مرحبا يا هبر! أعد أصدقاؤنا من Softpoint مقالة مثيرة للاهتمام حول Microsoft SQL Server. يوزع مثالين عمليين لاستخدام البحث عن النص الكامل:
- البحث في سطور "غير محدودة" (مثل التعليقات) بدلاً من البحث المنتظم من خلال LIKE ؛
- البحث عن طريق أرقام المستندات مع البادئات. حيث لا يمكن عادةً استخدام البحث عن النص الكامل: تتداخل البادئات الثابتة معه. يتم تحليل مقاربتين: تجهيز رقم المستند وإضافة قاطع الكلمات المكتبي الخاص بك.
انضم الآن!
 أعطي الكلمة للمؤلف
أعطي الكلمة للمؤلفالبحث الفعال في غيغا بايت من البيانات المتراكمة هو نوع من "الكأس المقدسة" لنظم المحاسبة. الكل يريد العثور عليه واكتساب المجد الخالد ، ولكن في عملية البحث مرارًا وتكرارًا ، تبيّن أنه لا يوجد حل معجزة واحد.
الموقف معقد بسبب حقيقة أن المستخدمين يريدون عادة البحث عن سلسلة فرعية - في مكان ما اتضح أن رقم العقد المطلوب "مدفون" في منتصف التعليق ؛ في مكان ما ، لا يتذكر المشغل اسم العميل تمامًا ، لكنه تذكر أن اسمه "Alexey Evgrafovich" ؛ في مكان ما ، تحتاج فقط إلى حذف النموذج المتكرر لملكية BYUBL والبحث على الفور باسم المنظمة. بالنسبة لأنظمة إدارة قواعد البيانات العلائقية الكلاسيكية ، فإن هذا البحث يعد أخبارًا سيئة للغاية. في معظم الأحيان ، يتم تقليل بحث السلسلة الفرعية هذا إلى التمرير المنهجي لكل صف من الجداول. ليست الإستراتيجية الأكثر فاعلية ، خاصةً إذا كان حجم الجدول ينمو إلى عدة عشرات من الجيجابايت.
بحثًا عن بديل ، أتذكر غالبًا "البحث عن النص الكامل". عادة ما يمر فرح إيجاد حل سريعًا بعد مراجعة سريعة للممارسة الحالية. اتضح بسرعة ، وفقًا للرأي الشائع ، أن البحث عن النص الكامل:
- من الصعب تكوين
- تحديث ببطء
- توقف النظام عند التحديث
- لديه نوع من بناء الجملة
غبي غير عادية - لا يجد ما يطلبونه
يمكن أن تستمر مجموعة الأساطير لفترة طويلة ، لكن حتى أفلاطون علمنا أن نكون متشككين ولا يقبلون رأي أعمى عن الإيمان. دعونا نرى ما إذا كان الشيطان رهيب للغاية كما هو رسمت؟
وعلى الرغم من أننا لسنا منغمسين بشدة في الدراسة ، إلا أننا
سنتفق على الفور على شرط مهم . يمكن لمحرك البحث عن النص الكامل القيام بأكثر من مجرد البحث في السلسلة العادية. على سبيل المثال ، يمكنك تحديد قاموس للمرادفات واستخدام كلمة "جهة اتصال" للعثور على "هاتف". أو ابحث عن الكلمات دون النظر إلى الشكل والنهايات. يمكن أن تكون هذه الخيارات مفيدة للغاية للمستخدمين ، ولكن في هذه المقالة ، نعتبر البحث عن النص الكامل فقط بديلاً للبحث عن الخطوط الكلاسيكية. بمعنى ،
سنبحث فقط عن السلسلة الفرعية التي سيتم تحديدها في شريط البحث ، دون مراعاة المرادفات ، دون جلب الكلمات إلى النموذج "العادي" والسحر الآخر.
كيف مرض التصلب العصبي المتعدد مزود النص الكامل يعمل
تمت إزالة وظيفة البحث عن النص الكامل في MS SQL جزئيًا من خدمة DBMS الرئيسية (بالقرب من نهاية المقالة سنرى لماذا يمكن أن يكون ذلك مفيدًا للغاية). للبحث ، يتم تكوين فهرس خاص بهيكله ، على عكس الأشجار المتوازنة المعتادة.
من المهم إنشاء فهرس بحث كامل النص ، من الضروري وجود فهرس فريد في الجدول الرئيسي ، يتكون من عمود واحد فقط - وهو البحث عن النص الكامل الذي سيتم استخدامه لتحديد صفوف الجدول. غالبًا ما يحتوي الجدول بالفعل على مثل هذا الفهرس على المفتاح الأساسي ، ولكن في بعض الأحيان سوف يتعين إنشاؤه بشكل إضافي.
