
تتكون العديد من تطبيقات الشبكات من خادم ويب يقوم بمعالجة حركة المرور في الوقت الفعلي ومعالج إضافي يتم تشغيله في الخلفية بشكل غير متزامن. هناك العديد من النصائح الرائعة للتحقق من حالة حركة المرور ، ولا يتوقف المجتمع عن تطوير أدوات مثل Prometheus التي تساعد في التقييم. لكن في بعض الأحيان لا تقل أهمية المعالجات - بل والأكثر أهمية -. كما أنهم بحاجة إلى الاهتمام والتقييم ، ولكن هناك القليل من الإرشادات حول كيفية القيام بذلك مع تجنب المزالق الشائعة.
تم تخصيص هذه المقالة للفخاخ الأكثر شيوعًا في عملية تقييم المعالجات غير المتزامنة ، وذلك باستخدام مثال لحادث وقع في بيئة إنتاج ، حيث كان من المستحيل ، حتى مع المقاييس ، تحديد ما الذي كان يقوم به المعالجون بالضبط. إن استخدام المقاييس قد حوّل التركيز إلى درجة أن المقاييس نفسها كذبت علانية ، كما يقولون ، معالجاتك إلى الجحيم.
سنرى كيفية استخدام المقاييس بطريقة توفر تقديرًا دقيقًا ، وفي الختام سنبين التنفيذ المرجعي لبرنامج prometheus-client-tracer مفتوح المصدر ، والذي يمكنك استخدامه في تطبيقاتك.
حادث
وصلت التنبيهات بسرعة مدفع رشاش: زاد عدد أخطاء HTTP بشكل حاد ، وأكدت لوحات التحكم أن قوائم انتظار الطلب آخذة في الازدياد ، ونفاد وقت الاستجابة. بعد حوالي دقيقتين ، تم مسح قوائم الانتظار ، وعاد كل شيء إلى طبيعته.
بعد الفحص الدقيق ، اتضح أن خوادم واجهة برمجة التطبيقات (API) الخاصة بنا قد وقفت في انتظار استجابة DB ، مما تسبب في توقفها وفجأة عن القيام بجميع الأنشطة. وعندما تفكر في أن الحمل الأثقل يقع في كثير من الأحيان على مستوى المعالجات غير المتزامنة ، فقد أصبحوا المشتبه بهم الرئيسيين. كان السؤال المنطقي هو: ماذا يفعلون هناك على الإطلاق؟!
يوضح مقياس بروميثيوس ما تستغرقه العملية من وقت ، ومن هنا:
# HELP job_worked_seconds_total Sum of the time spent processing each job class # TYPE job_worked_seconds_total counter job_worked_seconds_total{job}
من خلال تتبع إجمالي وقت التنفيذ لكل مهمة ووتيرة تغيير المقياس ، سنكتشف مقدار وقت العمل الذي تم إنفاقه. إذا لمدة 15 ثانية. زاد العدد بمقدار 15 ، وهذا يعني وجود معالج مشغول (ثانية واحدة لكل ثانية سابقة) ، بينما تعني الزيادة 30 معالجين ، إلخ.
سوف يوضح جدول العمل خلال الحادث ما نواجهه. النتائج مخيبة للآمال. يتميز وقت الحادث (16: 02-16: 04) بخط أحمر مقلق:

نشاط المعالج أثناء الحادث: وجود فجوة ملحوظة.
لقد كان الأمر مؤلمًا بالنسبة لي ، كشخص كان يعمل على تصحيح الأخطاء بعد هذا الكابوس ، لأرى أن منحنى النشاط كان في أسفله تمامًا أثناء الحادث. هذا هو الوقت المناسب للعمل مع خطافات الويب ، حيث يوجد لدينا 20 معالج مخصص. من السجلات ، أعلم أنهم كانوا جميعهم في العمل ، وأتوقع أن يكون المنحنى في حوالي 20 ثانية ، ورأيت خطًا مستقيمًا تقريبًا. علاوة على ذلك ، ترى هذه القمة الزرقاء الكبيرة في الساعة 16:05؟ استنادا إلى الجدول الزمني ، أمضى 20 من المعالجات أحادية الخيوط 45 ثانية. لكل ثانية من النشاط ، ولكن هل هذا ممكن؟!
