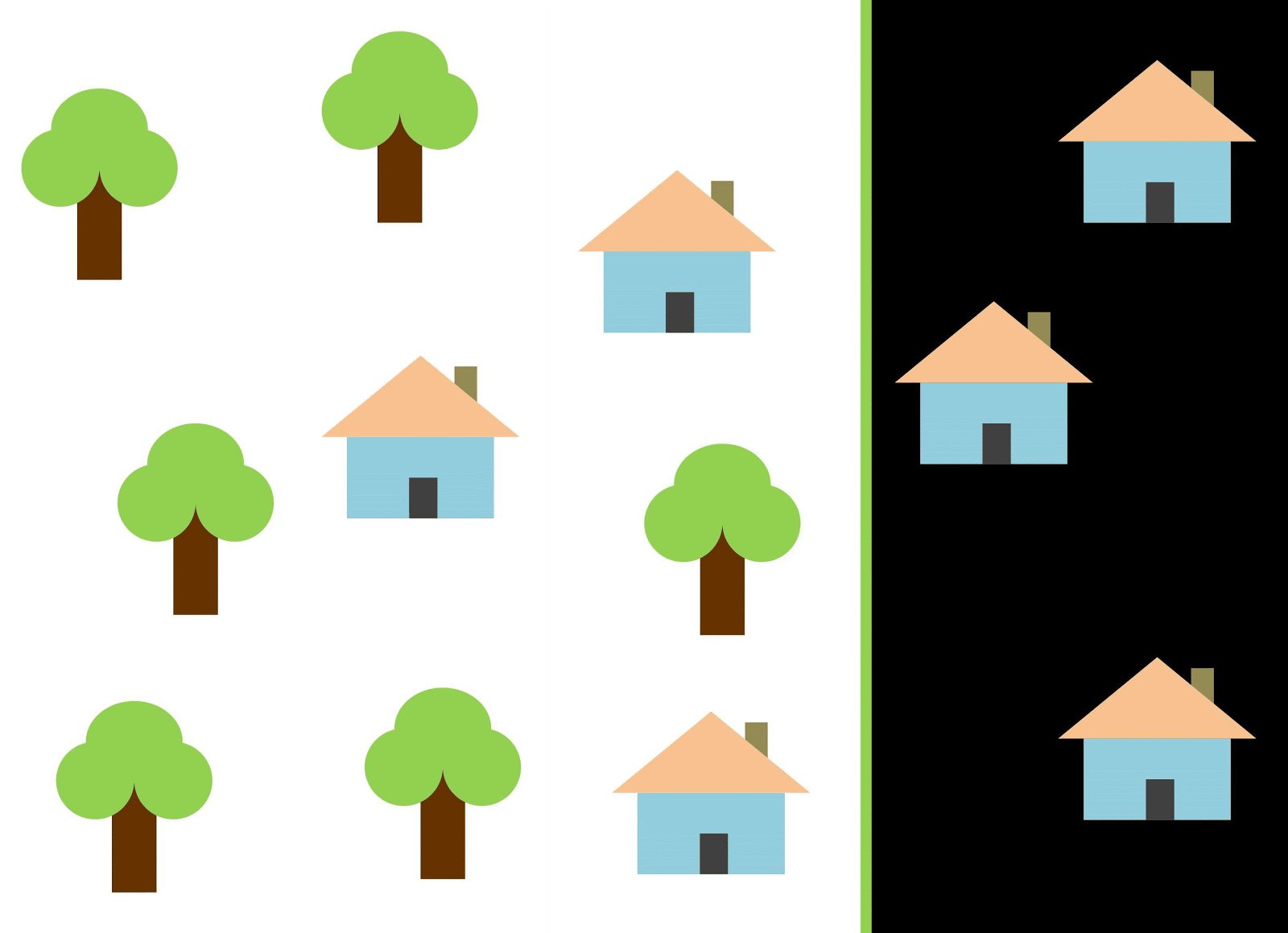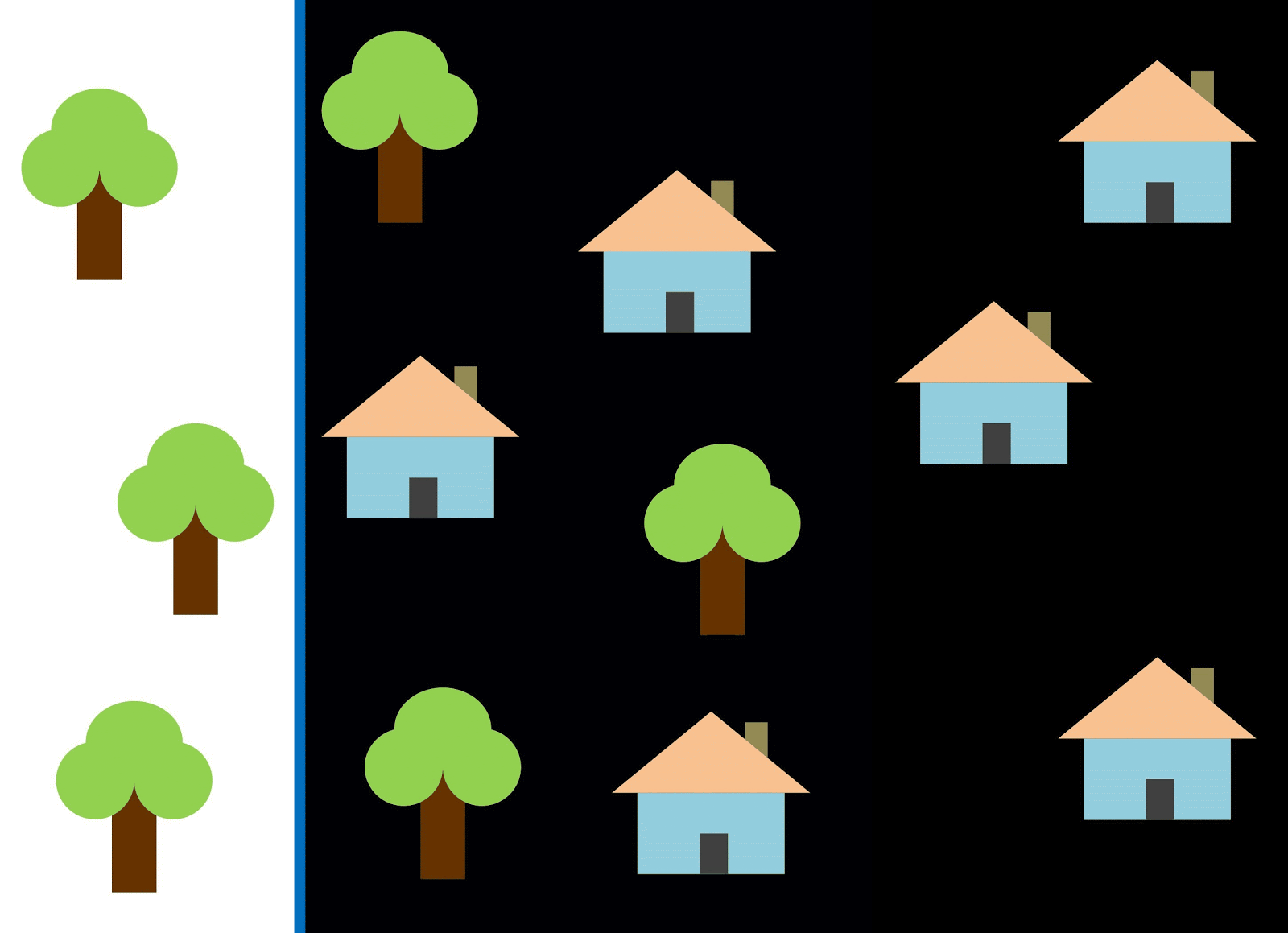
دعنا نستخدم الخط الأحمر لفصل الفصلين. في هذه الحالة ، حدد المصنف معظم المنازل ، ولكن لم يتم تخصيص منزل واحد لفئته ، وتم تخصيص ثلاث أشجار أخرى عن طريق الخطأ في "المنازل". لكي لا تفوت منزل واحد ، يمكنك استخدام المصنف في شكل خط أزرق. بعد ذلك ، سيتم تغطية كل شيء في المنزل ، أي نقول أن قياس الاستدعاء (الامتلاء) مرتفع. ومع ذلك ، لم تتحول جميع القيم المصنفة إلى منازل ، وهذا هو ، في الوقت نفسه ، حصلنا على قيمة منخفضة لقياس الدقة. إذا استخدمنا الخط الأخضر ، فستكون جميع الصور المصنفة كمنازل عبارة عن منازل ، أي أن المصنف سيظهر دقة عالية. في هذه الحالة ، سيكون الامتلاء أقل ، حيث سيتم مصادرة المنازل الثلاثة. في معظم الحالات ، يتعين علينا إيجاد حل وسط بين الدقة والكمال.