يتم ملء فهرس البحث عن النص الكامل بشكل غير متزامن وخارج المعاملة. بعد تغيير صف الجدول ، يتم وضعه في قائمة الانتظار للمعالجة. تتلقى عملية تحديث الفهرس من صف الجدول (صف) جميع قيم السلسلة ، "مشترك" في الفهرس ، وتقسيمها إلى كلمات منفصلة. بعد ذلك ، يمكن اختزال الكلمات إلى نموذج "قياسي" معين (على سبيل المثال ، بدون نهايات) ، بحيث يكون من السهل البحث عن طريق أشكال الكلمات. يتم التخلص من "كلمات التوقف" (حروف الجر والمقالات والكلمات الأخرى التي لا تحمل معنى). تتم كتابة تطابقات ارتباط الكلمة إلى السلسلة المتبقية في فهرس البحث عن النص الكامل.
اتضح أن كل عمود من الجدول المضمن في الفهرس يمر عبر خط الأنابيب هذا:
خط طويل -> wordbreaker -> مجموعة من الأجزاء (الكلمات) -> stemmer -> كلمات طبيعية -> [اختياري] إيقاف استثناء الكلمة -> الكتابة إلى الفهرس
كما ذكر ، عملية تحديث الفهرس غير متزامنة. يتبع من هذا:
- لا يمنع التحديث إجراءات المستخدم
- ينتظر التحديث إكمال معاملة تغيير الصف ويبدأ في تطبيق التغييرات في موعد لا يتجاوز الالتزام
- يتم تطبيق التغييرات على فهرس النص الكامل مع بعض التأخير نسبة إلى المعاملة الرئيسية. بمعنى أنه بين إضافة صف والوقت الذي يمكن العثور فيه ، سيكون هناك تأخير اعتمادًا على طول قائمة انتظار تحديث الفهرس
- يمكن مراقبة عدد العناصر الموجودة في الفهرس بواسطة الاستعلام:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
اختبارات عملية. البحث عن المادية الأشخاص بالاسم
تعبئة الجدول بالبيانات
للتجارب ، سنقوم بإنشاء قاعدة فارغة جديدة مع جدول واحد حيث سيتم تخزين "الأطراف المقابلة". داخل حقل "الوصف" ، سيكون هناك خط يحمل اسم العقد ، حيث سيتم ذكر اسم الطرف المقابل. شيء مثل هذا:
"التعاقد مع بوروفيك دميان إميليانوفيتش"
أو هكذا:
"الكلب. مع بوروفيك رومانوف أناتولي أفديفيتش "
نعم ، أرغب في إطلاق النار على الفور من هذه "الهندسة المعمارية" ، لكن للأسف ، فإن تطبيق "التعليقات" أو "الوصف" غالبًا ما يكون بين مستخدمي الأعمال.
بالإضافة إلى ذلك ، نضيف بعض الحقول "للوزن": إذا كان هناك عمودان فقط في الجدول ، فسيقوم مسح بسيط بقراءته في لحظات. نحتاج إلى "تضخيم" الجدول بحيث يكون المسح طويلاً. هذا يجعلنا أقرب إلى حالات العمل الحقيقية: فنحن لا نخزن فقط "الوصف" في الجدول ، ولكن أيضًا الكثير من المعلومات المفيدة الأخرى [الشيطان].
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
والسؤال التالي هو أين يمكن الحصول على الكثير من الأسماء الأخيرة الفريدة والأسماء الأولى والأقارب؟ وفقًا لعادة قديمة ، تصرفت كطالب روسي عادي ، أي ذهبت إلى ويكيبيديا:
- الأسماء مأخوذة من صفحة التصنيف: أسماء الذكور الروس
- إعادة كتابة الأسماء الوسطى يدويًا من الأسماء وتغيير النهايات
- مع الألقاب اتضح أن الأمر أكثر تعقيدًا. في النهاية ، تم العثور على فئة "تحمل أسماء". تحولت بعض الشامانية مع بيثون وفي جدول منفصل إلى 46.5 ألف اسم. (برنامج نصي لتنزيل الألقاب متاح هنا)
بالطبع ، كانت هناك اختلافات غريبة بين الألقاب ، لكن لأغراض الدراسة كان هذا مقبولًا تمامًا.
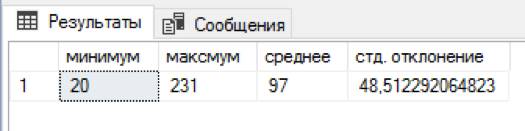
لقد كتبت سكيل الذي يربط عدد عشوائي من الأسماء والأسماء لكل اسم أخير. 5 دقائق من الانتظار وفي جدول منفصل كان هناك بالفعل 4.5 مليون توليفة. ليس سيئا! لكل لقب كان هناك 20 إلى 231 مجموعة من الاسم + الاسم الأوسط ، في المتوسط تم الحصول على 97 مجموعة. اتضح أن التوزيع حسب الاسم والمستفيد كان متحيزًا قليلاً "إلى اليسار" ، لكن بدا من الضروري الخروج بخوارزمية أكثر توازناً.
يتم إعداد البيانات ، يمكننا أن نبدأ تجاربنا.