أين وما الخطأ الذي حدث؟
الجدول الزمني للحادث يكذب: إنه يخفي نشاط العمل ويظهر في الوقت نفسه ما لا لزوم له - وهذا يتوقف على مكان القياس. لمعرفة سبب حدوث ذلك ، يجب أن تأخذ في الاعتبار تنفيذ تتبع المقاييس وكيفية تفاعلها مع قياسات جمع Prometheus.
بدءًا من كيفية قيام المعالجات بجمع المقاييس ، يمكنك وضع مخطط تقريبي لتطبيق سير العمل (انظر أدناه). ملاحظة: يقوم المعالجون بتحديث المقاييس فقط عند الانتهاء من المهمة .
class Worker JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) def work job = acquire_job start = Time.monotonic_now job.run ensure # run after our main method block duration = Time.monotonic_now - start JobWorkedSecondsTotal.increment(by: duration, labels: { job: job.class }) end end
تقوم بروميثيوس (مع فلسفتها في استخراج المقاييس) بإرسال طلب GET إلى كل معالج كل 15 ثانية ، مع تسجيل قيم المقاييس في وقت الطلب. يقوم المعالجون باستمرار بتحديث مقاييس المهام المكتملة ، وبمرور الوقت يمكننا عرض ديناميكيات التغييرات في القيم بيانياً.
تبدأ مشكلة نقص القيمة وإعادة التقييم في الظهور كلما تجاوز الوقت المستغرق لإكمال المهمة وقت انتظار طلب يصل كل 15 ثانية. على سبيل المثال ، تبدأ المهمة قبل 5 ثوانٍ من الطلب وتنتهي بعد ثانية واحدة. بشكل عام وعمومًا ، تستغرق 6 ثوانٍ ، لكن هذه المرة تكون مرئية فقط عند تقدير تكاليف الوقت التي تم إجراؤها بعد الطلب ، في حين تم إنفاق 5 من هذه الثواني الست قبل الطلب.
تظل المؤشرات أكثر إلهامًا إذا استغرقت المهام وقتًا أطول من فترة إعداد التقرير (15 ثانية) ، وخلال تنفيذ المهمة لمدة دقيقة واحدة ، سيكون لدى بروميثيوس الوقت لإرسال 4 طلبات إلى المعالجات ، ولكن سيتم تحديث المقياس فقط بعد الرابع.
بعد رسم جدول زمني لنشاط العمل ، سنرى كيف تؤثر اللحظة التي يتم فيها تحديث المقياس على ما يراه Prometheus. في الرسم البياني أدناه ، نقوم بتقسيم الجدول الزمني لعاملين إلى عدة قطاعات تعرض مهام بمدد مختلفة. تشير العلامات الحمراء (15 ثانية) والأزرق (30 ثانية) إلى عينتين من بيانات بروميثيوس ؛ يتم تمييز المهام التي كانت بمثابة مصدر بيانات للتقييم بالألوان ، على التوالي.
