منظمة العفو الدولية على الحديد المحلية
نتحدث عن كيفية نقلنا إطار عملنا للشبكات العصبية ونظام التعرف على الوجوه إلى معالجات Elbrus الروسية.
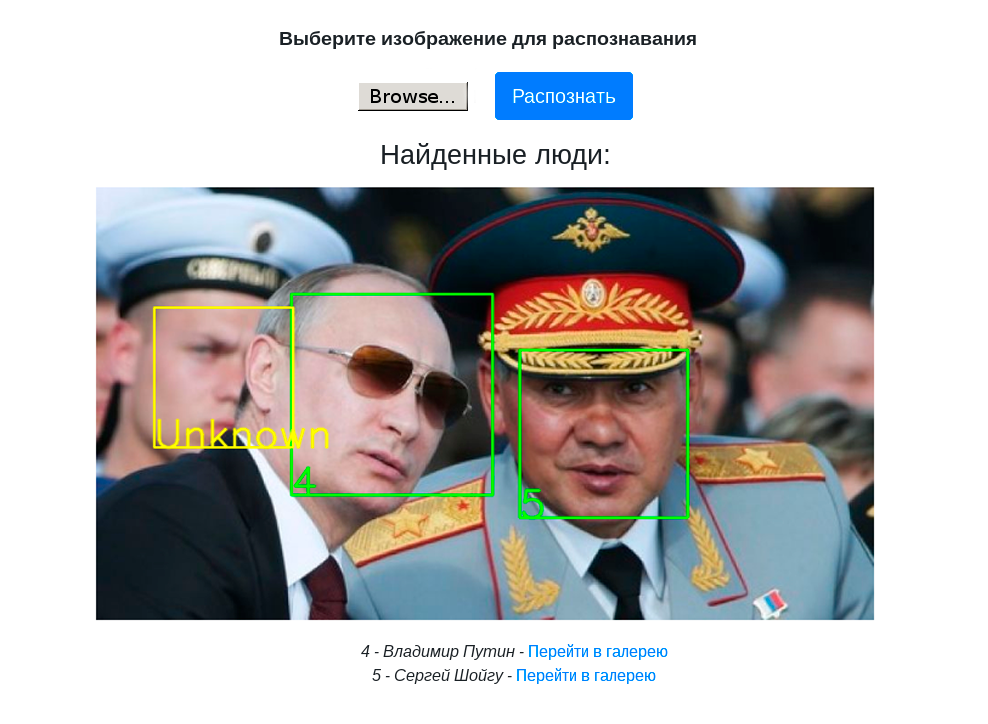
لقد كانت مهمة مثيرة للاهتمام ، في ربيع عام 2019 تحدثنا عن ذلك في مكتب ياندكس في الاجتماع الكبير حول Elbrus ، والآن نتشارك مع Habr.
لفترة وجيزة - ما هو Elbrus
هذا معالج روسي
بهيكله الخاص ، تم تطويره في
MCST . يتحدث مكسيم غورشينين عنه جيدًا على قناته:
www.youtube.com/watch؟v=H8eBgJ58EPYلفترة وجيزة - ما هو PuzzleLib
هذه هي منصتنا للشبكات العصبية ، التي نقوم بتطويرها واستخدامها منذ عام 2015. التناظرية من جوجل TensorFlow و Facebook PyTorch. ومن المثير للاهتمام ، أن PuzzleLib يدعم ليس فقط معالجات NVIDIA و Intel ، ولكن أيضًا بطاقات الفيديو AMD.
على الرغم من أن لدينا مكتبة صغيرة (يحتوي TensorFlow على حوالي مليوني خط ، ولدينا 100 ألف سطر) ، إلا أننا أفضل في السرعة - قليلاً ولكن أفضل =)
نحن لسنا بعد في المصادر المفتوحة ، يتم استخدام المكتبة لمشاريعنا. المكتبة كاملة: إنها تدعم كل من مرحلة التدريب ومرحلة الاستدلال للشبكات العصبية. يمكنك إنشاء شبكات عصبية تلافيفية متكررة ، وهناك أيضًا واجهة لإنشاء رسومات بيانية تعسفية للحسابات.