تشبه مشكلة المنازل والأشجار مشكلة المباني والكثيرات الشاغرة والحفر. قد تختلف أولوية مقاييس تصنيف صور القمر الصناعي حسب المهمة. على سبيل المثال ، إذا كنت بحاجة إلى التأكد من أن جميع المناطق المبنية تصنف على أنها مباني دون استثناء ، وأنك على استعداد لتحملها مع وجود وحدات بكسل لفئات أخرى بتوقيعات مماثلة ، والتي سيتم تصنيفها أيضًا على أنها مبان ، فستحتاج إلى نموذج ذو اكتمال عالٍ. وإذا كان من المهم بالنسبة لك تصنيف مبنى ما ، دون إضافة وحدات بكسل لفئات أخرى ، وكنت على استعداد للتخلي عن تصنيف المناطق المختلطة ، فاختر مصنفًا بدقة عالية. في حالة المنازل والأشجار ، سيستخدم النموذج المعتاد الخط الأحمر ، مع الحفاظ على التوازن بين الدقة والاكتمال.
البيانات المستخدمة
كعلامات ، سوف نستخدم قيم النطاقات الستة (النطاق 2 - النطاق 7) للصورة من Landsat 5 TM ، ونحاول التنبؤ بفئة التطوير الثنائية. للتدريب والاختبار ، سيتم استخدام البيانات متعددة الأطياف (الصور وطبقة مع فئة بناء ثنائي) مع Landsat 5 لعام 2011 لبنغالور. وللتنبؤ سيتم استخدام بيانات لاندسات 5 متعددة الأطياف التي تم الحصول عليها في عام 2005 في حيدر أباد.
نظرًا لأننا نستخدم البيانات الموسومة للتدريس ، فهذا يسمى التدريس مع المعلم.
 بيانات التدريب متعدد الأطياف والطبقة الثنائية المقابلة مع التنمية.
بيانات التدريب متعدد الأطياف والطبقة الثنائية المقابلة مع التنمية.لإنشاء شبكة عصبية ، سنستخدم Python - مكتبة Google Tensorflow. سنحتاج أيضًا إلى هذه المكتبات:
- بيرسيس - لقراءة وكتابة GeoTIFF.
- scikit-learn - للمعالجة المسبقة للبيانات وتقييم الدقة.
- numpy - للعمليات الأساسية مع المصفوفات.
والآن ، دون مزيد من اللغط ، دعنا نكتب الكود.
ضع جميع الملفات الثلاثة في دليل ، واكتب مسار أسماء الملفات المدخلة في البرنامج النصي ، ثم اقرأ ملفات GeoTIFF.
import os from pyrsgis import raster os.chdir("E:\\yourDirectoryName") mxBangalore = 'l5_Bangalore2011_raw.tif' builtupBangalore = 'l5_Bangalore2011_builtup.tif' mxHyderabad = 'l5_Hyderabad2011_raw.tif'
تقرأ الوحدة النمطية
raster من حزمة pyrsgis بيانات تحديد الموقع الجغرافي GeoTIFF وقيم الرقم الرقمي (DN) كصفيفات NumPy منفصلة. إذا كنت مهتمًا بالتفاصيل ، اقرأ
هنا .