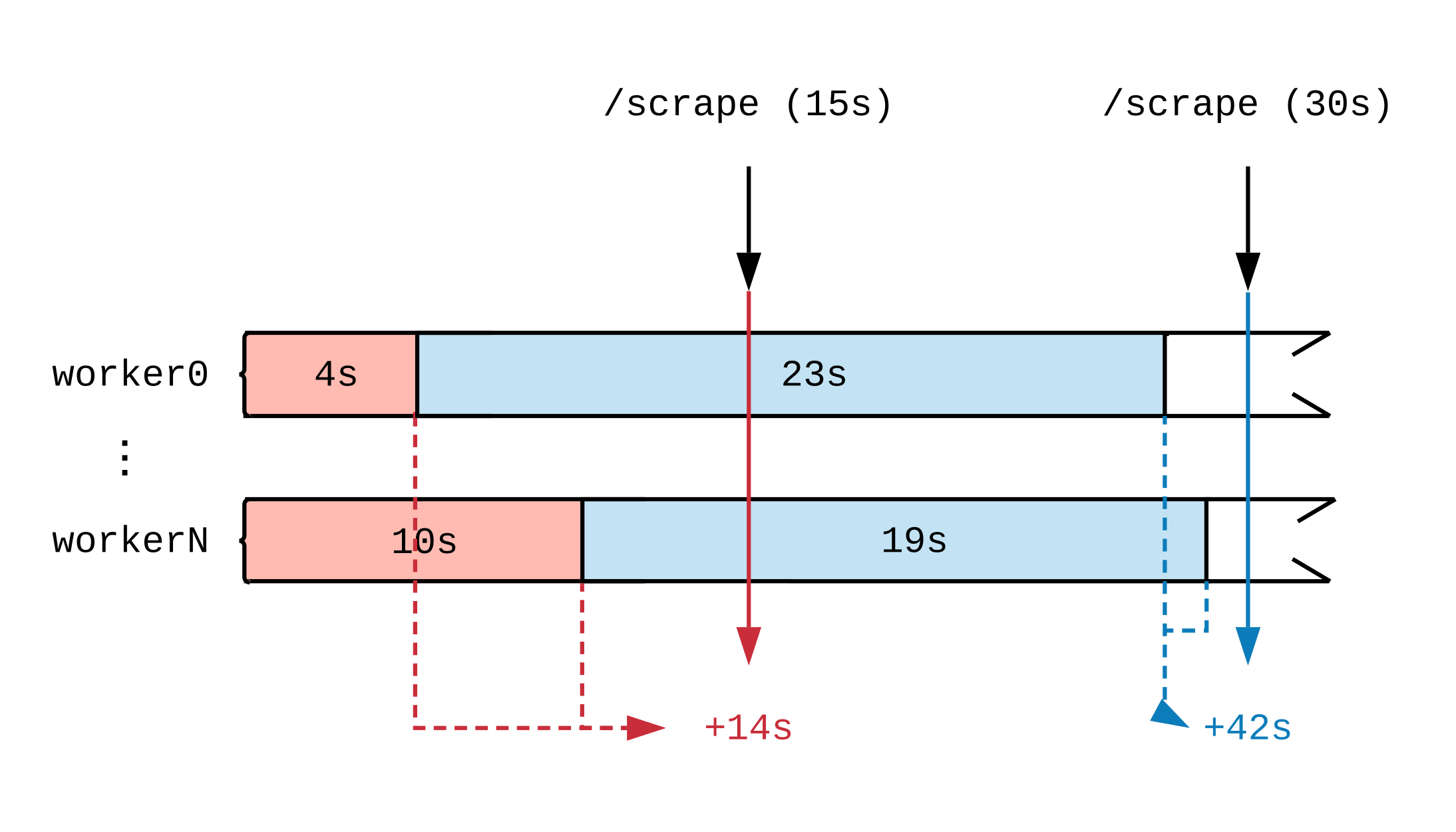
بغض النظر عن ما يقوم به القائمون على التحميل بكامل طاقتهم ، سيقومون بعمل 30 ثانية كل فاصل زمني مدته 15 ثانية. نظرًا لأن Prometheus لا ترى العمل حتى يتم الانتهاء منه ، بناءً على المقاييس ، تم إكمال 14 ثانية من العمل في الفترة الزمنية الأولى و 42 ثانية في الثانية. إذا تولى كل معالج مهمة ضخمة ، حتى بعد مرور بضع ساعات ، وحتى النهاية ، فلن نرى تقارير تفيد بأن العمل مستمر.
لإثبات هذا التأثير ، أجريت تجربة مع عشرة مناولي العمل في مهام مختلفة طولها وتوزع شبه طبيعية بين 0.1 ثانية وقيمة أعلى قليلاً (انظر المهام العشوائية ). فيما يلي 3 رسوم بيانية تصور نشاط العمل ؛ يظهر طول في الوقت في ترتيب متزايد.