إعداد بحث النص الكامل
إنشاء فهرس نص كامل على مستوى MS SQL. نحتاج أولاً إلى إنشاء مستودع لهذا الفهرس - كتالوج النص الكامل.
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
يوجد فهرس ، ونحن نحاول إضافة فهرس النص الكامل لجدولنا ... ولا شيء يعمل.
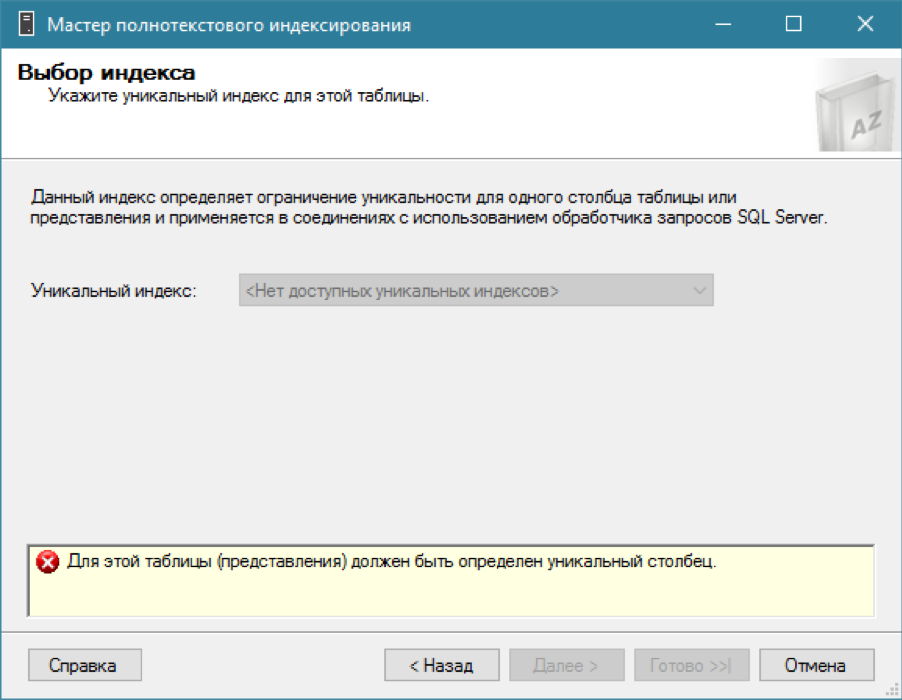
كما قلت ، لفهرس النص الكامل تحتاج إلى فهرس منتظم مع عمود واحد فريد. نذكر أن لدينا بالفعل الحقل المطلوب - معرف معرف فريد. دعنا ننشئ فهرسًا فريدًا للكتلة عليه (على الرغم من أن فهرسًا غير مصنّف سيكون كافٍ):
create unique clustered index ndx1 on partners (id)
بعد إنشاء فهرس جديد ، يمكننا أخيرًا إضافة فهرس البحث عن النص الكامل. دعنا ننتظر بضع دقائق حتى يصبح الفهرس ممتلئًا (تذكر أنه يتم تحديثه بشكل غير متزامن!). يمكنك المتابعة إلى الاختبارات.
تجريب
لنبدأ بأبسط سيناريو ، بالقرب من التطبيق الحقيقي للبحث. نحن نحاكي "عرض القائمة" - مجموعة مختارة من 45 سطرًا مع تحديد بواسطة قناع البحث. نقوم بتنفيذ الطلب باستخدام فهرس نص كامل جديد ، نلاحظ الوقت - 0 ثانية - ممتاز!
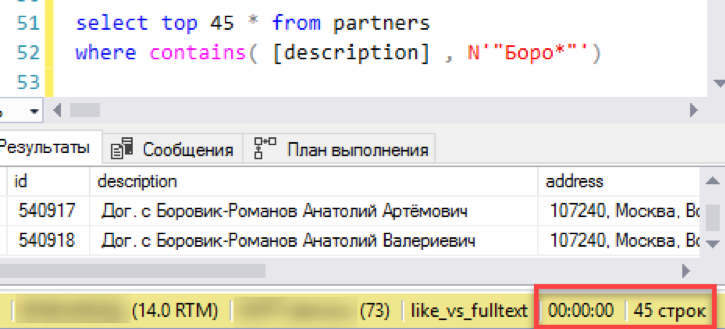
الآن بحث قديم أثبت نجاحه من خلال "أعجبني". استغرق الأمر 3 ثوان لتشكيل النتيجة. ليس سيئا للغاية ، لم تنجح الهزيمة الكاملة. ربما من غير المنطقي إعداد بحث عن النص الكامل - هل كل شيء يعمل بشكل جيد؟
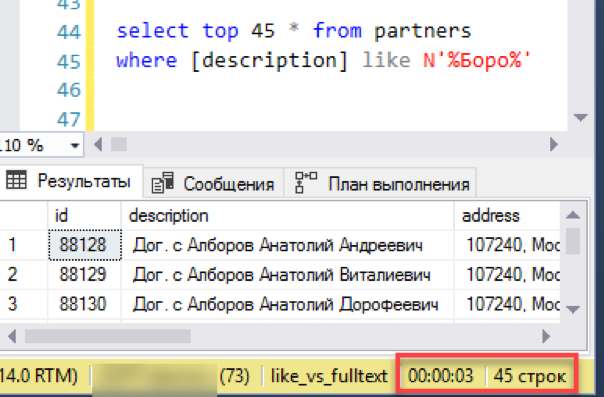
في الواقع ، فاتنا أحد التفاصيل المهمة: تم تنفيذ الطلب دون فرز. أولاً ، يُرجع هذا الاستعلام المقترن بـ "تحديد سجلات N الأولى" نتيجة غير مبررة. كل بداية يمكن أن ترجع سجلات N عشوائية وليس هناك ما يضمن أن اثنين من بدء متتالي سيعطي نفس مجموعة البيانات. ثانياً ، إذا كنا نتحدث عن "عرض القائمة مع نافذة منزلقة" - عادةً ما يتم فرز "النافذة" هذه حسب أي عمود ، على سبيل المثال ، حسب الاسم. بعد كل شيء ، يحتاج المشغل إلى معرفة ما سيحصل عليه عندما ينتقل إلى "النافذة" التالية.
