هذه المقالة هي محاولتي للتعبير عن رأيي في الجوانب التالية:
- ما هو عامل سرعة التعلم وما هي قيمته؟
- كيفية اختيار هذا المعامل عند نماذج التدريب؟
- لماذا من الضروري تغيير معامل سرعة التعلم أثناء تدريب النماذج؟
- ماذا تفعل مع عامل سرعة التعلم عند استخدام نموذج مدرّب مسبقًا؟
يعتمد معظم هذا
المنشور على المواد التي أعدها
fast.ai : [1] و [2] و [5] و [3] - تمثل نسخة موجزة من عملهم تهدف إلى فهم أسرع لجوهر القضية. للتعرف على التفاصيل ، يوصى بالضغط على الروابط أدناه.
ما هو عامل سرعة التعلم؟
معامل سرعة التعلم عبارة عن مقياس شائع يحدد الترتيب الذي سنعدل فيه مقاييسنا مع مراعاة دالة الخسارة في نزول التدرج. كلما انخفضت القيمة ، كلما تحركنا بشكل أبطأ عند الميل. على الرغم من أنه عند استخدام معامل سرعة منخفض للتعلم ، يمكن أن نحصل على تأثير إيجابي بمعنى أننا لا نضيع حداً أدنى محلي واحد ، لكن هذا قد يعني أيضًا أنه سيتعين علينا قضاء الكثير من الوقت في التقارب ، خاصة إذا كنا في منطقة الهضبة.
يتم توضيح العلاقة بواسطة الصيغة التالية
 هبوط متدرج مع عوامل سرعة تعلم صغيرة (أعلى) وكبيرة (أسفل). المصدر: دورة أندرو نغ في التعليم الآلي في كورسيرا
هبوط متدرج مع عوامل سرعة تعلم صغيرة (أعلى) وكبيرة (أسفل). المصدر: دورة أندرو نغ في التعليم الآلي في كورسيرا
في معظم الأحيان ، يتم تعيين عامل سرعة التعلم من قبل المستخدم بشكل تعسفي. في أحسن الأحوال ، للحصول على فهم سهل للقيمة الأكثر ملاءمة لتحديد معامل سرعة التعلم ، يمكنه الاعتماد على التجارب السابقة (أو أي نوع آخر من المواد التدريبية).
بشكل أساسي ، من الصعب اختيار القيمة الصحيحة. يوضح الرسم البياني أدناه العديد من السيناريوهات التي قد تنشأ عندما يقوم المستخدم بضبط معدل سرعة التعلم بشكل مستقل.
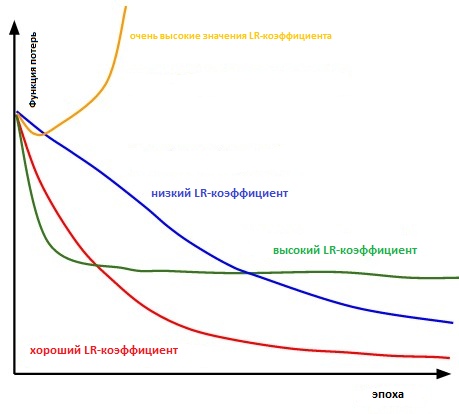 تأثير عوامل معدل التعلم المختلفة على التقارب. (Img Credit: cs231n)
تأثير عوامل معدل التعلم المختلفة على التقارب. (Img Credit: cs231n)
علاوة على ذلك ، يؤثر عامل سرعة التعلم على مدى سرعة وصول نموذجنا إلى الحد الأدنى المحلي (الملقب سيحقق أفضل دقة). وبالتالي ، فإن الاختيار الصحيح من البداية يضمن قدرا أقل من الوقت لتدريب النموذج. كلما قل وقت التدريب ، تم إنفاق أموال أقل على قوة حساب GPU في السحابة.
هل هناك طريقة أكثر ملاءمة لتحديد معدل معامل التعلم؟
في الفقرة 3.3. "
معاملات معدل التعلم الدوري للشبكات العصبية " ، دعت ليزلي سميث إلى ما يلي: يمكن تقدير كفاءة التعلم من خلال تدريب نموذج بسرعة تعلم منخفضة مبدئيًا ، والتي تزيد بعد ذلك (خطيًا أو أسيًا) في كل تكرار.