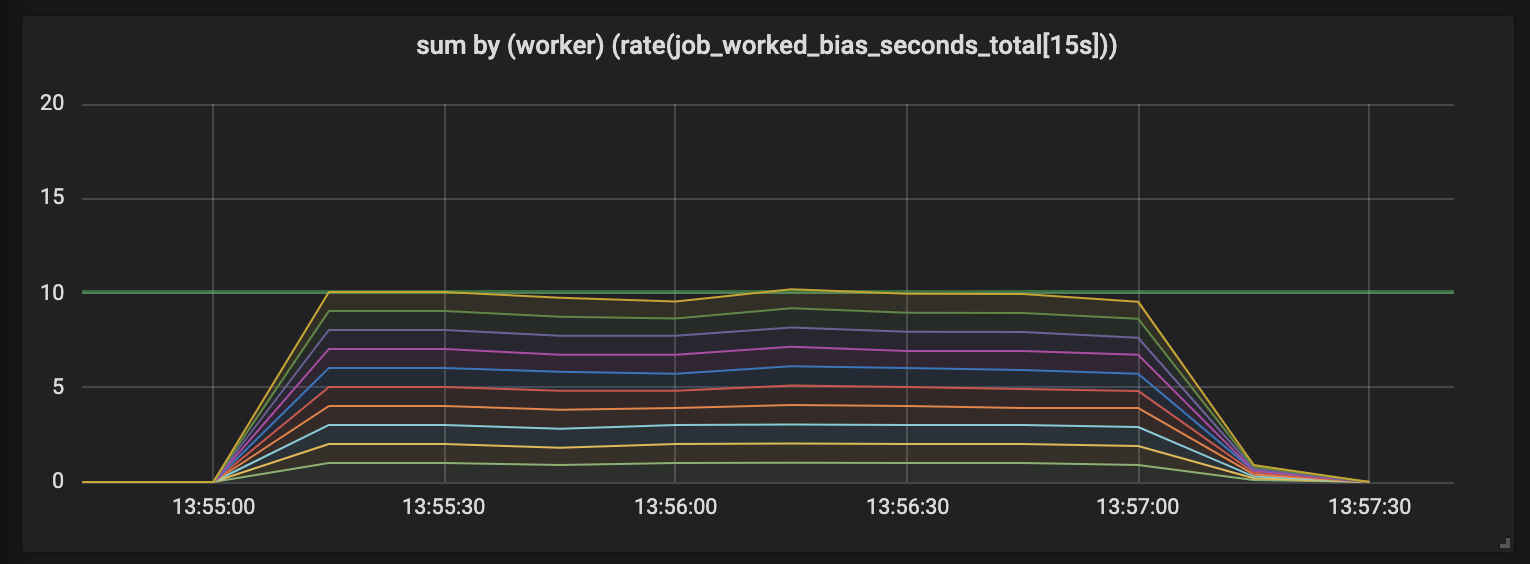
مهام تدوم حتى 1 ثانية.
يوضح الرسم البياني الأول أن كل معالج يفي بحوالي ثانية واحدة من العمل في كل ثانية من الوقت - وهذا مرئي على الخطوط المسطحة ، ومقدار إجمالي العمل مساوٍ لقدراتنا (10 من يعالجون يعطون ثانية من العمل في الثانية من الوقت). في الواقع ، هذا ، بصرف النظر عن طول المهمة ، نتوقعه: على الكثير من المهام القصيرة والطويلة ، ينبغي إعطاء المعالجات ذات الأحمال الثابتة.