صحح التجربة إضافة الفرز ، على سبيل المثال ، حسب رقم الهاتف:
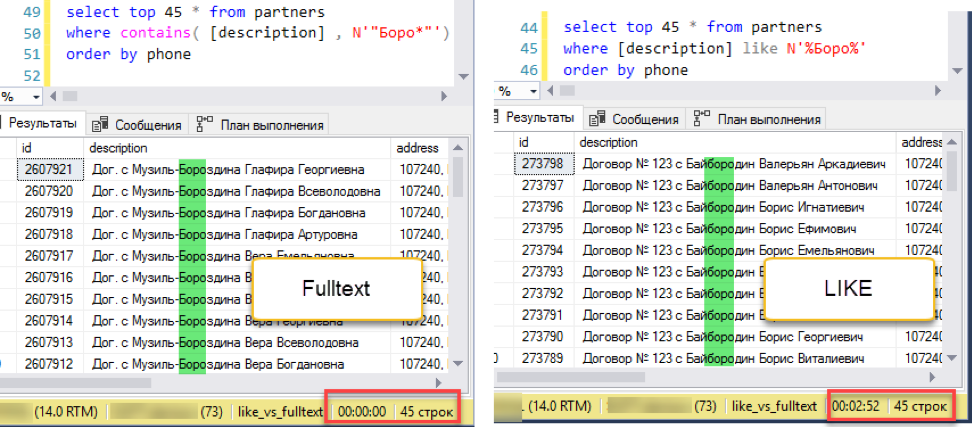 البحث عن النص الكامل يفوز بنتيجة deafening: 0 ثانية مقابل 172 ثانية!
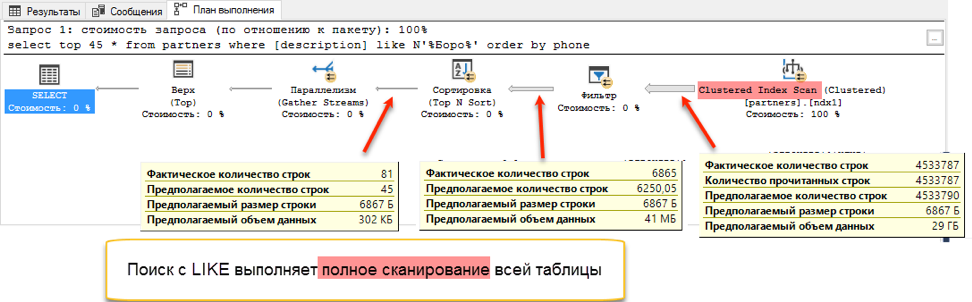
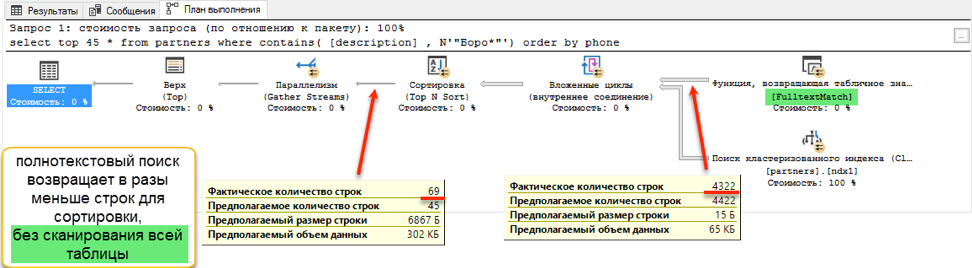
البحث عن النص الكامل يفوز بنتيجة deafening: 0 ثانية مقابل 172 ثانية!إذا نظرت إلى خطط الاستعلام ، يصبح من الواضح سبب ذلك. بسبب إضافة الطلب إلى نص الاستعلام ، ظهرت عملية فرز أثناء التنفيذ. هذه هي العملية المسماة "الحظر" ، والتي لا يمكنها إكمال الطلب حتى تتلقى كامل كمية البيانات للفرز. لا يمكننا استلام أول 45 سجلًا لدينا ، نحتاج إلى فرز مجموعة البيانات بالكامل.
