مرحبا يا هبر.
ستكون هذه المقالة بتنسيق "الجمعة" قليلاً ، اليوم سنتعامل مع البرمجة اللغوية العصبية. ليس البرمجة اللغوية العصبية حول الكتب التي يتم بيعها في الطرق السفلية ، ولكن تلك التي تعمل فيها معالجة اللغة الطبيعية في معالجة اللغات الطبيعية. وكمثال على هذه المعالجة ، سيتم استخدام إنشاء النص باستخدام الشبكة العصبية. يمكننا إنشاء نصوص بأي لغة ، من الروسية أو الإنجليزية ، إلى C ++. النتائج مثيرة للاهتمام للغاية ، وربما يمكنك تخمين من الصورة.

بالنسبة لأولئك الذين يهتمون بما يحدث ، فإن النتائج والشفرة المصدرية هي تحت الخفض.
إعداد البيانات
للمعالجة ، سوف نستخدم فئة خاصة من الشبكات العصبية - ما يسمى الشبكات العصبية المتكررة (RNN). تختلف هذه الشبكة عن الشبكة المعتادة في ذلك بالإضافة إلى الخلايا المعتادة ، فهي تحتوي على خلايا ذاكرة. يسمح لنا ذلك بتحليل بيانات بنية أكثر تعقيدًا ، وفي الواقع ، أقرب إلى الذاكرة البشرية ، لأننا أيضًا لا نبدأ كل فكرة "من الصفر". لكتابة التعليمات البرمجية ، سوف نستخدم
شبكات LSTM (الذاكرة قصيرة المدى طويلة المدى) ، لأنها مدعومة بالفعل من قبل Keras.
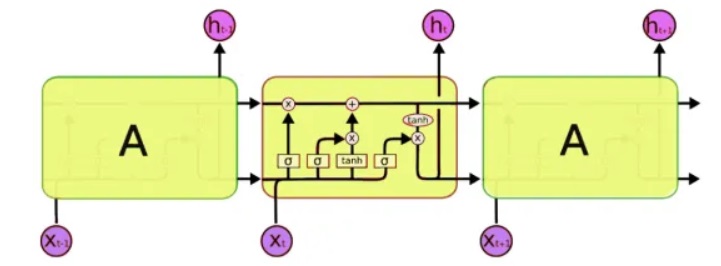
المشكلة التالية التي يجب حلها هي ، في الواقع ، العمل مع النص. وهنا يوجد طريقتان - إرسال الرموز أو الكلمات بأكملها إلى الإدخال. مبدأ النهج الأول بسيط: ينقسم النص إلى كتل قصيرة ، حيث "المدخلات" جزء من النص ، و "الإخراج" هو الحرف التالي. على سبيل المثال ، بالنسبة إلى العبارة الأخيرة ، "المدخلات جزء من النص":
input: output: ""
input: : output: ""
input: : output:""
input: : output: ""
input: : output: "".
و هكذا. وبالتالي ، فإن الشبكة العصبية تتلقى شظايا النص عند الإدخال ، وعند الإخراج الأحرف التي ينبغي أن تشكل.
النهج الثاني هو في الأساس نفسه ، وتستخدم فقط كلمات كاملة بدلا من الكلمات. أولاً ، يتم تجميع قاموس الكلمات وإدخال الأرقام بدلاً من الكلمات عند إدخال الشبكة.
هذا ، بالطبع ، وصف مبسط إلى حد ما. لدى Keras
بالفعل أمثلة على إنشاء النص ، لكن أولاً ، لا يتم وصفها بمثل هذه التفاصيل ، وثانياً ، تستخدم جميع البرامج التعليمية باللغة الإنجليزية نصوصًا مجردة بدلاً من ذلك مثل شكسبير ، والتي يصعب على الأم فهمها. حسنًا ، نحن نختبر شبكة عصبية على شبكتنا العظيمة والقوية ، والتي بالطبع ستكون أكثر وضوحًا ومفهومة.
تدريب الشبكة
كنص إدخال ، لقد استخدمت ... تعليقات Habr ، وحجم الملف المصدر هو 1 ميغابايت (هناك بالفعل المزيد من التعليقات ، بالطبع ، لكن كان علي استخدام جزء فقط ، وإلا سيتم تدريب الشبكة لمدة أسبوع ولن يرى القراء هذا النص بحلول يوم الجمعة). واسمحوا لي أن أذكركم بأن الحروف فقط يتم إدخالها على مدخلات الشبكة العصبية ، ولا تعرف الشبكة أي شيء عن اللغة أو بنيتها. دعنا نذهب ، بدء تدريب الشبكة.