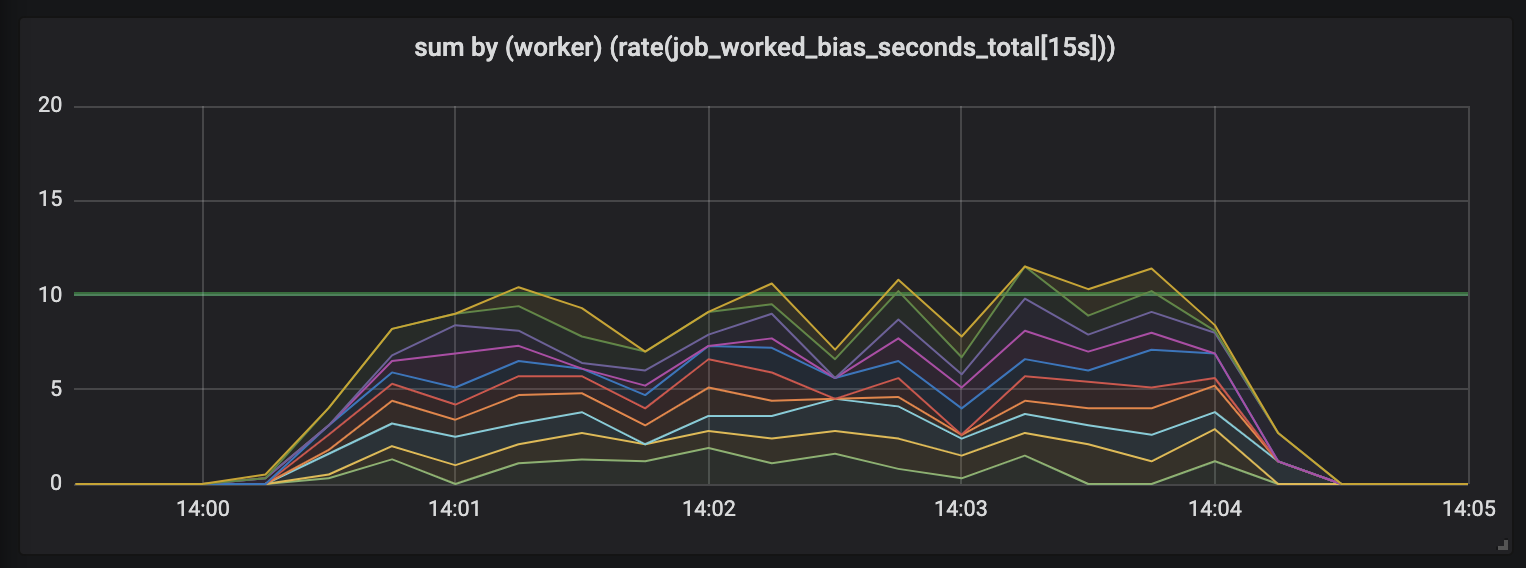
مهام تدوم حتى 15 ثانية.
تزداد مدة المهام ، وتظهر فوضى في الجدول: لا يزال لدينا 10 معالجات ، كلها مشغولة بالكامل ، لكن إجمالي عدد عمليات تخطي العمل - إما أقل أو أعلى من حدود السعة المفيدة (10 ثوانٍ).
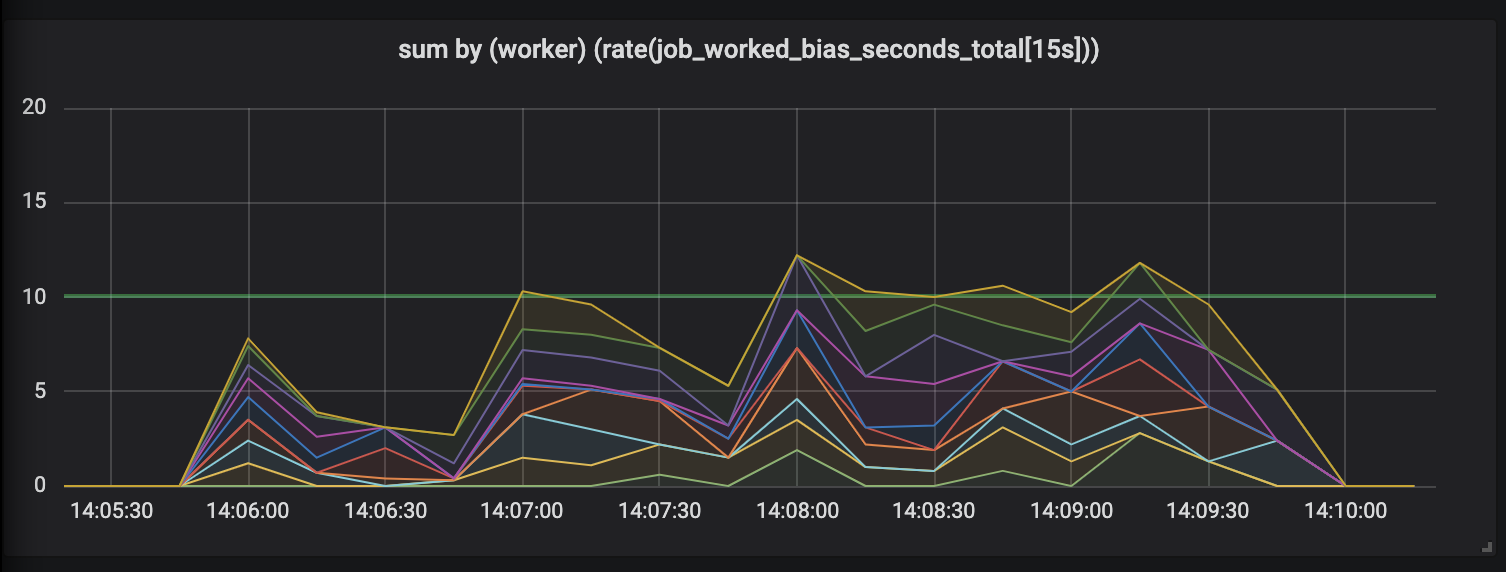
مهام تدوم حتى 30 ثانية.
