اسمي إيفان بوندارينكو. لقد عملت على خوارزميات التعلم الآلي لتحليل النص واللغة المنطوقة منذ عام 2005. أعمل الآن في موسكو PhysTech كمطور علمي رائد لمختبر حلول الأعمال على أساس مركز STI للكفاءة في الذكاء الاصطناعي MIPT وفي شركة Data Monsters ، التي تتعامل مع التطوير العملي للأنظمة التفاعلية لحل المشكلات المختلفة في الصناعة. أنا أيضا تدريس قليلا في جامعتنا. سيتم تكريس قصتي لماهية روبوت الدردشة ، وكيفية استخدام خوارزميات التعلم الآلي وغيرها من الأساليب لأتمتة الاتصالات بين الإنسان والحاسوب وأين يمكن تنفيذها.
يمكن مشاهدة النسخة الكاملة لخطابي في "ليلة القصص العلمية" في
الفيديو ، وسأقدم ملخصات موجزة في النص أدناه.

قدرات الخوارزمية
بادئ ذي بدء ، يتم استخدام خوارزميات التفاعل البشري بنجاح في مراكز الاتصال. عمل مشغل مركز الاتصال صعب ومكلف للغاية. علاوة على ذلك ، في كثير من الحالات يكاد يكون من المستحيل حل مشكلة الاتصال بين الإنسان والحاسوب بالكامل. إنه شيء واحد عندما نعمل مع أحد البنوك ، التي عادة ما تضم عدة آلاف من العملاء. يمكنك تعيين موظفي مركز الاتصال الذين يخدمون هؤلاء العملاء والتحدث معهم. لكن عندما نحل المهام الأكثر طموحًا (على سبيل المثال ، ننتج الهواتف الذكية أو بعض الأجهزة الإلكترونية الاستهلاكية الأخرى) ، فإن عملائنا ليسوا عدة آلاف ، بل عدة عشرات من الملايين حول العالم. ونحن نريد أن نفهم ما هي المشاكل التي يواجهها الناس مع منتجاتنا. كقاعدة عامة ، يقوم المستخدمون بمشاركة المعلومات مع بعضهم البعض في المنتديات أو الكتابة إلى خدمة دعم الشركة المصنعة للهواتف الذكية. لن يتمكن المشغلون المباشرون من التعامل مع العمل على قاعدة عملاء ضخمة ، وهنا تأتي الخوارزميات في عملية الإنقاذ ، والتي يمكن أن تعمل في وضع متعدد القنوات ، وتخدم عددًا كبيرًا من الأشخاص.
لحل هذه المشاكل ، لإنشاء خوارزميات لأنظمة الحوار التي يمكن أن تتفاعل مع شخص ما واستخراج المعنى ، والمعلومات المهمة من الرسائل التعسفية ، هناك مجال كامل في مجال اللغويات الحاسوبية - تحليل النصوص في اللغة الطبيعية. يجب أن يكون الروبوت قادرًا على القراءة والفهم والاستماع والتحدث وما إلى ذلك. هذا المجال - معالجة اللغة الطبيعية - ينقسم إلى عدة أجزاء.
فهم النص (فهم اللغة الطبيعية ، NLU).
عندما يتواصل الروبوت مع شخص ويكتب شخص ما شيئًا ما للروبوت ، فأنت بحاجة إلى فهم ما هو مكتوب ، وما يريده المستخدم ، والذي ذكره في كلمته. فهم نوايا المستخدم ، ما يسمى النية - ما يريده الشخص: إعادة إصدار بطاقة مصرفية أو طلب البيتزا. وتخصيص الكيانات المسماة ، أي الأشياء التي يتحدث عنها المستخدم على وجه التحديد: إذا كانت البيتزا ، ثم "Margarita" أو "Hawaiian" ، إذا كانت البطاقة ، ثم أي نظام - MasterCard ، World وما إلى ذلك.

وأخيراً ، فهم لونية الرسالة - ما هي الحالة العاطفية للشخص. يجب أن تكون الخوارزمية قادرة على اكتشاف المفتاح الذي تتم كتابة الرسالة فيه ، إما أن يكون نصًا للأخبار ، أو تكون هذه الرسالة من شخص يتواصل مع برنامج الروبوت الخاص بنا من أجل الاستجابة بشكل مناسب للمفتاح.