وفي مرحلة الحصول على البيانات للفرز ، يحدث فرق كبير. يجب أن يتصفح البحث باستخدام "أعجبني" الجدول الكامل المتاح. هذا يستغرق 172 ثانية. لكن البحث عن النص الكامل له بنية محسّنة خاصة به ، والتي تُرجع على الفور روابط لجميع الإدخالات اللازمة.
ولكن يجب أن يكون هناك ذبابة في مرهم؟ هناك واحد. كما هو مذكور في البداية ، لا يمكن البحث عن النص الكامل إلا من بداية الكلمة. وإذا أردنا العثور على "Ivan Poddubny" بواسطة السلسلة الفرعية "* oak *" ، فلن يُظهر البحث عن النص الكامل أي شيء مفيد.
لحسن الحظ ، للبحث بالاسم ، ليس هذا هو السيناريو الأكثر شعبية.
البحث عن وثيقة عن طريق الرقم
لنجرب شيئًا أكثر تعقيدًا. حالة الاستخدام الشائعة الثانية للبحث هي العثور على مستند بواسطة جزء من رقمه. علاوة على ذلك ، يتكون رقم المستند غالبًا من جزأين: بادئة الحرف والرقم الفعلي الذي يحتوي على أصفار بادئة.
لا توجد مسافات أو أحرف خدمة بين هذه الأجزاء. في الوقت نفسه ، البحث عن الرقم الكامل غير مريح بشكل كبير - عليك أن تتذكر عدد الأصفار البادئة بعد البادئة التي يجب أن تكون قبل بداية الجزء الهام. اتضح أن البحث عن النص الكامل "خارج الصندوق" هو ببساطة عديم الجدوى في مثل هذا السيناريو. دعنا نحاول إصلاحه.
بالنسبة للاختبار ، قمت بإنشاء جدول جديد يسمى المستند ، قمت بإضافة 13.5 مليون سجل به أرقام فريدة من نوع "ORG". بدأ الترقيم بالترتيب ، وبدأت جميع الأرقام بـ "ORG". يمكنك البدء.
قبل تقسيم عدد
البحث عن النص الكامل يمكنه البحث بكفاءة عن الكلمات. حسنًا ، دعنا نساعده ونفكك الرقم "غير المريح" إلى كلمات ملائمة مقدمًا. خطة العمل هي كما يلي:
- أضف عمودًا إضافيًا إلى الجدول المصدر حيث سيتم تخزين الرقم المحول خصيصًا
- أضف المشغل ، والذي عند تغيير الرقم سيقسمه إلى عدة أجزاء صغيرة ، مفصولة بمسافة
- إن البحث عن النص الكامل يعرف بالفعل كيفية تقسيم السلسلة إلى أجزاء حسب المسافات ، بحيث يفهرس رقمنا المعدل دون مشاكل
دعونا نرى كيف ستعمل هذه.
إضافة عمود إضافي إلى الجدول.
alter table document add number_parts nvarchar(128) not null default ''
يمكن كتابة المشغل الذي يملأ عمودًا جديدًا "الجبين" ، متجاهلاً التكرارات المحتملة (عدد التكرارات المتكررة في الرقم "0000012"؟) ويمكنك إضافة بعض سحر XML وتسجيل أجزاء فريدة فقط. التنفيذ الأول سيكون أسرع ، والثاني سوف يعطي نتيجة أكثر إحكاما. في الواقع ، يكون الاختيار بين سرعة الكتابة وسرعة القراءة ، واختيار ما هو أكثر أهمية في وضعك. الآن فقط انتقل من خلال برنامج
نصي يعالج الأرقام الحالية.
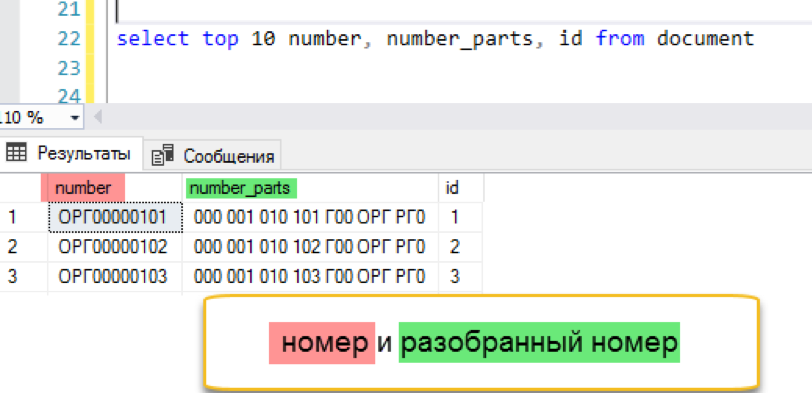
إضافة فهرس النص الكامل
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
وتحقق من النتيجة. التجربة هي نفسها - نمذجة اختيار "النافذة" من قائمة الوثائق. لا نكرر الأخطاء السابقة وننفذ الطلب فورًا بالفرز ، في هذه الحالة حسب التاريخ.