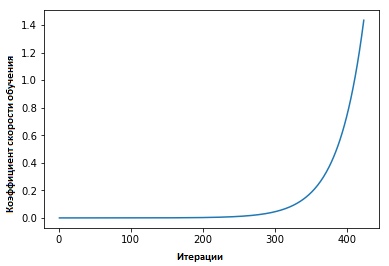 يزيد عامل سرعة التعلم بعد كل حزمة صغيرة.
يزيد عامل سرعة التعلم بعد كل حزمة صغيرة.
إصلاح قيم المؤشرات في كل تكرار ، سنرى أنه كلما زادت سرعة التعلم ، سيتم الوصول إلى نقطة تتوقف عندها قيمة وظيفة الخسارة وتبدأ في الزيادة. في الممارسة العملية ، يجب أن تكون سرعة التعلم لدينا في مكان ما على يسار النقطة السفلية على الرسم البياني (كما هو موضح في الرسم البياني أدناه). في هذه الحالة (ستكون القيمة) من 0.001 إلى 0.01.
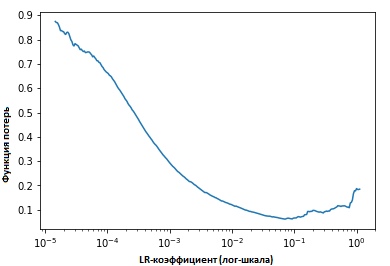
ما سبق يبدو مفيدا. كيف تبدأ في استخدامه؟
في الوقت الحالي ، توجد وظيفة جاهزة في حزمة
fast.ia التي طورها جيريمي هوارد ، وهذا نوع من التجريد / الإضافة في أعلى مكتبة pytorch (على غرار الطريقة التي يتم بها في حالة Keras و Tensorflow).
من الضروري فقط إدخال الأمر التالي لبدء البحث عن المعامل الأمثل لسرعة التعلم قبل (بدء) تدريب الشبكة العصبية.
learn.lr_find() learn.sched.plot_lr()
تحسين النموذج
لذلك ، تحدثنا عن ما هو معامل سرعة التعلم ، ما هي قيمتها وكيفية تحقيق قيمتها المثلى قبل البدء في تدريب النموذج نفسه.
سنركز الآن على كيفية استخدام عامل سرعة التعلم لضبط النماذج.
الحكمة التقليدية
عادة ، عندما يقوم المستخدم بتعيين معامل سرعة التعلم الخاص به ويبدأ تدريب النموذج ، فإنه يحتاج إلى الانتظار حتى يبدأ معامل سرعة التعلم في الانخفاض ويصل النموذج إلى القيمة المثلى.
ومع ذلك ، فمنذ اللحظة التي يصل فيها التدرج إلى هضبة ، يصبح من الصعب تحسين قيم وظيفة الخسارة عند تدريب النموذج. في [3] ، تعبر Dauphin عن وجهة نظر مفادها أن الصعوبة في تقليل وظيفة الخسارة تنبع من نقطة السرج ، وليس من الحد الأدنى المحلي.
 نقطة سرج على سطح الأخطاء. نقطة السرج هي نقطة من مجال تعريف دالة ثابتة لوظيفة معينة ، ولكنها ليست الطرف المحلي لها
نقطة سرج على سطح الأخطاء. نقطة السرج هي نقطة من مجال تعريف دالة ثابتة لوظيفة معينة ، ولكنها ليست الطرف المحلي لها . (ImgCredit: safaribooksonline)
فكيف يمكن تجنب هذا؟
أقترح النظر في عدة خيارات. واحد منهم ، العام ، وذلك باستخدام الاقتباس من [1] ،
... بدلاً من استخدام قيمة ثابتة لمعامل سرعة التعلم وتقليله بمرور الوقت ، إذا لم يعد التدريب يخفف من خسائرنا ، فسوف نقوم بتغيير معامل سرعة التعلم في كل تكرار وفقًا لبعض الوظائف الدورية f. كل حلقة لها - من حيث عدد التكرارات - طول ثابت. تتيح هذه الطريقة أن يختلف معامل سرعة التعلم بين القيم الحدية المعقولة. هذا يساعد حقًا ، لأننا نتعاطى في نقاط السرج ، من خلال زيادة معامل سرعة التعلم ، نحصل على تقاطع أسرع لهضبة السرج
في [2] ، يقترح ليزلي "طريقة المثلث" ، حيث يتم مراجعة معامل سرعة التعلم بعد كل تكرار من عدة.