 إنشاء النص (إنشاء لغة طبيعية)
إنشاء النص (إنشاء لغة طبيعية) - استجابة كافية لطلب إنساني بنفس اللغة البشرية (الطبيعية) ، وليس لوحة معقدة وليس عبارات رسمية.
التعرف على الكلام وتوليف الكلام (خطاب إلى نص وتحويل النص إلى كلام). إذا كان chatbot لا يتوافق مع الشخص فحسب ، بل يتحدث ويتحدث ، فستحتاج إلى تعليمه فهم اللغة المنطوقة ، وتحويل الاهتزازات الصوتية إلى نص ، ثم تحليل هذا النص باستخدام وحدة فهم النص ، وإنشاء اهتزازات صوتية من نص الاستجابة ، بدوره ثم الشخص ، سوف يسمع المشترك.
أنواع الدردشة البوتات
Chatbots تشمل العديد من الهياكل الرئيسية.
يعد chatbot الذي يجيب على الأسئلة الأكثر شيوعًا (FAQ-chatbot) هو الخيار الأسهل. يمكننا دائمًا صياغة مجموعة من الأسئلة النموذجية التي يطرحها الناس. بالنسبة إلى موقع لتوصيل الأغذية الجاهزة ، كقاعدة عامة ، فهذه هي الأسئلة: "كم ستكون تكلفة التوصيل" ، "هل تقوم بتسليمها إلى Pervomaisky district" ، وما إلى ذلك. يمكنك تجميعها وفقًا لعدة فئات ، ونوايا ، ونوايا المستخدم. ولكل نية ، حدد إجابات نموذجية.
استهداف الدردشة بوت (الهدف الموجه بوت). حاولت هنا إظهار بنية مثل chatbot ، الذي يتم تنفيذه في مشروع iPavlov. iPavlov هو مشروع لخلق الذكاء الاصطناعي للمحادثة. على وجه الخصوص ، يساعد chatbot المركز المستخدم على تحقيق هدف (على سبيل المثال ، حجز طاولة في مطعم أو طلب البيتزا ، أو معرفة شيء ما عن المشاكل في البنك). الأمر لا يتعلق فقط بالإجابة على السؤال (السؤال - الإجابة - بدون أي سياق). يحتوي chatbot المستهدف على وحدة لفهم النص وإدارة الحوار ووحدة لتوليد الاستجابات.
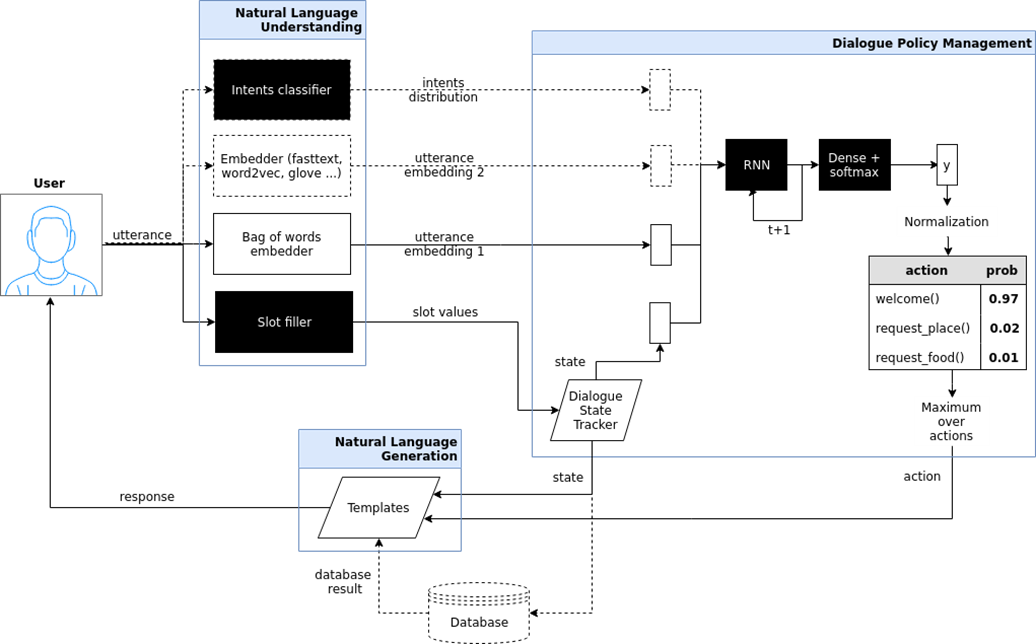 دردشة روبوتات السؤال الإجابة على نظام الإجابة على السؤال ونظام "المتكلمين" فقط (شيت دردشة بوت).