5 دقائق من التدريب:حتى الآن ، لا يوجد شيء واضح ، لكن يمكنك بالفعل رؤية بعض المجموعات المعروفة من الحروف:
. . . «
15 دقيقة من التدريب:والنتيجة هي بالفعل أفضل بشكل ملحوظ:
« » — « » » —لسبب ما ، اتضح أن جميع النصوص كانت بدون نقاط وبدون حروف كبيرة ، ربما لم تتم معالجة utf-8 بشكل صحيح. لكن بشكل عام ، هذا مثير للإعجاب. من خلال تحليل أكواد الرموز فقط وتذكرها ، تعلم البرنامج فعليًا الكلمات الروسية "بشكل مستقل" ، ويمكنه إنشاء نص يبدو مقبولًا للغاية.
لا تقل إثارة للاهتمام هو حقيقة أن البرنامج يحفظ نمط النص بشكل جيد للغاية. في المثال التالي ، تم استخدام نص بعض القوانين كوسيلة تعليمية. وقت تدريب الشبكة 5 دقائق.
"" , , , , , , , ,
وهنا ، تم استخدام التعليقات التوضيحية الطبية للأدوية كمجموعة إدخال. وقت تدريب الشبكة 5 دقائق.
, ,
هنا نرى جمل كاملة تقريبا. هذا يرجع إلى حقيقة أن النص الأصلي قصير ، والشبكة العصبية في الواقع "تحفظ" بعض العبارات ككل. يسمى هذا التأثير "إعادة التدريب" ، ويجب تجنبه. من الناحية المثالية ، تحتاج إلى اختبار شبكة عصبية على مجموعات البيانات الكبيرة ، لكن التدريب في هذه الحالة قد يستغرق عدة ساعات ، وللأسف ليس لدي كمبيوتر عملاق إضافي.
مثال ممتع لاستخدام مثل هذه الشبكة هو توليد الأسماء. عن طريق تحميل قائمة بأسماء الذكور والإناث في الملف ، حصلت على خيارات جديدة مثيرة للاهتمام والتي ستكون مناسبة تمامًا لرواية خيال علمي: Rlar ، Laaa ، Aria ، Arera ، Aelia ، Ninran ، Air. شيء فيها يشعر بأسلوب إفريموف وسديم أندروميدا ...
C ++
الشيء المثير للاهتمام هو أن الشبكة العصبية تشبه إلى حد كبير التذكر. كانت الخطوة التالية هي التحقق من كيفية تعامل البرنامج مع الكود المصدري. كاختبار ، أخذت مصادر C ++ مختلفة ودمجتها في ملف نصي واحد.
بصراحة ، فاجأت النتيجة أكثر مما كانت عليه في حالة اللغة الروسية.
5 دقائق من التدريباللعنة ، انها حقيقية تقريبا C ++.
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } }
30 دقيقة من التدريب void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate);
كما ترون ، فإن البرنامج "تعلم" أن يكتب وظائف كاملة. في الوقت نفسه ، فصلت الوظيفة "إنسانيًا" تمامًا الوظائف مع تعليق باستخدام علامات النجمة ووضع التعليقات في الكود وكل ذلك. أود أن أتعلم لغة برمجة جديدة بهذه السرعة ... بالطبع ، هناك أخطاء في الشفرة ، وبالطبع لن يتم تجميعها. وبالمناسبة ، لم أقم بتهيئة الكود ، فقد تعلم البرنامج أيضًا وضع الأقواس البادئة "أنا".
بالطبع ، ليس لهذه البرامج الشيء الرئيسي -
المعنى ، وبالتالي تبدو سريالية ، كما لو كانت مكتوبة في المنام ، أو لم يكتبها شخص سليم تمامًا. ومع ذلك ، فإن النتائج مثيرة للإعجاب. وربما تساعد دراسة أعمق لتوليد نصوص مختلفة على فهم أفضل لبعض الأمراض العقلية للمرضى الحقيقيين. بالمناسبة ، كما هو مقترح في التعليقات ، يوجد مثل هذا المرض العقلي الذي يتحدث فيه الشخص في نص مرتبط نحويًا ولكن بلا معنى تمامًا (
انفصام الشخصية ).
استنتاج
تعتبر الشبكات العصبية الترفيهية واعدة للغاية ، وهذه بالفعل خطوة كبيرة إلى الأمام مقارنة بالشبكات "العادية" مثل MLP ، التي لا تملك ذاكرة. في الواقع ، قدرات الشبكات العصبية لتخزين ومعالجة الهياكل المعقدة إلى حد ما مثيرة للإعجاب. بعد هذه الاختبارات ، ظننت في البداية أن قناع إيلون كان على حق في شيء ما عندما كتبت أن الذكاء الاصطناعى في المستقبل يمكن أن يكون "أكبر خطر على البشرية" - حتى لو كان بإمكان الشبكة العصبية البسيطة أن تتذكر وتتكاثر بسهولة أنماط معقدة إلى حد ما ، ماذا يمكن أن شبكة من مليارات المكونات تفعل؟ لكن من ناحية أخرى ، لا تنسَ أن شبكتنا العصبية لا تستطيع
التفكير ، فهي تتذكر بشكل أساسي سلاسل الأحرف ، ولا تفهم معناها. هذه نقطة مهمة - حتى إذا قمت بتدريب شبكة عصبية على جهاز كمبيوتر فائق ومجموعة بيانات ضخمة ، فستتعلم في أحسن الأحوال إنشاء جمل صحيحة بنسبة 100٪ ، لكن بدون معنى تمامًا.