الآن نعرض حجم بيانات القراءة.
print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
النتيجة:
Bangalore multispectral image shape: 6, 2054, 2044 Bangalore binary built-up image shape: 2054, 2044 Hyderabad multispectral image shape: 6, 1318, 1056
كما ترون ، تحتوي صور بنغالور على نفس عدد الصفوف والأعمدة الموجودة في الطبقة الثنائية (المقابلة للمبنى). يتزامن أيضًا عدد الطبقات في الصور متعددة الأطياف في بنغالور وحيدر أباد. سيتعلم النموذج تحديد وحدات البكسل التي تنتمي إلى المبنى وأيها لا ، بناءً على القيم المقابلة لكل الأطياف الستة. لذلك ، يجب أن تحتوي الصور متعددة الأطياف على نفس عدد الميزات (النطاقات) المدرجة بنفس الترتيب.
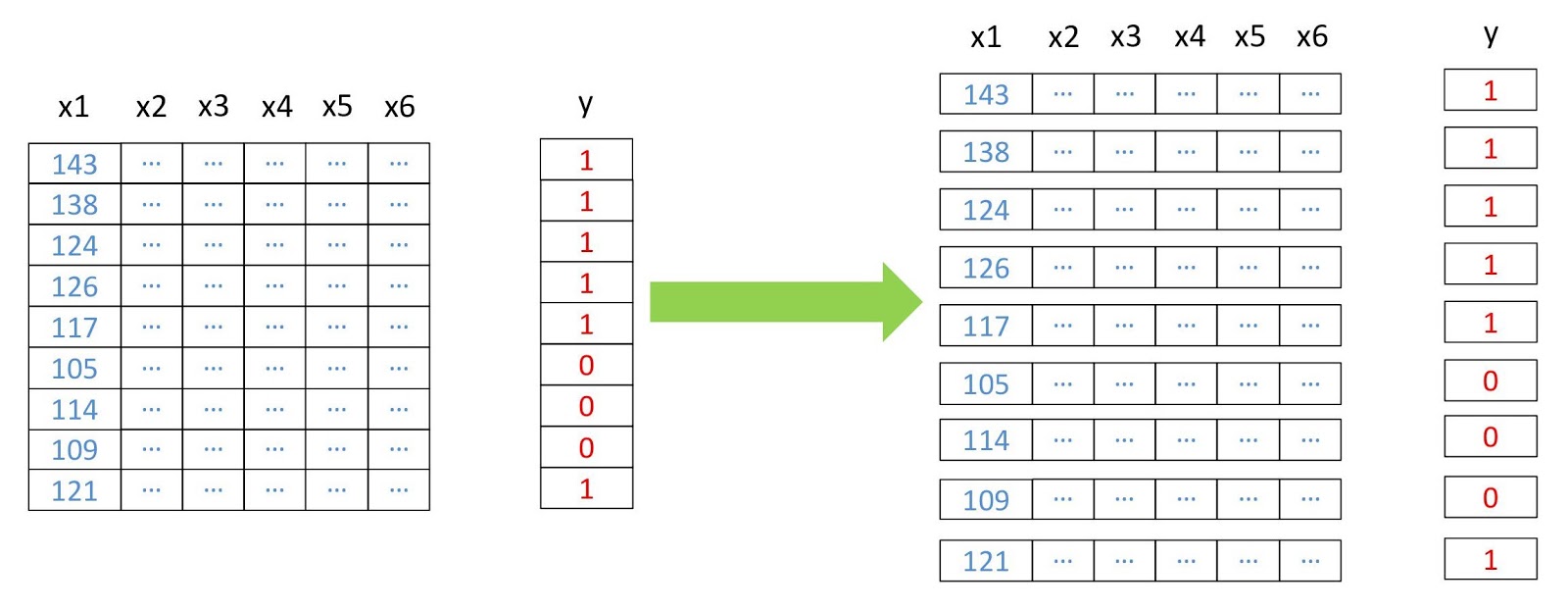
الآن نقوم بتحويل المصفوفات إلى ثنائي الأبعاد ، حيث يمثل كل صف بكسلًا منفصلًا ، لأن هذا ضروري لتشغيل معظم خوارزميات التعلم الآلي. سنفعل ذلك باستخدام وحدة
convert من حزمة
pyrsgis .