دردشة روبوتات السؤال الإجابة على نظام الإجابة على السؤال ونظام "المتكلمين" فقط (شيت دردشة بوت). إذا كان النوعان السابقان من روبوتات الدردشة إما يجيبان على الأسئلة الأكثر شيوعًا أو يقودان المستخدم عبر مربع الحوار ، في النهاية ، يساعدان في حجز مطعم ، ويكتشفان ما يريده المستخدم ، أو المطبخ الصيني أو الإيطالي ، إلخ ، ثم إجابة السؤال النظام هو نوع آخر من برامج الدردشة. ليس هدف روبوت الدردشة هذا هو التحرك على طول عمود الحوار وليس فقط تصنيف نوايا المستخدم ، بل تقديم بحث عن المعلومات - للعثور على المستند الأكثر ملاءمة الذي يطابق سؤال الشخص والمكان الذي يحتوي عليه الجواب. على سبيل المثال ، يقوم موظفو تاجر تجزئة كبير بدلاً من حفظ الإرشادات التي تحكم العمل ، أو يبحثون عن إجابة أين يضعون الحنطة السوداء ، بطرح سؤال لمثل chatbot بناءً على نظام الإجابة عن الأسئلة.
أنواع التعلم الآلي
من المستحيل تنفيذ الاعتراف بالنوايا ، وتخصيص الكيانات المسماة ، والبحث في المستندات والبحث عن الأماكن في وثيقة تتوافق مع دلالات السؤال - كل هذا دون التعلم الآلي ، دون نوع من التحليل الإحصائي. لذلك ، فإن أساس روبوتات الدردشة الحديثة هو التعلم الآلي - أساليب المهمة ، وتقريب بعض الأنماط المخفية الموجودة في مجموعات البيانات الكبيرة وتحديد هذه الأنماط. من المنطقي تطبيق هذا النهج عندما يكون هناك أنماط ومهام ، لكن من المستحيل التوصل إلى صيغة بسيطة ، شكلية لوصف هذا النمط.
هناك عدة أنواع من التعلم الآلي: مع المعلم (التعلم الخاضع للإشراف) ، بدون المعلم (التعلم غير الخاضع للإشراف) ، مع التعزيز (التعلم التعزيز). نحن مهتمون في المقام الأول بمهمة التدريس مع المعلم - عند وجود مدخلات صور وتعليمات (علامات) للمعلم وتصنيف هذه الصور. أو إشارات الكلام المدخلة وتصنيفها. ونحن نعلم الروبوت لدينا ، خوارزمية لدينا لإعادة إنتاج عمل المعلم.
حسنًا ، يبدو أن كل شيء رائع. وكيف لتعليم الكمبيوتر لفهم النصوص؟ النص كائن معقد ، وكيف تتحول الحروف إلى أرقام وتوصل إلى وصف متجه للنص؟ هناك أبسط خيار - "حقيبة الكلمات". نطلب قاموس النظام بأكمله ، على سبيل المثال ، كل الكلمات الموجودة باللغة الروسية ، ونصوغ مثل هذه المتجهات شديدة التكرار بترددات الكلمات. هذا الخيار مناسب للأسئلة البسيطة ، لكن بالنسبة للمهام الأكثر تعقيدًا فهو غير مناسب.