تقييم الأعمال التي تدوم حتى 30 ثانية أمر مثير للسخرية بكل بساطة. يُظهر المقياس المرتبط زمنياً أي نشاط صفري لأطول المهام ، وفقط عند اكتمال المهام ، يرسمنا قمم النشاط.
استعادة الثقة
هذا لم يكن كافياً بالنسبة لنا ، لذلك هناك مشكلة أخرى أكثر غدراً مع هذه المهام الطويلة الأجل التي تفسد قياساتنا. عندما يتم إكمال مهمة طويلة الأجل - على سبيل المثال ، إذا قامت Kubernetes بإلقاء جراب من مجموعة ، أو عند وفاة عقدة - فما الذي يحدث للمقاييس؟ يجدر تحديثها فور الانتهاء من المهمة ، لأنها تظهر أنها لم تقم بالعمل على الإطلاق .
يجب أن لا تكذب المقاييس. الكمبيوتر المحمول يعوي بشكل لا يصدق ، مما تسبب في رعب وجودي ، وأدوات المراقبة التي تشوه صورة العالم هي فخ وغير مناسبة للعمل.
لحسن الحظ ، الأمر قابل للتثبيت. يحدث تشويه البيانات لأن Prometheus يأخذ القياسات بغض النظر عن وقت تحديث المعالجات للقياسات. إذا طلبنا من المعالجات تحديث المقاييس عندما يرسل بروميثيوس الطلبات ، فسنرى أن بروميثيوس لم تعد ملتوية ويظهر النشاط الحالي.
تقديم ... التتبع
أحد الحلول لمشكلة المقاييس المشوهة هو Tracer ، وهو حل تم تصميمه بشكل تجريدي يقوم بتقييم النشاط في المهام الطويلة الأمد من خلال تحديث المقاييس المتعلقة بروميثيوس بشكل تدريجي.
class Tracer def trace(metric, labels, &block) ... end def collect(traces = @traces) ... end end
توفر أدوات التتبع طريقة تتبع تأخذ مقاييس Prometheus ومهمة التتبع. سيقوم أمر trace بتنفيذ الكتلة المعطاة (وظائف Ruby المجهولة) ويضمن أن طلبات tracer.collect أثناء التنفيذ ستقوم بتحديث المقاييس ذات الصلة بشكل متزايد ، بغض النظر عن مقدار الوقت الذي انقضى منذ آخر طلب collect .
نحتاج إلى توصيل جهاز tracer من أجل تتبع مدة المهمة ونقطة النهاية التي تخدم طلبات قياس Prometheus. نبدأ مع المعالجات ، نبدأ في إعداد تتبع جديد ونطلب منه تتبع acquire_job.run التنفيذ لـ acquire_job.run .
class Worker def initialize @tracer = Tracer.new(self) end def work @tracer.trace(JobWorkedSecondsTotal, labels) { acquire_job.run } end # Tell the tracer to flush (incremental) trace progress to metrics def collect @tracer.collect end end
في هذه المرحلة ، سيقوم برنامج التتبع فقط بتحديث المقاييس بالثواني التي تم إنفاقها على المهمة المكتملة - كما فعلنا في التنفيذ الأولي للمقاييس. يجب أن نطلب من tracer تحديث مقاييسنا قبل تنفيذ طلب من Prometheus. يمكن القيام بذلك عن طريق إعداد الرف الوسيطة.