وقد PuzzleLib
- وحدات لتجميع الشبكات العصبية (التنشيط (Sigmoid ، Tanh ، ReLU ، ELU ، LeakyReLU ، SoftMaxPlus) ، AvgPool (1D ، 2D ، 3D) ، BatchNorm (1D ، 2D ، 3D ، ND) ، Conv (1D ، 2D ، 3D ، ND) ، CrossMapLRN ، Deconv (1D ، 2D ، 3D ، ND) ، التسرب (1D ، 2D) ، وما إلى ذلك)
- Optimizers (AdaDelta، AdaGrad، Adam، Hooks، LBFGS، MomentumSGD، NesterovSGD، RMSProp، etc.)
- شبكات عصبية جاهزة للاستخدام (Resnet ، Inception ، YOLO ، U-Net ، إلخ.)
هذه هي مألوفة ومألوفة لجميع المشاركين في الشبكات العصبية ، وكتل لمصممي الشبكات العصبية (لأن أي أطر هي بناة تتكون من كتل الحوسبة وخوارزميات نموذجية).
كان لدينا فكرة لإطلاق مكتبتنا على الهندسة المعمارية Elbrus.
لماذا نريد دعم Elbrus؟
- هذا هو المعالج الروسي الوحيد ، أردت أن أفهم كيف تسير الأمور معه ، ومدى سهولة التعامل معه.
- لقد اعتقدنا أنه قد يكون من المثير للاهتمام لمؤسسات الدولة أن البرنامج الروسي الذي نقوم بتطويره يعمل على الأجهزة الروسية.
- وبالطبع ، كنا مهتمين فقط ، لأن Elbrus هو معالج VLIW ، أي معالج بتعليمات طويلة ، ولا يوجد مثل هذه المعالجات الكاملة للأغراض العامة في العالم.
بدأ كل شيء بحقيقة أننا التقينا مع MCST وتحدثنا وأعارنا كمبيوتر
Elbrus 401 لتطويره.
ما أعجبني : يعمل Linux على Elbrus ، يوجد بيثون في هذا Linux ، ولا يعمل في وضع المحاكاة - إنه بيثون أصلي كامل ، تم تجميعه من أجل Elbrus. هناك أيضًا مجموعة من مكتبات python القياسية ، على سبيل المثال ، numpy ، والتي يحبها المطورون كثيرًا.
كانت هناك بعض المهام التي اضطررنا إلى جمع المكتبات بها بشكل إضافي: على سبيل المثال ، في PuzzleLib نستخدم تنسيق hdf لتخزين أوزان الشبكات العصبية ، وبالتالي ، كان علينا إنشاء مكتبات libhdf و h5py باستخدام برنامج التحويل البرمجي lcc. لكن لم يكن لدينا أي مشاكل في التجميع.
كما تم بالفعل تجميع مكتبة رؤية الكمبيوتر OpenCV ، ولكن لم يكن هناك أي ارتباط بيثون - لقد بنيناها بشكل منفصل.
مكتبة dlib الشهيرة هي أيضًا سهلة التجميع. كانت هناك صعوبات طفيفة فقط: كانت بعض ملفات هذا المشروع المفتوح المصدر بدون علامة bom لتحديد utf-8 ، مما أزعج lccer lccer. في الواقع ، كان هناك ببساطة تنسيق ملف غير صحيح ، والذي كان لا بد من تصحيحه في المصدر.
قررنا أن نبدأ في التعرف على الوجوه أولاً. هذه حالة استخدام مفهومة للكثيرين ، حيث يتم استخدام هذه التكنولوجيا. يحتوي PuzzleLib ، مثل المكتبات الأخرى ، على جزء خلفي كبير إلى حد ما ، أي ، قاعدة رمز خاصة ببنيات المعالج المختلفة.