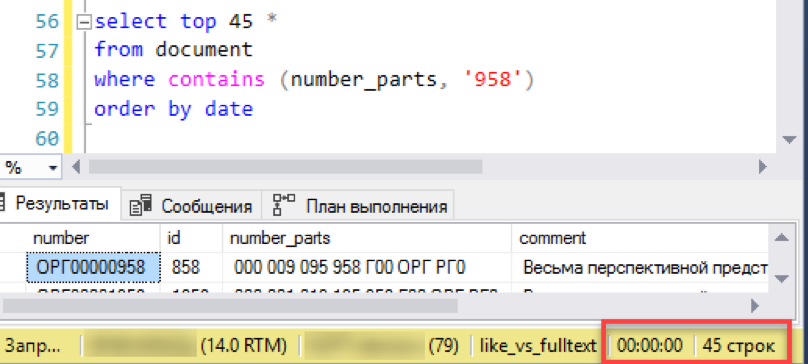
إنه يعمل! الآن لنجرب رقمًا أكثر أصالة:
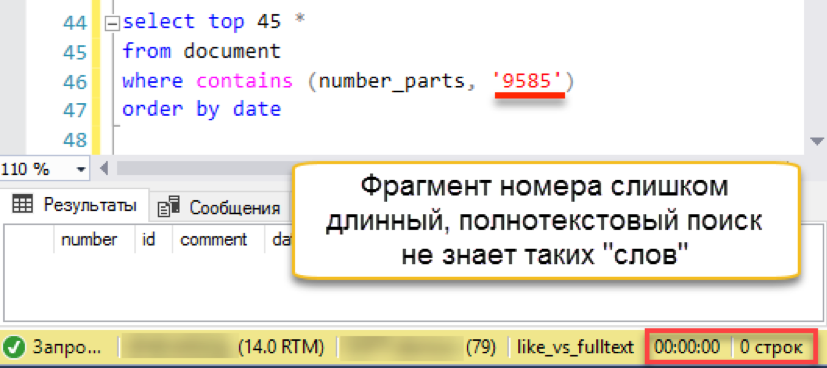
ثم يحدث اختلال. طول سلسلة البحث أطول من طول "الكلمات" المخزنة. في الواقع ، لا تحتوي قاعدة بيانات البحث ببساطة على سطر واحد يتكون من 4 أحرف ، لذلك تقوم بإرجاع نتيجة فارغة بأمانة. سيتعين علينا تجاوز سلسلة البحث إلى أجزاء:
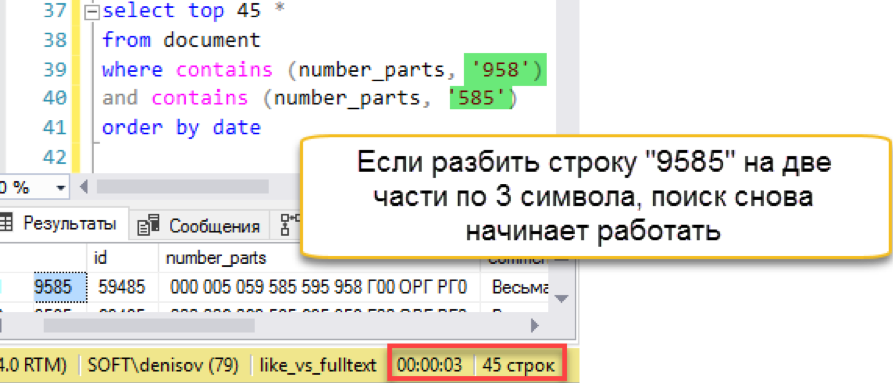
شيء اخر لدينا مرة أخرى بحث سريع. نعم ، يفرض النفقات العامة على الصيانة ، لكن النتيجة أسرع بمئات المرات من البحث الكلاسيكي. نلاحظ المحاولة التي تم حسابها ، ولكن حاول تبسيط الصيانة بطريقة ما - في القسم التالي.
سنقوم بتقسيمها إلى كلمات بطريقتنا الخاصة!
في الواقع ، من قال أن الكلمات يجب أن تفصل بينها مسافات؟ ربما أريد الأصفار بين الكلمات! (و ، إن أمكن ، البادئة بحيث يتم تجاهله أيضًا بطريقة ما ولا تتداخل بالأقدام). بشكل عام ، لا يوجد شيء مستحيل في هذا. دعنا نتذكر نظام تشغيل البحث عن النص الكامل من بداية المقالة - مكون منفصل ، كسر الكلمات ، مسؤول عن اقتحام الكلمات ، ولحسن الحظ ، تسمح لك Microsoft بتنفيذ "كسر الكلمات" الخاص بك.