# config.ru # https://rack.imtqy.com/ class WorkerCollector def initialize(@app, workers: @workers); end def call(env) workers.each(&:collect) @app.call(env) # call Prometheus::Exporter end end # Rack middleware DSL workers = start_workers # Array[Worker] # Run the collector before serving metrics use WorkerCollector, workers: workers use Prometheus::Middleware::Exporter
Rack هي واجهة لخوادم الويب من Ruby تتيح لك الجمع بين معالجات Rack متعددة في نقطة نهاية واحدة. config.ru الأمر config.ru أن تطبيق Rack - عندما يتلقى الطلب - يرسل أمر التجميع إلى معالجات أولاً ، وعندها فقط يخبر عميل Prometheus برسم نتائج المجموعة.
بالنسبة إلى الرسم البياني لدينا ، نقوم بتحديث المقاييس كلما اكتملت المهمة أو عندما نتلقى طلبًا للمقاييس. تقوم المهام التي لها عدة استعلامات بإرسال البيانات على قدم المساواة على جميع القطاعات: كما هو موضح بالمهام التي تم تقسيم مدتها إلى فواصل زمنية مدتها 15 ثانية.

هل هو أفضل؟
يؤثر استخدام التتبع على مدار 24 ساعة يوميًا في كيفية تسجيل النشاط. على عكس القياسات الأولية ، التي أظهرت "منشارًا" ، عندما تجاوز عدد القمم عدد المعالجات قيد التشغيل وفترات الصمت الباهت ، توفر التجربة مع عشرة معالجات رسمًا بيانيًا يوضح بوضوح أن كل معالج مضمن في العمل الذي تتم مراقبته بالتساوي.

المقاييس مبنية على المقارنة (يسار) والتحكم فيها بواسطة التتبع (يمين) ، مأخوذة من تجربة عمل واحدة.
مقارنة بالجدول الزمني غير الدقيق والفوضوي للقياسات الأولية ، فإن المقاييس التي تم جمعها بواسطة التتبع متجانسة ومتسقة. نحن الآن لا نربط العمل بدقة بكل طلب قياس ، لكننا أيضًا لا نخشى الموت المفاجئ لأي من المعالجين: تقوم بروميثيوس بتسجيل المقاييس حتى يختفي المعالج ، وتقييم كل أعماله.
هل يمكن استخدام هذا؟
نعم! لقد أثبتت واجهة Tracer أنها مفيدة بالنسبة لي في العديد من المشاريع ، لذا فهي جوهرة Ruby منفصلة ، و prometheus-tracer . إذا كنت تستخدم عميل Prometheus في تطبيقات Ruby الخاصة بك ، فما عليك سوى إضافة prometheus-client-tracer إلى Gemfile:
require "prometheus/client" require "prometheus/client/tracer" JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) Prometheus::Client.trace(JobWorkedSecondsTotal) do sleep(long_time) end
إذا كان هذا مفيدًا لك وإذا كنت تريد أن يظهر عميل Prometheus Ruby الرسمي في Tracer ، فاترك مراجعة في client_ruby # 135 .
وأخيرا ، بعض الأفكار
آمل أن يساعد ذلك الآخرين في جمع المقاييس بوعي أكثر للقيام بالمهام الطويلة الأمد وحل إحدى المشاكل الشائعة. لا تخطئ ، فهو يرتبط ليس فقط بالمعالجة غير المتزامنة: إذا تم إبطاء طلبات HTTP الخاصة بك ، فسوف تستفيد أيضًا من استخدام التتبع عند تقييم الوقت الذي تستغرقه المعالجة.
كالعادة ، أي تعليقات وتصحيحات هي موضع ترحيب: الكتابة إلى تويتر أو فتح العلاقات العامة . إذا كنت ترغب في المساهمة في جوهرة التتبع ، فإن الكود المصدري موجود على prometheus-client-tracer-ruby .