في عام 2013 ، حدث نوع من الثورة في نمذجة الكلمات والنصوص. اقترح توماس ميكولوف مقاربة خاصة للتمثيل الفعال لناقلات الكلمات بناءً على فرضية التوزيع. إذا تم العثور على كلمات مختلفة في نفس السياق ، عندها يكون هناك شيء مشترك. على سبيل المثال: "أجرى العلماء تحليلًا للخوارزميات" و "أجرى العلماء دراسة للخوارزميات". لذا ، فإن "التحليل" و "البحث" مرادفان ويعنيان نفس الشيء تقريبًا. لذلك ، يمكنك تعليم شبكة عصبية خاصة للتنبؤ بكلمة أو سياق أو كلمة.
أخيرًا ، كيف نتدرب؟ من أجل تدريب الروبوت لفهم النوايا ، النوايا الحقيقية ، تحتاج إلى ترميز مجموعة من النصوص يدويًا باستخدام برامج خاصة. لتعليم الروبوت لفهم الكيانات المسماة - اسم الشخص ، واسم الشركة ، والموقع - تحتاج أيضًا إلى وضع النصوص. وفقًا لذلك ، من ناحية ، تعد خوارزمية التعلم مع المعلم هي الأكثر فاعلية ، فهي تتيح لك إنشاء نظام التعرف الفعال ، ولكن من ناحية أخرى ، تنشأ مشكلة: تحتاج إلى مجموعات بيانات كبيرة ذات علامات ، وهذا مكلف ويستغرق وقتًا طويلاً. في عملية ترميز مجموعات البيانات ، قد تكون هناك أخطاء ناتجة عن العامل البشري.
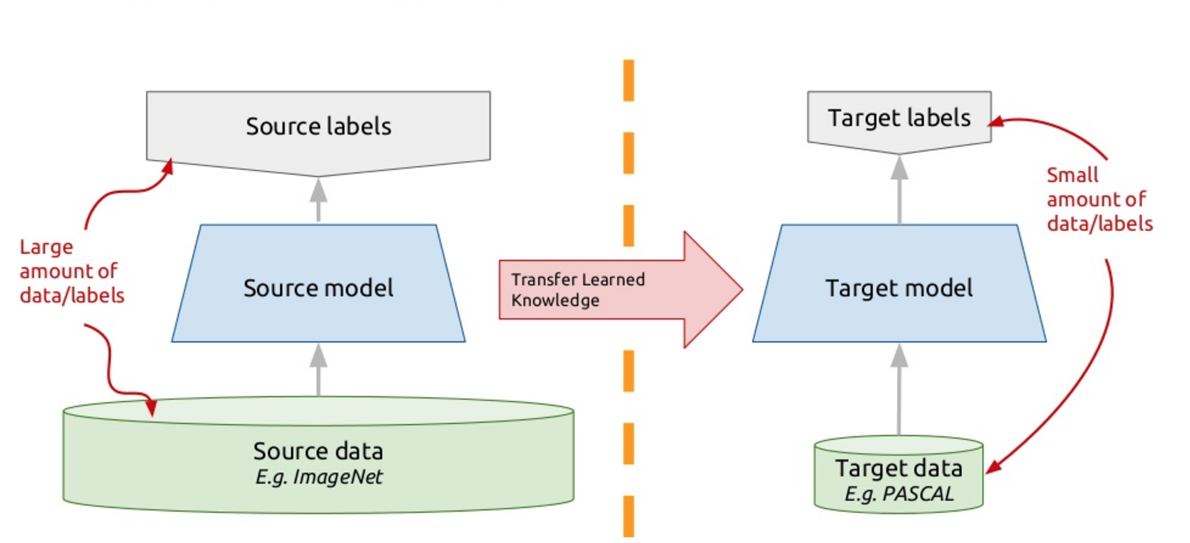
لحل هذه المشكلة ، تستخدم برامج الدردشة الحديثة ما يسمى نقل التعلم - نقل التعلم. أولئك الذين يعرفون العديد من اللغات الأجنبية ، ربما لاحظوا هذا الفارق البسيط لدرجة أنه من الأسهل تعلم لغة أجنبية أخرى من الأولى. في الواقع ، عندما تدرس بعض المهام الجديدة ، فإنك تحاول استخدام تجربتك السابقة لهذا الغرض. لذلك ، يعتمد نقل التعلم على هذا المبدأ: نحن نعلم الخوارزمية لحل مشكلة واحدة لدينا مجموعة كبيرة من البيانات من أجلها. ثم هذه الخوارزمية المدربة (أي أننا نأخذ الخوارزمية ليس من نقطة الصفر ، ولكن مدربين على حل مشكلة أخرى) ، نحن ندرب لحل مشكلتنا. وبالتالي ، نحصل على حل فعال باستخدام مجموعة صغيرة من البيانات.