 مخطط إعادة هيكلة البيانات.
مخطط إعادة هيكلة البيانات. from pyrsgis.convert import changeDimension featuresBangalore = changeDimension(featuresBangalore) labelBangalore = changeDimension (labelBangalore) featuresHyderabad = changeDimension(featuresHyderabad) nBands = featuresBangalore.shape[1] labelBangalore = (labelBangalore == 1).astype(int) print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
النتيجة:
Bangalore multispectral image shape: 4198376, 6 Bangalore binary built-up image shape: 4198376 Hyderabad multispectral image shape: 1391808, 6
في الصف السابع ، استخرجنا جميع البيكسلات بقيمة 1. وهذا يساعد على تجنب مشاكل البيكسلات بدون معلومات (NoData) ، والتي غالباً ما تحتوي على قيم عالية أو منخفضة للغاية.
سنقوم الآن بتقسيم البيانات إلى عينات للتدريب والتحقق من الصحة. يعد ذلك ضروريًا حتى لا يرى النموذج بيانات الاختبار ويعمل تمامًا مع المعلومات الجديدة. وإلا ، سيتم إعادة تدريب النموذج وسيعمل بشكل جيد فقط على بيانات التدريب.
from sklearn.model_selection import train_test_split xTrain, xTest, yTrain, yTest = train_test_split(featuresBangalore, labelBangalore, test_size=0.4, random_state=42) print(xTrain.shape) print(yTrain.shape) print(xTest.shape) print(yTest.shape)
النتيجة:
(2519025, 6) (2519025,) (1679351, 6) (1679351,) test_size=0.4
يعني أن البيانات تنقسم إلى التدريب والتحقق من الصحة بنسبة 60/40.
تحتاج العديد من خوارزميات التعلم الآلي ، بما في ذلك الشبكات العصبية ، إلى بيانات طبيعية. هذا يعني أنه يجب توزيعها ضمن نطاق معين (في هذه الحالة ، من 0 إلى 1). لذلك ، لتحقيق هذا المطلب ، نحن تطبيع الأعراض. يمكن القيام بذلك عن طريق استخراج الحد الأدنى للقيمة ثم تقسيمها على السبريد (الفرق بين الحد الأقصى والحد الأدنى للقيم). نظرًا لأن مجموعة بيانات Landsat تتكون من ثمانية بتات ، ستكون القيم الدنيا والقصوى 0 و 255 (2 = = 256 قيمة).
لاحظ أنه للتطبيع ، من الأفضل دائمًا حساب الحد الأدنى والحد الأقصى للقيم بناءً على البيانات. لتبسيط المهمة ، سنلتزم بنطاق الثمانية بت افتراضيًا.
مرحلة أخرى من المعالجة المسبقة هي تحويل مصفوفة السمات من ثنائي الأبعاد إلى ثلاثي الأبعاد ، بحيث يرى النموذج كل صف على أنه بكسل منفصل (كائن تعليمي منفصل).
النتيجة:
(2519025, 1, 6) (1679351, 1, 6) (1391808, 1, 6)
كل شيء جاهز ، دعنا
نجمع نموذجنا مع
keras . للبدء ، دعونا نستخدم النموذج المتسلسل ، مضافين الطبقات الواحدة تلو الأخرى. سيكون لدينا طبقة إدخال واحدة مع عدد العقد مساوٍ لعدد النطاقات (
nBands ) - في حالتنا هناك 6. سنستخدم أيضًا طبقة مخفية واحدة مع 14 عقدة
ReLu تنشيط
ReLu . تتكون الطبقة الأخيرة من عقدتين لتحديد فئة بناء ثنائية مع
softmax تنشيط
softmax ، وهي مناسبة لعرض نتيجة مصنفة. اقرأ المزيد عن وظائف التنشيط
هنا .