لدينا الخلفية:- كودا (نفيديا)
- فتح CL + MI مفتوح (AMD)
- mlkDNN (Intel)
- وحدة المعالجة المركزية (numpy)
في Elbrus ، أطلقنا خلفية رائعة ، كانت بسيطة للغاية ، لأن النظام الأساسي يتطلب الحد الأدنى من كل شيء:
النظام الأساسي -> مترجم C90 -> الثعبان -> numpyلدينا مكتبة بدون أي عوامل معقدة (على سبيل المثال ، بدون أي أنظمة تجميع خاصة) - بالإضافة إلى حقيقة أننا نحتاج إلى جمع بعض المجلدات. أجرينا الاختبارات ، كل شيء يعمل - سواء شبكات التلافيفية والشبكات المتكررة. التعرف على الوجوه الذي أطلقناه بسيط للغاية ، يستند إلى Inception-ResNet.
النتائج الأولى للعملفي Intel Core i7 7700 ، كان وقت المعالجة لصورة واحدة 0.1 ثانية ، وهنا - 15. كان من الضروري التحسين.
بطبيعة الحال ، سيكون من الخطأ أن تكون الأمور سيئة للغاية.
كيف قمنا بتحسين الحوسبة
قمنا بقياس سرعة الاستدلال من خلال ملف التعريف بيثون ووجدنا أنه تقريبًا قضى كل الوقت في ضرب المصفوفات في حالة سيئة. بالنسبة للعينة ، كتبوا الضرب اليدوي البسيط للمصفوفة ، واتضح بالفعل أنه أسرع ، رغم أنه لم يكن من الواضح سبب ذلك.
يبدو أن numpy.dot كان يجب أن يكون مكتوبًا أقل سذاجة من الضرب البسيط. ومع ذلك ، فإننا مقتنعون ، فحصنا - اتضح أنه أسرع (12 ثانية لكل إطار بدلاً من 15).
بعد ذلك ، تعلمنا عن مكتبة الجبر الخطية EML ، التي يتم تطويرها في ICST ، واستبدلنا np.dot باستدعاءات cblas_sgemm. أصبح أسرع 10 مرات (1.5 ثانية) - كنا سعداء للغاية.
وتبع ذلك العديد من التحسينات خطوة بخطوة. نظرًا لأننا نقوم بتشغيل ميزة التعرف على الوجوه فقط ، وليس البيانات التعسفية بشكل عام ، فقد قررنا زيادة حدة عملياتنا فقط تحت التنسورات 4d وجعل Fusion - بعد ذلك انخفض وقت المعالجة بمقدار مرتين - إلى 0.75 ثانية.
Explanation: الانصهار هو عندما يتم دمج عدة عمليات في عملية واحدة ، على سبيل المثال ، الالتواء والتطبيع والتنشيط. بدلاً من المرور في ثلاث دورات ، يتم تمرير واحد.
تتوفر مثل هذه المكتبات من NVIDIA (
TensorRT ). يتم تحميل رسم بياني حسابي فيه ، وتنتج المكتبة رسمًا بيانيًا مُسارعًا مُحسَّنًا ، لا سيما بسبب حقيقة أنه يمكن أن ينهار العمليات في واحد. لدى Intel أيضًا مثيل واحد (nGraph و
OpenVINO ).
ثم رأينا أنه نظرًا لوجود عدد كبير من التصفيف 1 × 1 في Inception-ResNet ، فقد حصلنا على نسخ بيانات إضافية. قررنا أن نتخصص في حقيقة أننا نعمل على دفعات من صورة واحدة (بمعنى ، لا نعالج 100 صورة على دفعات ، ولكننا نوفر وضع الدفق) - هناك حالات الاستخدام هذه عندما تحتاج إلى العمل ليس مع المحفوظات ، ولكن مع دفق (على سبيل المثال ، للمراقبة بالفيديو أو ACS). لقد أنشأنا ممرًا متخصصًا بدون
im2col (تمت إزالة النسخ الكبيرة) - أصبح 0.45 ثانية.
ثم نظرنا مرة أخرى إلى المحلل ، كان لدينا كل شيء بالطريقة نفسها - على الرغم من أن جميع المراحل انكمشت في الوقت المناسب ، ما زلنا 80 ٪ من الوقت الذي يقضيه في حساب كتل الاستدلال التلافيفي.