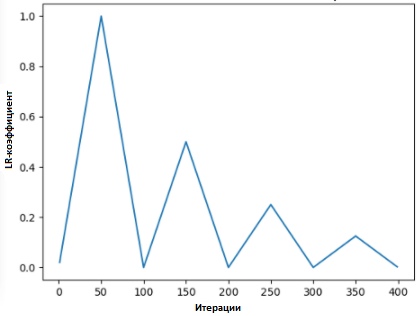 "طريقة المثلثات" و "طريقة المثلثات -2" هي طرق للاختبار الدوري لمعاملات معدل التعلم ، اقترحته ليزلي إن سميث. في الرسم البياني العلوي ، يتم الحفاظ على الحد الأدنى والحد الأقصى Ir متساوية.
"طريقة المثلثات" و "طريقة المثلثات -2" هي طرق للاختبار الدوري لمعاملات معدل التعلم ، اقترحته ليزلي إن سميث. في الرسم البياني العلوي ، يتم الحفاظ على الحد الأدنى والحد الأقصى Ir متساوية.اقترح Lonchilov & Hutter [6] طريقة أخرى ، وهي ليست أقل شعبية وتسمى "هبوط التدرج العشوائي مع إعادة تعيين دافئة". هذه الطريقة ، التي تعتمد على استخدام دالة جيب التمام كدورة دورية ، تعيد تشغيل معامل سرعة التعلم عند أقصى نقطة في كل دورة. يرجع مظهر البت "الساخن" إلى حقيقة أنه عند إعادة تشغيل معامل معدل التعلم ، لا يبدأ من مستوى الصفر ، ولكن من المعلمات التي وصل إليها النموذج في الخطوة السابقة.
نظرًا لأن هذه الطريقة بها اختلافات ، فإن الرسم البياني أدناه يعرض إحدى طرق تطبيقه ، حيث ترتبط كل دورة بالفاصل الزمني نفسه.
 SGDR - الرسم البياني ، معامل معدل التعلم مقابل التكرارات
SGDR - الرسم البياني ، معامل معدل التعلم مقابل التكرارات
وبالتالي ، لدينا طريقة لتقصير مدة التدريب بمجرد القفز فوق "القمم" من وقت لآخر (كما هو موضح أدناه).
 مقارنة معاملات معدل التعلم الثابت والدوري
مقارنة معاملات معدل التعلم الثابت والدوري (img credit:
arxiv.org/abs/1704.00109بالإضافة إلى توفير الوقت ، تعمل هذه الطريقة ، وفقًا للدراسات ، على تحسين دقة التصنيف دون توليف وتكرار أقل.
نقل نسبة التعلم في نقل التعلم
في سياق
fast.ai ، يتم التركيز على إدارة نموذج تم تدريبه مسبقًا في حل مشكلات الذكاء الاصطناعي. على سبيل المثال ، عند حل مشكلات تصنيف الصور ، يتم تعليم الطلاب كيفية استخدام النماذج المدربة مسبقًا مثل VGG و Resnet50 وربطها بعينة من بيانات الصورة التي يجب التنبؤ بها.
لتلخيص كيف تم بناء النموذج في برنامج
fast.ai (يجب عدم الخلط بينه وبين
fast. حزمة Ai - الحزمة من البرنامج) ، فيما يلي الخطوات التي
سنتخذها في الموقف العادي:
- تمكين زيادة البيانات و precompute = صحيح
- استخدم Ir_find () للعثور على أعلى معامل معدل للتعلم ، حيث لا يزال الفقد يتحسن بوضوح.
- تدريب الطبقة الأخيرة من عمليات التنشيط المحسوبة مسبقًا لعصر 1-2.
- تدريب الطبقة الأخيرة مع الحصول على البيانات (على سبيل المثال ، حساب = خطأ) لمدة 1-2 حقبة مع دورة _len 1.
- ذوبان الجليد جميع الطبقات.
- ضع الطبقات السابقة في عامل سرعة التعلم الذي يتراوح بين 3x و 10x أسفل الطبقة العليا التالية
- إعادة استخدام Ir_find ()
- تدريب شبكة كاملة مع دورة _mult = 2 = 2 حتى يبدأ إعادة التدريب.
قد تلاحظ أن الخطوات 2 و 5 و 7 (أعلاه) مرتبطة بمعدل عامل التعلم. في جزء سابق من منشورنا ، أبرزنا نقطة الخطوات المذكورة الثانية - حيث تطرقنا إلى كيفية الحصول على أفضل معامل سرعة التعلم قبل البدء في تدريب النموذج.