from tensorflow import keras
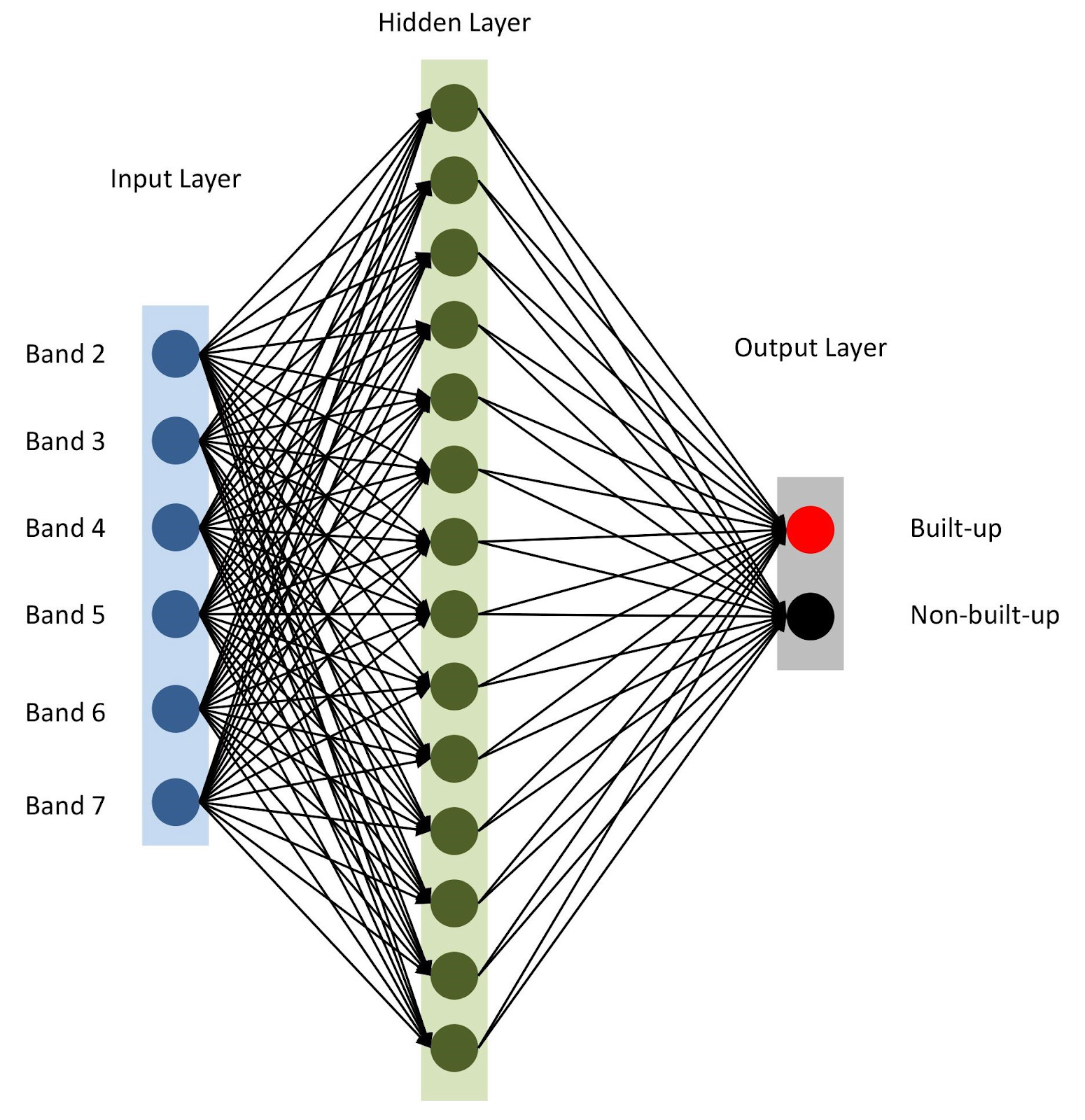 بنية الشبكة العصبية
بنية الشبكة العصبيةكما هو مذكور في السطر 10 ، نحدد
adam للطراز (يوجد العديد من النماذج
الأخرى ). في هذه الحالة ، سوف نستخدم الانتروبيا المتقاطعة كدالة خسارة (en.
categorical-sparse-crossentropy - المزيد عن ذلك مكتوب
هنا ). لتقييم جودة النموذج ، سوف نستخدم مقياس
accuracy .