أحد هذه النماذج هو ELMo (الزخارف من نماذج اللغة) ، مثل ELMo من Sesame Street. نحن نستخدم الشبكات العصبية المتكررة ، لديهم ذاكرة ويمكن معالجة تسلسل. على سبيل المثال: "مبرمج فازيا يحب البيرة. كل مساء بعد العمل ، يذهب إلى جوناثان ويفتقد كوبًا أو اثنين ". من هو؟ هل هو هذا المساء ، هل هو بيرة ، أم أنه مبرمج فازيا؟ يمكن للشبكة العصبية التي تعالج الكلمات كعناصر تسلسل ، بالنظر إلى السياق ، وهي شبكة عصبية متكررة ، أن تفهم العلاقات وحل هذه المشكلة وتسليط الضوء على نوع من الدلالات.
نحن ندرب مثل هذه الشبكة العصبية العميقة لتصميم النصوص. بشكل رسمي ، هذه هي مهمة التعلم مع المعلم ، ولكن المعلم هو النص غير الموضع نفسه. الكلمة التالية في النص هي معلم بالنسبة لجميع الكلمات السابقة. وبالتالي ، يمكننا استخدام غيغا بايت ، وعشرات غيغا بايت من النصوص ، وتدريب النماذج الفعالة التي تؤكد عليها دلالات في هذه النصوص. ثم ، عندما نستخدم Embeddings from Language Models (ELMo) في وضع الإخراج ، نعطي الكلمة بناءً على السياق. ليس مجرد عصا ، ولكن دعنا نلتزم. نحن ننظر إلى ما يولد الشبكة العصبية في هذه المرحلة من الزمن ، والذي يشير. نقوم بجمع هذه الإشارات والحصول على تمثيل متجه للكلمة في نص معين ، مع مراعاة أهميتها المحددة المحددة.
في تحليل النصوص ، هناك ميزة أخرى: عندما يتم حل مهمة الترجمة الآلية ، يمكن نقل المعنى نفسه بعدد من الكلمات باللغة الإنجليزية وعدد آخر من الكلمات باللغة الروسية. وفقًا لذلك ، لا توجد مقارنة خطية ، ونحن بحاجة إلى آلية من شأنها أن تركز على أجزاء معينة من النص من أجل ترجمتها بشكل كاف إلى لغة أخرى. في البداية ، تم اختراع الانتباه للترجمة الآلية - مهمة تحويل نص إلى آخر باستخدام أنظمة عصبية متكررة تقليدية. نضيف إلى هذا طبقة خاصة من الاهتمام ، والتي في كل لحظة من الزمن تقيم الكلمة المهمة بالنسبة لنا الآن.
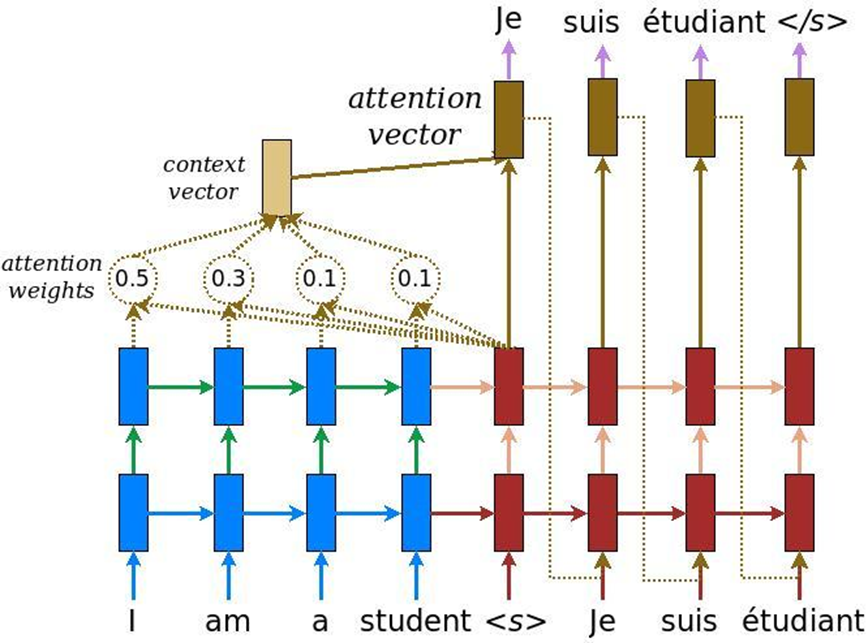
ولكن بعد ذلك ، فكر شباب Google ، لماذا لا يستخدمون آلية الانتباه على الإطلاق دون وجود شبكات عصبية متكررة - مجرد اهتمام. وقد توصلوا إلى بنية تسمى المحولات (BERT (تمثيلات التشفير ثنائية الاتجاه من المحولات)).