في الفقرة التالية ، تحدثنا عن كيف يمكنك تقليل وقت التدريب باستخدام SGDR ، ومن خلال إعادة تشغيل عامل سرعة التعلم بشكل دوري ، قم بتحسين الدقة بحيث يمكنك تجنب المناطق التي يكون فيها التدرج اللوني قريبًا من الصفر.
في القسم الأخير ، سوف نتطرق إلى مفهوم التعلم المتباين ونوضح كيف يتم استخدامه لتحديد معامل سرعة التعلم عندما يرتبط نموذج مدرّب بمدربة سابقة التدريب ...
ما هو التعلم التفاضلي
هذه هي الطريقة التي يتم بها تعيين عوامل سرعة التدريب المختلفة على الشبكة أثناء التدريب. إنه يوفر بديلاً للطريقة التي يقوم بها المستخدمون عادةً بضبط عوامل سرعة التعلم - أي استخدام نفس عامل سرعة التعلم من خلال الشبكة أثناء التدريب.
 السبب في أنني أحب Twitter هو استجابة مباشرة من الشخص نفسه.
السبب في أنني أحب Twitter هو استجابة مباشرة من الشخص نفسه.
(في وقت كتابة هذا المقال ، نشر جيريمي مقالًا مع سيباستيان رودر ، الذي تعمق أكثر في هذا الموضوع. لذلك ، أعتقد أن المعامل التفاضلي لسرعة التعلم له الآن اسم آخر - الضبط الدقيق التمييزي :)
لإظهار المفهوم بشكل أكثر وضوحًا ، يمكننا الرجوع إلى الرسم البياني أدناه ، حيث يتم تقسيم "النموذج المُدرَّب مسبقًا" إلى 3 مجموعات ، حيث يتم ضبط كل منها مع زيادة قيمة معامل سرعة التعلم.
 مثال CNN مع معامل معدل التعلم المتباين
مثال CNN مع معامل معدل التعلم المتباين . رصيد الصورة من [3]
تتضمن طريقة التكوين هذه الفهم التالي: تحتوي الطبقات القليلة الأولى عادةً على تفاصيل صغيرة جدًا للبيانات ، مثل الخطوط والزوايا - والتي لن نحاول تغييرها كثيرًا ومحاولة حفظ المعلومات الموجودة فيها. بشكل عام ، ليست هناك حاجة جادة لتغيير وزنهم لأي عدد كبير.
على العكس من ذلك ، بالنسبة للطبقات اللاحقة - مثل تلك الموجودة في الصورة المطلية باللون الأخضر ، حيث نحصل على علامات تفصيلية للبيانات ، مثل بياض العينين ، أو الفم ، أو الأنف - تختفي الحاجة إلى حفظها.
كيف يمكن مقارنة هذا مع أساليب ضبط أخرى؟
في [9] ، ثبت أن ضبط النموذج بالكامل سيكون مكلفًا للغاية ، حيث يمكن للمستخدمين الحصول على أكثر من 100 طبقة. في معظم الأحيان ، يلجأ الناس إلى تحسين نموذج طبقة واحدة في وقت واحد.
ومع ذلك ، هذا هو السبب وراء عدد من المتطلبات ، ما يسمى تداخل التزامن ، ويتطلب مدخلات متعددة من خلال مجموعة البيانات ، مما يؤدي إلى الإفراط في تدريب مجموعات صغيرة.
لقد أظهرنا أيضًا أن الأساليب المقدمة في [9] قادرة على تحسين الدقة وتقليل عدد الأخطاء في المهام المختلفة المتعلقة بتصنيف NRL.
 النتائج مأخوذة من المصدر [9]
النتائج مأخوذة من المصدر [9]المراجع:
[1] تحسين طريقة عملنا مع معدل التعلم.
[2] تقنية معدل التعلم الدوري.
[3] نقل التعلم باستخدام معدلات التعلم التفاضلية.
[4] ليزلي إن سميث. معدلات التعلم الدوري لتدريب الشبكات العصبية.
[5] تقدير معدل التعلم الأمثل لشبكة عصبية عميقة
[6] هبوط مؤشر ستوكاستيك مع إعادة التشغيل الدافئة
[7] التحسين لمقاطع التعلم العميق في عام 2017
[8] دفتر الدرس الأول ، fast.ai Part 1 V2
[9] نماذج لغة مضبوطة لتصنيف النصوص