أخيرًا ، سنبدأ في تدريب نموذجنا
xTrain (أو التكرارات) على
xTrain و
yTrain . سيستغرق ذلك بعض الوقت ، اعتمادًا على حجم البيانات وقوة المعالجة. إليك ما ستراه بعد التجميع:

دعنا نتنبأ بقيم بيانات التحقق من الصحة التي نقوم بتخزينها بشكل منفصل وحساب مقاييس الدقة المختلفة.
from sklearn.metrics import confusion_matrix, precision_score, recall_score
تقوم وظيفة
softmax بإنشاء أعمدة منفصلة لقيم الاحتمالات لكل فئة. نحن نستخدم فقط قيم الفئة الأولى ("هناك مبنى") ، كما يتضح من السطر السادس من الكود أعلاه. تقييم عمل نماذج التحليل الجيوفضائي ليس بهذه البساطة ، على عكس مهام التعلم الآلي الكلاسيكية الأخرى. سيكون من الظلم الاعتماد على خطأ كلي معمم. المفتاح لنموذج ناجح هو التخطيط المكاني. وبالتالي ، يمكن أن تعطي مصفوفة الارتباك والدقة والاكتمال فكرة أكثر دقة عن جودة النموذج.
 لذلك تعرض وحدة التحكم مصفوفة الخطأ والدقة والاكتمال.
لذلك تعرض وحدة التحكم مصفوفة الخطأ والدقة والاكتمال.كما ترون من مصفوفة الارتباك ، هناك الآلاف من وحدات البكسل المرتبطة بالمباني ، ولكن يتم تصنيفها بشكل مختلف ، والعكس صحيح. ومع ذلك ، فإن حصتها من إجمالي حجم البيانات ليست كبيرة جدًا. تجاوزت دقة واكتمال بيانات الاختبار عتبة 0.8.
يمكنك قضاء المزيد من الوقت وإجراء العديد من التكرارات للعثور على العدد الأمثل من الطبقات المخفية ، وعدد العقد في كل طبقة مخفية ، وكذلك عدد العصور لتحقيق الدقة المطلوبة. حسب الحاجة ، يمكن استخدام مؤشرات الاستشعار عن بُعد مثل NDBI أو NDWI كميزات. عند تحقيق الدقة المطلوبة ، استخدم النموذج للتنبؤ بالتطور استنادًا إلى بيانات جديدة وتصدير النتيجة إلى GeoTIFF. لمثل هذه المهام ، يمكنك استخدام نموذج مماثل مع تغييرات طفيفة.
predicted = model.predict(feature2005) predicted = predicted[:,1]
يرجى ملاحظة أننا نقوم بتصدير GeoTIFF بقيم الاحتمال المتوقعة ، وليس بإصدارها المحدود. في وقت لاحق في بيئة نظم المعلومات الجغرافية ، يمكننا ضبط القيمة الدنيا لطبقة من النوع float ، كما هو مبين في الشكل أدناه.
 طبقة حيدر أباد المبنية التي تنبأ بها النموذج بناءً على بيانات متعددة الأطياف.
طبقة حيدر أباد المبنية التي تنبأ بها النموذج بناءً على بيانات متعددة الأطياف.تم قياس دقة النموذج بالفعل بدقة واستدعاء. يمكنك أيضًا إجراء اختبارات تقليدية (على سبيل المثال ، باستخدام معامل kappa) على طبقة جديدة متوقعة. بالإضافة إلى الصعوبات المذكورة أعلاه في تصنيف صور الأقمار الصناعية ، تشمل القيود الواضحة الأخرى استحالة التنبؤ بناءً على الصور التي التقطت في أوقات مختلفة من السنة وفي مناطق مختلفة ، حيث سيكون لها توقيعات طيفية مختلفة.
يحتوي النموذج الموصوف في هذه المقالة على أبسط هندسة للشبكات العصبية. يمكن تحقيق نتائج أفضل من خلال نماذج أكثر تعقيدًا ، بما في ذلك الشبكات العصبية التلافيفية. الميزة الرئيسية لمثل هذا التصنيف هي قابلية التوسع (قابلية التطبيق) بعد تدريب النموذج.
البيانات المستخدمة وجميع رمز
هنا .