وهنا تبدأ مثيرة للاهتمام. Wordbreaker هو دلل منفصلة الذي يتصل بمحرك البحث عن النص الكامل. تقول
الوثائق الرسمية أن جعل هذه المكتبة بسيط جدًا - ما عليك سوى تطبيق واجهة IWordBreaker. وهنا اثنين من قوائم التهيئة قصيرة في C ++. بنجاح كبير ، لقد وجدت برنامج تعليمي مناسب!

(
المصدر )
على محمل الجد ، الوثائق اللازمة لإنشاء أداة إزالة القلق الخاصة بك على الإنترنت صغيرة للغاية. حتى أقل الأمثلة والقوالب. لكنني ما زلت أجد
مشروعًا لطيفًا كتب في تطبيق C ++ تطبيقًا يقسم الكلمات ليس بالفواصل ، ولكن ببساطة عن طريق ثلاثة أضعاف (نعم ، تمامًا كما في القسم السابق!) علاوة على ذلك ، يحتوي مجلد المشروع بالفعل على ثنائي مترجم بعناية ، والذي تحتاجه فقط الاتصال بمحرك البحث.
مجرد توصيل ... في الواقع ليست سهلة للغاية. دعنا نذهب من خلال الخطوات:
تحتاج إلى نسخ المكتبة إلى المجلد باستخدام SQL Server:

تسجيل "لغة" جديدة في البحث عن النص الكامل
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
قم بتحرير عدة مفاتيح في السجل يدويًا (كان المؤلف بصدد تنفيذ العملية تلقائيًا ، ولكن لا توجد أخبار منذ عام 2016. ومع ذلك ، كان هذا في الأصل "مثال للتنفيذ" ، شكرًا على ذلك أيضًا)
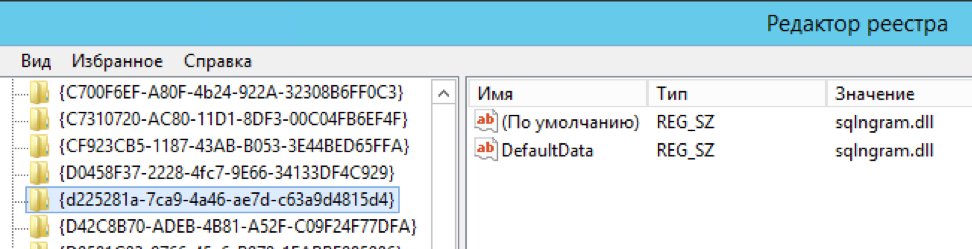
يتم وصف الخطوات بالتفصيل في صفحة المشروع.
القيام به. دعنا نحذف فهرس النص الكامل القديم ، لأنه لا يمكن أن يوجد فهرسان للنص الكامل لجدول واحد. إنشاء واحدة جديدة وفهرسة أرقام المستندات الخاصة بنا. كعمود مفتاح ، فإننا نشير إلى الأرقام نفسها ، وليس هناك حاجة إلى أعمدة بديلة سابقة التكسير. تأكد من تحديد "رقم اللغة 1" لاستخدام أداة إزالة الكلمات المثبتة حديثًا.
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
تحقق؟
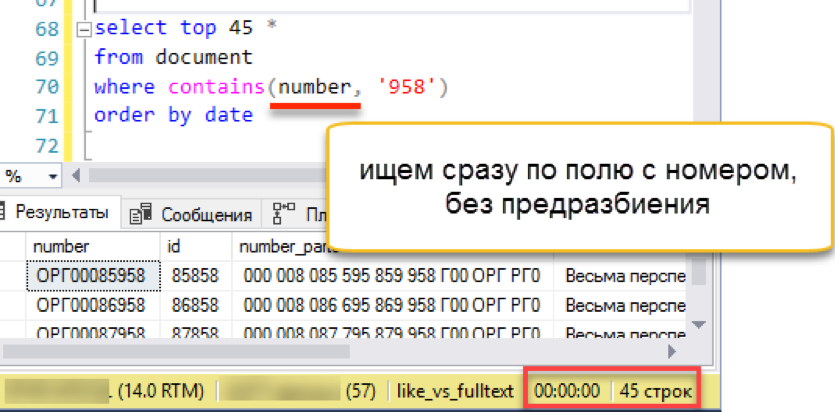
إنه يعمل! إنه يعمل بأسرع ما تقدمه الأمثلة المذكورة أعلاه.