ولكن لن يتم إزالته في الفلسفة ، لا يزال المقال أكثر بالنسبة للممارسين. بالنسبة لأولئك الذين يرغبون في تجربة من تلقاء أنفسهم ،
شفرة المصدر في بيثون 3.7 تحت المفسد. هذا الرمز عبارة عن تجميع من مشاريع github المختلفة ، وليس عينة من أفضل رمز ، ولكن يبدو أنه يؤدي مهمته.
لا يتطلب استخدام البرنامج مهارات البرمجة ، يكفي معرفة كيفية تثبيت Python. أمثلة على البدء من سطر الأوامر:
- إنشاء وتدريب النماذج وتوليد النصوص:
python. \ keras_textgen.py --text = text_habr.txt - epochs = 10 --out_len = 4000
- توليد النص فقط دون التدريب النموذجي:
python. \ keras_textgen.py --text = text_habr.txt - epochs = 10 --out_len = 4000 - توليد
أعتقد أنه تبين أنه منشئ نصوص عمل
غير تقليدي للغاية ،
وهو مفيد لكتابة مقالات عن هبر . من المثير للاهتمام بشكل خاص اختبار النصوص الكبيرة وأعداد كبيرة من تكرار التدريب ، إذا كان بإمكان أي شخص الوصول إلى أجهزة الكمبيوتر السريعة ، سيكون من المثير للاهتمام رؤية النتائج.
إذا كان أي شخص يرغب في دراسة الموضوع بمزيد من التفاصيل ، يمكن العثور على وصف جيد لاستخدام RNN مع أمثلة تفصيلية في
http://karpathy.imtqy.com/2015/05/21/rnn-effectiveness/ .
ملاحظة: وأخيراً ، بعض الآيات ؛) من المثير للاهتمام أن نلاحظ أنه لم يكن أنا من قام بتنسيق النص أو حتى إضافة النجوم ، "أنا نفسي". الخطوة التالية مثيرة للاهتمام للتحقق من إمكانية رسم الصور وتأليف الموسيقى. أعتقد أن الشبكات العصبية واعدة للغاية هنا.
الثلاثون
بالنسبة للبعض ، أن يتم ضبطهم في ملفات تعريف الارتباط - كل هذا في حظ سعيد في ملعب للخبز.
وتحت المساء من تاماكي
تحت شمعة تأخذ جبل.
الثلاثون
قريبا أبناء مونس في petachas في الترام
الضوء الخفي تنبعث منه رائحة الفرح
لهذا السبب أنا يطرق معا ينمو
لن تكون مريضًا من مجهول.
قلب نتف في ogora متداخلة
ليس قديمًا لدرجة أن الحبوب تأكل ،
أحرس الجسر حتى تسرق الكرة.
بنفس الطريقة دارينا في دوبا ،
أسمع في قلبي الثلج على يدي.
لدينا الغناء الأبيض كم دومينا لطيف
التفت بعيدا volot الوحش خام.
الثلاثون
طبيب بيطري يصلب fretters مع تعويذة
وانسكب تحت المنسي.
وأنت ، كما هو الحال مع فروع كوبا
تألق فيه.
س متعة في zakoto
مع هروب الحليب.
يا وردة خفيفة
ضوء السحب في متناول اليد:
وتدحرجت في الفجر
كيف حالك يا فارس!
إنه يخدم في المساء ، وليس حتى العظم ،
في الليل في تانيا الضوء الأزرق
مثل نوع من الحزن.والآيات القليلة الماضية في التعلم عن طريق وضع الكلمة. هنا اختفى القافية ، ولكن ظهر بعض المعنى (؟).
وأنت من اللهب
النجوم.
تحدث مع الأفراد البعيدين.
يقلقك يا روس ، أنت ، في الغد.
"حمامة المطر ،
وموطن القتلة ،
للفتاة الاميرة
وجهه.
الثلاثون
يا الراعي ، موجة من الغرف
على بستان في الربيع.
أنا أذهب عبر قلب المنزل إلى البركة ،
والفئران مرح
نيجني نوفغورود أجراس.
لكن لا تخف يا ريح الصباح.
مع الطريق ، مع نادي الحديد ،
وفكر مع المحار
مأوى على البركة
في rakit الفقيرة.