أدركنا أننا في حاجة إلى
موازنة الجوهرة (المصفوفة العامة). هذه الأحجار الكريمة ، والتي في EML ، تبين أنها مترابطة. وفقا لذلك ، كان علينا أن نكتب جوهرة متعددة الخيوط أنفسنا. الفكرة هي: مصفوفة كبيرة تنقسم إلى كتل فرعية ، ثم هناك ضرب من هذه المصفوفات الصغيرة. لقد كتبنا جوهرة مع OpenMP ، لكنها لم تنجح ، تعطلت الأخطاء. أخذنا مجموعة يدوية من المواضيع ، أعطى التوازي 0.33 ثانية لكل إطار.
بعد ذلك ، تم منحنا إمكانية الوصول عن بُعد إلى خادم أكثر قوة باستخدام
Elbrus 8C ، حيث زادت السرعة إلى 0.2 ثانية لكل إطار.
يُظهر الفيديو التالي عمل الحامل التجريبي مع التعرف على الوجوه على كمبيوتر Elbrus 401-PC باستخدام معالج Elbrus 4C:
الاستنتاجات وخطط المستقبل
- لا نعمل فقط على التعرف على الوجوه ، ولكن من حيث المبدأ إطار عمل للشبكة العصبية ، حتى نتمكن من جمع أي أجهزة كشف وتصنيفات وتشغيلها على Elbrus.
- قمنا بتجميع موقف تجريبي مع Web-UI لإظهار التعرف على الوجوه على PuzzleLib.
- التعرف على الوجوه على Elbrus سريع بالفعل بما يكفي للقيام بالمهام العملية ، ثم يمكنك تسريع الأمر إذا لزم الأمر.
- يمكنك العمل مع Elbrus. اعتدنا على العمل مع المعالجات الغريبة - على سبيل المثال ، مع المعالجات الروسية التنسور التي لا تزال قيد التطوير ، مع بطاقات الفيديو AMD والبرامج الخاصة بهم. كل شيء ليس جيدًا وبسيطًا. أي إذا أخذنا مكتبة MI Open من AMD ، فهذه مكتبة مكتوبة بشكل سيء للغاية ولا تؤدي فيها جميع مجموعات الخطوات والباطل وأحجام المرشحات إلى حسابات ناجحة. جودة الأدوات من Elbrus جيدة - إذا كان لديك مشروع في Python أو C أو C ++ ، فإن تشغيله على Elbrus ليس بالأمر الصعب على الإطلاق.
- تجدر الإشارة أيضًا إلى أن العمل على التحسين التدريجي الذي تحدثنا عنه ليس عمليات محددة للعمل في Elbrus. هذه هي عمليات المعالجات متعددة النواة القياسية. في رأينا ، هذه علامة جيدة على أنه يمكن تشغيل المعالج كما هو الحال مع معالج منتظم من Intel / NVIDIA.
الخطط:
- نظرًا لوجود خصوصية Elbrus لأنه معالج VLIW ، يمكن إجراء بعض التحسينات الخاصة بـ Elbrus.
- قم بإجراء القياس الكمي (العمل مع int8 بدلاً من float32) ، مما يوفر الذاكرة ويزيد السرعة. وفقًا لذلك ، في هذه الحالة ، بالطبع ، قد يكون هناك انخفاض في جودة الحسابات - ولكن هذا قد لا يكون. لقد لاحظنا كلتا الحالتين في الممارسة.
نحن نخطط لمزيد من الفهم ، واستكشاف قدرات المعالج VLIW. في الواقع ، في الوقت الحالي ، لقد وثقنا فقط بالمترجم في أنه إذا كتبنا رمزًا جيدًا ، فسيقوم المترجم بتحسينه جيدًا ، لأنه يعرف ميزات Elbrus.
بشكل عام ، كان مثيرا للاهتمام ، وسوف نفهم أكثر من ذلك. هذا لم يستغرق الكثير من الوقت - استغرقت جميع عمليات النقل ما مجموعه أسبوع.
في يناير 2020 ، نخطط لوضع PuzzleLib في المصدر المفتوح ، وسوف نكتب المزيد عن هذا هنا =)
شكرا لاهتمامكم!