دعونا نتحقق من الخط الطويل الذي تعثر فيه الخيار السابق:
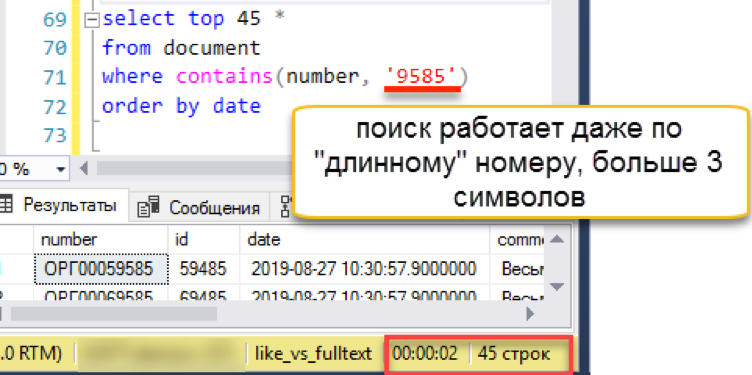
البحث يعمل بشفافية للمستخدم والمبرمج. يقسم Wordbreaker بشكل مستقل سلسلة البحث إلى أجزاء ويجد النتيجة المرجوة.
اتضح الآن أننا لسنا بحاجة إلى أعمدة ومشغلات إضافية ، أي أن الحل أبسط (اقرأ: أكثر موثوقية) من محاولتنا السابقة. حسنًا ، من حيث الدعم ، مثل هذا التنفيذ أبسط وأكثر شفافية ، هناك فرصة أقل للأخطاء.
لذلك ، توقف ، قلت "أكثر موثوقية"؟ لقد قمنا للتو بتوصيل بعض مكتبة الطرف الثالث بقواعد البيانات الخاصة بنا. وماذا سيحدث إذا سقطت؟ حتى عن غير قصد يسحب خدمة قاعدة البيانات بأكملها!
هنا ، عليك أن تتذكر كيف ذكرت في بداية المقال خدمة البحث عن النص الكامل ، المنفصلة عن عملية DBMS الرئيسية. ومن هنا يتضح سبب أهمية ذلك. تتصل المكتبة بخدمة فهرسة النص الكامل ، والتي يمكن أن تعمل مع حقوق مخفضة. والأهم من ذلك ، إذا سقطت مكونات الطرف الثالث ، فستقع خدمة الفهرسة فقط. سيتوقف البحث لفترة من الوقت (لكنه غير متزامن بالفعل) ، وسيستمر محرك قاعدة البيانات في العمل كما لو لم يحدث شيء.
لتلخيص. يمكن أن تشكل إضافة wordbreaker الخاصة بك تحديا كبيرا. ولكن عندما تلعب "على المدى الطويل" ، فإن هذه الجهود تؤتي ثمارها بمزيد من المرونة وسهولة الصيانة. الخيار كالمعتاد هو اختيارك.
لماذا كل هذا ضروري؟
ربما تساءل القارئ الفضولي أكثر من مرة: "كل هذا رائع ، لكن كيف يمكنني استخدام هذه الميزات إذا لم أتمكن من تغيير استعلامات البحث من طلبي؟" سؤال معقول. يتطلب تضمين بحث MS SQL بنص كامل تغيير بناء جملة الاستعلامات ، وغالبًا ما يكون ذلك غير ممكن في البنية الحالية.
يمكنك محاولة خداع التطبيق عن طريق "إزاحة" دالة ذات قيمة الجدول بنفس الاسم بدلاً من جدول عادي ، والذي سيقوم بالفعل بإجراء البحث بالطريقة التي نريدها. يمكنك محاولة ربط البحث كنوع من مصدر البيانات الخارجي. يوجد حل آخر - Softpoint Data Cluster - خدمة خاصة تقوم بتثبيت "إعادة توجيه" بين التطبيق المصدر وخدمة SQL Server ، وتستمع لحركة المرور ويمكنها تغيير الطلبات "سريعًا" وفقًا للقواعد الخاصة. باستخدام هذه القواعد ، يمكننا العثور على استعلامات منتظمة باستخدام LIKE وتحويلها إلى CONTAINS من خلال البحث عن النص الكامل.
لماذا هذه الصعوبات؟ ومع ذلك ، فإن سرعة البحث آسر. في نظام محمّل بكثافة ، حيث يبحث المشغلون غالبًا عن السجلات بملايين الجداول ، تعد سرعة الاستجابة أمرًا بالغ الأهمية. يؤدي توفير الوقت على أكثر العمليات تكرارًا إلى عشرات التطبيقات الإضافية المعالجة ، وهذا يعد نقودًا حقيقية يسعد أي عمل تجاري بها. في النهاية ، فإن بضعة أيام أو حتى أسابيع لدراسة وتنفيذ التكنولوجيا سوف تؤتي ثمارها مع زيادة كفاءة المشغل.
جميع النصوص المذكورة في المقالة متوفرة في مستودع
github.com/frrrost/mssql_fulltextعن المؤلف
 ألكساندر دينيسوف
ألكساندر دينيسوف - محلل أداء قاعدة بيانات خادم SQL. على مدار السنوات الست الماضية ، وكجزء من فريق Softpoint ، كنت أساعد في العثور على الاختناقات في طلبات الآخرين والضغط على معظم قواعد بيانات العملاء.