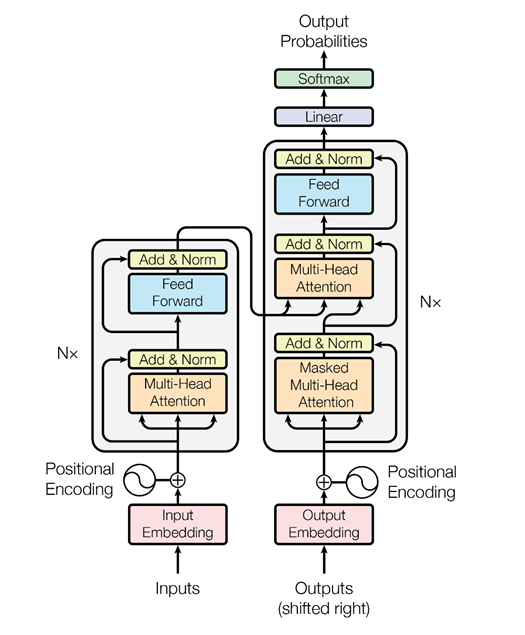
بناءً على مثل هذه البنية ، عندما يكون هناك اهتمام متعدد الرؤوس فقط ، تم اختراع خوارزميات خاصة يمكنها أيضًا تحليل العلاقة بين الكلمات في النصوص ، وعلاقة النصوص ببعضها البعض - كما يفعل ELMo ، بشكل أكثر دهاءًا. أولاً ، إنها شبكة أكثر برودة وتعقيدًا. ثانياً ، نحل مشكلتين في وقت واحد ، وليس مشكلة واحدة ، كما في حالة نمذجة اللغة ELMo والتنبؤ بها. نحن نحاول استعادة الكلمات المخفية في النص واستعادة الروابط بين النصوص. هذا هو ، دعنا نقول: "مبرمج فاسيا يحب البيرة. كل ليلة يذهب إلى البار ". نصان مترابطان. "مبرمج فازيا يحب البيرة. الرافعات تطير جنوبًا في الخريف "- هذان نصان لا علاقة لهما. مرة أخرى ، يمكن استخراج هذه المعلومات من النصوص غير المخصصة وتدريب بيرت والحصول على نتائج رائعة للغاية.
نُشر هذا في نوفمبر الماضي في مقال "الاهتمام هو كل ما تحتاج إليه" والذي أوصي بشدة بقراءته. في الوقت الحالي ، هذه هي النتيجة الأكثر روعة في مجال تحليل النص لحل المشكلات المختلفة: لتصنيف النص (التعرف على الدرجة اللونية ، نوايا المستخدم) ؛ لنظم السؤال والجواب ؛ للتعرف على الكيانات المسماة وهلم جرا. تستخدم أنظمة الحوار الحديثة BERT ، والزخارف السياقية المدربة مسبقًا (ELMo أو BERT) من أجل فهم ما يريده المستخدم. لكن وحدة إدارة الحوار لا تزال مصممة غالبًا استنادًا إلى القواعد ، لأن حوارًا معينًا يمكن أن يعتمد اعتمادًا كبيرًا على الموضوع أو حتى على المهمة.